小甲鱼Python教程学习笔记(一)
P3用Python设计第一个游戏
print('----------------我爱小甲————————————————')
temp = input("不妨猜一下小甲鱼心里想的是那个数字:")
guess = int(temp)
if guess == 8:
print("正确")
print("恭喜你,猜中了")
else:
print("错了,我猜的是8")
print("游戏结束,不玩了")
>>>
============ RESTART: D:/Desktop/2021暑假python学习/P3用Python设计一个小游戏.py ============
----------------我爱小甲————————————————
不妨猜一下小甲鱼心里想的是那个数字:1
错了,我猜的是8
游戏结束,不玩了
>>>
============ RESTART: D:/Desktop/2021暑假python学习/P3用Python设计一个小游戏.py ============
----------------我爱小甲————————————————
不妨猜一下小甲鱼心里想的是那个数字:8
正确
恭喜你,猜中了
游戏结束,不玩了

BIF == built in Functions 内置函数
查看内置函数
>>> dir(__builtins__)
['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException', 'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning', 'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError', 'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning', 'EOFError', 'Ellipsis', 'EnvironmentError', 'Exception', 'False', 'FileExistsError', 'FileNotFoundError', 'FloatingPointError', 'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError', 'ImportWarning', 'IndentationError', 'IndexError', 'InterruptedError', 'IsADirectoryError', 'KeyError', 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'ModuleNotFoundError', 'NameError', 'None', 'NotADirectoryError', 'NotImplemented', 'NotImplementedError', 'OSError', 'OverflowError', 'PendingDeprecationWarning', 'PermissionError', 'ProcessLookupError', 'RecursionError', 'ReferenceError', 'ResourceWarning', 'RuntimeError', 'RuntimeWarning', 'StopAsyncIteration', 'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError', 'TimeoutError', 'True', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning', 'WindowsError', 'ZeroDivisionError', '__build_class__', '__debug__', '__doc__', '__import__', '__loader__', '__name__', '__package__', '__spec__', 'abs', 'all', 'any', 'ascii', 'bin', 'bool', 'breakpoint', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'exec', 'exit', 'filter', 'float', 'format', 'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip']
>>>
查看函数方法:help(input)
>>> help(input)
Help on built-in function input in module builtins:
input(prompt=None, /)
Read a string from standard input. The trailing newline is stripped.
The prompt string, if given, is printed to standard output without a
trailing newline before reading input.
If the user hits EOF (*nix: Ctrl-D, Windows: Ctrl-Z+Return), raise EOFError.
On *nix systems, readline is used if available.
P4变量和字符串
变量的定义规划:
不以数字开头
变量的值是会被替换的,变量的值取决于最后一个操作
>>> x=4
>>> print(x)
4
>>> x=3
>>> print(x)
3
>>>
变量之间可以传递
>>> x=3
>>> y=5
>>> x=y
>>> print(x)
5
交换变量的值
>>> x=2
>>> y=6
>>> x,y=y,x
>>> print(x,y)
6 2
>>>
Python字符串的编写方式主要有
Single quotes
>>> print('I love China.')
I love China.
Double quotes
>>> print("I love China.")
I love China.
Triple quoted
单引号和双引号都必须成双成对
>>> print('Let's go!')
SyntaxError: invalid syntax
>>> print("Let's go!")
Let's go!
>>> print('"Life is short, you need python."')
"Life is short, you need python."
>>>
同时含有单引号和双引号
使用转义字符
>>> print('"Life is short, you need python."')
"Life is short, you need python."
>>> print('\"Life is short, let\'s learn python.\"')
"Life is short, let's learn python."
>>> print("\"Life is short, let\'s learn python.\"")
"Life is short, let's learn python."
>>>
原始字符串
>>> print("D:\three\two\one\now")
D: hree wo\one
ow
>>>
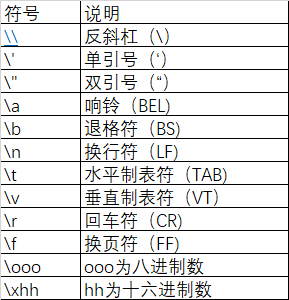
>>> print("D:\\three\\two\\one\\now")#对反斜杠转义
D:\three\two\one\now
使用原始字符串,在字符串前面加r
>>> print(r"D:\three\two\one\now")
D:\three\two\one\now
反斜杠不能放在末尾

\ &
\ / \
\ * *
\ * *
\ * *
\ *******
\ *********
\ ***********
\ *************
\ * *
\ * *
\ *****
\ *******
\ *********
长字符串——Triple quoted
‘’‘前呼后应’’’
“”“成双成对”""

字符串的加法和乘法
>>> 520+1314
1834
>>> '520'+'1314'
'5201314'
字符串相加,也叫拼接
P7改进我们的小游戏
- 当用户猜错时,程序应该给出提示
- 提供多次机会给用户 每次运行程序,
- 答案是随机的
循环语句
>>> while counts > 0:
print("fansong")
counts=counts-1
fansong
fansong
fansong
random:随机数的产生
>>> import random #导入模块
>>> x=random.randint(20,100)#随机产生一个20~100的数字
>>> print(x)
84
>>>
"""用Python设计第一个游戏"""
import random #导入模块
counts = 3
answer = random.randint(1,10) #在1~10内随机生成一个整数
while counts>0:
temp = input("不妨猜一下小甲鱼心里想的是那个数字:")
guess = int(temp)
if guess == answer:
print("正确")
print("恭喜你,猜中了")
break
else:
if(guess<answer):
print("小啦~")
else:
print("大啦~")
counts=counts-1
print("游戏结束,不玩了")
>>>
============ RESTART: D:\Desktop\2021暑假python学习\P3用Python设计一个小游戏.py ============
不妨猜一下小甲鱼心里想的是那个数字:5
大啦~
不妨猜一下小甲鱼心里想的是那个数字:4
正确
恭喜你,猜中了
游戏结束,不玩了
random生成的伪随机数都是可以被重现的,要实现对伪随机数的攻击就要拿到他的种子,默认情况下,random使用当前操作系统的系统时间来作为随机数的种子
random.getstate()可以获取随机数种子加工后的随机数生成器的内部状态。
>>> x=random.getstate()
>>> print(x)
>>> random.randint(1,10)
4
>>> random.randint(1,10)
4
>>> random.randint(1,10)
3
>>> random.randint(1,10)
9
>>> random.randint(1,10)
3
>>> random.randint(1,10)
3
>>> random.setstate(x)
>>> random.randint(1,10)
4
>>> random.randint(1,10)
4
>>> random.randint(1,10)
3
>>> random.randint(1,10)
9
>>> random.randint(1,10)
3
>>> random.randint(1,10)
3
P9数字类型
整数(integers)
浮点数(floating point numbers)
>>> 0.1+0.2
0.30000000000000004
Python的浮点数之所以具有误差,是因为,Python和C语言一样都是采用IEEE754的标准来储存浮点数的,所以会产生一定的误差
>>> 0.3 == 0.1+0.2
False
但实际中,对精度要求很高,为了解决这个问题,就需要借助decimal模块。
>>> import decimal
>>> a=decimal.Decimal('0.1') #实例化对象
>>> b=decimal.Decimal('0.2') #实例化对象
>>> print(a+b)
0.3
>>> c=decimal.Decimal('0.3') #实例化对象
>>> print(c)
0.3
>>> a+b==c
True
>>>
‘E记法’:科学计数法
>>> 0.00008
8e-05
>>>
复数(complex numbers)
>>> 5+8j
(5+8j)
>>> x=5+8j
>>> x.real
5.0
>>> x.imag
8.0

x//y:取比目标结果小的最大整数,向下取整
>>> 3/2
1.5
>>> -3/2
-1.5
>>> 3//2
1
>>> -3//2
-2
>>>
divmod
>>> divmod(3,2)
(1, 1)
>>> divmod(-3,2)
(-2, 1)
int
>>> int(3.14)
3
>>> int(-3.14)
-3
>>> int(9.999)
9
>>>
float
>>> float("3.14")
3.14
>>> float(250)
250.0
>>> float('1E8')
100000000.0
complex
>>> complex(5+9j)
(5+9j)
>>> complex('5+9j')
(5+9j)
>>> complex("5+9j")
(5+9j)
pow与x**y
>>> pow(2,3)
8
>>> pow(2,1/2)
1.4142135623730951
>>> 2**3
8
>>> 2**1/2
1.0
>>> 2**(1/2)
1.4142135623730951
但pow支持第三个参数
入过传入第三个参数,会将幂运算的结果与第三个参数进行取余运算
>>> pow(2,3,5)
3
>>> 2**3%5
3
P11布尔类型
布尔类型只有:False or True
bool()
对于字符串来说,只有空字符的结果是False,其余都为True
>>> bool(False)
False
>>> bool('False')
True
>>> bool(' ')
True
>>> bool('')
False
无论数值是所少,值为0的结果才是False,其余都为True
>>> bool(0)
False
>>> bool(0.0)
False
>>> bool(0j)
False
>>> bool(1)
True
>>> bool(0.1)
True
>>> bool(1j)
True
以下涵盖了值为False的大多数情况
- 定义为False的对象:
None和False - 值为0的数字类型:
0,0.0,0j,Decimal(0),Fraction(0,1)分子为0,分母为1的有理数 - 空的序列和集合:
",().[].{}.set(),range(0)
>>> 1==True
True
>>> 0==False
True
>>> True+False
1
>>> True-False
1
>>> True*False
0
>>> True/False
Traceback (most recent call last):
File "" , line 1, in <module>
True/False
ZeroDivisionError: division by zero
逻辑运算符/布尔运算符(Boolean Operations)
- and
- or
- not
>>> not 1
False
>>> not 0
True
>>> 1>0 and 2<1
False
>>> 1>0 and 2>1
True
>>> 1>0 or 2<1
True
>>> 1>0 or 2>1
True
>>> 1<0 or 2<1
False
>>> not True
False
>>> not False
True
>>> 3 and 4
4
>>> 5 or 6
5
>>> "FishC" and "LOVE"
'LOVE'
>>> "FishC" and 250
250
>>> (not 1) or (0 and 1) or (3 and 4) or (5 and 6) or (7 and 8 and 9)
4
>>>
>>> 0 or 0 or 4 or 6 or 9
4
or 和and 都遵循短路逻辑
短路逻辑的核心思想:从左往右,只有当第一个操作数的值无法确定逻辑运算的结果时,才对第二个操作数进行求职。
运算符优先级

>>> not 1 or 0 and 1 or 3 and 4 or 5 and 6 or 7 and 8 and 9
4
>>> 0 or 0 or 4 or 6 or 9
4
>>> 0 or 1 and not 2
False
P13谋定而后动,知止而有得
流程图(Flowchart)
流程图是一种用于表示算法或代码流程的框图组合,它以不同类型的框框代表不同的种类的程序步骤,每两个步骤之间以箭头连接起来。
优点
- 代码指导文档
- 有助于高效得程序结构
- 便于交流
name=input("你的名字:")
print("你好,"+name+"!")
