Java、Go、Rust大比拼,高并发时代谁能称雄?
作者 | 马超
出品 | CSDN(ID:CSDNnews)
互联网时代流量的大起大落,很多科技巨头在面对流量的冲击时也都败下阵来,XXX崩了的新闻热搜不断,而Serverless凭借快速伸缩的自动弹性特点,可以从容应对类似的冲击,这也让这种新技术出尽的风头。
在Serverless的喧嚣背后,Rust看似牢牢占据了C位,但其实在高并发这个话题下要总结的模式与套路其实很多,尤其是像Tokio、RxJava等专业的编程框架,对于程序员编写高性能程序的帮助很大。为了深入讨论高并发这个话题,本文还是将目光集中在Java、C、Go和Rust几种主流后端语言,可以说这些语言在面对高并发的场景时都有自己独特的生态位,下面就像大家分享一下笔者的心得。

在正式讨论之前,笔者这里先要说明本文主要讨论的话题高并发而非高并行,其实并发和并行完全是两件事,并行是一个核心负责一个任务,其基础是多核的执行架构;而并发是多个任务交替执行,也就是说高并发就是要极限压榨系统的性能,尽量在等待IO返回的空窗期,也给CPU安排满负荷的工作,从而使单核发挥出多核的效果。
一刀流的剑客-Go语言
与Java、Rust等语言不同,Go语言风格自成一派,它不太需要什么高并发框架,因为Go语言自身就是一个非常强大的高并发框架。Go语言给人的第一印象是非常的极致,它对于代码简洁性的要求非常严格,代码中用不到的Package严禁import,用不到的变量也要求强制删除。
Go语言的优秀范例很多,Docker、K8s、TiDB、BFE等等不胜枚举,即便不参考这些成功的开源项目,仅仅依靠官方给出的示范,也能让一行简单的Go语句表现出技惊四座的性能。在限定代码行数的情况下,Go语言的表现应该是所有框架中最好的。
使用Go语言让程序员可以轻而易举的开发出一款性能强劲的应用程序,而恰恰是这种简单、易用的特性,也会让很多开发者误以为程序的效率卓越是自身编码实力的体现。但其实深入了解Go语言你会发现在高并发神器Goroutine的背后,也可能会隐藏很多细节问题,下面给大家举两个例子。
一、内存屏障导致变量值未刷新:在下面这段代码当中,我们启动了一个Gourtine无限调用i++,对于变量i不断进行+1操作。
package main
import (
"fmt"
"runtime"
"time"
)
func main() {
var y int32
go func() {
for {
y++
}
}()
time.Sleep(time.Second)
fmt.Println("y=", y)
}
但不管你的主线程等多久时间,运行输出结果都始终是a=0。
这其实是一个高速缓存与内存之间的屏障问题,CPU对于变量a的操作仅限于高速缓存之中,却没有被flush到内存里,因此主goutine在打印a变量的值时,只能得到始值也就是0。
这个问题解决之道也简单的令人无语,只要在Gouroutine的执行函数体当中加上一个完全不可能被执行到的if判断就能解决。
package main
import (
"fmt"
"runtime"
"time"
)
func main() {
var y int32
z:=0
go func() {
for {
if z > 0 {
fmt.Println("zis", z)//这一行代码不会执行到
}
y++
}
}()
time.Sleep(time.Second)
fmt.Println("y=", y)
}
通反编译工具查看汇编代码,可以看到if操作实际上隐匿调用了writebarrier也就是内存写屏障操作。
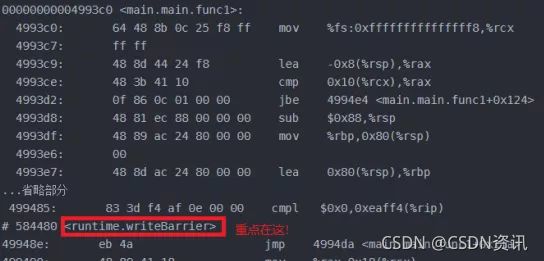
虽然这个if分支根本不会被执行,但只要这种if代码段存在,就会让Goroutine在被调度出执行态时执行内存wirtebarrier操作,从而将调整缓存中的变量flush到主内存中,这种机制很可能隐藏非常难以排查的BUG。
二、闭包地址传递,错使切片元素取值错误:在日常工作中如果一个切片/数组中的元素彼此独立,我们非常有可能通过gouroutine创建闭包,将切片中的每个元素取出来单独处理,但是如果没参考最佳实践,随手写出来的代码很可能会存在隐患,比如:
import (
"fmt"
"time"
)
func main() {
tests1ice := []int{
1, 2, 3, 4, 5}
for _, v := range tests1ice {
go func() {
fmt.Println(v)
}()
}
time.Sleep(time.Millisecond)
}
上述代码一般只会取一个元素出来,比如这种连续5个3或者5个5,
想解决这个问题,就需要强制使用值传递的办法,具体如下:
go func(v int) {
fmt.Println(v)
}(v)
有关Go语言的疑难杂症并不是我们今天要关注的重点,这里笔者想表达的是Go语言想用好简单,但要用精、用到极限却很难。所以个人认为Go语言和一刀流这种东洋剑术门派很像,入门简单,成型快速,但想成为绝顶高手,要走的路其实也是一样漫长。
高并发中的Poll、Epoll、Future都是什么概念
