分布式ID常用方案——UUID、MySQL、Redis、ZooKeeper、雪花算法、美团Leaf……
背景
原文地址:https://duktig.cn/archives/85/
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。如在美团点评的金融、支付、餐饮、酒店、猫眼电影等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息,数据库的自增ID显然不能满足需求;特别一点的如订单、骑手、优惠券也都需要有唯一ID做标识。此时一个能够生成全局唯一ID的系统是非常必要的。
概括下来,那业务系统对ID号的要求有哪些呢?
- 全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求。
- 趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
- 什么是递增? 如:第一次生成的ID为12,下一次生成的ID是13,再下一次生成的ID是14。这个就是生成ID递增。
- 什么是趋势递增? 如:在一段时间内,生成的ID是递增的趋势。如:再一段时间内生成的ID在【0,1000】之间,过段时间生成的ID在【1000,2000】之间。但在【0-1000】区间内的时候,ID生成有可能第一次是12,第二次是10,第三次是14。
- 单调递增:保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求。
- 信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,会需要ID无规则、不规则。
有时候也会要求含时间戳,这样就能够在开发中快速了解这个分布式id的生成时间。
上述123对应三类不同的场景,3和4需求还是互斥的,无法使用同一个方案满足。
同时除了对ID号码自身的要求,业务还对ID号生成系统的可用性要求极高,想象一下,如果ID生成系统瘫痪,整个美团点评支付、优惠券发券、骑手派单等关键动作都无法执行,这就会带来一场灾难。
ID号生成系统的可用性要求
- 高可用:发一个获取分布式ID的请求,服务器就要保证99.999%的情况下给我创建一个唯一分布式ID。
- 低延迟:发一个获取分布式ID的请求,服务器就要快,极速。
- 高QPS:假如并发一口气10万个创建分布式ID请求同时杀过来,服务器要顶的住且一下子成功创建10万个分布式ID。
源码参看:https://github.com/duktig666/distributed-programme
常用方案
- UUID
- MySQL主键自增
- Redis(原子操作INCR和INCRBY)
- 雪花算法(twitter)
- 基于Zookeeper生成全局id
- MongoDb的ObjectId
- 美团点评——leaf
- Leaf-segment数据库方案
- Leaf-snowflake方案
- 百度开源的分布式唯一ID生成器UidGenerator
- 滴滴 Tinyid
UUID
UUID(Universally Unique Identifier)的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符,示例:
550e8400-e29b-41d4-a716-446655440000,到目前为止业界一共有5种方式生成UUID,详情见IETF发布的UUID规范 A Universally Unique IDentifier (UUID) URN Namespace。
优点:
- 代码实现简单
- UUID可以实现唯一性
- 性能非常高(本地生成,没有网络消耗)。
缺点:
-
每次生成的ID是无序的,无法保证趋势递增
-
ID本事无业务含义,不可读
-
不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。
-
信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
-
ID作为主键时在特定的环境会存在一些问题,比如做DB主键的场景下,UUID就非常不适用:
① MySQL官方有明确的建议主键要尽量越短越好[4],36个字符长度的UUID不符合要求。
All indexes other than the clustered index are known as secondary indexes. In InnoDB, each record in a secondary index contains the primary key columns for the row, as well as the columns specified for the secondary index. InnoDB uses this primary key value to search for the row in the clustered index.If the primary key is long, the secondary indexes use more space, so it is advantageous to have a short primary key.
