【AI】第四次作业:猫狗大战挑战赛
文章目录
-
- 前言
- 作业要求
- 实验前,先明确一些概念
- 一、在谷歌 Colab 上完成猫狗大战VGG分类
-
- 实验目的:
- 实验思路:
- 0、代码环境Colab
- 1、数据下载
- 2、数据预处理
- 3、创建VGG
- 4、修改最后一层网络,冻结前面层的参数
- 5、训练全连接层
- 6、测试整个模型
- 7、可视化输出结果
- 二、改进代码,参加猫狗大战比赛
-
- 参赛资源
- 实验目的
- 1、数据下载
- 2、Colab文件目录
- 3、输出CSV注意文件顺序
- 4、提交结果
- 5、补充,我改进了哪里?
前言
第一次收到作业要写博客的要求…所以局外人可能不知道我为什么要写这篇博客,好吧,其实就是为了交作业。我会在一个月之后对标题进行修改(怎么着也给等老师看完了吧…),方便大家进行理解。
本来是想写的简洁一些,但是感觉写的太少不能说明自己实验过程。如果只想了解大致步骤,只看博客目录即可。
作业要求
- 完成一篇技术博客,题目为“第四次作业:猫狗大战挑战赛”,在谷歌 Colab 上完成猫狗大战VGG模型的迁移学习,关键步骤截图,并附一些自己想法和解读。
- 在该代码的基础上,下载AI研习社“猫狗大战”比赛的测试集,利用fine-tune的VGG模型进行测试,按照比赛规定的格式输出,上传结果在线评测。将在线评测结果截图,将代码实现的解读发在博客。同时,分析使用哪些技术可以进一步提高分类准确率。
实验前,先明确一些概念
-
VGG是卷积神经网络的一种,研究这个网络的课题组叫做VGG,所以该网络是这么个名字。
-
VGG 模型如下图所示,注意该网络由三种元素组成。有关于卷积神经网络更详细的介绍可以看我的另一篇博客(不知道这可不可以加分~虽说关系也不大吧…)
- 卷积层(CONV)是发现图像中局部的 特征
- 全连接层(FC)是在全局上建立特征的关联
- 池化(Pool)是给图像降维,防止训练过拟合。
-
数据会被分为三个部分:
- Train集:训练模型用,不多解释
- Valid集:这部分数据用来进行模拟考试,检验自己模型的正确率,相当于带标签的test集
- Test集:最终提交作业实验所用的测试集,是真正的考试。
一、在谷歌 Colab 上完成猫狗大战VGG分类
实验1的源码,colab需要
实验目的:
在谷歌 Colab 上完成猫狗大战VGG模型的迁移学习,关键步骤截图,并附一些自己想法和解读。
实验思路:
- 首先我们需要下载猫和狗的图片的数据集(在这里使用的是精简过的数据集)。
- 把下载的图片数据进行一些预处理。
- 创建VGG模型(使用已经训练好的模型)。
- 可视化最终分类结果。
0、代码环境Colab
- 谷歌Colab是一个在线python编辑器,内置了很多现成的包,而且可以使用谷歌免费的GPU资源进行数据训练,本篇博客的代码均在Colab上运行。
Colab地址:
https://colab.research.google.com/notebooks/intro.ipynb#scrollTo=P-H6Lw1vyNNd