>>>
============== RESTART: D:/Desktop/2021暑假python学习/P13谋定而动_知止而有得.py =============
你的名字:fansong
你好,fansong!
>>>

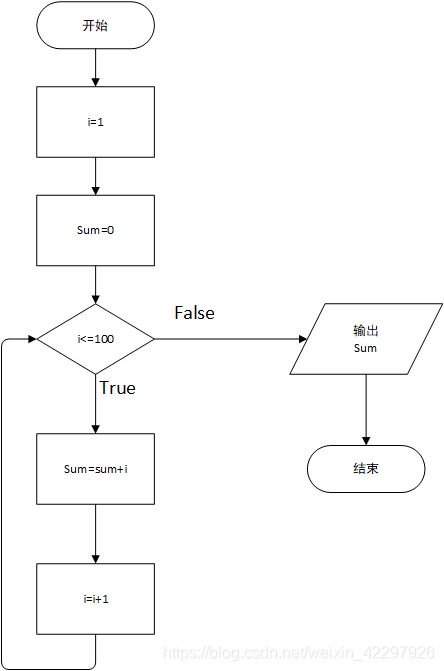
i=1
sum=0
while i<=100:
sum = sum+i
i = i+1
print(sum)
#name=input("你的名字:")
#print("你好,"+name+"!")
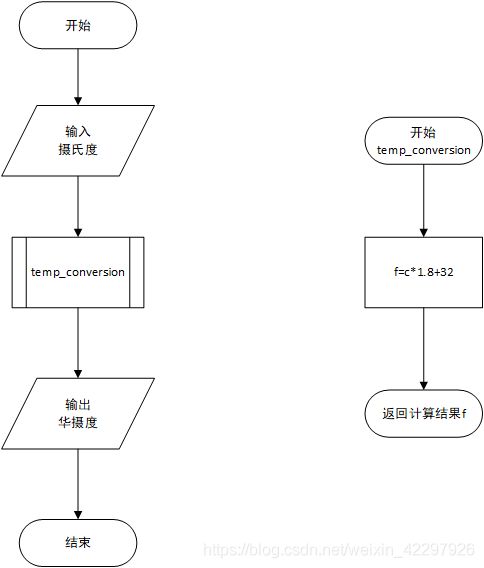
def temp_conversion(c):
f=c*1.8+32
return f
c=float(input("请输入摄氏度:"))
f=temp_conversion(c)
print("转换位华氏摄氏度是:"+str(f))
============== RESTART: D:/Desktop/2021暑假python学习/P13谋定而动_知止而有得.py =============
请输入摄氏度:22
转换位华氏摄氏度是:71.6
思维导图(mide map)
思维导图又叫心智图,是表达发散性思维的有效的图形思维工具,它简单又及其有效,是一种革命性的思维工具。
思维导图侧重于设计,流程图侧重于实现
P15了不起的分支和循环
分支和循环(branch and loop)
分支结构
1,判断一个条件,如果这个条件成立,就执行其包含的某条语句或者某个代码块
if 3>5:
print("我在里面~")
print("我也在里面~")
print("我在外面~")
2,判断一个条件:
如果条件成立,就执行其包含的某条语句或某个代码块
如果不成立,就执行另外的某条语句或某个代码块
if condition:
statement(s)
else:
statement(s)
3,判断多个条件,如果第一个条件不成立,则继续判断第二个条件,如果第二个条件还不成立,则接着判断第三个条件…
python
if condition1:
statement(s)
elif condition2:
statement(s)
elif condition3:
statement(s)
..................
score=input("请输入你的分数:")
score=int(score)
if 0<=score<60:
print("D")
elif 60<=score<80:
print("C")
elif 80<=score<90:
print("B")
elif 90<=score<100:
print("A")
elif score==100:
print("无敌")
4,在第三种的情况下添加一个else,表示上面所有的条件均不成立的情况,执行某条语句或者某个代码块
python
if condition1:
statement(s)
elif condition2:
statement(s)
elif condition3:
statement(s)
...
else:
statement(s)
5,条件成立时执行的语句 if condition else 条件不成立时执行的语句
>>> age=16
>>> if age<18:
print("未满18岁,禁止访问!")
else:
print("欢迎您回来!")
未满18岁,禁止访问!
>>> age=16
>>> print("未满18岁,禁止访问") if age<18 else print("欢迎回来")
未满18岁,禁止访问
>>>
>>> samll = 3 if 3>4 else 4
>>> print(samll)
4
>>> samll = 3 if 3<4 else 4
>>> print(small)
5
>>>
score=input("请输入你的分数:")
score=int(score)
leave=('D' if 0<=score<60 else
'C' if 60<=score<80 else
'B' if 80<=score<90 else
'A' if 90<=score<100 else
'无敌' if score==100 else "输入无效,请输入0~100之间的数字"
)
print(leave)
分支结构的嵌套(nested branches)
>>> age=18
>>> isMale=True
>>> if age<18:
print("抱歉,未满18岁,禁止访问")
else:
if isMale == True:
print("任君选购")
else:
print("抱歉,本店商品可能不适合小公举")
任君选购
>>>
continue
>>> i=0
>>> while i<10:
i+=1
if i%2==0:
continue
print(i)
1
3
5
7
9
>>>
else
i=1
while i<5:
print("循环内,i的值是",i)
i=i+1
else:
print("循环外,i的值是",i)
============== RESTART: D:/Desktop/2021暑假python学习/P13谋定而动_知止而有得.py =============
循环内,i的值是 1
循环内,i的值是 2
循环内,i的值是 3
循环内,i的值是 4
循环外,i的值是 5
>>>
实际作用:非常容易检测到循环的退出状况
day=1
while day <=7:
answer=input("今天有好好学习吗?")
if answer != "有":
break
day+=1
else:
print("非常棒,你已经坚持了七天连续学习!")
>>>
============== RESTART: D:/Desktop/2021暑假python学习/P13谋定而动_知止而有得.py =============
今天有好好学习吗?有
今天有好好学习吗?有
今天有好好学习吗?有
今天有好好学习吗?有
今天有好好学习吗?有
今天有好好学习吗?有
今天有好好学习吗?有
非常棒,你已经坚持了七天连续学习!
循环结构的嵌套(nested loop)
i=1
while i<=9:
j=1
while j<=i:
print(j,"*",i,"=",j*i,end=" ")
j+=1
print('\n')
i+=1
============== RESTART: D:/Desktop/2021暑假python学习/P13谋定而动_知止而有得.py =============
1 * 1 = 1
1 * 2 = 2 2 * 2 = 4
1 * 3 = 3 2 * 3 = 6 3 * 3 = 9
1 * 4 = 4 2 * 4 = 8 3 * 4 = 12 4 * 4 = 16
1 * 5 = 5 2 * 5 = 10 3 * 5 = 15 4 * 5 = 20 5 * 5 = 25
1 * 6 = 6 2 * 6 = 12 3 * 6 = 18 4 * 6 = 24 5 * 6 = 30 6 * 6 = 36
1 * 7 = 7 2 * 7 = 14 3 * 7 = 21 4 * 7 = 28 5 * 7 = 35 6 * 7 = 42 7 * 7 = 49
1 * 8 = 8 2 * 8 = 16 3 * 8 = 24 4 * 8 = 32 5 * 8 = 40 6 * 8 = 48 7 * 8 = 56 8 * 8 = 64
1 * 9 = 9 2 * 9 = 18 3 * 9 = 27 4 * 9 = 36 5 * 9 = 45 6 * 9 = 54 7 * 9 = 63 8 * 9 = 72 9 * 9 = 81
>>>
无论是break语句还是continue语句,它们只能作用于一层循环体
day=1
hour=1
while day <= 7:
while hour <= 8:
print("今天,我一定要坚持学习8个小时!")
hour+=1
if hour>1:
break
day+=1
>>>
============================================== RESTART: D:/Desktop/2021暑假python学习/P13谋定而动_知止而有得.py ==============================================
今天,我一定要坚持学习8个小时!
今天,我一定要坚持学习8个小时!
今天,我一定要坚持学习8个小时!
今天,我一定要坚持学习8个小时!
今天,我一定要坚持学习8个小时!
今天,我一定要坚持学习8个小时!
今天,我一定要坚持学习8个小时!