② 对MySQL索引不利:如果作为数据库主键,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能。
应用场景:
- 类似生成token令牌的场景
- 不适用一些要求有趋势递增的ID场景
实现:
- 使用JDK1.5提供的
UUID类
UUID uuid = UUID.randomUUID();
System.out.println(uuid); // 0e070a22-0e2f-422e-96ca-f63987dadba5
这样的UUID还是比较长的,36个字符。
- 可以使用Hutool的 IdUtil 快速实现简单的UUID。
String simpleUUID = IdUtil.simpleUUID();
System.out.println(simpleUUID); // 99407162a2fb48a1a3209dd9f04e5ccb
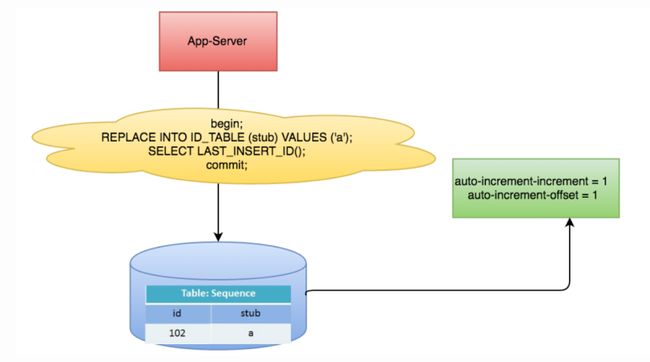
MySQL主键自增
利用给字段设置
auto_increment_increment和auto_increment_offset来保证ID自增,每次业务使用下列SQL读写MySQL得到ID号。
begin;
REPLACE INTO Tickets64 (stub) VALUES ('a');
SELECT LAST_INSERT_ID();
commit;
优点:
- 非常简单,利用现有数据库系统的功能实现,成本小
- 查询效率高
- ID号单调自增,可以实现一些对ID有特殊要求的业务
缺点:
- 强依赖DB,存在单点问题,如果mysql挂了,就没法生成ID了(配置主从复制可以尽可能的增加可用性,但是数据一致性在特殊情况下难以保证。主从切换时的不一致可能会导致重复发号)
- 数据库压力大,高并发抗不住(ID发号性能瓶颈限制在单台MySQL的读写性能)
MySQL多实例主键自增
这个方案就是解决mysql的单点问题,在auto_increment基础上,设置step步长。
在分布式系统中我们可以多部署几台机器,每台机器设置不同的初始值,且步长和机器数相等。比如有两台机器。设置步长step为2,TicketServer1的初始值为1(1,3,5,7,9,11…)、TicketServer2的初始值为2(2,4,6,8,10…)。这是Flickr团队在2010年撰文介绍的一种主键生成策略(Ticket Servers: Distributed Unique Primary Keys on the Cheap )。如下所示,为了实现上述方案分别设置两台机器对应的参数,TicketServer1从1开始发号,TicketServer2从2开始发号,两台机器每次发号之后都递增2。
TicketServer1:
auto-increment-increment = 2
auto-increment-offset = 1
TicketServer2:
auto-increment-increment = 2
auto-increment-offset = 2
假设我们要部署N台机器,步长需设置为N,每台的初始值依次为0,1,2…N-1那么整个架构就变成了如下图所示:

优点:
- 解决了单点问题
缺点:
- 一旦把步长定好后,系统水平扩展比较困难
- ID没有了单调递增的特性,只能趋势递增,这个缺点对于一般业务需求不是很重要,可以容忍。
- 数据库压力还是很大,每次获取ID都得读写一次数据库,只能靠堆机器来提高性能。
应用场景:
- 数据不需要扩容的场景
Redis生成方案
利用redis的incr原子性操作自增,一般算法为: 年份 + 当天距当年第多少天 + 天数 + 小时 + redis自增
优点:
- 有序递增,可读性强
缺点:
- 占用带宽,每次要向redis进行请求
- 存在单点问题,如果集群部署,复杂而如果单单只为了生成ID,得不偿失
算法可以调整为 就一个 redis自增,不需要什么年份,多少天等。
关于Redis实现分布式唯一ID的方案,后续会专门写一篇文章来介绍……
Redis构建分布式唯一ID生成器
ZooKeeper生成方案
ZooKeeper分布式ID生成,原理是利用ZooKeeper的临时有序节点,生成全局唯一的ID。
多个客户端同时创建同一节点,zk保证了能有序的创建,创建成功并返回的path类似于/root/generateid0000000001酱紫的,可以看到是顺序有规律的,能较好的解决这个问题,缺点是,会依赖于zk。
关于ZooKeeper实现分布式唯一ID的方案,后续会专门写一篇文章来介绍……
ZooKeeper 构建分布式唯一ID生成器
雪花(snowflake)算法
Twitter的分布式自增ID算法snowflake,这种方案大致来说是一种以划分命名空间(UUID也算,由于比较常见,所以单独分析)来生成ID的一种算法,这种方案把64-bit分别划分成多段,分开来标示机器、时间等,比如在snowflake中的64-bit分别表示如下图所示:
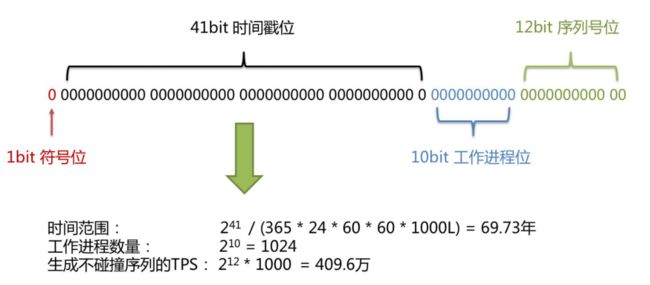
分析:
- 1bit不用,因为二进制中最高位是符号位,1表示负数,0表示正数。生成的id一般都是用整数,所以最高位固定为0。
- 41-bit的时间可以表示
(1L<<41)/(1000L*3600*24*365)=69年的时间 - 10-bit机器可以分别表示1024台机器。如果我们对IDC划分有需求,还可以将10-bit分5-bit给IDC(DataCenterId),分5-bit给工作机器(Workerld)。这样就可以表示32个IDC,每个IDC下可以有32台机器,可以根据自身需求定义。
