【slowfast 训练自己的数据集】自定义动作,制作自己的数据集,使用预训练模型进行训练,并检测其结果
目录
- 前言
- 一,视频的处理
-
- 1.1 视频准备
- 1.2 切割视频为图片
- 1.3 使用faster rcnn自动框人
- 1.4 via标注图片
- 二,数据集文件
-
- 2.1 数据集文件总览
- 2.2 annotations
-
- 2.2.1 ava_train_v2.2.csv
- 2.2.2 ava_val_v2.2.csv
- 2.2.3 ava_val_excluded_timestamps_v2.2.csv
- 2.2.4 ava_action_list_v2.2_for_activitynet_2019.pbtxt
- 2.2.5 ava_detection_train_boxes_and_labels_include_negative_v2.2.csv
- 2.2.6 ava_detection_val_boxes_and_labels.csv
- 2.3 frame_lists
-
- 2.3.1 train.csv
- 2.3.2 val.csv
- 2.4 frames
- 三,slowfast 训练自己的数据集
-
- 3.1 预训练模型
- 3.2 配置文件
- 3.3 训练过程
- 四 检测模型效果
-
- 4.2 创建json文件
- 4.2 创建yaml文件
- 4.3 修改ava_helper.py
- 4.4 运行
前言
终于到了这一步了,看了很久很久的slowfast,这次终于用slowfast训练了自己的数据集(只是用了个非常小的,非常小的数据集跑了一下),并且格式修改过程是手动修改的,训练过程所需要的yaml文件也是手动写出来的(后面会改成程序自动修改)
在看这篇训练自己的数据集博客之前,我觉得有必要了解一下之前我写一些博客:
的slowfast的训练,slowfast的减少数据集
1:【SlowFast复现】SlowFast Networks for Video Recognition复现代码 使用自己的视频进行demo检测
2:【Faster RCNN & detectron2】detectron2实现Faster RCNN目标检测
3,【faster rcnn 实现via的自动框人】使用detectron2中faster rcnn 算法生成人的坐标,将坐标导入via(VGG Image Annotator)中,实现自动框选出人的区域
4,【ffmpeg裁剪视频faster rcnn自动检测 via】全自动实现ffmpeg将视频切割为图片帧,再使用faster rcnn将图片中的人检测出来,最后将检测结果转化为via可识别的csv格式
5,【slowfast复现 训练】训练过程 制作ava数据集 复现 SlowFast Networks for Video Recognition 训练 train
6,【slowfast 减少ava数据集】将ava数据集缩小到2个,对数据集做训练,然后进行检测,为训练自己的数据集做准备
一,视频的处理
这里使用的数据集就是自己定义的数据集了,大家做什么领域的就用什么视频,比如有人要做手势识别的,就用手势的。有人要做人摔倒的,那就找人摔倒的视频。
我这里就用一个简单的视频,人在说话的视频。视频不多,就2个3秒的视频(这里是我用来做例子的,如果真实情况,2个视频3秒视频是远远不够的)。
1.1 视频准备
准备2个3秒的视频,最好里面人少一点,减少标注的难度。下图是我选择的几个3秒的视频(为了快速,我这里只选择其中2个)

下面是使用ffmpeg将一段长视频裁剪为3秒视频的命令。
ffmpeg -ss 00:00:00.0 -to 00:00:3.0 -i "../cutVideo2/1/1.mp4" "../shortVideoTrain/A.mp4"
ffmpeg -ss 00:00:03.0 -to 00:00:06.0 -i "../cutVideo2/1/1.mp4" "../shortVideoTrain/B.mp4"
ffmpeg -ss 00:00:06.0 -to 00:00:09.0 -i "../cutVideo2/1/1.mp4" "../shortVideoTrain/C.mp4"
ffmpeg -ss 00:00:09.0 -to 00:00:12.0 -i "../cutVideo2/1/1.mp4" "../shortVideoTrain/D.mp4"
ffmpeg -ss 00:00:12.0 -to 00:00:15.0 -i "../cutVideo2/1/1.mp4" "../shortVideoTrain/E.mp4"
1.2 切割视频为图片
这里需要把3秒的视频按2种方式切割
第一种是,把视频按照每秒1帧来裁剪,这样裁剪的目的是用来标注,因为ava数据集就是1秒1帧的标志。
命令如下:
#切割图片,每秒1帧
IN_DATA_DIR="../shortVideoTrain/"
OUT_DATA_DIR="../shortVideoTrainCut/"