在聊完Go语言这个比较另类的派别之后,我们回归到高并发中的几个重要概念,由于我们今天关注的几种语言中,Future并不是一个主流的实现,但是Future与Poll的概念又是如此重要,我们必须放在开头来讲,因此这里先将重心放在Rust身上,由于Rust与Go、Java相比对于Future实现比较完整,特性支持也彻底。因此下面的代码均以Rust为例。
简单来讲Future不是一个值,而是一种值类型,一种在未来才能得到的值类型。Future对象必须实现Rust标准库中的std::future:: future接口。Future的输出Output是Future完成后才能生成的值。在Rust中Future通过管理器调用Future::poll来推动Future的运算。Future本质上是一个状态机,而且可以嵌套使用,我们来看一下面这个例子,在main函数中,我们实例化MainFuture并调用.await,而MainFuture除了在几个状态之间迁移以外,还会调用一个Delay的Future,从而实现Future的嵌套。
MainFuture以State0状态做为初始状态。当调度器调用poll方法时,MainFuture会尝试尽可能地提升其状态。如果future完成,则返回Poll::Ready,如果MainFuture没有完成,则是由于它等待的DelayFuture没有达到Ready状态,那么此时返回Pending。调度器收到Pending结果,会将这个MainFuture重新放回待调度的队列当中,稍后会再度调用Poll方法来推进Future的执行。具体如下:
use std::future::Future;
use std::pin::Pin;
usestd::task::{
Context, Poll};
usestd::time::{
Duration, Instant};
struct Delay {
when: Instant,
}
impl Future forDelay {
type Output = &'static str;
fn poll(self: Pin<&mut Self>, cx:&mut Context<'_>)
-> Poll<&'static str>
{
if Instant::now() >= self.when {
println!("Hello world");
Poll::Ready("done")
} else {
cx.waker().wake_by_ref();
Poll::Pending
}
}
}
enum MainFuture {
State0,
State1(Delay),
Terminated,
}
impl Future forMainFuture {
type Output = ();
fn poll(mut self: Pin<&mut Self>,cx: &mut Context<'_>)
-> Poll<()>
{
use MainFuture::*;
loop {
match *self {
State0 => {
let when = Instant::now() +
Duration::from_millis(1);
let future = Delay {
when};
println!("initstatus");
*self = State1(future);
}
State1(ref mut my_future) =>{
matchPin::new(my_future).poll(cx) {
Poll::Ready(out) =>{
assert_eq!(out,"done");
println!("delay finished this future is ready");
*self = Terminated;
returnPoll::Ready(());
}
Poll::Pending => {
println!("notready");
returnPoll::Pending;
}
}
}
Terminated => {
panic!("future polledafter completion")
}
}
}
}
}
#[tokio::main]
async fn main() {
let when = Instant::now() +Duration::from_millis(10);
let mainFuture=MainFuture::State0;
mainFuture.await;
}
当然这个Future的实现存在一个明显的问题,通过运行结果也可以知道调试器明显在需要等待的情况下还执行了很多次的Poll操作,理想状态下需要当Future有进展时再执行Poll操作。不断轮徇的Poll其实就退化成了低效的Select,有关于Epoll的话题我们会在下一节详细说明,这里就不加赘述了。
解决之道在于poll函数中的Context参数,这个Context就是Future的waker(),通过调用waker可以向执行器发出信号,表明这个任务应该进行Poll操作了。当Future的状态推进时,调用wake来通知执行器,才是正解,这就需要把Delay部分的代码改一下:
let waker =cx.waker().clone();
let when = self.when;
// Spawn a timer thread.
