项目优化方案及分析过程,解决办法
一、工具和排查方法
二、大批量的导入导出优化
三、抽样计算功能的优化
1.1. 工具和排查方法
1.1.1. 使用jdk自带的 jconsole,直接在cmd命令中打入jconsole,就会弹出一个窗体


1.1.2. 使用FinalShell 工具查看

1.1.3. 使用jprofile工具查看内存和cpu

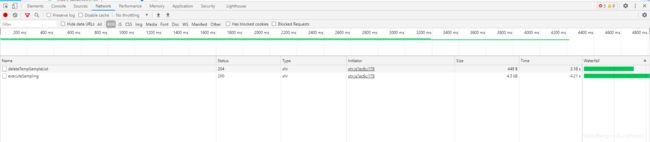
1.1.4. 前端浏览器控制台,F12查看接口调用的time 耗时
1.1.5. 采用打印日志方式查看内存和使用时间
totalMemory()这个方法返回的是java虚拟机现在已经从操纵系统那里挖过来的内存大小,也就是java虚拟机这个进程当时所占用的 所有 内存。假如在运行java的时候没有添加-Xms参数,那么,在java程序运行的过程的,内存总是慢慢的从操纵系统那里挖的,基本上是用多少挖多少,一直 挖到maxMemory()为止,所以totalMemory()是慢慢增大的。假如用了-Xms参数,程序在启动的时候就会无条件的从操纵系统中挖- Xms后面定义的内存数,然后在这些内存用的差不多的时候,再往挖。
freeMemory()是什么呢,刚才说到假如在运行java的时候没有添加-Xms参数,那么,在java程序运行的过程的,内存总是慢慢的 从操 作系统那里挖的,基本上是用多少挖多少,但是java虚拟机100%的情况下是会稍微多挖一点的,这些挖过来而又没有用上的内存,实际上就是 freeMemory(),所以freeMemory()的值一般情况下都是很小的,但是假如你在运行java程序的时候使用了-Xms,这个时候由于程 序在启动的时候就会无条件的从操纵系统中挖-Xms后面定义的内存数,这个时候,挖过来的内存可能大部分没用上,所以这个时候freeMemory()可 能会有些大。
StopWatch是位于org.springframework.util包下的一个工具类,通过它可方便的对程序部分代码进行计时(ms级别),适用于同步单线程代码块。
具体使用
//Byte(字节)
long startMemory=(Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory());
log.debug("Data prepared Start,memory: {} MB",startMemory/1024/1024);
long endMemory=(Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory());
log.debug("Data prepared Done,memory: {} MB",endMemory/1024/1024);
log.debug("Data prepared Done all used memory: {} MB",(endMemory-startMemory)/1024/1024);
Stopwatch stopwatch = Stopwatch.createStarted();
log.debug("Data prepared Done, using: {} ms", stopwatch.stop().elapsed(TimeUnit.MILLISECONDS));
1.2. 优化一:多用户大批量数据的导入导出
1.2.1. 问题描述:
1.当对大数据量的execle导入导出会特别缓慢
2.多个用户同时导出时内存爆满,服务器卡死
1.2.2. 分析:主要是非常大的内存消耗
报错:OutOfMemoryError: GC overthread limit exceeded。是否可以 采用easyexcel 来替换原本的 poi 方式。
1.2.3. 实验:写一个demo 来进行比对两个直接的区别,poi和easyExcel 读取文件内存占用统计
介绍:
虽然POI是目前使用最多的用来做excel解析的框架,但这个框架并不那么完美。大部分使用POI都是使用他的userModel模式。userModel的好处是上手容易使用简单,随便拷贝个代码跑一下,剩下就是写业务转换了,虽然转换也要写上百行代码,相对比较好理解。然而userModel模式最大的问题是在于非常大的内存消耗,一个几兆的文件解析要用掉上百兆的内存。现在很多应用采用这种模式,之所以还正常在跑一定是并发不大,并发上来后一定会OOM或者频繁的full gc。
EasyExcel是一个基于Java的简单、省内存的读写Excel的开源项目。在尽可能节约内存的情况下支持读写百M的Excel。
前提:需要准备一个excel 文件 (历史问卷-混合.xlsx) 大小约为44M
我们直接来看结果对比
左边是poi 方式的,右边是easyExcel方式的,明显easyExcel的内存占用小很多很多 ,内存运行也相对稳定,并且读取速度也比poi方式快很多倍。
控制台打印内存情况(另一个文件, 约14M左右)
poi
解析前时间18:31:37 解析后时间:18:32:21
解析前内存:81940KB 解析后内存:3827028KB
(3827028KB-81940KB)/1024/1024=3.5G
easyexcel
解析前l时间18:29:27 解析后时间:18:29:35
解析前内存:81940KB 解析后内存:804407KB
(804407KB-81940KB)/1024/1024=0.69G
1.2.4. 实现:
1.引入poi和easyExcel的包
2.编写测试内容–
<dependencies>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>easyexcelartifactId>
<version>1.1.2-beta4version>
dependency>
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poiartifactId>
<version>4.0.0version>
dependency>
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poi-ooxmlartifactId>
<version>4.0.0version>
dependency>
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poi-ooxml-schemasartifactId>
<version>4.0.0version>
dependency>
dependencies>
EasyExcelTest.java
package excel;
import com.alibaba.excel.EasyExcelFactory;
import com.alibaba.excel.ExcelReader;
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.event.AnalysisEventListener;
import com.alibaba.excel.support.ExcelTypeEnum;
import org.apache.poi.ss.usermodel.Sheet;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.List;
/**
* @Author: wjx
* @Date: 2021/5/7-16:38
* @Version: 1.0
*/
public class EasyExcelTest{
public static void main(String[] args) throws InterruptedException {
System.out.println("解析Excel前内存:"+(Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory())/1024/1024+"MB");
read();
System.out.println("解析Excel后内存:"+(Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory())/1024/1024+"MB");
System.out.println();
Thread.sleep(20000);
}
private static void read() {