if [[ ! -d "${OUT_DATA_DIR}" ]]; then
echo "${OUT_DATA_DIR} doesn't exist. Creating it.";
mkdir -p ${
OUT_DATA_DIR}
fi
for video in $(ls -A1 -U ${
IN_DATA_DIR}/*)
do
video_name=${
video##*/}
if [[ $video_name = *".webm" ]]; then
video_name=${
video_name::-5}
else
video_name=${
video_name::-4}
fi
out_video_dir=${
OUT_DATA_DIR}/${
video_name}/
mkdir -p "${out_video_dir}"
out_name="${out_video_dir}/${video_name}_%06d.jpg"
ffmpeg -i "${video}" -r 1 -q:v 1 "${out_name}"
done
切割结果如下(3秒的视频被切割为5张):

第二种是,把视频按照每秒30帧来裁剪,这样裁剪的目的是,用于slowfast的训练,因为slowfast,在slow流里,1秒会采集到15帧,在fast流里,1秒会采集到2帧。
命令如下:
#切割图片,每秒30帧
IN_DATA_DIR="../shortVideoTrain/"
OUT_DATA_DIR="../shortVideoFrames/"
if [[ ! -d "${OUT_DATA_DIR}" ]]; then
echo "${OUT_DATA_DIR} doesn't exist. Creating it.";
mkdir -p ${
OUT_DATA_DIR}
fi
for video in $(ls -A1 -U ${
IN_DATA_DIR}/*)
do
video_name=${
video##*/}
if [[ $video_name = *".webm" ]]; then
video_name=${
video_name::-5}
else
video_name=${
video_name::-4}
fi
out_video_dir=${
OUT_DATA_DIR}/${
video_name}/
mkdir -p "${out_video_dir}"
out_name="${out_video_dir}/${video_name}_%06d.jpg"
ffmpeg -i "${video}" -r 30 -q:v 1 "${out_name}"
done
切割结果如下(3秒的视频被切割为90张):


1.3 使用faster rcnn自动框人
其中这一步可以自己框人,因为2个视频就10张图片,但是,之后的数据集,应该是上万张,而且一张图片可能多达40个人,自己手动标注会很累的,所以这里采用我之前写的博客里的方法,使用detectron2里的faster rcnn 实现人的自动框出。
【faster rcnn 实现via的自动框人】使用detectron2中faster rcnn 算法生成人的坐标,将坐标导入via(VGG Image Annotator)中,实现自动框选出人的区域
【ffmpeg裁剪视频faster rcnn自动检测 via】全自动实现ffmpeg将视频切割为图片帧,再使用faster rcnn将图片中的人检测出来,最后将检测结果转化为via可识别的csv格式
这里就不说怎么自动标注了,上面两篇博客写的很清楚自动标注的过程。
自动标注后,会有生成一个csv文件,如下图所示:

打开这个文件,把里面的 单引号 ’ 全部删掉(可以替换为空),结果如下:
filename,file_size,file_attributes,region_count,region_id,region_shape_attributes,region_attributes
A_000001.jpg,33338,"""{}""",3,0,"{""name"": ""rect"", ""x"": 285, ""y"": 93, ""width"": 108, ""height"": 284}","""{}"""
A_000001.jpg,33338,"""{}""",3,1,"{""name"": ""rect"", ""x"": 537, ""y"": 357, ""width"": 50, ""height"": 46}","""{}"""
A_000001.jpg,33338,"""{}""",3,2,"{""name"": ""rect"", ""x"": 238, ""y"": 361, ""width"": 52, ""height"": 42}","""{}"""
A_000002.jpg,33430,"""{}""",3,0,"{""name"": ""rect"", ""x"": 535, ""y"": 361, ""width"": 55, ""height"": 42}","""{}"""
