本科生学深度学习-GRU最简单的讲解,伪代码阐述逻辑,实例展示效果
目录
1.gru 是什么
2.和LSTM的网络结构差别
3.门控单元解释
4.实例
下面的代码是在LSTM的基础上改动来的,数据也是和LSTM一样的,所以整体的结构是一样的,但是在修改代码的过程中还是遇到了一些问题,先看下完整的代码。
5、遇到的问题:
6、总结
RNN写了几期了,今天写下最后一个RNN的神经网络GRU,废话不多说,直接走起。
1.gru 是什么
GRU是LSTM的一种简单的变体,比LSTM网络的结构更加简单,而且效果也不差,运行效率更高,因此也是当前流行的一种网络结构。
使用GRU能够达到相当的效果,并且相比之下更容易进行训练,能够很大程度上提高训练效率,因此很多时候会更倾向于使用GRU。
2.和LSTM的网络结构差别
上一节的时候我写了LSTM的网络结构,LSTM最终的三个门控神经单元是输入门,遗忘门,以及输出门,简单的概括下三个门控单元所做的事

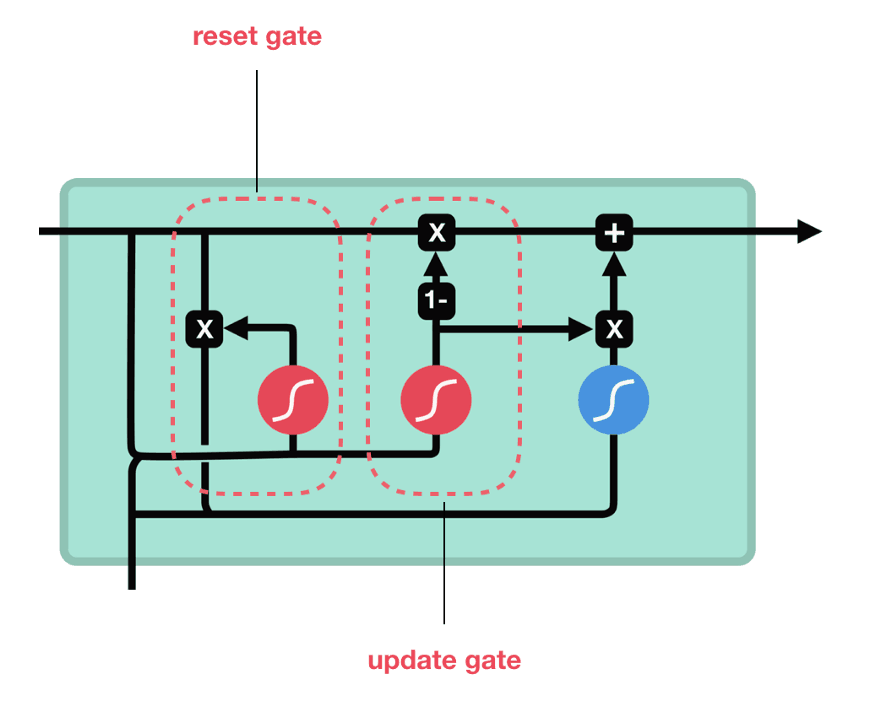
3.门控单元解释
RNN 主要需要关注的是隐藏参数的输出和输出值
详细的网络结构可以看下图,这张图说表述的很清楚,注意观察箭头的方向。
重置门:有多少记忆保存,重置 更新门:保留多少记忆更新到当前细胞单元
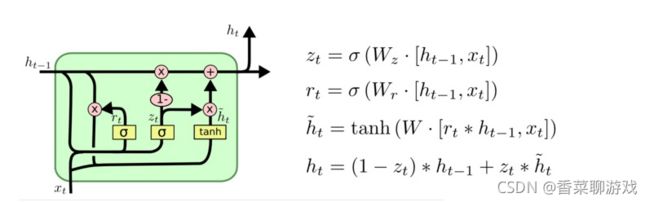
注:tanh 和 6 都是 神经网络,并不是简单的函数,W 表示神经网络的参数
伪代码如下,可以参照伪代码对比上述公式,知道函数之间的调用关系。
def 矩阵拼接(prevH,input):
#例如 [1,2] 和 [3,4] 拼接 [1,2,3,4]
return (prevH,input)
def 矩阵乘法(a,b):
#例如 (2,3)矩阵*(3,2)矩阵 =(2,2)矩阵
return a*b
# 注sigmoid 为神经网络
def getZt(prevH,input):
return sigmoid(prevH,input)
def getRt(prevH,input):
return sigmoid(prevH,input)
def getTempHt(prevH,input)
rt = getZt(prevH,input)
mult = rt * prevH
return tanh(mult)
def getHt(prevH,input):
zt = getZt(prevH,input)
ht = (1-zt)*prevH + zt* getTempHt(prevH,input)
return ht上面几个简单的函数式为了表示函数之间的关系,具体的实现还是很复杂的
4.实例
下面的代码是在LSTM的基础上改动来的,数据也是和LSTM一样的,所以整体的结构是一样的,但是在修改代码的过程中还是遇到了一些问题,先看下完整的代码。
import torch
import torch.nn as nn
import torch.nn.functional
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
"""
导入数据
"""
# load the dataset
flight_data = pd.read_csv('flights.csv', usecols=[1], engine='python')
dataset = flight_data.values
dataset = dataset.astype('float32')
print(flight_data.head())
print(flight_data.shape)
#绘制每月乘客的出行频率
fig_size = plt.rcParams['figure.figsize']
fig_size[0] = 15
fig_size[1] = 5
plt.rcParams['figure.figsize'] = fig_size
plt.title('Month vs Passenger')
plt.ylabel('Total Passengers')
plt.xlabel('Months')
plt.grid(True)
plt.autoscale(axis='x',tight=True)
plt.plot(flight_data['passengers'])
plt.show()
"""
数据预处理
"""
flight_data.columns#显示数据集中 列的数据类型