try(InputStream inputStream = new FileInputStream("E:\历史问卷-混合2.xlsx")) {
ExcelReader excelReader = new ExcelReader(inputStream, ExcelTypeEnum.XLSX, null, new AnalysisEventListener<List<String>>() {
@Override
public void invoke(List<String> object, AnalysisContext context) {
/*System.out.println("当前sheet:" + context.getCurrentSheet().getSheetNo() + ",当前行:" +
context.getCurrentRowNum());*/
}
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
}
});
excelReader.read();
} catch (Exception e) {
e.printStackTrace();
}
}
}
ExcelListener.java
package excel;
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.event.AnalysisEventListener;
import java.util.ArrayList;
import java.util.List;
/**
* @Author: wjx
* @Date: 2021/5/7-16:40
* @Version: 1.0
*/
public class ExcelListener extends AnalysisEventListener {
private List<Object> data = new ArrayList<Object>();
@Override
public void invoke(Object object, AnalysisContext context) {
data.add(object);
}
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
}
}
PoiExcelTest.java
package excel;
import org.apache.poi.hssf.usermodel.HSSFDataFormatter;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.ss.usermodel.WorkbookFactory;
import java.io.File;
import java.io.FileInputStream;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @Author: wjx
* @Date: 2021/5/7-16:28
* @Version: 1.0
*/
public class PoiExcelTest {
private int totalRows = 0;// 总行数
private int totalCells = 0;// 总列数
public Map<String, List<List<String>>> read(String fileName) {
Map<String, List<List<String>>> maps = new HashMap<String, List<List<String>>>();
if (fileName == null || !fileName.matches("^.+\.(?i)((xls)|(xlsx))$"))
return maps;
File file = new File(fileName);
if (file == null || !file.exists())
return maps;
try {
Workbook wb = WorkbookFactory.create(new FileInputStream(file));
maps = read(wb);
} catch (Exception e) {
e.printStackTrace();
}
return maps;
}
public int getTotalRows() {
return totalRows;
}
public int getTotalCells() {
return totalCells;
}
private Map<String, List<List<String>>> read(Workbook wb) {
Map<String, List<List<String>>> maps = new HashMap<String, List<List<String>>>();
int number = wb.getNumberOfSheets();
if (number > 0) {
for (int i = 0; i < number; i++) {
// 循环每个工作表
List<List<String>> list = new ArrayList<List<String>>();
int delnumber = 0;// 第一页去除行数
Sheet sheet = wb.getSheetAt(i);
this.totalRows = sheet.getPhysicalNumberOfRows() - delnumber; // 获取工作表中行数
if (this.totalRows >= 1 && sheet.getRow(delnumber) != null) {
this.totalCells = sheet.getRow(0)
.getPhysicalNumberOfCells(); // 得到当前行的所有单元格
for (int j = 0; j < totalRows; j++) {
List<String> rowLst = new ArrayList<String>();
for (int f = 0; f < totalCells; f++) {
if (totalCells > 0) {
String value = getCell(sheet.getRow(j).getCell(f));
rowLst.add(value);
}
}
list.add(rowLst);
}
}
maps.put(sheet.getSheetName(), list);
}
}
return maps;
}
public String getCell(Cell cell) {
String cellValue = null;
HSSFDataFormatter hSSFDataFormatter = new HSSFDataFormatter();
cellValue = hSSFDataFormatter.formatCellValue(cell); // 使用EXCEL原来格式的方式取得值
return cellValue;
}
public static void main(String[] args) {
try {
System.out.println("解析Excel前内存:"+(Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory())/1024/1024+"MB");
Map<String, List<List<String>>> map = new PoiExcelTest ()
.read("E:\历史问卷-混合2.xlsx");
System.out.println("解析Excel后内存:"+(Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory())/1024/1024+"MB");
//System.out.println(map);
} catch (Exception e) {
e.printStackTrace();
}
}
}
1.2.5. 结论:easyExcel完胜 → 应用
把easyExcel放入到正常测试环境中
导出占用内存,对于一个 10806 页的问卷明细 导出后压缩包为210M左右的 ,数据量约为11W
文件大小
![]()
导出数据量和导出结果时间