- 12个自增序列号可以表示2^12个ID,理论上snowflake方案的QPS约为409.6w/s,这种分配方式可以保证在任何一个IDC的任何一台机器在任意毫秒内生成的ID都是不同的。
SnowFlake可以保证:
- 所有生成的ID按时间趋势递增。
- 整个分布式系统内不会产生重复id(因为有DataCenterId和Workerld来做区分)
Twitter的分布式雪花算法SnowFlake ,经测试snowflake 每秒能够产生26万个自增可排序的ID
- Twitter的SnowFlake生成ID能够按照时间有序生成。
- SnowFlake算法生成ID的结果是一个64bit大小的整数, 为一个Long型(转换成字符串后长度最多19)。
- 分布式系统内不会产生ID碰撞(由datacenter和workerld作区分)并且效率较高。
分布式系统中,有一些需要使用全局唯一ID的场景, 生成ID的基本要求:
- 在分布式的环境下必须全局且唯一 。
- 一般都需要单调递增,因为一般唯一ID都会存到数据库,而Innodb的特性就是将内容存储在主键索引树上的叶子节点而且是从左往右,递增的,所以考虑到数据库性能,一般生成的ID也最好是单调递增。 为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点, 首先他相对比较长, 另外UUID一般是无序的。
- 可能还会需要无规则,因为如果使用唯一ID作为订单号这种,为了不然别人知道一天的订单量是多少,就需要这个规则。
优点:
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
- 可以根据自身业务特性分配bit位,非常灵活。
缺点:
- 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
- 在单机上是递增的,但是由于设计到分布式环境,每台机器上的时钟不可能完全同步,有时候会出现不是全局递增的情况。(此缺点可以认为无所谓,一般分布式ID只要求趋势递增,并不会严格要求递增,90%的需求都只要求趋势递增)
想解决 【雪花算法 时钟回拨问题】 可以参看并使用美团的 Leaf 。
实现:
可使用Hutool提供的 IdUtil 快速实现雪花算法。
/**
* description:Hutool的雪花算法实现
*
* 可以使用Hutool默认提供的方法 IdUtil.getSnowflake 实现雪花算法,一般使用此即可。可根据情况传入 5位dataCenterId 和 5位workerId
*
* 如果使用 IdUtil.createSnowflake 使用雪花算法,需要自行维护单例模式(不同的Snowflake对象创建的ID可能会有重复)。
* 一个比较好的选择是交由 Spring 管理(默认单例)
*
* @author RenShiWei
* Date: 2021/7/18 17:48
**/
@Slf4j
public class HutoolSnowflake {
public static void main(String[] args) {
Snowflake snowflake = IdUtil.getSnowflake(1, 1);
for (int i = 0; i < 1000; i++) {
long id = snowflake.nextId();
System.out.println(id);
}
}
}
雪花算法源码分析参看:雪花算法源码
Leaf——美团点评分布式ID生成系统
Leaf这个名字是来自德国哲学家、数学家莱布尼茨的一句话: >There are no two identical leaves in the world > “世界上没有两片相同的树叶”
综合对比上述几种方案,每种方案都不完全符合美团的要求。所以Leaf分别在上述 数据库自增id 和 雪花算法 方案上做了相应的优化,实现了 Leaf-segment 和 Leaf-snowflake 方案。
GitHub地址:https://github.com/Meituan-Dianping/Leaf
技术文档:https://tech.meituan.com/2017/04/21/mt-leaf.html
UidGenerator——百度
参看其GitHub:https://github.com/baidu/uid-generator
滴滴(Tinyid)
参看其GitHub:https://github.com/didi/tinyid
参考:
- Leaf——美团点评分布式ID生成系统 (总结了UUID、数据库自增方案、雪花算法的优缺点,并且总结Leaf的算法优化逻辑;基本已经可以涵盖常用分布式ID的问题,除了Redis没有进行分析)
- 一线大厂的分布式唯一 ID 生成方案是什么样的 (有redis的分析,也分析了Leaf-segment数据库方案)
- 分布式id生成策略,我居然和面试官扯了一个半小时? (有Redis和雪花算法实现分布式ID的代码实现)
- Spring Cloud 学习笔记(3 / 3) (文末有分布式ID问题的分析,对应于尚硅谷周阳讲的SpringCloud笔记)
- Leaf的GitHub地址
- UidGenerator的GitHub地址
- 一口气说出9种分布式ID生成方式,阿里面试官都懵了