all_data = flight_data['passengers'].values.astype(float)#将passengers列的数据类型改为float
#划分测试集和训练集
test_data_size = 12
train_data = all_data[:-test_data_size]#除了最后12个数据,其他全取
test_data = all_data[-test_data_size:]#取最后12个数据
print(len(train_data))
print(len(test_data))
#最大最小缩放器进行归一化,减小误差
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(-1, 1))
train_data_normalized = scaler.fit_transform(train_data.reshape(-1, 1))
#查看归一化之后的前5条数据和后5条数据
print(train_data_normalized[:5])
print(train_data_normalized[-5:])
#将数据集转换为tensor,因为PyTorch模型是使用tensor进行训练的,并将训练数据转换为输入序列和相应的标签
train_data_normalized = torch.FloatTensor(train_data_normalized).view(-1)
#view相当于numpy中的resize,参数代表数组不同维的维度;
#参数为-1表示,这个维的维度由机器自行推断,如果没有-1,那么view中的所有参数就要和tensor中的元素总个数一致
#定义create_inout_sequences函数,接收原始输入数据,并返回一个元组列表。
def create_inout_sequences(input_data, tw):
inout_seq = []
L = len(input_data)
for i in range(L-tw):
train_seq = input_data[i:i+tw]
train_label = input_data[i+tw:i+tw+1]#预测time_step之后的第一个数值
inout_seq.append((train_seq, train_label))#inout_seq内的数据不断更新,但是总量只有tw+1个
return inout_seq
train_window = 12#设置训练输入的序列长度为12,类似于time_step = 12
train_inout_seq = create_inout_sequences(train_data_normalized, train_window)
print(train_inout_seq[:5])#产看数据集改造结果
"""
注意:
create_inout_sequences返回的元组列表由一个个序列组成,
每一个序列有13个数据,分别是设置的12个数据(train_window)+ 第13个数据(label)
第一个序列由前12个数据组成,第13个数据是第一个序列的标签。
同样,第二个序列从第二个数据开始,到第13个数据结束,而第14个数据是第二个序列的标签,依此类推。
"""
"""
创建LSTM模型
参数说明:
1、input_size:对应的及特征数量,此案例中为1,即passengers
2、output_size:预测变量的个数,及数据标签的个数
2、hidden_layer_size:隐藏层的特征数,也就是隐藏层的神经元个数
"""
class GRU(nn.Module):#注意Module首字母需要大写
def __init__(self, input_size=1, hidden_layer_size=100, output_size=1):
super().__init__()
self.hidden_layer_size = hidden_layer_size
# 创建LSTM层和linear层,LSTM层提取特征,linear层用作最后的预测
##LSTM算法接受三个输入:先前的隐藏状态,先前的单元状态和当前输入。
self.gru = nn.GRU(input_size, hidden_layer_size)
self.linear = nn.Linear(hidden_layer_size, output_size)
#初始化隐含状态及细胞状态C,hidden_cell变量包含先前的隐藏状态和单元状态
self.hidden_cell = torch.zeros(1, 1, self.hidden_layer_size)