A_000002.jpg,33430,"""{}""",3,1,"{""name"": ""rect"", ""x"": 285, ""y"": 95, ""width"": 106, ""height"": 268}","""{}"""
A_000002.jpg,33430,"""{}""",3,2,"{""name"": ""rect"", ""x"": 238, ""y"": 361, ""width"": 52, ""height"": 42}","""{}"""
A_000003.jpg,33416,"""{}""",3,0,"{""name"": ""rect"", ""x"": 328, ""y"": 96, ""width"": 105, ""height"": 152}","""{}"""
A_000003.jpg,33416,"""{}""",3,1,"{""name"": ""rect"", ""x"": 234, ""y"": 360, ""width"": 52, ""height"": 43}","""{}"""
A_000003.jpg,33416,"""{}""",3,2,"{""name"": ""rect"", ""x"": 543, ""y"": 367, ""width"": 52, ""height"": 36}","""{}"""
A_000004.jpg,34544,"""{}""",3,0,"{""name"": ""rect"", ""x"": 328, ""y"": 94, ""width"": 110, ""height"": 152}","""{}"""
A_000004.jpg,34544,"""{}""",3,1,"{""name"": ""rect"", ""x"": 232, ""y"": 363, ""width"": 52, ""height"": 40}","""{}"""
A_000004.jpg,34544,"""{}""",3,2,"{""name"": ""rect"", ""x"": 541, ""y"": 365, ""width"": 52, ""height"": 38}","""{}"""
A_000005.jpg,34433,"""{}""",4,0,"{""name"": ""rect"", ""x"": 328, ""y"": 93, ""width"": 106, ""height"": 155}","""{}"""
A_000005.jpg,34433,"""{}""",4,1,"{""name"": ""rect"", ""x"": 233, ""y"": 364, ""width"": 53, ""height"": 39}","""{}"""
A_000005.jpg,34433,"""{}""",4,2,"{""name"": ""rect"", ""x"": 367, ""y"": 354, ""width"": 54, ""height"": 48}","""{}"""
A_000005.jpg,34433,"""{}""",4,3,"{""name"": ""rect"", ""x"": 543, ""y"": 369, ""width"": 52, ""height"": 34}","""{}"""
1.4 via标注图片
打开via,导入图片,导入csv,结果如下:
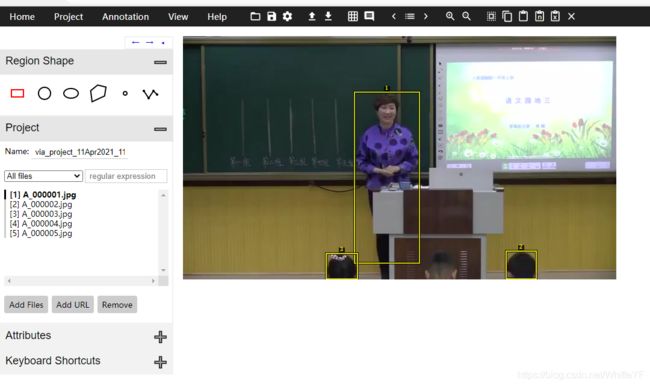
接下来,要做的是把一些没用的框给去掉,比如说上面图片中,只有脑袋的检测结果,这些就是不需要的,去掉,去掉后结果如下:

注意,这里不打标签,不打标签,因为slowfast所需要的标签格式和via的标签格式不同,这里在后面会手动填入标签,在我之后的博客里,会把via和slowfast的数据集格式的转换博客补上。
我们处理好上面所说的之后,导出csv文件,如下图:

filename,file_size,file_attributes,region_count,region_id,region_shape_attributes,region_attributes
A_000001.jpg,33338,"{""0"":""{"",""1"":""}""}",1,0,"{""name"":""rect"",""x"":285,""y"":93,""width"":108,""height"":284}","{""0"":""{"",""1"":""}""}"
A_000002.jpg,33430,"{""0"":""{"",""1"":""}""}",1,0,"{""name"":""rect"",""x"":285,""y"":95,""width"":106,""height"":268}","{""0"":""{"",""1"":""}""}"
A_000003.jpg,33416,"{""0"":""{"",""1"":""}""}",1,0,"{""name"":""rect"",""x"":328,""y"":96,""width"":105,""height"":152}","{""0"":""{"",""1"":""}""}"
