风格迁移数据集_数据和结构越大越精准,谷歌提出CV领域最先进的迁移学习模型BiT...
来源|新智元加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
【极市导读】近日,Google推出计算机视觉领域最先进的迁移学习模型Bigtransfer (BiT) 。BigTransfer (BiT) 是一组经过预先训练的模型,在新数据集上进行简单的迁移学习就能获得优秀的性能。
在这篇文章中,我们将带你了解如何使用BigTransfer(BiT)。
ImageNet预训练的ResNet50s是目前提取图像表示的行业标准。BigTransfer(BiT)论文中分享的模型,即使每个类别只有几个例子,也能获得不错的效果,而且在许多任务中都取得了优于ResNet50s表现。
你可以在TFHub中找到在ImageNet和ImageNet-21k上预训练的BiT模型,你可以像用Keras Layers一样,轻松使用TensorFlow2 SavedModels,从标准的ResNet50到ResNet152x4(152层深,比典型的ResNet50宽4倍)都有,ResNet152x4适合有更大的计算和内存预算、对精度要求较高的用户。

图1:X轴显示的是每类图像的使用数量。上面蓝色的曲线来自BiT-L模型,而下面的曲线是在ImageNet上预训练的ResNet-50(ILSVRC-2012)。
BigTransfer「大迁移模型」大在哪?
在我们深入了解如何使用模型的细节之前,我们先要理解BigTransfer是如何训练这些模型的。
上游训练
精髓就在名字里。我们在大数据集上更有效地训练大架构。
在此之前,很少有论文能够从大数据集上训练得到更好的结果,比如ImageNet-21k(14M图像,比常用的ImageNet大10倍)。
大数据集
随着数据集大小的增加,BigTransfer模型的最佳性能也会随之增加。
大架构
为了充分利用大数据集,我们需要足够大的架构。
例如,在JFT上训练一个ResNet50(有300M的图像),相对于在ImageNet-21k(14.8M的图像)上训练ResNet50,并不一定能提高性能。但当训练更大的模型如ResNet152x4时,使用JFT的性能始终要优于ImageNet-21k。
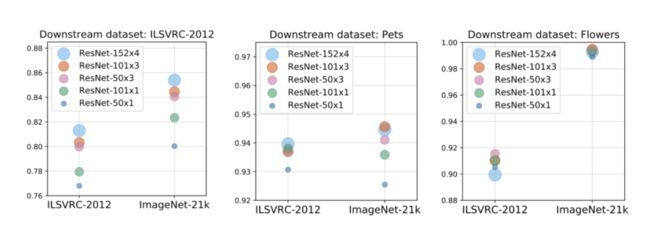
图2:较大的上游数据集(x轴)和模型大小(气泡大小/颜色)对下游任务性能的影响。单独使用更大的数据集或更大的模型可能会伤害性能。两者需要同步提高。
而且,在较大的数据集上进行预训练时,训练时间也是很重要的。在ImageNet上训练90个epochs是标准的,但如果在ImageNet-21k等较大的数据集上进行相同步数的训练(然后在ImageNet上进行微调),其性能会比直接在ImageNet上训练的效果要差。
GroupNorm和权重标准化
最后,我们使用GroupNorm与Weight Standardisation相结合的GroupNorm,而不是BatchNorm。
由于我们的模型很大,所以我们只能在每个加速器(如GPU或TPU芯片)上贴合几个图像。当每个加速器上的图像数量太少时,BatchNorm的表现会很差。
GroupNorm就没有这个问题,当我们将GroupNom和Weight Standardisation结合起来,我们会发现GroupNorm在大的批处理规模下的扩展性很好,甚至超过了BatchNorm。
下游微调
此外,在数据效率和计算成本方面,下游微调是很便宜的,每类只需几个例子我们的模型就能达到良好的性能。
我们还设计了一种超参数配置,称之为 "BiT-HyperRule",它在许多任务上都有相当好的表现,而不需要进行昂贵的超参数扫描。
BiT-HyperRule:我们的超参数启发式配置
你可以通过更昂贵的超参搜索来获得更好的结果,但BiT-HyperRule可以在数据集上获得一个较好的初始化参数。
在BiT-HyperRule中,我们使用SGD,初始学习率为0.003,动量为0.9,批处理量为512。在微调过程中,我们在30%、60%和90%的训练步骤中,将学习率依次衰减10倍。
作为数据预处理,我们对图像进行大小调整,随机裁剪,然后进行随机水平翻转(详见表1)。
我们对所有任务都做随机裁剪和水平翻转,除了那些破坏标签语义的动作。例如,我们不对计数任务进行随机裁剪,也不对要预测物体方向的任务进行随机水平翻转(图3)。

表1: 下行调整大小和随机裁剪细节。如果图像较大,我们会将其调整到一个较大的固定尺寸,以便在更高的分辨率上进行微调,从中受益。

图3:CLEVR计数示例。这里的任务是统计图像中的小圆柱体或红色物体的数量。我们不会应用随机裁剪,因为这可能会裁剪出我们想要统计的对象,但我们应用随机水平翻转,因为这不会改变图像中我们关心的对象数量(因此不会改变标签)
我们根据数据集的大小(表2),确定时间表的长度和是否使用MixUp。

图4:MixUp采取了成对的例子,并对图像和标签进行了线性组合。这些图像来自于数据集 tf_flowers

表2: 关于下行计划长度和我们何时使用MixUp的细节
研究人员根据试验结果确定了这些超参数启发式方法,有时间(也有计算资源)的话你可以去尝试一下,看能否达到这么好的效果。
参考链接:
https://blog.tensorflow.org/2020/05/bigtransfer-bit-state-of-art-transfer-learning-computer-vision.html
推荐阅读:谷歌又放大招:视觉效果完胜其他SOTA的风格迁移网络,手机端可达实时4K
CVPR 2020 Oral:一行代码提升迁移性能,中科院计算所研究生一作
三维迁移学习

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:AI移动应用-小极-北大-深圳),即可申请加入AI移动应用极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~ 