>>>
for循环
for 变量 in 可迭代对象:
statement(s)
迭代
>>> for each in "FishC":
print(each)
F
i
s
h
C
>>>
>>> i=0
>>> while i<len('FishC'):
print("FishC"[i])
i+=1
F
i
s
h
C
>>>
利用for循环,从1加到1000000
>>> for i in 1000000:
sum+=i
Traceback (most recent call last):
File "" , line 1, in <module>
for i in 1000000:
TypeError: 'int' object is not iterable
>>>
range:生成一个数字序列,有以下三种形式,但是,不管使用哪一种,参数必须为整形。
- range(stop)
产生从0到stop跨度为1的整数,但不包含stop - range(start,stop)
产生从start到stop跨度为1的整数,但不包含stop - range(start,stop,step)
产生从start到stop跨度为step的整数,但不包含stop
>>> for i in range(10,20,5):
print(i)
10
15
>>> for i in range(10,16,1):
print(i)
10
11
12
13
14
15
>>> for i in range(10,16):
print(i)
10
11
12
13
14
15
>>>
>>>> for i in range(2,-2,-1):
print(i)
2
1
0
-1
>>> for i in range(-2,-8,-1):
print(i)
-2
-3
-4
-5
-6
-7
>>>
>>> sum=0
>>> for i in range(1000001):#1+2+....1000001
sum+=i
>>> print(sum)
500000500000
>>>
#找到10以内的所有素数
>>> for i in range(2,11):
for x in range(2,i):
if i%x == 0:
print(i,"=",x,"*",i//x)
break
else:
print(i,"是一个素数")
2 是一个素数
3 是一个素数
4 = 2 * 2
5 是一个素数
6 = 2 * 3
7 是一个素数
8 = 2 * 4
9 = 3 * 3
10 = 2 * 5
P20列表
列表:菜篮子,而不是只能放一种食品的袋子
创建列表:
列表可以容纳不同类型的数据
>>> [1,2,3,4,5]
[1, 2, 3, 4, 5]
>>> [1,2,3,4,5,"abcd"]
[1, 2, 3, 4, 5, 'abcd']
>>> test=[1,2,3,4,5,"abcd"]
>>> print(test)
[1, 2, 3, 4, 5, 'abcd']
>>>
序列:序列是python中最常见得一个数据结构,字符串,列表都是序列
>>> test=[1,2,3,4,5,"abcd"]
>>> print(test)
[1, 2, 3, 4, 5, 'abcd']
>>> for each in test:
print(each)
1
2
3
4
5
abcd
>>>
列表的下表索引
>>> test=[1,2,3,4,5,"abcd"]
>>> length=len(test)
>>> for i in range(length):
print(test[i])
1
2
3
4
5
abcd
>>>
#获取列表中的最后一个元素
>>> test[length-1]
'abcd'
>>> test[-1]
'abcd'
>>>
列表切片:一次性获取多个元素
Python的索引是从0开始的
>>> test=[1,2,3,4,5,6,7,"abcd"]
>>> test[1:3]
[2, 3]
>>> test[0:3]
[1, 2, 3]
>>> test[6:]
[7, 'abcd']
>>> test[:]
[1, 2, 3, 4, 5, 6, 7, 'abcd']
>>> test[:3]
[1, 2, 3]
>>> test[2:7:2]#test[开始:结束:跨度]
[3, 5, 7]
>>> test[2:7:3]
[3, 6]
>>> test[1:7:2]
[2, 4, 6]
>>> test[0:7:2]
[1, 3, 5, 7]
>>> test[::2]
[1, 3, 5, 7]
>>> test[::]#正着来
[1, 2, 3, 4, 5, 6, 7, 'abcd']
>>> test[::-1]#倒着来
['abcd', 7, 6, 5, 4, 3, 2, 1]
>>> test[::-2]#倒着来
['abcd', 6, 4, 2]
列表的诸多方法:增/删/改/查
增:
append():在列表的末尾添加一个指定的元素
>>> heros=["钢铁侠","绿巨人"]
>>> print(heros)
['钢铁侠', '绿巨人']
>>> heros.append("黑寡妇")
>>> print(heros)
['钢铁侠', '绿巨人', '黑寡妇']
>>>
extend():可以添加一个可迭代对象
>>> heros=["钢铁侠","绿巨人"]
>>> heros.append("黑寡妇")
>>> print(heros)
['钢铁侠', '绿巨人', '黑寡妇']
>>> heros.extend(["鹰眼","灭霸","雷神"])
>>> print(heros)
['钢铁侠', '绿巨人', '黑寡妇', '鹰眼', '灭霸', '雷神']
>>>
>>>
extend()方法的参数必须是一个可迭代对象。新的内容是追加到原列表最后一个元素的后面会
切片
>>> s=[1,2,3,4,5]
>>> s[len(s):]=[6]
>>> print(s)
[1, 2, 3, 4, 5, 6]
>>> s[len(s):]=[7,8,9]
>>> print(s)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
insert(),第一个元素插入待插入的位置,第二个是待插入的元素
>>> s=[1,3,4,5]
>>> print(s)
[1, 3, 4, 5]
>>> s.insert(1,2)
>>> print(s)
[1, 2, 3, 4, 5]
>>> s.insert(0,0)
>>> print(s)
[0, 1, 2, 3, 4, 5]
>>> s.insert(len(s),6)
>>> print(s)
[0, 1, 2, 3, 4, 5, 6]
删
remove
- 如果列表中存在多个匹配的元素,那么它只会删掉第一个。
- 如果指定得元素不存在,程序会报错
>>> s=["唐僧","孙悟空","猪八戒","沙和尚","李逵"]
>>> print(s)
['唐僧', '孙悟空', '猪八戒', '沙和尚', '李逵']
>>> s.remove("李逵")
>>> print(s)
['唐僧', '孙悟空', '猪八戒', '沙和尚']
>>> s.extend(["诸葛亮","白龙马","诸葛亮"])
>>> print(s)
['唐僧', '孙悟空', '猪八戒', '沙和尚', '诸葛亮', '白龙马', '诸葛亮']
>>> s.remove("诸葛亮")
>>> print(s)
['唐僧', '孙悟空', '猪八戒', '沙和尚', '白龙马', '诸葛亮']
>>> s.remove("诸葛亮")
>>> print(s)
['唐僧', '孙悟空', '猪八戒', '沙和尚', '白龙马']
>>> s.remove("哪吒")
Traceback (most recent call last):
File "" , line 1, in <module>
s.remove("哪吒")
ValueError: list.remove(x): x not in list
>>>
pop
>>> s.pop(4)
'白龙马'
>>> print(s)
['唐僧', '孙悟空', '猪八戒', '沙和尚']
>>>
clear()
>>> s.clear()
>>> print(s)
[]
>>>
改
列表是可变的,字符串是不可变的
单个元素替换
>>> heros=["蜘蛛侠","绿巨人","黑寡妇","鹰眼","灭霸","雷神"]
>>> heros[4]="钢铁侠"
>>> print(heros)
['蜘蛛侠', '绿巨人', '黑寡妇', '鹰眼', '钢铁侠', '雷神']
>>>
>>> heros
['李逵', '林冲', '武松', '黑寡妇', '绿巨人', '蜘蛛侠']
>>> heros[heros.index("武松")]="神奇女侠"
>>> heros
['李逵', '林冲', '神奇女侠', '黑寡妇', '绿巨人', '蜘蛛侠']
多个连续元素替换
利用切片
>>> heros[3:]=["武松","林冲","李逵"]
>>> print(heros)
['蜘蛛侠', '绿巨人', '黑寡妇', '武松', '林冲', '李逵']
>>>
- 将赋值号(=)左边指定的内容删除
- 将包含在赋值符号(=)右边的可迭代对象中的片段插入左边被删除的位置
对该列表元素,从小到大排序
sort()
>>> nums=[3,4,6,5,8,7,2,3,4,85,8,5]
>>> nums.sort()
>>> print(nums)
[2, 3, 3, 4, 4, 5, 5, 6, 7, 8, 8, 85]
>>>
从大到小排序
reverse()
>>> nums.reverse()
>>> print(nums)
[85, 8, 8, 7, 6, 5, 5, 4, 4, 3, 3, 2]
>>>
>>> print(heros)
['蜘蛛侠', '绿巨人', '黑寡妇', '武松', '林冲', '李逵']
>>> heros.reverse()
>>> print(heros)
['李逵', '林冲', '武松', '黑寡妇', '绿巨人', '蜘蛛侠']
>>>
>>> nums=[3,4,6,5,8,7,2,3,4,85,8,5]
>>> nums.sort(reverse=True)
>>> nums
[85, 8, 8, 7, 6, 5, 5, 4, 4, 3, 3, 2]
>>>
查
查找某个元素的出现次数
count()
>>> nums
[85, 8, 8, 7, 6, 5, 5, 4, 4, 3, 3, 2]
>>> nums.count(8)
2
>>>
查找某个元素的索引值
index()
>>> heros.index("绿巨人")
4
>>> heros
['李逵', '林冲', '武松', '黑寡妇', '绿巨人', '蜘蛛侠']
>>> heros.index("绿巨人")
4
>>>
index(x,start,end):指定查找结束位置
>>> nums=[3,4,6,5,8,7,2,3,4,85,8,5]
>>> nums.index(8)
4
>>> nums.index(8,5,12)
10
copy()
复制一个列表
>>> nums_copy1=nums.copy()
>>> nums_copy1
[3, 4, 6, 5, 8, 7, 2, 3, 4, 85, 8, 5]
>>>
使用切片来实现
>>> nums_copy2=nums[:]
>>> nums_copy2
[3, 4, 6, 5, 8, 7, 2, 3, 4, 85, 8, 5]
以上称为浅copy(shallow copy)
列表的加法和乘法
concatenation and multiplication of list
>>> s=[1,2,3]
>>> t=[4,5,6]
>>> s+t
[1, 2, 3, 4, 5, 6]
>>> s*3
[1, 2, 3, 1, 2, 3, 1, 2, 3]
>>>
嵌套列表
nested list
>>> matrix=[[1,2,3],[4,5,6],[7,8,9]] #写法1
>>> matrix
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
>>> matrix=[[1,2,3], [4,5,6], [7,8,9]] #写法2
>>> matrix
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
>>>
访问嵌套类表
access nested list