thread::spawn(move || {
let now = Instant::now();
if now < when {
thread::sleep(when - now);
}
waker.wake();
});
无论是哪种高并发框架,本质上讲都是基于这种Task/Poll机制的调度器,poll做的本质工作就是监测链条上前续Task的执行状态。
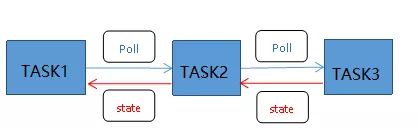
用好Poll的机制,就能避免上面出现事件循环定期遍历整个事件队列的调度算法,Poll的精髓就是把状态为ready的事件通知给对应的处理程序,而基于Poll设计的如tokio框架进行应用开发时,程序员根本不必关心整个消息传递,只需要用and_then、spawn等方法建立任务链条并让系统工作起来就可以了。而Linux中大名鼎鼎的epoll多路复用是基于Poll的一种高并发机制,这种机制一个线程可以监视多个任务的状态,一旦某个任务描述符状态变为就绪,能够通知对应的handler进行后续操作。
简单来说Future是一个在未来才能取得的值类型,Poll是推动Future状态迁移的方法,而Epoll则是只用一个线程,监控多个Future/Task状态的多路复用机制。
C语言-永远的名门少林派
C语言的高并发产品多得数不胜数,从Linux到Redis等经典的操作系统和数据库基本都是基于C语言开发的,甚至我们刚刚提到Linux中高并发的神器Epoll本质上也是一个C语言的程序。C语言的理念就是充分相信程序员自身的能力,语言自身既无语法糖,也无也没有严格的编译检查,因此如果你不能熟练掌握C的话,那么他几乎不会给你输出什么生产力。
但C语言的上限在我们今天要讲的所有语言当中又是最高的,C语言既无虚拟机也无垃圾回收器,它的唯一限制就是计算机的物理性能极限,在前文《这个创造了Github冠军项目的老男人,堪称10倍程序员本尊》曾经介绍过taosTimer的性能不但远远超过了原生的Timer,甚至比基于多路复用的Epoll定时器timerfd也有一定的提升。所以说C语言很像少林派,广开大门、广结善缘,无论是扫地僧这样不世出的绝顶高手,还是看似普通的火工头陀都是少林的门下弟子。
C语言作为编程世界中程序员的母语,这里还是以Tdengine的缓存为例,做一下简单解读,TaosCache的工作原理如下:
1.缓存初始化(taosOpenConnCache):首先初始化缓存对象SConnCache,再初始化哈希表connHashList,并调用taosTmrReset,重置timer。
2.链接加入缓存(taosAddConnIntoCache):首先通过ip、port、username计算其哈希值(hash),然后将此链接(connInfo)加入connHashList[hash]对应的pNode节点,pNode本身又是一个双链表,也会根据添加时间将哈希值相同的connInfo排序,放入pNode双链表中。注意这里pNode是哈希表connHashList的一个节点,而其自身也是一个链表。代码如下:
void *taosAddConnIntoCache(void *handle, void*data, uint32_t ip, short port, char *user) {
int hash;
SConnHash* pNode;
SConnCache *pObj;
uint64_ttime = taosGetTimestampMs();
pObj =(SConnCache *)handle;
if (pObj== NULL || pObj->maxSessions == 0) return NULL;
if (data== NULL) {
tscTrace("data:%p ip:%p:%d not valid, not added in cache",data, ip, port);
returnNULL;
}
hash =taosHashConn(pObj, ip, port, user);//通过ip port user计算哈希值
pNode =(SConnHash *)taosMemPoolMalloc(pObj->connHashMemPool);