说明:内存及时间使用的打印情况(没有开启jprofile,可能开启会有一定的影响),之后的jprofile 又重新导出的一遍
Data prepared Start,memory: 4591 MB
Data prepared Done, using: 102480 ms
Data prepared Done,memory: 13732 MB
Data prepared Done all used memory: 9141 MB
Create EasyExcel Data use 51330 ms
Create EasyExcel Data,memory: 14427 MB
Excel Generated done, using :166049 ms
详细步骤图查看
此时重新启动项目,使用 jprofile 监控查看,分了7个图解
1、整体使用情况

2、初始化启动项目时,默认使用0.55G左右

3、初始导出时4.5G,此时开始执行导出方法, 在从数据库 拿全量数据

4、此时,在拼装数据

5、此时在执行拼装数据

6、后面这是在执行 EasyExcel拼装excel 表头和内容,写出excel。(此时几乎不会增加消耗很多内存)

7、结束后

1.2.6. 存在瓶颈 :
如果导出几十万的数据的话,还是会耗时很长,那么就改为异步导入导出,采用异步消息提示的方式。后端改为多个接口,点击导出时提示客户正在进行下载,然后异步去执行这个导出的下载任务,前端定时刷新消息去更新状态。成功后提示用户。


1.2.7. 开发时困难的点:
1.2.7.1. 对于表头样式的问题

进行调整样式
ExcelWriter excelWriter = write(os)
.registerWriteHandler(new CustomHandler()).build();
需要写一个自定义的类来实现表格 大小的调整
CustomHandler.java
public class CustomHandler extends AbstractColumnWidthStyleStrategy {
private static final int MAX_COLUMN_WIDTH = 255;
//the maximum column width in Excel is 255 characters
public CustomHandler() {
// empty constructor
}
@Override
protected void setColumnWidth(WriteSheetHolder writeSheetHolder, List<CellData> cellDataList, Cell cell, Head head, Integer relativeRowIndex, Boolean isHead) {
if (isHead && cell.getRowIndex() == 0) {
int columnWidth = cell.getStringCellValue().getBytes().length;
if (columnWidth > MAX_COLUMN_WIDTH) {
columnWidth = MAX_COLUMN_WIDTH;
} else {
columnWidth = columnWidth + 10;
}
writeSheetHolder.getSheet().setColumnWidth(cell.getColumnIndex(), columnWidth * 300);
}
}
}
改造后