# 为什么的第二个参数也是1
# 第二个参数代表的应该是batch_size吧
# 是因为之前对数据已经进行过切分了吗?????
def forward(self, input_seq):
lstm_out, self.hidden_cell = self.gru(input_seq.view(len(input_seq), 1, -1), self.hidden_cell)
#lstm的输出是当前时间步的隐藏状态ht和单元状态ct以及输出lstm_out
#按照lstm的格式修改input_seq的形状,作为linear层的输入
predictions = self.linear(lstm_out.view(len(input_seq), -1))
return predictions[-1]#返回predictions的最后一个元素
"""
forward方法:LSTM层的输入与输出:out, (ht,Ct)=lstm(input,(h0,C0)),其中
一、输入格式:lstm(input,(h0, C0))
1、input为(seq_len,batch,input_size)格式的tensor,seq_len即为time_step
2、h0为(num_layers * num_directions, batch, hidden_size)格式的tensor,隐藏状态的初始状态
3、C0为(seq_len, batch, input_size)格式的tensor,细胞初始状态
二、输出格式:output,(ht,Ct)
1、output为(seq_len, batch, num_directions*hidden_size)格式的tensor,包含输出特征h_t(源于LSTM每个t的最后一层)
2、ht为(num_layers * num_directions, batch, hidden_size)格式的tensor,
3、Ct为(num_layers * num_directions, batch, hidden_size)格式的tensor,
"""
#创建LSTM()类的对象,定义损失函数和优化器
model = GRU()
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)#建立优化器实例
print(model)
"""
模型训练
batch-size是指1次迭代所使用的样本量;
epoch是指把所有训练数据完整的过一遍;
由于默认情况下权重是在PyTorch神经网络中随机初始化的,因此可能会获得不同的值。
"""
epochs = 300
for i in range(epochs):
for seq, labels in train_inout_seq:
#清除网络先前的梯度值
optimizer.zero_grad()#训练模型时需要使模型处于训练模式,即调用model.train()。缺省情况下梯度是累加的,需要手工把梯度初始化或者清零,调用optimizer.zero_grad()
#初始化隐藏层数据
model.hidden_cell = torch.zeros(1, 1, model.hidden_layer_size)
#实例化模型
y_pred = model(seq)
#计算损失,反向传播梯度以及更新模型参数
single_loss = loss_function(y_pred, labels)#训练过程中,正向传播生成网络的输出,计算输出和实际值之间的损失值
single_loss.backward()#调用loss.backward()自动生成梯度,
optimizer.step()#使用optimizer.step()执行优化器,把梯度传播回每个网络
# 查看模型训练的结果
if i%25 == 1:
print(f'epoch:{i:3} loss:{single_loss.item():10.8f}')
print(f'epoch:{i:3} loss:{single_loss.item():10.10f}')
"""
预测
注意,test_input中包含12个数据,
在for循环中,12个数据将用于对测试集的第一个数据进行预测,然后将预测值附加到test_inputs列表中。
在第二次迭代中,最后12个数据将再次用作输入,并进行新的预测,然后 将第二次预测的新值再次添加到列表中。
由于测试集中有12个元素,因此该循环将执行12次。
循环结束后,test_inputs列表将包含24个数据,其中,最后12个数据将是测试集的预测值。
"""
fut_pred = 12
test_inputs = train_data_normalized[-train_window:].tolist()#首先打印出数据列表的最后12个值
print(test_inputs)
#更改模型为测试或者验证模式
model.eval()#把training属性设置为false,使模型处于测试或验证状态
for i in range(fut_pred):
seq = torch.FloatTensor(test_inputs[-train_window:])
with torch.no_grad():
model.hidden = (torch.zeros(1, 1, model.hidden_layer_size),
torch.zeros(1, 1, model.hidden_layer_size))
test_inputs.append(model(seq).item())
#打印最后的12个预测值
print(test_inputs[fut_pred:])
#由于对训练集数据进行了标准化,因此预测数据也是标准化了的
#需要将归一化的预测值转换为实际的预测值。通过inverse_transform实现
actual_predictions = scaler.inverse_transform(np.array(test_inputs[train_window:]).reshape(-1, 1))
print(actual_predictions)
"""
根据实际值,绘制预测值
"""
x = np.arange(132, 132+fut_pred, 1)
plt.title('Month vs Passenger with all data')
plt.ylabel('Total Passengers')
plt.xlabel('Months')
plt.grid(True)
plt.autoscale(axis='x', tight=True)
plt.plot(flight_data['passengers'])
plt.plot(x, actual_predictions)
plt.show()注:训练数据可以从LSTM的文章中获取下载地址,就不再上传了 看下预测的数据
从图上可以看到橙色的线的形状基本拟合了数据的趋势
5、遇到的问题:
在调试的过程中没有注意到LSTM 和 GRU 对隐藏参数的传递,出现了下面的报错,导致一直没办法训练

可以看到主要是hx.size 不是expected_hidden_size ,也就是说隐藏层的参数不对。
刚开始看了一头雾水,也不知道改哪里,最后参看了官方的文档,把hidden_cell 的初始化改成上面的代码
6、总结
RNN的神经网络暂时到一个段落了,时序模型的学习到此结束了,下面开始学习强化学习的模型