pNode->ip = ip;
pNode->port = port;
pNode->data = data;
pNode->prev = NULL;
pNode->time = time;
pthread_mutex_lock(&pObj->mutex);
//以下是将链接信息加入pNode的链表
pNode->next = pObj->connHashList[hash];
if(pObj->connHashList[hash] != NULL) (pObj->connHashList[hash])->prev =pNode;
pObj->connHashList[hash] = pNode;
pObj->total++;
pObj->count[hash]++;
taosRemoveExpiredNodes(pObj, pNode->next, hash, time);
pthread_mutex_unlock(&pObj->mutex);
tscTrace("%p ip:0x%x:%d:%d:%p added, connections in cache:%d",data, ip, port, hash, pNode, pObj->count[hash]);
returnpObj;
}
3.将链接由缓存中取出(taosGetConnFromCache):根据ip、port、username计算其哈希值(hash),取出connHashList[hash]对应的pNode节点,再从pNode当中取出ip、port与需求相同的元素。
Java的RxJava-最具平衡之美的太极剑
基于Java语言编写的高并发产品和C相比也是不遑多让,比如Kafka、Rocket MQ等等精典也都是Java的杰作。与Go和C相比,Java的入门也不算太难,由于垃圾回收器GC的存在,令人头痛的指令问题与内存泄漏在Java的世界中基本上是不存在的。
在JVM虚拟机的加持下,Java语言的下限通常比较高,即使是初级程序员也能通过Java实现比较高的生产力,甚至会比中级程序员使用C的生产力还高;但同样也是JVM虚拟机的限制,Java语言的上限不如C和Rust那么高。但不能否认的是Java是目前在学习难度、生产力、性能、内存消耗等等方面做得最为均衡的语言,这就特别像武当派的太极剑,几乎没有破绽也没有短板,追求平衡与和谐之美。
目前Java的高并发框架以RxJava最为火爆,由于Java太流行了,网上的解读很多,这里就不再列举代码了,在本文的最后再以Java为例,聊一聊高并发中可能存在的问题。
Rust的Tokio-没有菜鸟的逍遥派
Rust是近些年来随着Serverless一起新兴起的语言,表面上看他像是C,既没有JVM虚拟机也没有GC垃圾回收器,但仔细一瞧他还不是C,Rust特别不信任程序员,力图让Rust编译器把程序中的错误杀死在在生成可执行文件之前的Build阶段。由于没有GC所以Rust当中独创了一套变量的生命周期及借调用机制。开发者必须时刻小心变量的生命周期是否存在问题。
而且Rust难的像火星语言,多路通道在使用之前要clone,带锁的哈希表用之前要先unwrap,种种用法和Java、Go完全不同,但是也正在由于这样严格的使用限制,我们刚刚所提到的Go语言中Gorotine会出现的问题,在Rust中都不会出现,因为Go的那些用法,通通不符合Rust变量生命周期的检查,想编译通过都是不可能完成的任务。
所以Rust很像逍遥派,想入门非常难,但只要能出师,写的程序能通过编译,那你百分百是一位高手,所以这是一门下限很高,上限同样也很高的极致语言。
目前Rust的高并发编程框架最具代表性的就是Tokio,本文开头Future的例子就是基于Tokio框架编写的,这里也不加赘述了。
根据官方的说法每个Rust的Tokio任务只有64字节大小,这比直接通过folk线程去网络请求,效率会提升几个数量级,在高并发框架的帮助下,开发者完全可以做到极限压榨硬件的性能。
高并发中要特别小心的坑
无论是RxJava还是Tokio、Gortouine,高并发框架再强大,在追求极致性能的道路上,也会有一些共性的问题需要特别注意,以下给大家列举几个例子。