- 另外,使用谷歌Colab需要科学上网…具体方法在此不说了,我怕一会我号没了。
1、数据下载
这个数据集中:
- 训练集包含1800张图(猫的图片900张,狗的图片900张)
- 测试集包含2000张图。
#一、下载精简过的数据集####################################################################
! wget http://fenggao-image.stor.sinaapp.com/dogscats.zip
! unzip dogscats.zip
2、数据预处理
完成数据下载之后,需要对数据进行一些预处理:
- 图片将被整理成 224 × 224 × 3 224\times 224 \times 3 224×224×3 的大小,同时还将进行归一化处理。
- 其他的一些对数据的复杂的预处理/变换 (normalization, cropping, flipping, jittering 等)可以参照 torchvision.tranforms 的官方文档说明。
#二、对下载的数据进行数据处理############################################################
#1、设置刚刚下载的文件目录
data_dir = './dogscats'
#2、归一化,注意transforms是一个图像预处理包
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
- 设置VGG的格式(其实我并不知道为什么一定就要规定一个格式,就当是规定吧…)
- 同时加载图像的数据。
#3、设置VGG输入图片的格式
vgg_format = transforms.Compose([#用Compose把多个步骤整合到一起:
transforms.CenterCrop(224),#裁剪出图象的中心区域,大小为:244x244
transforms.ToTensor(),#数据类型转换而已,有点类似于numpy包的arrary化操作
normalize,
])
#4、加载图像数据。dataset是该功能的一个包。
dsets = {
x: datasets.ImageFolder(os.path.join(data_dir, x),
vgg_format) for x in ['train', 'valid']}
#获取一些必要属性
dset_sizes = {
x: len(dsets[x]) for x in ['train', 'valid']}
dset_classes = dsets['train'].classes
- 将数据拆分为训练集和有效集;
- 顺便取一小部分数据用来做可视化。
#5、加载训练集和有效集
# torch.utils.data.DataLoader在训练模型时使用到此函数
# 用来把训练数据分成多个小组,此函数每次抛出一组数据。
# 直至把所有的数据都抛出。就是做一个数据的初始化。
loader_train = torch.utils.data.DataLoader(dsets['train'], batch_size=64, shuffle=True, num_workers=6) #num_workers越大,好处是寻batch速度快,但是CPU负担越重
loader_valid = torch.utils.data.DataLoader(dsets['valid'], batch_size=5, shuffle=False, num_workers=6)
#6、去除一小部分数据,用做实验可视化
#valid数据一共有2000张图,每个batch是5张,因此,下面进行遍历一共会输出400次。同时,把第一个batch保存到inputs_try,labels_try,并分别查看
count = 1
for data in loader_valid:
#print(count)
if count == 1:
inputs_try,labels_try = data
count +=1
在把这几张图片打印出来看看效果:
##########################
#工具-显示图片的函数
##########################
def imshow(inp, title=None):
# Imshow for Tensor.
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = np.clip(std * inp + mean, 0,1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
#打印这俩试试
print(inputs_try.shape)
print(labels_try)
# 看一看labels_try 的5张图片,即valid里第一个batch的5张图片
out = torchvision.utils.make_grid(inputs_try)
imshow(out, title=[dset_classes[x] for x in labels_try])
打印图片和对应结果:

- input_try是5张244x244x3(RGB三通道)的小图片;
- lable_try是这五张图片对应的标签,都是0,说明,这五张照片都是猫;
- 补充,在本次实验中,规定:标签为0是猫,1是狗。

3、创建VGG
#三、创建VGG模型#############################################################################
#在这部分代码中,对输入的5个图片利用VGG模型进行预测,同时,使用softmax对结果进行处理,随后展示了识别结果。
#1、下载ImageNet(120万张训练数据)的1000个类的JSON文件。
!wget https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json
#2、创建VGG模型
model_vgg = models.vgg16(pretrained=True)
with open('./imagenet_class_index.json') as f:#python读json文件按,加载模型
class_dict = json.load(f)
接下来的dic_imagenet是各种动物的标签。
来源自下载的模型中会对数据有一个分类的总概率分布,有5000种分类,dic_imagenet适合最终的分类概率有关的一个数。
我输入一张图片:
- x的概率像tench(一种鱼)
- x1的概率像老虎。
- x2的概率像大白鲨
- x3的概率像虎鲸…
…有5000种分类。
#这里面存的都是各种动物的名称,用于分类
#dic_imagenet = [class_dict[str(i)][1] for i in range(len(class_dict))]
dic_imagenet = []
for i in range(len(class_dict)):
dic_imagenet.append(class_dict[str(i)][1])
#print(dic_imagenet)
- 就如下图print所展示的那样,是各种动物的标签。

- 下一步:
#把数据塞到GPU里
inputs_try = inputs_try.to(device)
labels_try = labels_try.to(device)
model_vgg = model_vgg.to(device)
#3、把输入的集合,放在VGG模型里跑一跑,得到输出
outputs_try = model_vgg(inputs_try)
print(outputs_try)
#print(outputs_try.shape)