>>> matrix=[[4,5,6],[7,8,9],[10,11,12]]
>>> matrix
[[4, 5, 6], [7, 8, 9], [10, 11, 12]]
>>> for i in matrix:
for each in i:
print(each)
4
5
6
7
8
9
10
11
12
>>> for i in matrix:
print(i)
[4, 5, 6]
[7, 8, 9]
[10, 11, 12]
>>> for i in matrix:
for each in i:
print(each,end=' ')
print()
4 5 6
7 8 9
10 11 12
>>> for i in matrix:
for each in i:
print(each,end=' ')
4 5 6 7 8 9 10 11 12
>>>
>>>
>>> matrix[0]
[4, 5, 6]
>>> matrix[0][0]
4
>>> matrix[2][2]
12
>>>
使用循环创建并初始化二维列表
>>> A=[0]*3
>>> A
[0, 0, 0]
>>> for i in range(3):
A[i]=[0]*3
>>> A
[[0, 0, 0], [0, 0, 0], [0, 0, 0]]
下面方法是错误的
>>> B=[[0]*3]*3
>>> B
[[0, 0, 0], [0, 0, 0], [0, 0, 0]]
因为
>>> A[1][1]=1
>>> A
[[0, 0, 0], [0, 1, 0], [0, 0, 0]]
>>> B[1][1]=1
>>> B
[[0, 1, 0], [0, 1, 0], [0, 1, 0]]
>>>
is
is operator
同一性运算符,检验两个对象是否指向同一个运算符
#Python对于不同对象的储存机制不同
>>> x="FishC"
>>> y="FishC"
>>> x is y
True
>>> x=[1,2,3]
>>> y=[1,2,3]
>>> x is y
False

>>> x=[1,2,3]
>>> y=[1,2,3]
>>> x is y
False
>>> A[0] is A[1]
False
>>> A[1] is A[2]
False
>>> B[0] is B[1]
True
>>> B[1] is B[2]
True
>>>
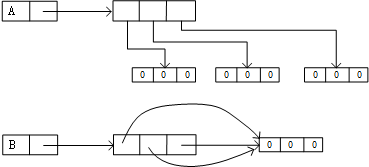
矩阵的乘法并不是赋值,而是重复引用
>>> lists=[[]]*3
>>> lists
[[], [], []]
>>> lists[0].append(3)
>>> lists
[[3], [3], [3]]
>>>
变量不是盒子
Variables are not boxes
>>> x=[1,2,3]
>>> y=x
>>> y
[1, 2, 3]
>>> x[1]=1
>>> x
[1, 1, 3]
>>> y
[1, 1, 3]
>>>
在Python中变量不是一个盒子,当发生赋值运算时,并不是将数据放进去,而是将变量与数据挂钩——引用,将一个变量赋值给另一个变量就是将一个变量的引用传递给另一个变量。
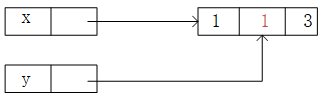
要想得到两个独立的列表,需要用到拷贝
浅拷贝和深拷贝
Shallow and deep copy
shallow copy
>>> x=[1,2,3]
>>> y=x.copy()
>>> y
[1, 2, 3]
>>> x[1]=1
>>> x
[1, 1, 3]
>>> y
[1, 2, 3]
>>>
对比上一个例子,浅拷贝拷贝的是整个列表对像,而不仅仅是变量的引用
利用切片实现copy的效果
>>> x=[1,2,3]
>>> y=x[:]
>>> x
[1, 2, 3]
>>> y
[1, 2, 3]
>>> x[1]=1
>>> x
[1, 1, 3]
>>> y
[1, 2, 3]
>>>
浅拷贝处理一位列表没问题,但处理嵌套列表,需要使用深拷贝
>>> x=[[1,2,3],[4,5,6],[7,8,9]]
>>> y=x.copy()
>>> y
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
>>> x[1][1]=1
>>> x
[[1, 2, 3], [4, 1, 6], [7, 8, 9]]
>>> y
[[1, 2, 3], [4, 1, 6], [7, 8, 9]]
>>>
这是因为浅拷贝只是拷贝了外层对象,如果包含嵌套对象的话,拷贝的只是其引用。

Deep copy
实现深copy要借助copy模块
copy模块有两个函数,copy()和deepcopy
浅copy
>>> import copy
>>> x=[[1,2,3],[4,5,6],[7,8,9]]
>>> y=copy.copy(x)
>>> x
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
>>> y
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
>>> x[1][1]=1
>>> x
[[1, 2, 3], [4, 1, 6], [7, 8, 9]]
>>> y
[[1, 2, 3], [4, 1, 6], [7, 8, 9]]
深拷贝
>>> x=[[1,2,3],[4,5,6],[7,8,9]]
>>> y=copy.deepcopy(x)
>>> x[1][1]=1
>>> x
[[1, 2, 3], [4, 1, 6], [7, 8, 9]]
>>>
>>> y
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
>>>
列表推导式
list comprehension expression
将列表中的每一个元素的值都变成原来的2倍
>>> x=[1,2,3,4,5]
>>> for i in range(len(x)):
x[i]=x[i]*2
>>> x
[2, 4, 6, 8, 10]
列表推导式
>>> x=[1,2,3,4,5]
>>> x=[i*2 for i in x]
>>> x
[2, 4, 6, 8, 10]
>>>
[expression for target in iterable]
>>> x=[i for i in range(10)]
>>> x
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> x=[i+1 for i in range(10)]
>>> x
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> x[]
SyntaxError: invalid syntax
>>> x=[]
>>> for i in range(10):
x.append(i+1)
>>> x
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> y=[i*2 for i in "FishC"]
>>> y
['FF', 'ii', 'ss', 'hh', 'CC']
>>>
将字符串的每一个字符都转换为对应的Unicode编码并保存为列表
>>> code = [ord(i) for i in "FishC"]
>>> code
[70, 105, 115, 104, 67]
ord()将单个字符转换为对应的编码
>>> matrix=[[1,2,3],
[4,5,6],
[7,8,9]]
>>> matrix
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
>>> col2=[row[1] for row in matrix]
>>>
>>> col2
[2, 5, 8]
>>>
>>> matrix=[[1,2,3],
[4,5,6],
[7,8,9]]
>>> diag=[matrix[i][i] for i in range(len(matrix))]
>>> diag
[1, 5, 9]
>>> len(matrix)
3
>>> diag=[matrix[i][2-i] for i in range(len(matrix))]
>>> diag
[3, 5, 7]
>>>
通过循环和通过列表表达式将矩阵元素*2效果是不一样的
循环是通过迭代来逐个修改原列表中的元素
列表推导式直接创建一个新的列表,然后再赋值回原先逐个变量名
创建一个嵌套列表
方法1,使用for循环
>>> B=[[0]*3]*3
>>> B
[[0, 0, 0], [0, 0, 0], [0, 0, 0]]
>>> B[1][1]
0
>>> B[1][1]=1
>>> B
[[0, 1, 0], [0, 1, 0], [0, 1, 0]]
>>> A=[0]*3
>>> for i in range(3):
A[i]=[0]*3
>>> A
[[0, 0, 0], [0, 0, 0], [0, 0, 0]]
>>> A[1][1]=1
>>> A
[[0, 0, 0], [0, 1, 0], [0, 0, 0]]
>>>
方法二,利用列表推导式
>>> S=[[0]*3 for i in range(3)]
>>> S
[[0, 0, 0], [0, 0, 0], [0, 0, 0]]
>>> S[1][1]=1
>>> S
[[0, 0, 0], [0, 1, 0], [0, 0, 0]]
>>>
列表推导式
[expression for target in iterable if condition]
>>> even=[i for i in range(10) if i%2==0]
>>> even
[0, 2, 4, 6, 8]
>>> even
[1, 3, 5, 7, 9]
执行优先级

>>> words=["Great","FishC","Brilliant","Excellent","Fantistic"]
>>> words_F_first=[i for i in words if i[0]=="F"]
>>> words_F_first
['FishC', 'Fantistic']
嵌套的列表推导式
[expression for target1 in iterable1
for target2 in iterable2
…
for targetN in iterableN]
eg:将二维列表降级为以为列表
>>> matrix=[[1,2,3],
[4,5,6],
[7,8,9]]
>>> flatten=[col for row in matrix for col in row]
>>> flatten
[1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> flatten=[]
>>> for row in matrix:
for col in row:
flatten.append(col)
>>> flatten
[1, 2, 3, 4, 5, 6, 7, 8, 9]
>>>
>>> [x+y for x in "fishc" for y in "FISHC"]
['fF', 'fI', 'fS', 'fH', 'fC', 'iF', 'iI', 'iS', 'iH', 'iC', 'sF', 'sI', 'sS', 'sH', 'sC', 'hF', 'hI', 'hS', 'hH', 'hC', 'cF', 'cI', 'cS', 'cH', 'cC']
>>>
>>> _=[] #无关紧要的变量可以用下划线
>>> for x in "fishc":
for y in "FISHC":
_.append(x+y)
>>> _
['fF', 'fI', 'fS', 'fH', 'fC', 'iF', 'iI', 'iS', 'iH', 'iC', 'sF', 'sI', 'sS', 'sH', 'sC', 'hF', 'hI', 'hS', 'hH', 'hC', 'cF', 'cI', 'cS', 'cH', 'cC']
>>>
[expression for target1 in iterable1 if condition1
for target2 in iterable2 if condition2
…
for targetN in iterableN if conditionN]
>>> [[x,y] for x in range(10) if x%2==0 for y in range(10) if y%3==0]