A_000004.jpg,34544,"{""0"":""{"",""1"":""}""}",1,0,"{""name"":""rect"",""x"":328,""y"":94,""width"":110,""height"":152}","{""0"":""{"",""1"":""}""}"
A_000005.jpg,34433,"{""0"":""{"",""1"":""}""}",1,0,"{""name"":""rect"",""x"":328,""y"":93,""width"":106,""height"":155}","{""0"":""{"",""1"":""}""}"
二,数据集文件
在第一部分,我们已经拿到了2个图片文件的标注csv,接下来我们就手动把数据集的相关文件写了。
2.1 数据集文件总览
annotations
—person_box_67091280_iou90
——ava_detection_train_boxes_and_labels_include_negative_v2.2.csv
——ava_detection_val_boxes_and_labels.csv
—ava_action_list_v2.2_for_activitynet_2019.pbtxt
—ava_val_excluded_timestamps_v2.2.csv
—ava_train_v2.2.csv
—ava_val_v2.2.csv
frame_lists
—train.csv
—val.csv
frames
—A
——A_000001.jpg
——A_0000012.jpg
…
——A_000090.jpg
—B
——B_000001.jpg
——B_0000012.jpg
…
——B_000090.jpg
2.2 annotations
2.2.1 ava_train_v2.2.csv
A,1,0.395,0.230,0.545,0.933,1,0
A,2,0.395,0.235,0.543,0.898,1,0
A,3,0.455,0.237,0.601,0.613,1,0
A,4,0.455,0.232,0.608,0.608,1,0
A,5,0.455,0.230,0.602,0.613,1,0
2.2.2 ava_val_v2.2.csv
B,1,0.455,0.227,0.601,0.613,1,0
B,2,0.455,0.227,0.601,0.611,1,0
B,3,0.455,0.225,0.601,0.611,1,0
B,4,0.455,0.230,0.602,0.616,1,0
B,5,0.455,0.227,0.604,0.611,1,0
2.2.3 ava_val_excluded_timestamps_v2.2.csv
这是空文件
2.2.4 ava_action_list_v2.2_for_activitynet_2019.pbtxt
item {
name: "talk"
id: 1
}
2.2.5 ava_detection_train_boxes_and_labels_include_negative_v2.2.csv
A,1,0.395,0.230,0.545,0.933,1,0.996382
A,2,0.395,0.235,0.543,0.898,1,0.996382
A,3,0.455,0.237,0.601,0.613,1,0.996382
A,4,0.455,0.232,0.608,0.608,1,0.996382
A,5,0.455,0.230,0.602,0.613,1,0.996382
2.2.6 ava_detection_val_boxes_and_labels.csv
B,1,0.455,0.227,0.601,0.613,,0.995518
B,2,0.455,0.227,0.601,0.611,,0.995518
B,3,0.455,0.225,0.601,0.611,,0.995518
B,4,0.455,0.230,0.602,0.616,,0.995518
B,5,0.455,0.227,0.604,0.611,,0.995518
2.3 frame_lists
2.3.1 train.csv
original_vido_id video_id frame_id path labels
A 0 0 A/A_000001.jpg ""
A 0 1 A/A_000002.jpg ""
A 0 2 A/A_000003.jpg ""
A 0 3 A/A_000004.jpg ""
A 0 4 A/A_000005.jpg ""
A 0 5 A/A_000006.jpg ""
A 0 6 A/A_000007.jpg ""
A 0 7 A/A_000008.jpg ""
A 0 8 A/A_000009.jpg ""
A 0 9 A/A_000010.jpg ""
A 0 10 A/A_000011.jpg ""
A 0 11 A/A_000012.jpg ""
A 0 12 A/A_000013.jpg ""