打印出结果,观测可知:
- 结果为5行(因为一共是5张图片嘛),1000列的数据,每一列在不同dic_imagenet 目标识别的结果。
- 结果非常奇葩,有负数,有正数。
- 为了好看(至少让数据看起来像一个概率),我们把结果输入到 Softmax 函数。
#4、对输出进行软最大化处理,要不然数据实在是不好看清。
m_softm = nn.Softmax(dim=1)#softmax将杂乱的数,变成明确的概率分布,便于观察。
#probs = m_softm(outputs_try)
softmax_outputs_try = m_softm(outputs_try)
#max是选取了每一个维度中最大值进行输出,观察vals_try的第一个值——0.17,就是因为第一张图有两只手遮住了猫,所以却认为猫的概率会直线下降
vals_try,index_pred_try = torch.max(softmax_outputs_try,dim=1)
#打印
print( 'prob sum: ', torch.sum(softmax_outputs_try,1))
print()
print( 'vals_try: ', vals_try)
print()
print( 'index_pred_try: ', index_pred_try)
#print([dic_imagenet[i] for i in index_pred_try.data])
imshow(torchvision.utils.make_grid(inputs_try.data.cpu()), title=[dset_classes[x] for x in labels_try.data.cpu()])

4、修改最后一层网络,冻结前面层的参数
首先说明为什么要这么做?
- 因为我们使用的模型是现成的、预训练好的模型,所以大部分的模型参数我们都不需要动,只需要动最后全连接层输出部分的参数就可以了(也就是修改最后一层网络)。
因此,
- 需要把最后的 nn.Linear 层由1000类,替换为2类。
- 为了在训练中冻结前面层的参数,需要设置 required_grad=False。
- 这样,反向传播训练梯度时,前面层的权重就不会自动更新了。训练中,只会更新最后一层的参数。
#四、修改最后一层,冻结前面的参数?
print(model_vgg)#打印当前VGG模型长什么样子
#新的VGG锁定前面的参数,只更新最后一层。
model_vgg_new = model_vgg;
for param in model_vgg_new.parameters():
param.requires_grad = False#False冻结前面的参数
model_vgg_new.classifier._modules['6'] = nn.Linear(4096, 2)
model_vgg_new.classifier._modules['7'] = torch.nn.LogSoftmax(dim = 1)
model_vgg_new = model_vgg_new.to(device)#把新的模型添加到GPU,就像前几部做的那样,一回事儿。
print(model_vgg_new.classifier)
5、训练全连接层
- 虽然VGG大部分层数参数不需要更改,但是毕竟最后输出还是要靠全连接层,最后一层的参数是发生变动的(相当于前面99%的网络都别人训练好的,我就训练最后的1%),所以我们还是需要训练、并测试全连接层。
#五、训练全连接层#################################################################
#包括三个步骤:第1步,创建损失函数和优化器;第2步,训练模型。
#1、创建损失函数和优化器,损失函数 NLLLoss()的输入是一个对数概率向量和一个目标标签,它不会为我们计算对数概率,适合最后一层是log_softmax()的网络。
criterion = nn.NLLLoss()
# 设置学习率(步长)
study_step_length = 0.001
# 随机梯度下降
optimizer_vgg = torch.optim.SGD(model_vgg_new.classifier[6].parameters(),lr = study_step_length)
#2、训练模型
def train_model(model,dataloader,size,epochs=1,optimizer=None):
model.train()
for epoch in range(epochs):
running_loss = 0.0
running_corrects = 0
count = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
optimizer = optimizer
optimizer.zero_grad()
loss.backward()
optimizer.step()
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
count += len(inputs)
print('Training: No.', count, ' process ... totalSize = ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print()
print('Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss, epoch_acc))
# 模型训练
train_model(model_vgg_new,loader_train,size=dset_sizes['train'], epochs=1, optimizer=optimizer_vgg)
6、测试整个模型
- 现在整个模型都训练好了,那就理所应当的跑一跑,测试而已。
- 现在输入的是Valid集,因为它自带标签,可以用来统计一些误差数据。
#六、测试模型###################################################
def test_model(model,dataloader,size):
model.eval()
predictions = np.zeros(size)
all_classes = np.zeros(size)
all_proba = np.zeros((size,2))
i = 0
running_loss = 0.0
running_corrects = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
predictions[i:i+len(classes)] = preds.to('cpu').numpy()
all_classes[i:i+len(classes)] = classes.to('cpu').numpy()
all_proba[i:i+len(classes),:] = outputs.data.to('cpu').numpy()
i += len(classes)
print('Testing: No. ', i, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print()
print('Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss, epoch_acc))
return predictions, all_proba, all_classes
predictions, all_proba, all_classes = test_model(model_vgg_new,loader_valid,size=dset_sizes['valid'])
7、可视化输出结果
#七、将结果可视化############################################################
# 单次可视化显示的图片个数
n_view = 8
correct = np.where(predictions==all_classes)[0]
from numpy.random import random, permutation
idx = permutation(correct)[:n_view]
print('random correct idx: ', idx)
loader_correct = torch.utils.data.DataLoader([dsets['valid'][x] for x in idx],
batch_size = n_view,shuffle=True)
for data in loader_correct:
inputs_cor,labels_cor = data
# Make a grid from batch
out = torchvision.utils.make_grid(inputs_cor)
#打印
imshow(out, title=[l.item() for l in labels_cor])
打印结果,其中0是猫;1是狗(第四幅图那个黑色的屁股,我是真没看出来那是个啥,电脑说是猫就是猫吧)。