[[0, 0], [0, 3], [0, 6], [0, 9], [2, 0], [2, 3], [2, 6], [2, 9], [4, 0], [4, 3], [4, 6], [4, 9], [6, 0], [6, 3], [6, 6], [6, 9], [8, 0], [8, 3], [8, 6], [8, 9]]
>>> _=[]
>>> for x in range(10):
if x%2==0:
for y in range(10):
if y%3==0:
_.append([x,y])
>>> _
[[0, 0], [0, 3], [0, 6], [0, 9], [2, 0], [2, 3], [2, 6], [2, 9], [4, 0], [4, 3], [4, 6], [4, 9], [6, 0], [6, 3], [6, 6], [6, 9], [8, 0], [8, 3], [8, 6], [8, 9]]
>>>
程序设计原则:KISS
Keep It Simple & Stupid
P27元组tuple
序列:
字符串
列表
元组
元组:既能像列表一样同时容纳多种类型的对象,也有拥有字符串不可变的特性。
列表-[元素1,元素2,元素3,…]
元组-(元素1,元素2,元素3,…)
>>> rhyme=(1,2,3,4,5,"dfafd")#元组可以不带括号
>>> rhyme
(1, 2, 3, 4, 5, 'dfafd')
>>> rhyme=1,2,3,4,5,"dfafd"
>>> rhyme
(1, 2, 3, 4, 5, 'dfafd')
>>>
>>> rhyme[0]
1
>>> rhyme[5]
'dfafd'
元组是不可修改的
>>> rhyme[0]=5
Traceback (most recent call last):
File "" , line 1, in <module>
rhyme[0]=5
TypeError: 'tuple' object does not support item assignment
>>>
元组是可以切片的,但不是在原始的基础上进行修改而是导出一个新的对象
>>> rhyme[:3]
(1, 2, 3)
>>> rhyme[3:]
(4, 5, 'dfafd')
>>> rhyme[:]
(1, 2, 3, 4, 5, 'dfafd')
>>> rhyme[::2]
(1, 3, 5)
>>> rhyme[::-1]
('dfafd', 5, 4, 3, 2, 1)
>>>
元组只有 查
count,index
>>> nums=(3,1,5,5,8,5,7,78,2,87,5,4,8,5,7,5,2,58,4)
>>> nums.count(3)
1
>>> nums.count(2)
2
>>> heros=("蜘蛛侠","绿巨人","钢铁侠","鹰眼","美国队长","蚁人")
>>> heros.index("蜘蛛侠")
0
>>> heros.index("蚁人")
5
>>>
元组中 +,- 也是可以使用的
>>> s=(1,2,3)
>>> t=(4,5,6)
>>> s+t
(1, 2, 3, 4, 5, 6)
>>> s*3
(1, 2, 3, 1, 2, 3, 1, 2, 3)
>>>
元组也可以嵌套
‘,’是构成元组的基本条件
>>> s=(1,2,3)
>>> t=(4,5,6)
>>> w=s,t
>>> w
((1, 2, 3), (4, 5, 6))
>>>
元组也支持迭代
>>> s=(1,2,3)
>>> t=(4,5,6)
>>> w=s,t
>>> w
((1, 2, 3), (4, 5, 6))
>>> s=(1,2,3)
>>> for each in s:
print(each)
1
2
3
>>>
>>>
>>> for i in w:
for each in i:
print(each)
1
2
3
4
5
6
列表推导式,但没有元组推导式
>>> s=(1,2,3,4,5)
>>> [each*2 for each in s]
[2, 4, 6, 8, 10]
>>> (each*2 for each in s)
<generator object <genexpr> at 0x0000024E18BCEA50>
>>>
如何生成只有一个元素的元组
>>> x=(23) #错误
>>> type(x)
<class 'int'>
>>> x=(23,) #正确
>>> type(x)
<class 'tuple'>
>>>
打包和解包
>>> t=(123,"FishC",3.14) #将123,"FishC",3.14打包在了一起
>>> x,y,z=t #解包
>>> x
123
>>> y
'FishC'
>>> z
3.14
>>>
打包解包,适用于任何的序列类型
>>> t=[123,"FishC",3.14]
>>> a1,a2,a3=t
>>> a1
123
>>> a2
'FishC'
>>> a3
3.14
>>>
>>> a,b,c,d,e="FishC"
>>> a
'F'
>>> b
'i'
>>> c
's'
>>> d
'h'
>>> e
'C'
>>>
>>> a,b,*c="FishC"
>>> a
'F'
>>> b
'i'
>>> c
['s', 'h', 'C']
>>>
>>> x,y=10,20
>>> x
10
>>> y
20
>>>
实现过程为
>>> _=(10,20)
>>> x,y=_
>>> x
10
>>> y
20
>>>
元组中的元素虽然是不可变的,但如果元组中的元素指向一个可变的列表,则可以修改这个列表里面的内容
>>> s=[1,2,3]
>>> t=[4,5,6]
>>> w=(s,t)
>>> w
([1, 2, 3], [4, 5, 6])
>>> w[1][1]=1
>>> w
([1, 2, 3], [4, 1, 6])
>>>
P28字符串
判断是不是回文数
>>> x="12321"
>>> "是回文数" if x==x[::-1] else "不是回文数"
'是回文数'
>>> x="123456"
>>> "是回文数" if x==x[::-1] else "不是回文数"
'不是回文数'
>>>
字符串的小伙伴
1,大小写字母换来换去
- capitalize()
- casefold()
- title()
- swapcase()
- upper()
- lower()
1.1 capitalize() 将字符串的首字母变成大写,其他字母变成小写
注意返回的并不是源字符串,因为字符串是不可变对象,所以只是按照规则生成一个字符串
>>> x="I love FishC"
>>> x.capitalize()
'I love fishc'
>>>
1.2 casefold() 返回一个所有字母都是小写的字符串
>>> x.casefold()
'i love fishc'
1.3 title() 将字符串中每个单词的首字母变成大写,单词的其他变为小写
>>> x="I love FishC"
>>> x.title()
'I Love Fishc'
>>>
1.4 swapcase() 将字符串中的所有字母,大小写翻转
>>> x="I love FishC"
>>> x.swapcase()
'i LOVE fISHc'
>>>
1.5 upper() 将所有字母都变成大写
>>> x="I love FishC"
>>> x.upper()
'I LOVE FISHC'
>>>
1.6 lower() 将所有字母都变成小写,只能处理英语字母
>>> x="I love FishC"
>>> x.lower()
'i love fishc'
2,左中右对其
- center(width,fillchar=’ ')
- ljust(width,fillchar=’ ')
- rjust(width,fillchar=’ ')
- zfill(width)
2.1 center(width,fillchar=’ ')
如果输入的宽度小于或者等于原字符串,则直接输出原字符串。第二个参数表示填充字符
>>> x="有内鬼,停止交易!"
>>> x.center(5)
'有内鬼,停止交易!'
>>> x.center(15)
' 有内鬼,停止交易! '
>>> x.center(55)
' 有内鬼,停止交易! '
>>>
>
2.2 ljust(width,fillchar=’ ')
实现左对齐
>>> x.ljust(15)
'有内鬼,停止交易! '
2.3 rjust(width,fillchar=’ ')
实现右对齐
>>> x.rjust(15)
' 有内鬼,停止交易!'
2.4 zfill(width)
用0填充左侧
>>> x.zfill(15)
'000000有内鬼,停止交易!'
>>>
做数据报表的时候比较实用
>>> "520".zfill(5) #要求数据宽度是5个字符
'00520'
>>>
>>>> "-520".zfill(5) #要求数据宽度是5个字符
'-0520'
>>>
第二个参数fillchar表示填充字符
>>> x.center(15,"惊")
'惊惊惊有内鬼,停止交易!惊惊惊'
>>> x.ljust(15,'啊')
'有内鬼,停止交易!啊啊啊啊啊啊'
>>> x.rjust(15,'啊')
'啊啊啊啊啊啊有内鬼,停止交易!'
3,查找
- count(sub[,start[,end]])
- find(sub[,start[,end]])
- rfind(sub[,start[,end]])
- index(sub[,start[,end]])
- rindex(sub[,start[,end]])
3.1 count(sub[,start[,end]])
用于查找sub参数指定的子字符串在字符串中出现的次数
>>> x="好人是我是好人"
>>> x.count("好")
2
>>> x.count("好",0,5) #指定起始字符
1
>>>
3.2 find(sub[,start[,end]])
用于定位sub参数指定的子字符串在字符串中的索引下标值,从左往右找
>>> x="好人是我是好人"
>>> x.find("是")
2
>>> x.find("是",3,6)
4
>>>
3.3 rfind(sub[,start[,end]])
用于定位sub参数指定的子字符串在字符串中的索引下标值,从右往左找
>>> x.rfind("是")
4
>>>
>>>> x.rfind("是",1,3)
2
>>>
3.4 index(sub[,start[,end]])
如果定位不到子字符串,
>>> x.find("松")
-1
>>> x.rfind("松")
-1
>>> x.index("松")
Traceback (most recent call last):
File "" , line 1, in <module>
x.index("松")
ValueError: substring not found
>>> x.rindex("松")
Traceback (most recent call last):
File "" , line 1, in <module>
x.rindex("松")
ValueError: substring not found
>>>
3.5 rindex(sub[,start[,end]])
4,替换
- expandtabs([tabsize=8])
- replace(old,new,count=-1)
- translate(table)
4.1 expandtabs([tabsize=8])
使用空格来替换制表符,并返回一个新的字符串
>>> code="""
print("I love FishC") #使用tab缩进
print("使用空格缩进") #使用2空格缩进
"""
>>> print(code)
print("I love FishC") #使用tab缩进
print("使用空格缩进") #使用2空格缩进
>>> new_code=code.expandtabs(2) #表示几个空格对应一个tab
>>> print(new_code)
print("I love FishC") #使用tab缩进
print("使用空格缩进") #使用2空格缩进
>>>
4.2 replace(old,new,count=-1)
将所有old的参数指定的子字符串替换为new参数指定的新字符串,count参数指定的是替换的次数,默认值是-1,全部替换
>>> "在吗?我在你家楼下,赶快下来!!".replace("在吗","想你")
'想你?我在你家楼下,赶快下来!!'