1.2.7.2. 对于导出表格拼接表头的问题
这是官方的示例和代码,直接在 固定的实体类写入 @ExcelProperty,来实现合并

但是在动态里面,固定的实体类是不适用的,那么就需要自己去手动的拼接表头

1.3. 优化二:多用户大量数据的 复杂公式 抽样计算
1.3.1. 第一阶段:查询语句及数据库索引优化
1.3.1.1. 问题分析
对抽样计算过程做拆解:
加载选中数据集的数据
根据抽样规则抽样
将抽样得到的样本集存入库表
关联详情表查询出汇总变量值
变量代入表达式得出计算结果
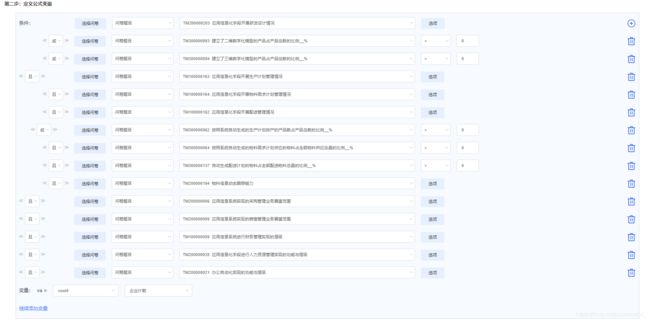
首先发现复杂公式的汇总变量查询功能运行缓慢。
1)计算公式-汇总变量配置界面
2)汇总变量查询语句
原始sql
SELECT COUNT(1)
FROM dsp_dataset_result t0,
f_result_sync t1
WHERE ((((t0.dataset_id = 410)) AND
(((t1.asse_res_unicode IN (SELECT t2.asse_res_unicode
FROM f_result_sync_im t3,
f_result_sync t2
WHERE (((t3.ques_id = 147) AND (t3.ques_answer_content IN
('A', 'AB', 'ABC', 'ABCD', 'ABCDE', 'ABCE', 'ABD',
'ABDE', 'ABE', 'AC', 'ACD', 'ACDE', 'ACE', 'AD',
'ADE', 'AE', 'B', 'BC', 'BCD', 'BCDE', 'BCE', 'BD',
'BDE', 'BE', 'C', 'CD', 'CDE', 'CE', 'D',
'DE'))) AND
(t2.asse_res_unicode = t3.asse_res_unicode))) AND
(t1.paper_id IN (1751, 1756, 1753, 1755, 1754)))
AND ((t1.asse_res_unicode IN
(SELECT t4.asse_res_unicode
FROM f_result_sync_im t5,
f_result_sync t4
WHERE (((t5.ques_id = 146) AND
(t5.ques_answer_content IN
('A', 'AB', 'ABC', 'ABCD', 'ABCDE', 'ABCE', 'ABD', 'ABDE', 'ABE', 'AC', 'ACD', 'ACDE',
'ACE', 'AD', 'ADE', 'AE', 'B', 'BC', 'BCD', 'BCDE', 'BCE', 'BD', 'BDE', 'BE', 'C', 'CD',
'CDE', 'CE', 'D', 'DE'))) AND
(t4.asse_res_unicode = t5.asse_res_unicode))) AND
(t1.paper_id IN (1751, 1756, 1753, 1755, 1754))) AND
((t1.asse_res_unicode IN (SELECT t6.asse_res_unicode
FROM f_result_sync_im t7,
f_result_sync t6
WHERE (((t7.ques_id = 139) AND
(t7.ques_answer_content IN ('B', 'C', 'D', 'E'))) AND
(t6.asse_res_unicode = t7.asse_res_unicode))) AND
(t1.paper_id IN (1751, 1756, 1753, 1755, 1754))) AND
((t1.asse_res_unicode IN (SELECT t8.asse_res_unicode
FROM f_result_sync_im t9,
f_result_sync t8
WHERE (((t9.ques_id = 132) AND
(t9.ques_answer_content IN
('AB', 'ABC', 'ABCD', 'ABCDE', 'ABCDEF', 'ABCDEFG', 'ABCDEFGH',
'ABCDEFGHI', 'ABCDEFGI', 'ABCDEFH', 'ABCDEFHI', 'ABCDEFI',
'ABCDEG', 'ABCDEGH', 'ABCDEGHI', 'ABCDEGI', 'ABCDEH', 'ABCDEHI',
'ABCDEI', 'ABCDF', 'ABCDFG', 'ABCDFGH', 'ABCDFGHI', 'ABCDFGI',
'ABCDFH', 'ABCDFHI', 'ABCDFI', 'ABCDG', 'ABCDGH', 'ABCDGHI',
'ABCDGI', 'ABCDH', 'ABCDHI', 'ABCDI', 'ABCE', 'ABCEF', 'ABCEFG',
'ABCEFGH', 'ABCEFGHI', 'ABCEFGI', 'ABCEFH', 'ABCEFHI', 'ABCEFI',
'ABCEG', 'ABCEGH', 'ABCEGHI', 'ABCEGI', 'ABCEH', 'ABCEHI',
'ABCEI', 'ABCF', 'ABCFG', 'ABCFGH', 'ABCFGHI', 'ABCFGI', 'ABCFH',
'ABCFHI', 'ABCFI', 'ABCG', 'ABCGH', 'ABCGHI', 'ABCGI', 'ABCH',
'ABCHI', 'ABCI', 'ABD', 'ABDE', 'ABDEF', 'ABDEFG', 'ABDEFGH',
'ABDEFGHI', 'ABDEFGI', 'ABDEFH', 'ABDEFHI', 'ABDEFI', 'ABDEG',
'ABDEGH', 'ABDEGHI', 'ABDEGI', 'ABDEH', 'ABDEHI', 'ABDEI', 'ABDF',
'ABDFG', 'ABDFGH', 'ABDFGHI', 'ABDFGI', 'ABDFH', 'ABDFHI',
'ABDFI', 'ABDG', 'ABDGH', 'ABDGHI', 'ABDGI', 'ABDH', 'ABDHI',