到此,完成VGG网络的搭建并分类应用。
二、改进代码,参加猫狗大战比赛
参赛资源
-
猫狗大战比赛链接
-
官方提供的训练集和测试集
-
实验二的完整代码点击这里查看
实验目的
-
在实验一代码的基础上,下载AI研习社“猫狗大战”比赛的测试集,利用fine-tune的VGG模型进行测试,按照比赛规定的格式输出(CSV格式),上传结果在线评测。

-
将在线评测结果截图,将代码实现的解读发在博客。
-
同时,分析使用哪些技术可以进一步提高分类准确率。
注意:由于第二部分的代码与实验一的代码有大量重复,所以在实验二中值列举关键步骤和值得注意的步骤。
1、数据下载
- 准备好官方提供的测试集和训练集至Colab云盘(直接在代码里面解压缩图片的话,过一段时间该目录下的所有文件会被清除缓存,无法长时间存储)。
- 值得注意的是,之前的代码中,不论是训练集还是有效集,他们都有一层子目录叫做cats或者是dogs来充当这些图片的标签,而且代码也是这么写的,需要图片有上一级的子文件夹。
- 然而我们获得的训练及是没有标签,所以如果还想使用原来的读数据集的代码,需要手动设置一层子文件夹当作标签。
- 这个子文件夹其实叫什么都无所谓,因为随中的标签是我们用模型生成的,原来读进来的标签放在一边,不使用就好了。
2、Colab文件目录
-
由于我把照片集放在了Colab的云盘上,这和本机文件目录有所区别。所以如何在代码中读Colab的文件(图片)也成为了一个问题。
-
需要输入以下指令获取Colab的Drive网盘权限(我姑且先这么翻译)。
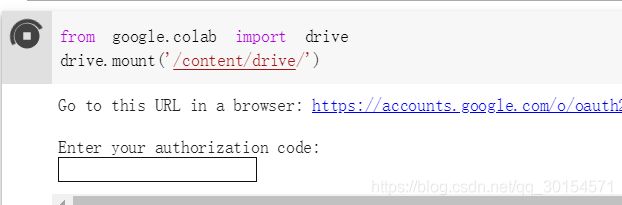
-
之后会提示让你输入一个权限码:

-
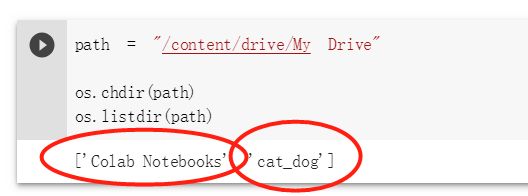
之后成功切换目录到网盘目录,就可以按照本机的操作习惯调取文件了

-
打印一下我云盘的内容,看看是不是已经成功切换。
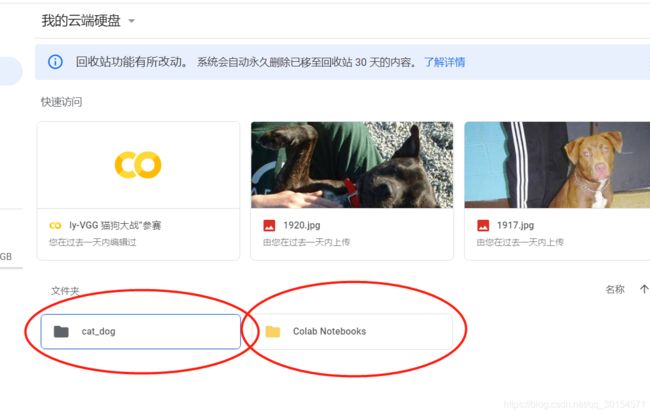
嗯,成功切换到网盘目录下了,再也不用担心colab清理缓存结果把把我的数据图片清理了…
3、输出CSV注意文件顺序
- 之前提交了几次结果,我默认图像的顺序是1~2000,之后把图像对应的value直接按照顺序打上了1-2000的顺序,后来检测成绩都是0分。

究其原因,是因为图像文件并不是按照顺序执行的,而是按照以下这种诡异的顺序排列而成: 所以输出CSV文件的时候要考虑到每个文件的名称。
所以输出CSV文件的时候要考虑到每个文件的名称。
- 解决方法是先获取datasets里面的文件名,之后把文件名都存到一个字典里,最后去for循环这个dic,同步输出value。

测试集具体的代码实现:
#3、测试模型
filenameAndValue = {
}#用来存图片编号和对应的Value
def test_model(model,dataloader,size):
model.eval()
predictions = np.zeros(size)
all_classes = np.zeros(size)
all_proba = np.zeros((size,2))
i = 0
running_loss = 0.0
running_corrects = 0
myTest_folder = datasets.ImageFolder('cat_dog/myTest', vgg_format)#这里的地址是我存放赛题数据集的地址,需要注意的是这个地址只包含test
#因为图片输出不是按照顺序,所以需要提取图片名称作为key,存为dic
pic_index = 0
for inputs,classes in dataloader:#数据和标签
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)#获得输出
loss = criterion(outputs, classes)#计算损失函数
_,preds = torch.max(outputs.data, 1)
#
key = myTest_folder.imgs[pic_index][0].split("\\")[-1].split('.')[0]
pic_index = pic_index + 1
filenameAndValue[key] = preds[0]
# statistics统计
predictions[i:i+len(classes)] = preds.to('cpu').numpy()
all_classes[i:i+len(classes)] = classes.to('cpu').numpy()
all_proba[i:i+len(classes),:] = outputs.data.to('cpu').numpy()
i += len(classes)
return predictions, all_proba, all_classes
predictions, all_proba, all_classes = test_model(model_vgg_new, loader_test, size=dset_sizes['myTest'])#装入测试集test
输出csv
# coding: utf-8
#输出成csv
with open("result.csv",'a+') as f:
for item in filenameAndValue.items():
#这里使用大量的split函数来分离出我想要的元素
f.write("{},{}\n".format(str(item[0]).split("/")[3],int(str(item[1]).split("(")[1].split(",")[0])))
输出csv如下(我又手动给csv的key做了个升序排序):
4、提交结果

5、补充,我改进了哪里?
- 第一开始,我对于网络进行了调参的优化,包括学习率、batch的大小,网络内的反射次数等等,但都不是很明显。
- 在调参的过程中准确率一直堪忧,在某些测试中,loss高达0.2,ACC只有0.5左右,后来我提高了这里——随机梯度下降部分,效果立竿见影。损失函数立马变成0.01左右,ACC升到了0.9x:

究其原因:
- torch.optim是一个实现了多种优化算法的包,大多数通用的方法都已支持,为了使用torch.optim,需先构造一个优化器对象Optimizer,用来保存当前的状态,并能够根据计算得到的梯度来更新参数。
- 要构建一个优化器optimizer,你必须给它一个可进行迭代优化的包含了所有参数的列表。 然后,您可以指定程序优化特定的选项,例如学习速率,权重衰减等。
- 而SGD和Adam都是pytorch中常用的优化器
- SGD 是最普通的优化器, 也可以说没有加速效果; 而Adam 是SGD优化器添加了诸如动量原则等升级,所以一般效果比SGD优化效果好。