>>>
4.3 translate(table)
返回一个根据table参数转换后的新字符串
table指的是表格,需要用str.maketrans[x[,y[,z]]]获取table
>>> table=str.maketrans("ABCDRFG","1234567")
>>> "I love FishC".translate(table)
'I love 6ish3'
>>>
>>> "I love FishC".translate(str.maketrans("ABCDRFG","1234567"))
'I love 6ish3'
str.maketrans[x[,y[,z]]]支持第三个参数,将指定的字符忽略
>>> "I love FishC".translate(str.maketrans("ABCDRFG","1234567","love"))
'I 6ish3'
5,判断
返回的都是一个布尔类型的值,True or False
- startswith(prefix[,start[,end]]) #[]表示可选参数
- endswith(prefix[,start[,end]])
- isupper()
- islower()
- istitle()
- isalpha()
- isascii()
- isspace()
- isprintable()
- isdecimal()
- isdigit()
- isnumeric()
- isalnum()
- isidentififer()
5.1 startswith(prefix[,start[,end]])
判断它的参数指定的子字符串是否出现在起始位置,
>>> x="我爱Python"
>>> x.startswith("我")
True
>>> x.startswith("我",1)#从索引1开始
False
>>> x.startswith("爱",1)
True
>>> x.startswith("n")
False
>>> x.startswith("P")
False
可以以元组的方式传入待匹配的字符串
>>> x="她爱Pyhon"
>>> if x.startswith(("你","我","她")):
print("总有人喜爱Pyhon")
总有人喜爱Pyhon
>>>
5.2 endswith(prefix[,start[,end]])
判断它的参数指定的子字符串是否出现在结束位置,可以以元组的方式传入待匹配的字符串
>>> x="我爱Python"
>>> x.endswith("n")
True
>>> x.endswith("Py",0,4)
True
>>> x.endswith("n",0,6)
False
>>> x.endswith("P")
False
>>>
5.3 isupper()
判断字符串中所有字母是否都为大写
>>> x="I Love FishC"
>>> x.isupper()
False
>>> x="I LOVE FISHC"
>>> x.isupper()
True
>>>
>>> x="I Love FishC"
>>> x.upper()
'I LOVE FISHC'
>>> x.upper().isupper()#对于这种情况Python从左到右依次调用
True
>>>
5.4 islower()
判断字符串中所有字母是否都为小写
5.5 istitle()
判断字符串中所有字母是否都已大写字母开头,其余字母均为小写
>>> x="I love FishC"
>>> x.istitle()
False
>>> x="I Love FishC"
>>> x.istitle()
False
>>> x="I Love Fishc"
>>> x.istitle()
True
>>>
5.6 isalpha()
判断字符串中是否只有字母构成
>>> x="I Love FishC"
>>> x.isalpha()
False
>>> x="ILoveFishC"
>>> x.isalpha()
True
5.7 isascii()
5.8 isspace()
判断一个字符串是否为空白字符串
空白字符串 空格,tab,\n
>>> " ".isspace() #空格
True
>>> " ".isspace() #tab
True
>>> "\n".isspace()
True
>>>
5.9 isprintable()
判断一个字符串是否所有字符可打印的
转义字符
>>> x="I love FishC"
>>> x.isprintable()
True
>>> "I love FishC\n".isprintable()
False
>>>
5.10 isdecimal()
>>> x="123456"
>>>> x.isdecimal()
True
>>> x="2²"
>>> x.isdecimal()
False
>>> x="ⅠⅡⅢⅣⅤⅥ"
>>>> x.isdecimal()
False
>>> x="一二三四五六"
>>> x.isdecimal()
False
5.11 isdigit()
>>> x="123456"
>>>> x.isdigit()
True
>>> x="2²"
>>> x.isdigit()
True
>>> x="ⅠⅡⅢⅣⅤⅥ"
>>>> x.isdigit()
False
>>> x="一二三四五六"
>>> x.isdigit()
False
5.12 isnumeric()
>>> x="123456"
>>>> x.isnumeric()
True
>>> x="2²"
>>> x.isnumeric()
True
>>> x="ⅠⅡⅢⅣⅤⅥ"
>>>> x.isnumeric()
True
>>> x="一二三四五六"
>>> x.isnumeric()
True
5.13 isalnum()
isalpha()
isdecimal()
isdigit()
isnumeric()四个中有一个返回为True,结果就是True。
5.14 isidentififer()
判断字符串是否为一个标准的Python表示符
>>> "HELLO HI".isidentifier() #空格
False
>>> "HELLO_HI".isidentifier()
True
>>> "dfsf5444".isidentifier()
True
>>> "46dfsaf".isidentifier()
False
>>>
如果判断一个字符串是否为Python的保留标识符
if for…
可以使用keyword模块的iskeyword
>>> import keyword
>>> keyword.iskeyword("if")
True
>>> keyword.iskeyword("a")
False
>>> keyword.iskeyword("for")
True
>>>
6,截取
- strip(chars=None)
- lstrip(chars=None)
- rstrip(chars=None)
- removeprefix(prefix)
- removesuffix(suffix)
6.1 strip(chars=None)
左右两侧都不留空白
参数chars=None表示默认空白,如果chars=*,则把字符串中的 *去掉。
>>> " 左右不要留白 ".strip()
'左右不要留白'
>>>
>>> s="**测试参数*chars=None**"
>>> s.strip("*")
'测试参数*chars=None'
>>> s.lstrip("*")
'测试参数*chars=None**'
>>> s.rstrip("*")
'**测试参数*chars=None'
>>>
#虽然传入的是一串字符,但是它是按照单个字符为单位进行匹配去剔除
>>> s="*--*测试参数*-*chars=None*--*"
>>> s.strip("*-")
'测试参数*-*chars=None'
>>> s.lstrip("*-")
'测试参数*-*chars=None*--*'
>>> s.rstrip("*-")
'*--*测试参数*-*chars=None'
>>>
6.2 lstrip(chars=None)
去掉字符串左侧的空白
>>> " 左侧不要空白".lstrip()
'左侧不要空白'
6.3 rstrip(chars=None)
去掉字符串右侧的空白
>>> "右侧不要有空白 ".rstrip()
'右侧不要有空白'
>>>
6.4 removeprefix(prefix)
删除指定的前缀
>>> "www.baidu.com".removeprefix("www.")
'baidu.com'
>>> "www.baidu.com".removesuffix("www.")
'www.baidu.com'
>>> "www.baidu.com".removesuffix(".com")
'www.baidu'
>>>
6.5 removesuffix(suffix)
删除指定的后缀
7,拆分&拼接
- partition(sep)
- rpartition(sep)
- split(sep=None,maxsplit=-1)
- rsplit(sep=None,maxsplit=-1)
- splitlines(keepends=False)
- join(iterable)
7.1 partition(sep)
将字符串以参数指定的分隔符为依据进行分割,并且将分割后的结果返回一个三元组,从左往右
>>> "www.baidu.com".partition(".")
('www', '.', 'baidu.com')
7.2 rpartition(sep)
将字符串以参数指定的分隔符为依据进行分割,并且将分割后的结果返回一个三元组,从右往左
>>> "www.baidu.com".rpartition(".")
('www.baidu', '.', 'com')
7.3 split(sep=None,maxsplit=-1)
参数maxsplit指定分割的次数,默认是根据分割符全部切割
>>> "人之初,性本善,性相近,习相远".split() #默认
['人之初,性本善,性相近,习相远']
>>> "人之初,性本善,性相近,习相远".split(",")
['人之初', '性本善', '性相近', '习相远']
>>>
>>> "人之初,性本善,性相近,习相远".split(",",1)
['人之初', '性本善,性相近,习相远']
>>> "人之初,性本善,性相近,习相远".rsplit(",",1)
['人之初,性本善,性相近', '习相远']
>>>
包含换行符的切割
>>> "人之初\n性本善\n性相近\n习相远".split("\n")
['人之初', '性本善', '性相近', '习相远']
但是不同操作系统的换行符不同
\n:Unix and Unix-like systems(Linux,macOS,FreeBSD,AIX,Xenix,etc.)
\r:Classic Mac OS
\r\n:Microsoft Windows
为了方便可以使用7.5 splitlines(keepends=False)
7.4 rsplit(sep=None,maxsplit=-1)
从右往左
>>> "人之初,性本善,性相近,习相远".rsplit(",")
['人之初', '性本善', '性相近', '习相远']
>>> "人之初\n性本善\r性相近\r\n习相远".split("\n")
['人之初', '性本善\r性相近\r', '习相远']
>>>> "人之初\n性本善\r性相近\r\n习相远".splitlines()
['人之初', '性本善', '性相近', '习相远']
>>>
7.5 splitlines(keepends=False)
将字符串按照行进行分割,然后将结果以列表的形式返回
>>> "人之初\n性本善\n性相近\n习相远".splitlines()
['人之初', '性本善', '性相近', '习相远']
>>>
参数keepends是指定结果是否包含换行符
默认是False不包含
>>> "人之初\n性本善\r性相近\r\n习相远".splitlines()
['人之初', '性本善', '性相近', '习相远']
>>> "人之初\n性本善\r性相近\r\n习相远".splitlines(True)
['人之初\n', '性本善\r', '性相近\r\n', '习相远']
7.6 join(iterable) 重要
>>> ".".join(["www","baidu","com"])#用列表
'www.baidu.com'
>>> "+".join(("www","baidu","com"))#用元组
'www+baidu+com'
>>>
将2个FishC进行拼接
>>> s="FishC"
>>> s+=s
>>> s
'FishCFishC'
>>> "".join(("FishC","FishC"))
'FishCFishC'
8,格式化字符串的方法
需要转换的原因
>>> year=2010
>>> "鱼C工作室成立于 year 年"
'鱼C工作室成立于 year 年'
>>> "鱼C工作室成立于{}年".format(year)
'鱼C工作室成立于2010年'
- format()
在字符串中使用{}占位,然后内容放在format(内)
8.1 format()
>>> "1+2={},2的平方是{},3的立方是{}".format(1+2,2*2,3*3*3)
'1+2=3,2的平方是4,3的立方是27'
{}里面还可以写上数字,表示参数的位置,参数中的字符串会被当做元组的元素来对待
>>> "{}看到{}就很激动!".format("小甲鱼","小姐姐")
'小甲鱼看到小姐姐就很激动!'