A 0 13 A/A_000014.jpg ""
A 0 14 A/A_000015.jpg ""
A 0 15 A/A_000016.jpg ""
A 0 16 A/A_000017.jpg ""
A 0 17 A/A_000018.jpg ""
A 0 18 A/A_000019.jpg ""
A 0 19 A/A_000020.jpg ""
A 0 20 A/A_000021.jpg ""
A 0 21 A/A_000022.jpg ""
A 0 22 A/A_000023.jpg ""
A 0 23 A/A_000024.jpg ""
A 0 24 A/A_000025.jpg ""
A 0 25 A/A_000026.jpg ""
A 0 26 A/A_000027.jpg ""
A 0 27 A/A_000028.jpg ""
A 0 28 A/A_000029.jpg ""
A 0 29 A/A_000030.jpg ""
A 0 30 A/A_000031.jpg ""
A 0 31 A/A_000032.jpg ""
A 0 32 A/A_000033.jpg ""
A 0 33 A/A_000034.jpg ""
A 0 34 A/A_000035.jpg ""
A 0 35 A/A_000036.jpg ""
A 0 36 A/A_000037.jpg ""
A 0 37 A/A_000038.jpg ""
A 0 38 A/A_000039.jpg ""
A 0 39 A/A_000040.jpg ""
A 0 40 A/A_000041.jpg ""
A 0 41 A/A_000042.jpg ""
A 0 42 A/A_000043.jpg ""
A 0 43 A/A_000044.jpg ""
A 0 44 A/A_000045.jpg ""
A 0 45 A/A_000046.jpg ""
A 0 46 A/A_000047.jpg ""
A 0 47 A/A_000048.jpg ""
A 0 48 A/A_000049.jpg ""
A 0 49 A/A_000050.jpg ""
A 0 50 A/A_000051.jpg ""
A 0 51 A/A_000052.jpg ""
A 0 52 A/A_000053.jpg ""
A 0 53 A/A_000054.jpg ""
A 0 54 A/A_000055.jpg ""
A 0 55 A/A_000056.jpg ""
A 0 56 A/A_000057.jpg ""
A 0 57 A/A_000058.jpg ""
A 0 58 A/A_000059.jpg ""
A 0 59 A/A_000060.jpg ""
A 0 60 A/A_000061.jpg ""
A 0 61 A/A_000062.jpg ""
A 0 62 A/A_000063.jpg ""
A 0 63 A/A_000064.jpg ""
A 0 64 A/A_000065.jpg ""
A 0 65 A/A_000066.jpg ""
A 0 66 A/A_000067.jpg ""
A 0 67 A/A_000068.jpg ""
A 0 68 A/A_000069.jpg ""
A 0 69 A/A_000070.jpg ""
A 0 70 A/A_000071.jpg ""
A 0 71 A/A_000072.jpg ""
A 0 72 A/A_000073.jpg ""
A 0 73 A/A_000074.jpg ""
A 0 74 A/A_000075.jpg ""
A 0 75 A/A_000076.jpg ""
A 0 76 A/A_000077.jpg ""
A 0 77 A/A_000078.jpg ""
A 0 78 A/A_000079.jpg ""
A 0 79 A/A_000080.jpg ""
A 0 80 A/A_000081.jpg ""
A 0 81 A/A_000082.jpg ""
A 0 82 A/A_000083.jpg ""
A 0 83 A/A_000084.jpg ""
A 0 84 A/A_000085.jpg ""
A 0 85 A/A_000086.jpg ""
A 0 86 A/A_000087.jpg ""
A 0 87 A/A_000088.jpg ""
A 0 88 A/A_000089.jpg ""
A 0 89 A/A_000090.jpg ""
2.3.2 val.csv
originBl_vido_id video_id frBme_id pBth lBbels
B 1 0 B/B_000001.jpg ""
B 1 1 B/B_000002.jpg ""
B 1 2 B/B_000003.jpg ""
B 1 3 B/B_000004.jpg ""
B 1 4 B/B_000005.jpg ""
B 1 5 B/B_000006.jpg ""
B 1 6 B/B_000007.jpg ""
B 1 7 B/B_000008.jpg ""
B 1 8 B/B_000009.jpg ""