一、注意分支预测:我们知道现代的CPU都是基于指令流水线执行的,也就是说CPU会提前将未来可能执行到的代码放到流水线上进行解码等处理操作,但遇到代码分支就需要预测才能知道具体下面哪一条指令可能被会执行。
指令预测的典型案例可以看下面的代码:
public class Main {
public static void main(String[] args) {
long timeNow=System.currentTimeMillis();
int max=100,min=0;
long a=0,b=0,c=0;
for(int j=0;j<10000000;j++){
int ran=(int)(Math.random()*(max-min)+min);
switch(ran){
case 0:
a++;
break;
case 1:
b++;
break;
default:
c++;
}
}
long timeDiff=System.currentTimeMillis()-timeNow;
System.out.println("a is "+a+"b is"+b+"c is "+c);
System.out.println("总耗时 "+timeDiff);
}
}
在上述代码中只需要把随机数的取值范围做一下变化,即将max=100改为max=5,那么上述代码的执行时间就至少要上升30%,这就是由于max先于5时变量ran的取值范围是从0到5,此时各分支执行的概率分布比较均衡,没有一个优势分支存在,因此指令预测很可能会失败,从而导致CPU执行效率降低,这个问题需要在高并发的编程场景中高度重视。
二、变量按照缓存行对齐:目前各种主流的高并发框架都是基于多路复用机制的,任务在各CPU核心上的调度基本不太需要程序员去关心,但是在多核场景下程序员需要注意尽量将可变量按照缓存行的大小进行对齐,这样能够避免CPU之间的无效缓存问题,比如以下例子中两个线程分别操作数据arr中的[0]和[1]两个成员。
public class Main {
public static void main(String[] args) {
final MyData data = new MyData();
new Thread(new Runnable() {
public void run() {
data.add(0);
}
}).start();
new Thread(new Runnable() {
public void run() {
data.add(1);
}
}).start();
try{
Thread.sleep(100);
} catch (InterruptedException e){
e.printStackTrace();
}
long[] arr=data.Getitem();
System.out.println("arr0 is "+arr[0]+"arr1is"+arr[1]);
}
}
class MyData {
private long[] arr={
0,0};
public long[] Getitem(){
return arr;
}
public void add(int j){
for (;true;){
arr[j]++;
}
}
}
但只要把arr变成二维数据将操作的变量由arr[j]变成arr[j][0],那么程序运行效率又可以获得极大的提升。
性能和效率是程序员永远的追求,无论是C、Java还是Rust、Go每种语言都有自己的生态位,追求短平快那么一刀流的Go就是不二选择;追求稳定与各方面平衡还是首推武当派的Java,追求极致性能的开发团队建议尝试Rust;追求个人英雄主义的单体天才还是用C更合适,只要选定自己的开发框架,在严格执行最佳实践的基础上,注意分支预测与变量对齐的问题,都能获得非常不错的性能。
作者:马超,CSDN博客专家,阿里云MVP、华为云MVP,华为2020年技术社区开发者之星。
10 月 23-24 日,到长沙参加 1024 程序员节,领略一线的技术专家带来的精彩分享、和众多开发者朋友交流合作,庆祝程序员自己的节日。大会嘉宾包括倪光南院士、龚克院士、王怀民院士、MySQL 之父、Kubernetes 联合创始人、RISC-V国际基金会 CTO、PostgreSQL 全球开发组联合创始人、MongoDB CTO……