>>> "{1}看到{0}就很激动!".format("小甲鱼","小姐姐")
'小姐姐看到小甲鱼就很激动!'
同一个索引值也可以引多次
>>> "{0}{0}{1}".format("是","非")
'是是非'
还可以通过关键字进行索引
>>> "我叫{name},我爱{fav}.".format(name="小甲鱼",fav="Python")
'我叫小甲鱼,我爱Python.'
位置索引和关键字索引可以组合着用
>>> "我叫{name},我爱{0},喜欢{0}的人,运气都不会太差".format("Python",name="小甲鱼")
'我叫小甲鱼,我爱Python,喜欢Python的人,运气都不会太差'
>>>
输出一对{}
>>> "{},{},{}".format(1,"{}",2)
'1,{},2'
>>> "{},{
{}},{}".format(1,2)
'1,{},2'
>>> "{},{},{
{}}".format(1,2)
'1,2,{}'
>>>
[[fill]align][sign][#][0][width][grouping_option][.precision][type]
[align]
指定对其方式

>>> "{:^}".format(250)
'250'
>>> "{:^10}".format(250) #:是必须的,左边是关键字索引,右边是格式化选项
' 250 '
>>> "{1:>10}{0:<10}".format("520","250")
' 250520 '
>>>

>>> "{left:>10}{right:<10}".format(right="520",left="250")
' 250520 '
>>>
>>> "{:010}".format(250)
'0000000250'
>>> "{:010}".format(-250)
'-000000250'
>>> "{:010}".format("FishC")
Traceback (most recent call last):
File "" , line 1, in <module>
"{:010}".format("FishC")
ValueError: '=' alignment not allowed in string format specifier
>>>
>>> "{1:%>10}{0:%<10}".format(520,250)
'%%%%%%%250520%%%%%%%'
>>>
>>> "{:0=10}".format(520)
'0000000520'
>>> "{:0=10}".format(-520)
'-000000520'
>>>

>>> "{:+}{:-}".format(520,-250)
'+520-250'
千位分割符
>>> "{:,}".format(1234)
'1,234'
>>> "{:_}".format(1234)
'1_234'
>>> "{:_}".format(123)#如果位数不足,则不显示千位分隔符
'123'
>>>
精度
- 对于[type]设置为’f’或者’F’的浮点数来说,是限定小数点后显示多少个位数
- 对于[type]设置为’g’或’G’的浮点数来说,是限定小数点前后一共显示多少个位数
- 对于非数字类型来说,限定的是最大字段的大小
- 对于整数类型来说,则不允许使用[.precision]
>>> "{:.2f}".format(3.1415)
'3.14'
>>> "{:.2g}".format(3.1415)
'3.1'
>>> "{:.2}".format("3.1415")
'3.'
>>> "{:.6}".format("3.1415") #截取功能
'3.1415'
>>> "{:.2}".format(520) #对于整数类型来说,则不允许使用[.precision]
Traceback (most recent call last):
File "" , line 1, in <module>
"{:.2}".format(520) #对于整数类型来说,则不允许使用[.precision]
ValueError: Precision not allowed in integer format specifier
>>>
type 类型选项
决定数据如何呈现

>>> "{:b}".format(80)
'1010000'
>>> "{:c}".format(80)
'P'
>>> "{:d}".format(80)
'80'
>>> "{:o}".format(80)
'120'
>>> "{:x}".format(80)
'50'
>>> "{:X}".format(80)
'50'
>>> "{:n}".format(80)
'80'
>>> "{}".format(80)
'80'
>>>
加个#会自动添加一个进制标识
>>> "{:#b}".format(80) #加个#会自动添加一个进制标识
'0b1010000'
>>> "{:#o}".format(80)
'0o120'
>>> "{:#x}".format(80)
'0x50'
>>>
适用于浮点数和复数的的类型

>>> "{:e}".format(3.1415926)
'3.141593e+00'
>>> "{:E}".format(3.1415926)
'3.141593E+00'
>>> "{:f}".format(3.1415926)
'3.141593'
>>> "{:F}".format(3.1415926)
'3.141593'
>>> "{:g}".format(3.1415926)
'3.14159'
>>> "{:g}".format(123456789)
'1.23457e+08'
>>> "{:g}".format(3.14159265656)
'3.14159'
>>> "{:%}".format(3.14159265656)
'314.159266%'
>>> "{:%}".format(0.98)
'98.000000%'
>>> "{:.2%}".format(0.98)
'98.00%'
>>> "{:.{prec}f}".format(3.1415926,prec=2)
'3.14'
>>>
f-字符串
f-string
>>> year=2010
>>> "鱼C工作室成立于{}年".format(year)
'鱼C工作室成立于2010年'
>>> f"鱼C工作室成立于{
year}年"
'鱼C工作室成立于2010年'
>>>
>>> "1+2={},2的平方是{},3的立方是{}".format(1+2,2*2,3*3*3)
'1+2=3,2的平方是4,3的立方是27'
>>> F"1+2={
1+2},2的平方是{
2*2},3的立方是{
3*3*3}"
'1+2=3,2的平方是4,3的立方是27'
>>>
>>> "{:010}".format(-520)
'-000000520'
>>> f"{
-520:010}"
'-000000520'
>>>
>>> "{:,}".format(1234)
'1,234'
>>> f"{
1234:,}"
'1,234'
>>>
>>> "{:.2f}".format(3.1415)
'3.14'
>>> f"{
3.1415:.2f}"
'3.14'
>>>
>>> "{:{fill}{align}{width}.{perc}{ty}}".format(3.1415,fill='+',align='^',width=10,perc=3,ty='g')
'+++3.14+++'
>>> fill='+'
>>> align='^'
>>> width=10
>>> perc=3
>>> ty='g'
>>> f"3.1415:{
fill}{
align}{
width}.{
perc}{
ty}" #少写了一个大括号
'3.1415:+^10.3g'
>>> f"{
3.1415:{
fill}{
align}{
width}.{
perc}{
ty}}"
'+++3.14+++'
>>>
P34序列
列表、元组、字符串的共同点
- 都可以通过索引获取每一个元素
- 第一个元素的索引值都是0
- 都可以通过切片的方法获取一个范围
- 都有很多共同的运算符
在Python中,列表、元组、字符串统称为序列
根绝序列是否可以被修改这一特征,可以将序列分为可变序列和不可变序列
可变序列:列表
不可变序列:元组,字符串
作用于序列的运算符和函数
+ *
>>> [1,2,3]+[4,5,6]
[1, 2, 3, 4, 5, 6]
>>> (1,2,3)+(4,5,6)
(1, 2, 3, 4, 5, 6)
>>> "123"+"456"
'123456'
>>> [1,2,3]*3
[1, 2, 3, 1, 2, 3, 1, 2, 3]
>>> (1,2,3)*3
(1, 2, 3, 1, 2, 3, 1, 2, 3)
>>> "123"*3
'123123123'
>>>
在Python中每一个对象都有一个属性,唯一表志、类型、值。
唯一标志在对象创建的时候就有,不可以被修改,也不会有重复的值,可以理解为身份证
id() 返回一个代表指定对象的唯一标识的整数值
>>> s=[1,2,3]
>>> id(s)
1684311466752
>>> s*=2
>>> s
[1, 2, 3, 1, 2, 3]
>>> id(s)
1684311466752
>>>
所以,内容改变,但id没有改变,s还是原来的s。对于不可变序列,是重新重新创建一个变量,并将结果返回,如下
>>> s=(1,2,3)
>>> id(s)
1684312457472
>>> s*=2
>>> id(s)
1684311667520
>>>
is 和 is not
用于检测对象的id值是否相等,从而判断是否为同一个对象,同一性运算符,判断是非问题
>>> x="FishC"
>>> y="FishC"
>>> x is y
True
>>> x=[1,2,3]
>>> y=[1,2,3]
>>> x is y
False
>>>
in 和 not in
in运算符,用于判断某个元素是否包含在序列中
判断的是包含问题
>>> "鱼" in "鱼C"
True
>>>
>>> "鱼c" in "鱼"
False
>>> "ABC" in "ABDC"
False
>>> "ABC" in "ABCD"
True
>>> "ABC" not in "ABDC"
True
>>>
>>> "C" not in "FishC"
False
>>>
del
用于删除一个或者多个指定的对象
>>> x="FishC"
>>> y=[1,2,3]
>>> del x,y
>>> x
Traceback (most recent call last):
File "" , line 1, in <module>
x
NameError: name 'x' is not defined
>>> t
Traceback (most recent call last):
File "" , line 1, in <module>
t
NameError: name 't' is not defined
>>>
删除可变序列中的指定元素
>>> x=[1,2,3,4,5,6]
>>> del x[1:4]
>>> x
[1, 5, 6]
>>>
使用切片语法实现删除可变序列中的指定元素
>>> y=[1,2,3,4,5,6]
>>> y[1:4]=[]
>>> y
[1, 5, 6]
>>>
相当于执行了两个步骤
- 将赋值号左侧指定位置的内容清空
- 将赋值号右侧可迭代对象的内容插入到左侧列表被清空的位置
>>> x=[1,2,3,4,5,6]
>>> del x[::2]
>>> x
[2, 4, 6]
>>> x=[1,2,3,4,5,6]
>>> del x[::1]
>>> x
[]
>>>
这种情况用切片不行
>>> y[::2]=[]
Traceback (most recent call last):
File "" , line 1, in <module>
y[::2]=[]
ValueError: attempt to assign sequence of size 0 to extended slice of size 3
>>>
>>> x=[1,2,3,4,5,6]
>>> x.clear()
>>> x
[]
>>> y=[1,2,3,4,5,6]
>>> del y[:]
>>> y
[]
>>>
跟序列相关的一些函数
1,列表、元组和字符串相互转换
- list()
- tuple()
- str()
1.1 list()
将一个可迭代对象转换为列表
>>> list("FishC")
['F', 'i', 's', 'h', 'C']
>>> list("FishC") #字符串
['F', 'i', 's', 'h', 'C']
>>>
>>> list((1,2,3,4)) #元组
[1, 2, 3, 4]
>>>
1.2 tuple()
将一个可迭代对象转换为元组
>>> tuple("FishC")
('F', 'i', 's', 'h', 'C')
>>> tuple([1,2,3,4,5,6])
(1, 2, 3, 4, 5, 6)
>>>
1.3 str()
将一个可迭代对象转换为字符串
>>> str([1,2,3,4,5,6])
'[1, 2, 3, 4, 5, 6]'
>>> str((1,2,3,4,5,6))
'(1, 2, 3, 4, 5, 6)'
>>>
2,对必传入的参数,并返回最小值或者最大值
- min()
- max()
2.1 min()
min(iterable,*[,key,default])
min(arg1,arg2,*args[,key])
>>> s=[1,1,2,5,6,8,3,8]
>>> min(s)
1
>>> t="FishC" #对于字符串,比较的是每个字符的编码值
>>> max(t)
's'
>>>
>>> min(5,1,55,2,5,52,8,2,5,1)
1
>>>
如果传入的是空字符串
>>> s=[]
>>> min(s)
Traceback (most recent call last):
File "" , line 1, in <module>
min(s)
ValueError: min() arg is an empty sequence
>>>
2.2 max()
max(iterable,*[,key,default])
max(arg1,arg2,*args[,key])
>>> s=[]
>>> min(s,default="屁,啥也没有,怎么找到最小?")