B 1 9 B/B_000010.jpg ""
B 1 10 B/B_000011.jpg ""
B 1 11 B/B_000012.jpg ""
B 1 12 B/B_000013.jpg ""
B 1 13 B/B_000014.jpg ""
B 1 14 B/B_000015.jpg ""
B 1 15 B/B_000016.jpg ""
B 1 16 B/B_000017.jpg ""
B 1 17 B/B_000018.jpg ""
B 1 18 B/B_000019.jpg ""
B 1 19 B/B_000020.jpg ""
B 1 20 B/B_000021.jpg ""
B 1 21 B/B_000022.jpg ""
B 1 22 B/B_000023.jpg ""
B 1 23 B/B_000024.jpg ""
B 1 24 B/B_000025.jpg ""
B 1 25 B/B_000026.jpg ""
B 1 26 B/B_000027.jpg ""
B 1 27 B/B_000028.jpg ""
B 1 28 B/B_000029.jpg ""
B 1 29 B/B_000030.jpg ""
B 1 30 B/B_000031.jpg ""
B 1 31 B/B_000032.jpg ""
B 1 32 B/B_000033.jpg ""
B 1 33 B/B_000034.jpg ""
B 1 34 B/B_000035.jpg ""
B 1 35 B/B_000036.jpg ""
B 1 36 B/B_000037.jpg ""
B 1 37 B/B_000038.jpg ""
B 1 38 B/B_000039.jpg ""
B 1 39 B/B_000040.jpg ""
B 1 40 B/B_000041.jpg ""
B 1 41 B/B_000042.jpg ""
B 1 42 B/B_000043.jpg ""
B 1 43 B/B_000044.jpg ""
B 1 44 B/B_000045.jpg ""
B 1 45 B/B_000046.jpg ""
B 1 46 B/B_000047.jpg ""
B 1 47 B/B_000048.jpg ""
B 1 48 B/B_000049.jpg ""
B 1 49 B/B_000050.jpg ""
B 1 50 B/B_000051.jpg ""
B 1 51 B/B_000052.jpg ""
B 1 52 B/B_000053.jpg ""
B 1 53 B/B_000054.jpg ""
B 1 54 B/B_000055.jpg ""
B 1 55 B/B_000056.jpg ""
B 1 56 B/B_000057.jpg ""
B 1 57 B/B_000058.jpg ""
B 1 58 B/B_000059.jpg ""
B 1 59 B/B_000060.jpg ""
B 1 60 B/B_000061.jpg ""
B 1 61 B/B_000062.jpg ""
B 1 62 B/B_000063.jpg ""
B 1 63 B/B_000064.jpg ""
B 1 64 B/B_000065.jpg ""
B 1 65 B/B_000066.jpg ""
B 1 66 B/B_000067.jpg ""
B 1 67 B/B_000068.jpg ""
B 1 68 B/B_000069.jpg ""
B 1 69 B/B_000070.jpg ""
B 1 70 B/B_000071.jpg ""
B 1 71 B/B_000072.jpg ""
B 1 72 B/B_000073.jpg ""
B 1 73 B/B_000074.jpg ""
B 1 74 B/B_000075.jpg ""
B 1 75 B/B_000076.jpg ""
B 1 76 B/B_000077.jpg ""
B 1 77 B/B_000078.jpg ""
B 1 78 B/B_000079.jpg ""
B 1 79 B/B_000080.jpg ""
B 1 80 B/B_000081.jpg ""
B 1 81 B/B_000082.jpg ""
B 1 82 B/B_000083.jpg ""
B 1 83 B/B_000084.jpg ""
B 1 84 B/B_000085.jpg ""
B 1 85 B/B_000086.jpg ""
B 1 86 B/B_000087.jpg ""
B 1 87 B/B_000088.jpg ""
B 1 88 B/B_000089.jpg ""
B 1 89 B/B_000090.jpg ""
2.4 frames
这里的存放我们在第一部分切割的图片,1秒切割30张的那个文件:

三,slowfast 训练自己的数据集
在第一部分和第二部分,我们把需要准备的东西都准备好了,下一步就是在slowfast修改训练所需要的代码。
3.1 预训练模型
最好使用预训练模型,这样可以缩短训练的一个时间,我用的预训练模型如下图
模型下载官网,预训练模型下载链接