'ABDI', 'ABE', 'ABEF', 'ABEFG', 'ABEFGH', 'ABEFGHI', 'ABEFGI',
'ABEFH', 'ABEFHI', 'ABEFI', 'ABEG', 'ABEGH', 'ABEGHI', 'ABEGI',
'ABEH', 'ABEHI', 'ABEI', 'ABF', 'ABFG', 'ABFGH', 'ABFGHI',
'ABFGI', 'ABFH', 'ABFHI', 'ABFI', 'ABG', 'ABGH', 'ABGHI', 'ABGI',
'ABH', 'ABHI', 'ABI', 'AC', 'ACD', 'ACDE', 'ACDEF', 'ACDEFG',
'ACDEFGH', 'ACDEFGHI', 'ACDEFGI', 'ACDEFH', 'ACDEFHI', 'ACDEFI',
'ACDEG', 'ACDEGH', 'ACDEGHI', 'ACDEGI', 'ACDEH', 'ACDEHI',
'ACDEI', 'ACDF', 'ACDFG', 'ACDFGH', 'ACDFGHI', 'ACDFGI', 'ACDFH',
'ACDFHI', 'ACDFI', 'ACDG', 'ACDGH', 'ACDGHI', 'ACDGI', 'ACDH',
'ACDHI', 'ACDI', 'ACE', 'ACEF', 'ACEFG', 'ACEFGH', 'ACEFGHI',
'ACEFGI', 'ACEFH', 'ACEFHI', 'ACEFI', 'ACEG', 'ACEGH', 'ACEGHI',
'ACEGI', 'ACEH', 'ACEHI', 'ACEI', 'ACF', 'ACFG', 'ACFGH',
'ACFGHI', 'ACFGI', 'ACFH', 'ACFHI', 'ACFI', 'ACG', 'ACGH',
'ACGHI', 'ACGI', 'ACH', 'ACHI', 'ACI', 'AD', 'ADE', 'ADEF',
'ADEFG', 'ADEFGH', 'ADEFGHI', 'ADEFGI', 'ADEFH', 'ADEFHI',
'ADEFI', 'ADEG', 'ADEGH', 'ADEGHI', 'ADEGI', 'ADEH', 'ADEHI',
'ADEI', 'ADF', 'ADFG', 'ADFGH', 'ADFGHI', 'ADFGI', 'ADFH',
'ADFHI', 'ADFI', 'ADG', 'ADGH', 'ADGHI', 'ADGI', 'ADH', 'ADHI',
'ADI', 'AE', 'AEF', 'AEFG', 'AEFGH', 'AEFGHI', 'AEFGI', 'AEFH',
'AEFHI', 'AEFI', 'AEG', 'AEGH', 'AEGHI', 'AEGI', 'AEH', 'AEHI',
'AEI', 'AF', 'AFG', 'AFGH', 'AFGHI', 'AFGI', 'AFH', 'AFHI', 'AFI',
'AG', 'AGH', 'AGHI', 'AGI', 'AH', 'AHI', 'AI', 'B', 'BC', 'BCD',
'BCDE', 'BCDEF', 'BCDEFG', 'BCDEFGH', 'BCDEFGHI', 'BCDEFGI',
'BCDEFH', 'BCDEFHI', 'BCDEFI', 'BCDEG', 'BCDEGH', 'BCDEGHI',
'BCDEGI', 'BCDEH', 'BCDEHI', 'BCDEI', 'BCDF', 'BCDFG', 'BCDFGH',
'BCDFGHI', 'BCDFGI', 'BCDFH', 'BCDFHI', 'BCDFI', 'BCDG', 'BCDGH',
'BCDGHI', 'BCDGI', 'BCDH', 'BCDHI', 'BCDI', 'BCE', 'BCEF',
'BCEFG', 'BCEFGH', 'BCEFGHI', 'BCEFGI', 'BCEFH', 'BCEFHI',
'BCEFI', 'BCEG', 'BCEGH', 'BCEGHI', 'BCEGI', 'BCEH', 'BCEHI',
'BCEI', 'BCF', 'BCFG', 'BCFGH', 'BCFGHI', 'BCFGI', 'BCFH',
'BCFHI', 'BCFI', 'BCG', 'BCGH', 'BCGHI', 'BCGI', 'BCH', 'BCHI',
'BCI', 'BD', 'BDE', 'BDEF', 'BDEFG', 'BDEFGH', 'BDEFGHI',
'BDEFGI', 'BDEFH', 'BDEFHI', 'BDEFI', 'BDEG', 'BDEGH', 'BDEGHI',
'BDEGI', 'BDEH', 'BDEHI', 'BDEI', 'BDF', 'BDFG', 'BDFGH',
'BDFGHI', 'BDFGI', 'BDFH', 'BDFHI', 'BDFI', 'BDG', 'BDGH',
'BDGHI', 'BDGI', 'BDH', 'BDHI', 'BDI', 'BE', 'BEF', 'BEFG',
'BEFGH', 'BEFGHI', 'BEFGI', 'BEFH', 'BEFHI', 'BEFI', 'BEG',
'BEGH', 'BEGHI', 'BEGI', 'BEH', 'BEHI', 'BEI', 'BF', 'BFG',
'BFGH', 'BFGHI', 'BFGI', 'BFH', 'BFHI', 'BFI', 'BG', 'BGH',
'BGHI', 'BGI', 'BH', 'BHI', 'BI', 'C', 'CD', 'CDE', 'CDEF',
'CDEFG', 'CDEFGH', 'CDEFGHI', 'CDEFGI', 'CDEFH', 'CDEFHI',
'CDEFI', 'CDEG', 'CDEGH', 'CDEGHI', 'CDEGI', 'CDEH', 'CDEHI',
'CDEI', 'CDF', 'CDFG', 'CDFGH', 'CDFGHI', 'CDFGI', 'CDFH',
'CDFHI', 'CDFI', 'CDG', 'CDGH', 'CDGHI', 'CDGI', 'CDH', 'CDHI',