'屁,啥也没有,怎么找到最小?'
>>>
3, len() & sum()
- len()
- sum()
3.1 len()
注意,len有取值范围
>>> len(range(2**100))
Traceback (most recent call last):
File "" , line 1, in <module>
len(range(2**100))
OverflowError: Python int too large to convert to C ssize_t
>>>
>>> len(range(2**63-1))
9223372036854775807
>>> len(range(2**63))
Traceback (most recent call last):
File "" , line 1, in <module>
len(range(2**63))
OverflowError: Python int too large to convert to C ssize_t
>>>
3.2 sum()
>>> s=[1,2,3,4,56,1]
>>> sum(s)
67
>>> sum(s,start=100) #默认从零开始加
167
>>>
4,
- sorted()
- reversed()
4.1 sorted()
sorted()函数返回的是一个全新的列表,原列表不会受影响
>>> s=[1,2,3,0,6]
>>> sorted(s)
[0, 1, 2, 3, 6]
>>> s
[1, 2, 3, 0, 6]
>>>
sort()函数直接在原列表中排序
>>> s=[1,2,3,0,6]
>>> s.sort()
>>> s
[0, 1, 2, 3, 6]
>>>
>>> s=[1,2,3,0,6]
>>> sorted(s,reverse=True) #排序后翻转
[6, 3, 2, 1, 0]
>>> t=["FishC","Apple","Book","Banana","Pen"]
>>> sorted(t) #对比的是每一个字符串的编码值
['Apple', 'Banana', 'Book', 'FishC', 'Pen']
>>> sorted(t,key=len) #key指定的是一个干预排序算法的函数,这里调用的是len()函数,则,在排序的过程中先将列表中的每一个元素自动调用len(),然后比较len()函数的返回结果,因此sorted(t,key=len)比较的是每个元素的长度
['Pen', 'Book', 'FishC', 'Apple', 'Banana']
>>>
sort()函数类似
>>> t=["FishC","Apple","Book","Banana","Pen"]
>>> t.sort(key=len)
>>> t
['Pen', 'Book', 'FishC', 'Apple', 'Banana']
>>>
但注意,sort()函数只能处理列表,sorted()函数,序列都可以
>>> sorted("FishC")
['C', 'F', 'h', 'i', 's']
>>> sorted((1,0,2,3,5,8))
[0, 1, 2, 3, 5, 8]
>>> "FishC".sort()
Traceback (most recent call last):
File "" , line 1, in <module>
"FishC".sort()
AttributeError: 'str' object has no attribute 'sort'
>>>
4.2 reversed()
reversed()返回的是一个参数的反向迭代器
>>> s=[1,2,5,8,0]
>>> reversed(s)
<list_reverseiterator object at 0x00000206C0888910>
>>> list(reversed(s))
[0, 8, 5, 2, 1]
>>>
>>> s
[1, 2, 5, 8, 0]
>>> s.reverse()
>>> s
[0, 8, 5, 2, 1]
>>>
>>> list(reversed("FishC"))
['C', 'h', 's', 'i', 'F']
>>> list(reversed((1,2,5,8,9,6,7)))
[7, 6, 9, 8, 5, 2, 1]
>>> list(reversed(range(0,10)))
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
>>>
5,
- all()
- any()
5.1 all()
判断可迭代对象中是否所有元素的值都为真
>>> x=[1,1,0]
>>> y=[1,1,9]
>>> all(x)
False
>>> all(y)
True
>>> any(x)
True
>>> any(y)
True
>>>
5.2 any()
判断可迭代对象中是否存在某个元素的值为真
6,enumerate()
enumerate()函数用于返回一个枚举对象,它的功能就是将可迭代对象中的每个元素及从0开始的序号共同构成一个二元组的列表
>>> seasons=["Spring","Summer","Fall","Winter"]
>>> enumerate(seasons)
<enumerate object at 0x00000206C0889080>
>>> list(enumerate(seasons))
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
>>> list(enumerate(seasons,10))
[(10, 'Spring'), (11, 'Summer'), (12, 'Fall'), (13, 'Winter')]
>>>
7,zip()
zip()函数用于创建一个聚合多个可迭代对象的迭代器。它会将作为参数传入的每个可迭代对象的每个元素依次组合成元组,即第i个元组包含来自每个参数的第i个元素。
>>> x=[1,2,3]
>>> y=[4,5,6]
>>> zipped=zip(x,y)
>>> list(zipped)
[(1, 4), (2, 5), (3, 6)]
>>> z=[7,8,9]
>>> zipped=zip(x,y,z)
>>> list(zipped)
[(1, 4, 7), (2, 5, 8), (3, 6, 9)]
>>>
会以较短的为准
>>> x=[1,2,3]
>>> y=[4,5,6]
>>> zipped=zip(x,y)
>>> list(zipped)
[(1, 4), (2, 5), (3, 6)]
>>> z="FishC"
>>> zipped=zip(x,y,z)
>>> list(zipped)
[(1, 4, 'F'), (2, 5, 'i'), (3, 6, 's')]
>>>
为了解决这一问题,可以使用itertools模块
>>> import itertools
>>> zipped = itertools.zip_longest(x,y,z)
>>> list(zipped)
[(1, 4, 'F'), (2, 5, 'i'), (3, 6, 's'), (None, None, 'h'), (None, None, 'C')]
>>>
8,map()
map()函数会根据提供的函数对指定的可迭代对象的每个元素进行运算,并将返回运算结果的迭代器
第一个参数指定一个函数
ord求出对象的unicode编码
>>> mapped=map(ord,"FishC")
>>> list(mapped)
[70, 105, 115, 104, 67]
>>>
>>>> mapped=map(pow,[2,3,10],[5,2,3])
>>> list(mapped)
[32, 9, 1000]
>>>
>>> list(map(max,[1,3,5],[2,2,2],[0,3,9,8]))
[2, 3, 9]
>>>
9,filter()
filter()函数会根据提供的函数对指定的可迭代对象的每个元素进行运算,并将运算结果为真的元素,以迭代器的形式返回
>>> list(filter(str.islower,"FishC"))
['i', 's', 'h']
>>>
迭代器 VS 可迭代对象
迭代器是一个可迭代对象
可迭代对象可以重复使用,但是迭代器是一次性的
>>> mapped=map(ord,"FishC")
>>> for each in mapped:
print(each)
70
105
115
104
67
>>> list(mapped)
[]
>>>
序列都是可迭代对象
iter():将可迭代对象转换为迭代器
>>> x=[1,2,3,4,5]
>>> y=iter(x)
>>> type(x)
<class 'list'>
>>> type(y)
<class 'list_iterator'>
>>>
next():逐个将迭代器中的元素提取出来
>>> next(y)
1
>>> next(y)
2
>>> next(y)
3
>>> next(y)
4
>>> next(y)
5
>>> next(y)
Traceback (most recent call last):
File "" , line 1, in <module>
next(y)
StopIteration
>>> y
<list_iterator object at 0x0000023888257040>
>>> list(y)
[]
>>>
如果不想异常
>>> z=iter(x) #激活迭代器
>>> next(z,"没了")
1
>>> next(z,"没了")
2
>>> next(z,"没了")
3
>>> next(z,"没了")
4
>>> next(z,"没了")
5
>>> next(z,"没了")
'没了'
>>> next(z,"没了")
'没了'
>>>