下载下来后,放在文件夹/SlowFast/configs/AVA/c2/下面,如下图:

3.2 配置文件
在/SlowFast/configs/AVA/下创建一个新的yaml文件:SLOWFAST_32x2_R50_SHORT5.yaml,如下图:
代码如下:
TRAIN:
ENABLE: True
DATASET: ava
BATCH_SIZE: 8 #64
EVAL_PERIOD: 5
CHECKPOINT_PERIOD: 1
AUTO_RESUME: True
CHECKPOINT_FILE_PATH: '/home/lxn/0yangfan/Slowfast2/SlowFast-master/configs/AVA/c2/SLOWFAST_32x2_R101_50_50.pkl' #path to pretrain model
CHECKPOINT_TYPE: caffe2
DATA:
NUM_FRAMES: 32
SAMPLING_RATE: 2
TRAIN_JITTER_SCALES: [256, 320]
TRAIN_CROP_SIZE: 224
TEST_CROP_SIZE: 224
INPUT_CHANNEL_NUM: [3, 3]
PATH_TO_DATA_DIR: '/home/lxn/yf_videos/myCustomava'
DETECTION:
ENABLE: True
ALIGNED: True
AVA:
FRAME_DIR: '/home/lxn/yf_videos/myCustomava/frames'
FRAME_LIST_DIR: '/home/lxn/yf_videos/myCustomava/frame_lists'
ANNOTATION_DIR: '/home/lxn/yf_videos/myCustomava/annotations'
DETECTION_SCORE_THRESH: 0.8
TRAIN_PREDICT_BOX_LISTS: [
"ava_train_v2.2.csv",
"person_box_67091280_iou90/ava_detection_train_boxes_and_labels_include_negative_v2.2.csv",
]
TEST_PREDICT_BOX_LISTS: ["person_box_67091280_iou90/ava_detection_val_boxes_and_labels.csv"]
SLOWFAST:
ALPHA: 4
BETA_INV: 8
FUSION_CONV_CHANNEL_RATIO: 2
FUSION_KERNEL_SZ: 7
RESNET:
ZERO_INIT_FINAL_BN: True
WIDTH_PER_GROUP: 64
NUM_GROUPS: 1
DEPTH: 50
TRANS_FUNC: bottleneck_transform
STRIDE_1X1: False
NUM_BLOCK_TEMP_KERNEL: [[3, 3], [4, 4], [6, 6], [3, 3]]
SPATIAL_DILATIONS: [[1, 1], [1, 1], [1, 1], [2, 2]]
SPATIAL_STRIDES: [[1, 1], [2, 2], [2, 2], [1, 1]]
NONLOCAL:
LOCATION: [[[], []], [[], []], [[], []], [[], []]]
GROUP: [[1, 1], [1, 1], [1, 1], [1, 1]]
INSTANTIATION: dot_product
POOL: [[[1, 2, 2], [1, 2, 2]], [[1, 2, 2], [1, 2, 2]], [[1, 2, 2], [1, 2, 2]], [[1, 2, 2], [1, 2, 2]]]
BN:
USE_PRECISE_STATS: False
NUM_BATCHES_PRECISE: 200
SOLVER:
BASE_LR: 0.1
LR_POLICY: steps_with_relative_lrs
STEPS: [0, 10, 15, 20]
LRS: [1, 0.1, 0.01, 0.001]
MAX_EPOCH: 20
MOMENTUM: 0.9
WEIGHT_DECAY: 1e-7
WARMUP_EPOCHS: 5.0
WARMUP_START_LR: 0.000125
OPTIMIZING_METHOD: sgd
MODEL:
NUM_CLASSES: 1
ARCH: slowfast
MODEL_NAME: SlowFast
LOSS_FUNC: bce
DROPOUT_RATE: 0.5
HEAD_ACT: sigmoid
TEST:
ENABLE: False
DATASET: ava
BATCH_SIZE: 8
DATA_LOADER:
NUM_WORKERS: 2
PIN_MEMORY: True
NUM_GPUS: 1
NUM_SHARDS: 1
RNG_SEED: 0
OUTPUT_DIR: .