'CDI', 'CE', 'CEF', 'CEFG', 'CEFGH', 'CEFGHI', 'CEFGI', 'CEFH',
'CEFHI', 'CEFI', 'CEG', 'CEGH', 'CEGHI', 'CEGI', 'CEH', 'CEHI',
'CEI', 'CF', 'CFG', 'CFGH', 'CFGHI', 'CFGI', 'CFH', 'CFHI', 'CFI',
'CG', 'CGH', 'CGHI', 'CGI', 'CH', 'CHI', 'CI', 'D', 'DE', 'DEF',
'DEFG', 'DEFGH', 'DEFGHI', 'DEFGI', 'DEFH', 'DEFHI', 'DEFI',
'DEG', 'DEGH', 'DEGHI', 'DEGI', 'DEH', 'DEHI', 'DEI', 'DF', 'DFG',
'DFGH', 'DFGHI', 'DFGI', 'DFH', 'DFHI', 'DFI', 'DG', 'DGH',
'DGHI', 'DGI', 'DH', 'DHI', 'DI', 'E', 'EF', 'EFG', 'EFGH',
'EFGHI', 'EFGI', 'EFH', 'EFHI', 'EFI', 'EG', 'EGH', 'EGHI', 'EGI',
'EH', 'EHI', 'EI', 'F', 'FG', 'FGH', 'FGHI', 'FGI', 'FH', 'FHI',
'FI', 'G', 'GH', 'GHI', 'GI', 'H', 'HI', 'I'))) AND
(t8.asse_res_unicode = t9.asse_res_unicode))) AND
(t1.paper_id IN (1751, 1756, 1753, 1755, 1754))) AND
((t1.asse_res_unicode IN (SELECT t10.asse_res_unicode
FROM f_result_sync_im t11,
f_result_sync t10
WHERE (((t11.ques_id = 128) AND
(t11.ques_answer_content IN
('AB', 'ABC', 'ABCD', 'ABCDE', 'ABCDEF', 'ABCDEFG', 'ABCDEG',
'ABCDF', 'ABCDFG', 'ABCDG', 'ABCE', 'ABCEF', 'ABCEFG', 'ABCEG',
'ABCF', 'ABCFG', 'ABCG', 'ABD', 'ABDE', 'ABDEF', 'ABDEFG',
'ABDEG', 'ABDF', 'ABDFG', 'ABDG', 'ABE', 'ABEF', 'ABEFG', 'ABEG',
'ABF', 'ABFG', 'ABG', 'AC', 'ACD', 'ACDE', 'ACDEF', 'ACDEFG',
'ACDEG', 'ACDF', 'ACDFG', 'ACDG', 'ACE', 'ACEF', 'ACEFG', 'ACEG',
'ACF', 'ACFG', 'ACG', 'AD', 'ADE', 'ADEF', 'ADEFG', 'ADEG',
'ADF', 'ADFG', 'ADG', 'AE', 'AEF', 'AEFG', 'AEG', 'AF', 'AFG',
'AG', 'B', 'BC', 'BCD', 'BCDE', 'BCDEF', 'BCDEFG', 'BCDEG',
'BCDF', 'BCDFG', 'BCDG', 'BCE', 'BCEF', 'BCEFG', 'BCEG', 'BCF',
'BCFG', 'BCG', 'BD', 'BDE', 'BDEF', 'BDEFG', 'BDEG', 'BDF',
'BDFG', 'BDG', 'BE', 'BEF', 'BEFG', 'BEG', 'BF', 'BFG', 'BG',
'C', 'CD', 'CDE', 'CDEF', 'CDEFG', 'CDEG', 'CDF', 'CDFG', 'CDG',
'CE', 'CEF', 'CEFG', 'CEG', 'CF', 'CFG', 'CG', 'D', 'DE', 'DEF',
'DEFG', 'DEG', 'DF', 'DFG', 'DG', 'E', 'EF', 'EFG', 'EG', 'F',
'FG', 'G'))) AND
(t10.asse_res_unicode = t11.asse_res_unicode))) AND
(t1.paper_id IN (1751, 1756, 1753, 1755, 1754))) AND
(((t1.asse_res_unicode IN
(SELECT t12.asse_res_unicode
FROM f_result_sync_im t13,
f_result_sync t12
WHERE (((t13.ques_id = 725) AND (t13.ques_answer_value_ > 0)) AND
(t12.asse_res_unicode = t13.asse_res_unicode))) AND
(t1.paper_id IN (1753, 1755, 1754))) OR
((t1.asse_res_unicode IN
(SELECT t14.asse_res_unicode
FROM f_result_sync_im t15,
f_result_sync t14
WHERE (((t15.ques_id = 660) AND
(t15.ques_answer_content IN
('AB', 'ABC', 'ABCD', 'ABD', 'AC', 'ACD', 'AD', 'B', 'BC', 'BCD', 'BD', 'C', 'CD',
'D'))) AND
(t14.asse_res_unicode = t15.asse_res_unicode))) AND
(t1.paper_id IN (1751, 1756))) OR
(t1.asse_res_unicode IN
(SELECT t16.asse_res_unicode
FROM f_result_sync t16,
f_result_sync_im t17