有几个需要注意的地方:
1,TRAIN:CHECKPOINT_FILE_PATH 就是我们下载的与训练模型的位置
2,DATA:PATH_TO_DATA_DIR 就是我们第二部分制作的数据集文件
3,AVA: 下面的路径也是对应第二部分数据集文件对应的地方
4,MODEL:NUM_CLASSES: 1 这里是最需要主义的,这里classes必需为1,因为我们只有talk这一个分类。
3.3 训练过程
python tools/run_net.py --cfg configs/AVA/SLOWFAST_32x2_R50_SHORT5.yaml
四 检测模型效果
使用slowfast检测自己的视频可以参考我之前写的一篇博客:
【SlowFast复现】SlowFast Networks for Video Recognition复现代码 使用自己的视频进行demo检测
详细过程我就不写了,上面这篇博客写的有。
4.2 创建json文件
在目录SlowFast-master/demo/AVA/下创建一个json文件:ava2.json
{
"talk": 0}
4.2 创建yaml文件
在目录SlowFast-master/demo/AVA/下创建一个yaml文件:SLOWFAST_32x2_R101_50_50s2.yaml

代码如下:
TRAIN:
ENABLE: False
DATASET: ava
BATCH_SIZE: 16
EVAL_PERIOD: 1
CHECKPOINT_PERIOD: 1
AUTO_RESUME: True
CHECKPOINT_FILE_PATH: '/home/lxn/0yangfan/Slowfast2/SlowFast-master/configs/AVA/c2/SLOWFAST_32x2_R101_50_50.pkl' #path to pretrain model
CHECKPOINT_TYPE: pytorch
DATA:
NUM_FRAMES: 32
SAMPLING_RATE: 2
TRAIN_JITTER_SCALES: [256, 320]
TRAIN_CROP_SIZE: 224
TEST_CROP_SIZE: 256
INPUT_CHANNEL_NUM: [3, 3]
DETECTION:
ENABLE: True
ALIGNED: False
AVA:
BGR: False
DETECTION_SCORE_THRESH: 0.8
TEST_PREDICT_BOX_LISTS: ["person_box_67091280_iou90/ava_detection_val_boxes_and_labels.csv"]
SLOWFAST:
ALPHA: 4
BETA_INV: 8
FUSION_CONV_CHANNEL_RATIO: 2
FUSION_KERNEL_SZ: 5
RESNET:
ZERO_INIT_FINAL_BN: True
WIDTH_PER_GROUP: 64
NUM_GROUPS: 1
DEPTH: 101
TRANS_FUNC: bottleneck_transform
STRIDE_1X1: False
NUM_BLOCK_TEMP_KERNEL: [[3, 3], [4, 4], [6, 6], [3, 3]]
SPATIAL_DILATIONS: [[1, 1], [1, 1], [1, 1], [2, 2]]
SPATIAL_STRIDES: [[1, 1], [2, 2], [2, 2], [1, 1]]
NONLOCAL:
LOCATION: [[[], []], [[], []], [[6, 13, 20], []], [[], []]]
GROUP: [[1, 1], [1, 1], [1, 1], [1, 1]]
INSTANTIATION: dot_product
POOL: [[[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]]]
BN:
USE_PRECISE_STATS: False
NUM_BATCHES_PRECISE: 200
SOLVER:
MOMENTUM: 0.9
WEIGHT_DECAY: 1e-7
OPTIMIZING_METHOD: sgd
MODEL:
NUM_CLASSES: 1
ARCH: slowfast
MODEL_NAME: SlowFast
LOSS_FUNC: bce
DROPOUT_RATE: 0.5
HEAD_ACT: sigmoid
TEST:
ENABLE: False
DATASET: ava
BATCH_SIZE: 8
DATA_LOADER:
NUM_WORKERS: 2
PIN_MEMORY: True
NUM_GPUS: 1
NUM_SHARDS: 1
RNG_SEED: 0
OUTPUT_DIR: .
#TENSORBOARD:
# MODEL_VIS:
# TOPK: 2
DEMO:
ENABLE: True
LABEL_FILE_PATH: "/home/lxn/0yangfan/Slowfast2/SlowFast-master/demo/AVA/ava2.json"
INPUT_VIDEO: "/home/lxn/yf_videos/myVideo15mins/eight.mp4"
OUTPUT_FILE: "/home/lxn/0yangfan/Slowfast2/SlowFast-master/Voutput/eight2.mp4"
DETECTRON2_CFG: "COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml"
DETECTRON2_WEIGHTS: detectron2://COCO-Detection/faster_rcnn_R_50_FPN_3x/137849458/model_final_280758.pkl
有几个地方需要注意:
1,TRAIN:CHECKPOINT_FILE_PATH 就是第三部分训练自己数据集的模型位置。
2,MODEL:NUM_CLASSES: 1 这里我们只有1个动作,所以只有一个分类
4.3 修改ava_helper.py
在目录/SlowFast-master/slowfast/datasets/下文件:ava_helper.py,如下图:

只需要一个修改:
#AVA_VALID_FRAMES = range(902, 1799)
AVA_VALID_FRAMES = range(1, 6)
把原来的 range(902, 1799) 改为 range(1, 6) 这是因为图片的编号改为了1~5.
4.4 运行
python tools/run_net.py --cfg demo/AVA/SLOWFAST_32x2_R101_50_50s2.yaml
检测结果如下:

视频已经上传到了B站:B站视频