WHERE (((t17.ques_id = 724) AND (t17.ques_answer_value_ > 0)) AND
(t16.asse_res_unicode = t17.asse_res_unicode))) AND
(t1.paper_id IN (1753, 1755, 1754))))) AND
(((t1.asse_res_unicode IN
(SELECT t18.asse_res_unicode
FROM f_result_sync_im t19,
f_result_sync t18
WHERE (((t19.ques_id = 518) AND (t19.ques_answer_content IN ('B', 'C'))) AND
(t18.asse_res_unicode = t19.asse_res_unicode))) AND
(t1.paper_id IN (1751, 1756))) AND
((t1.asse_res_unicode IN
(SELECT t20.asse_res_unicode
FROM f_result_sync t20,
f_result_sync_im t21
WHERE (((t21.ques_id = 519) AND (t21.ques_answer_content IN ('B', 'C'))) AND
(t20.asse_res_unicode = t21.asse_res_unicode))) AND
(t1.paper_id IN (1751, 1756))) AND
(t1.asse_res_unicode IN
(SELECT t22.asse_res_unicode
FROM f_result_sync_im t23,
f_result_sync t22
WHERE (((t23.ques_id = 520) AND (t23.ques_answer_content IN ('B', 'C'))) AND
(t22.asse_res_unicode = t23.asse_res_unicode))) AND
(t1.paper_id IN (1751, 1756))))) OR
((t1.asse_res_unicode IN
(SELECT t24.asse_res_unicode
FROM f_result_sync_im t25,
f_result_sync t24
WHERE (((t25.ques_id = 650) AND
(t25.ques_answer_content IN
('A', 'AB', 'ABC', 'ABCD', 'ABD', 'AC', 'ACD', 'AD', 'B', 'BC', 'BCD', 'BD', 'C',
'CD'))) AND
(t24.asse_res_unicode = t25.asse_res_unicode))) AND
(t1.paper_id IN (1753, 1755, 1754))) AND
((t1.asse_res_unicode IN
(SELECT t26.asse_res_unicode
FROM f_result_sync_im t27,
f_result_sync t26
WHERE (((t27.ques_id = 768) AND (t27.ques_answer_value_ > 0)) AND
(t26.asse_res_unicode = t27.asse_res_unicode))) AND
(t1.paper_id IN (1753, 1755, 1754))) AND
((t1.asse_res_unicode IN
(SELECT t28.asse_res_unicode
FROM f_result_sync_im t29,
f_result_sync t28
WHERE (((t29.ques_id = 693) AND (t29.ques_answer_value_ > 0)) AND
(t28.asse_res_unicode = t29.asse_res_unicode))) AND
(t1.paper_id IN (1753))) AND
(t1.asse_res_unicode IN
(SELECT t30.asse_res_unicode
FROM f_result_sync_im t31,
f_result_sync t30
WHERE (((t31.ques_id = 695) AND (t31.ques_answer_value_ > 0)) AND
(t30.asse_res_unicode = t31.asse_res_unicode))) AND
(t1.paper_id IN (1753, 1755, 1754))))))))))))))) AND
(t1.asse_res_unicode = t0.asse_res_unicode));
一个筛选条件对应的sql
t1.asse_res_unicode IN (
SELECT t20.asse_res_unicode
FROM f_result_sync t20,
f_result_sync_im t21
WHERE ((t21.ques_id = 519) AND (t21.ques_answer_content IN ('B', 'C')) AND
(t20.asse_res_unicode = t21.asse_res_unicode) AND
t1.paper_id IN (1751, 1756)
)
3)查看执行计划
explain基本理解
每个筛选条件都是一个子查询,其中都关联了两个表f_result_sync_im、f_result_sync,关联字段为paper_id;
oracle --> explain plan for [select 语句]
mysql --> explain [select 语句]
postgrSQL --> explain analyse [select 语句]
执行explain analyse + [select 语句],可以看到执行计划如下图,由于有HashAggregate的优化,子查询会被转换为常规的连接方法,即下面看到的hash join ,
但在每个子查询中还是能看到都对f_result_sync作了全表扫描:

1.3.1.2. 优化方案
1.去掉中间表 f_result_sync(将 paper_id 加入 f_result_sync_im 表)
2.在dsp_dataset_reasult上创建 dataset_id 和 asse_res_unicode 的 联合索引
3.在f_result_sync_im 上添加索引,包含字段 asse_res_unicode、paper_id、ques_id、4.ques_answer_content消除了 全表扫描
再看执行计划如下:

1.3.1.3. 优化成果
优化后的 sql,执行时间从 7 +s 减少到了 3.2s 左右。
1.3.2. 第二阶段:查询过程优化
1.3.2.1. 问题分析
即使是对select语句和表索引做了调整,由于汇总变量的查询所关联的答题详情表数据量比较大,并且字段很多,在样本集数据量也很大的情况下,复杂筛选条件的变量消耗的查询时间还是太长了。
于是有了第二阶段的优化方案。
1.3.2.2. 优化方案
采用临时表降低数量级(由于最后的测试结果不理想,并未继续采用)
每次抽样将相关数据从原表(f_result_sync_im)中把数据抽取出来,通过“create temp table ”建一张会话级的临时表,并添加 需要的索引,后续操作都基于这张临时表进行。
抽样得到的样本集同样建一张临时表来存储。
这样,执行汇总变量查询时关联的表从“千万”级降低到“十万”级。
1.3.2.3. 结论(优缺点)
1.优点–汇总变量查询速度大幅提升
降低数量级以后,count 操作的耗时可以从 “s”级 减少到 “ms”级。
2.缺点
1)临时表相对于实表具有不稳定性。临时表是基于会话的,在测试多线程抽样的过程中,会出现找不到临时表的问题,导致计算失败。由此得出结论:多线程运行的情况难以保证数据库连接会话的持续、稳定;
2)大量的数据库建表操作导致数据库服务器cpu吃不消。两用户20线程做抽样计算时,有的线程直接请求数据库连接超时,导致计算失败。
因为对cpu的消耗过高和计算失败的致命影响,此优化方案被弃用。
1.3.3. 第三阶段:抽样优化
1.3.3.1. 问题分析
抽样的过程并不算慢,但是样本集入库慢
抽样得到的样本数据是通过执行一个超长的insert语句插入到同一张表的,如果一个样本集中有20w数据,这条语句的执行时间大概是5s +
1.3.3.2. 优化方案
1.抽样改为用postgreSQL扩展python实现
1)postgreSQL扩展编程语言简介
postgreSQL扩展编程语言介绍
PostgreSQL是一个开放的数据库,开放性表现在支持自定义数据类型、索引方法、索引、操作符、聚合、窗口、服务端编程语言等等。
我们的抽样过程及通常应用开发的思路都是这样:编程语言,通过对应的数据库驱动,连接到数据库,如果要实现一些数据的处理时,需要将数据下拉到客户端,在客户端的语言中进行处理。
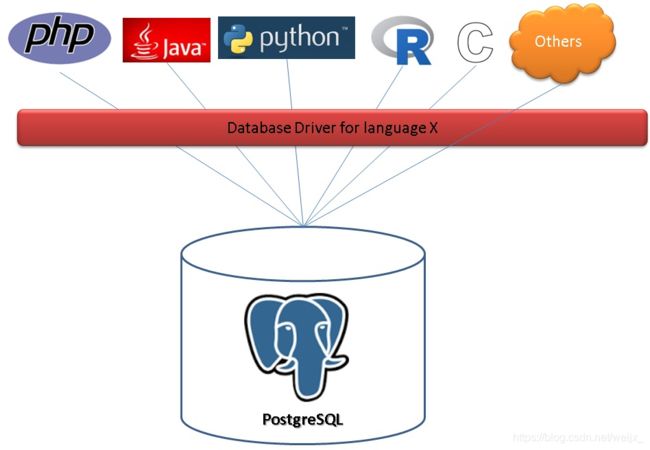
而PostgreSQL还可以这样使用:把编程语言和数据库融为一体,你可以把程序放到数据库里面去执行,这样的话数据库几乎可以做任何事情(只要程序能做的事情,数据库都可以做)。
2)扩展步骤
a.安装扩展语言:
只需要 create extension language_name 即可,目前系统自带的语言包括python, perl, tcl, plpgsql;
b.创建服务端函数
create or replace function 函数名(参数名 参数类型,....) returns [setof] 返回类型 as
$$
...扩展语言的代码, 根据对应的语言语法来写...
$$
language 扩展语言(如plpgsql) ;
抽样功能实现 展开源码
2.unlogged table的使用
临时样本集不再插入到同一张大表,而是抽样完成后创建unlogged table来存储;
PostgreSQL有一种介于正常表和临时表之间的类型表,称之为unlogged表,在该表新建的索引也属于unlogged,
该表在写入数据时候并不将数据写入到持久的write-ahead log文件中,在数据库异常关机或者异常崩溃后该表的数据会被truncate掉,
但是在写入性能上会比正常表快几倍。
1.3.3.3. 优化成果
抽样的耗时从6-7s减少为1s;
多线程抽样时数据库服务器cpu占用降低。