Linux系统(四)之docker
docker:
-
- 一、安装 docker
- 二、docker 卸载
- 三、配置 docker 镜像加速器
- 四、安装 mysql
- 五、安装 oracle
- 六、安装 redis(自)
- 七、部署 springboot 项目
- 八、分布式文件系统 FastDFS(自)
- 九、消息队列 rabbitmq(自)
- 十、docker 远程连接(自)
- 十一、docker 安装 elasticsearch 和 ik 分词
本篇主要内容如下:
一、安装 docker
Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从 Apache2.0 协议开源。 Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。 容器是完全使用沙箱机制,相互之间不会有任何接口(类似 iPhone 的 app),更重要的是容器性能开销极低。
我们可以在常用的服务器系统上安装 Docker 如:windows server、Linux 等。我们实验版本为 centos7,准备一台全新的 centos7 取名为 docker。
1.安装 Docker(yum方式)
yum install docker -y
2.查看是否安装成功
docker version
若输出以下,说明安装成功
Client:
Version: 1.13.1
API version: 1.26
Package version:
Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
3.启动 Docker
相类似的还有 stop,restart
service docker start
4.开机自启
systemctl enable docker
二、docker 卸载
1:查看已安装的 docker 安装包
yum list installed|grep docker
docker.x86_64 2:1.12.6-61.git85d7426.el7.centos @extras
docker-client.x86_64 2:1.12.6-61.git85d7426.el7.centos @extras
docker-common.x86_64 2:1.12.6-61.git85d7426.el7.centos @extras
2:删除安装包
yum –y remove docker.x86_64
yum –y remove docker-client.x86_64
yum –y remove docker-common.x86_64
3:删除 Docker 镜像
rm -rf /var/lib/docker
三、配置 docker 镜像加速器
配置镜像加速器
针对 Docker 客户端版本大于 1.10.0 的用户 您可以通过修改 daemon 配置文件 /etc/docker/daemon.json 来使用加速器(如果文件不存在请新建该文件),文件内容如下:修改后需要执行 systemctl daemon-reload 和 systemctl restart docker 命令。
{
"registry-mirrors":["https://reg-mirror.qiniu.com/"]}
检查加速器是否生效:
检查加速器是否生效配置加速器之后,如果拉取镜像仍然十分缓慢,请手动检查加速器配置是否生效,在命令行执行 docker info,如果从结果中看到了如下内容,说明配置成功。
docker info
......
Registry Mirrors:
https://reg-mirror.qiniu.com
四、安装 mysql
基本概念
仓库:集中存放镜像文件的地方
镜像:一个特殊的文件系统,可以看作可运行的软件包
容器:镜像运行时的实体
镜像仓库:地址,搜索并找到 mysql5.7,下载镜像。
docker pull mysql:5.7
关于镜像常用两个命令:
- docker images 查看下载到本地的镜像
- docker rmi 镜像 id:根据镜像 id 删除本地镜像。
启动容器
docker run -p 3306:3306 --name mysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7
配置说明:
-p 3306:3306:将容器的 3306 端口映射到主机的 3306 端口
-e MYSQL_ROOT_PASSWORD=“123456”:初始化 root 用户的密码
启动完成后 mysql 即可远程连接,docker 会自动将防火墙等处理好。
在使用过程中可能会用到如下命令:
1.如果启动失败,查看错误日志。
docker logs mysql
2.查看运行的容器状态
docker ps
3.查看全部容器的运行状态
docker ps -a
4.停止容器用
docker stop 容器 id
5.再次启动停止的容器
docker start 容器 id 启动
6.删除容器
docker rm 容器 id
五、安装 oracle
查找 oracle 镜像,我们选择精简版 oracle-xe-11g
docker search oracle
拉取镜像
docker pull oracleinanutshell/oracle-xe-11g
启动镜像
docker run -d -p 1521:1521 -e ORACLE_ALLOW_REMOTE=true --name oracle11g oracleinanutshell/oracle-xe-11g
ORACLE_ALLOW_REMOTE 为 true 表示可以远程访问
连接数据库()system 和 sys 的默认密码是 oracle
hostname: localhost
port: 1521
sid: xe
username: system
password: oracle
使用 idea 连接 Oracle
六、安装 redis(自)
从仓库拉取 redis 镜像
docker pull redis
启动 redis
docker run -p 6379:6379 --name redis -d redis
设置容器随 docker 容器自启
docker update redis --restart=always
七、部署 springboot 项目
将项目打包上传 linux 服务器
示例项目下载:链接
创建 Dockerfile 文件
FROM java:8
VOLUME /tmp
ADD demo.jar /demo.jar
ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/demo.jar"]
FROM :表示使用 Jdk8 环境为基础镜像,如果镜像不是本地的会从 DockerHub 进行下载
VOLUME :指向了一个 /tmp 的目录,由于 Spring Boot 使用内置的 Tomcat 容器,Tomcat 默认使用 /tmp 作为工作目录。这个命令的效果是:在宿主机的 /var/lib/docker 目录下创建一个临时文件并把它链接到容器中的 /tmp 目录
ADD :拷贝文件并且重命名(前面是上传 jar 包的名字,后面是重命名)
ENTRYPOINT :为了缩短 Tomcat 的启动时间,添加 java.security.egd 的系统属性指向/dev/urandom作为 ENTRYPOINT
将创建好的 Dockerfile 文件和 jar 包上传到服务器,放在同一文件夹下,进入 jar 包所在文件夹,执行命令
docker build -t demo .
注意:后面末尾有一个空格和一个“.”,demo 是创建的镜像的名字,“.”表示当前目录
查看生成的镜像,并运行 jar 包为容器
docker run -d -p 8080:8080 demo
-d:表示在后台运行
-p:指定端口号第一个 8080 为容器内部的端口号,第二个 8080 为外界访问的端口号,将容器内的 8080 端口号映射到外部的 8080 端口号。
八、分布式文件系统 FastDFS(自)
分布式文件系统(Distributed File System)是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连。
通俗来讲: 传统文件系统管理的文件就存储在本机。
分布式文件系统管理的文件存储在很多机器,这些机器通过网络连接,要被统一管理。无论是上传或者访问文件,都需要通过管理中心来访问。
FastDFS:是由淘宝的余庆先生所开发的一个轻量级、高性能的开源分布式文件系统。用纯 C 语言开发,功能丰富:
①文件存储
②文件同步
③文件访问(上传、下载)
④存取负载均衡
⑤在线扩容
适合有大容量存储需求的应用或系统。同类的分布式文件系统有 GFS(谷歌)、HDFS(Hadoop)、TFS(淘宝)等。
安装 fastDFS
1.首先下载 FastDFS 文件系统的 docker 镜像
docker search fastdfs
2.获取镜像
docker pull delron/fastdfs
3.使用docker镜像构建tracker容器(跟踪服务器,起到调度的作用):
docker run -d --network=host --name tracker delron/fastdfs tracker
4.使用 docker 镜像构建 storage 容器(存储服务器,提供容量和备份服务):
docker run -d --network=host --name storage -e TRACKER_SERVER=192.168.175.128:22122 -e GROUP_NAME=group1 delron/fastdfs storage
5.创建 springboot 项目并导入下面的依赖
com.github.tobato</groupId>
fastdfs-client</artifactId>
1.26.1-RELEASE</version>
</dependency>
配置文件如下
fdfs:
so-timeout: 1501 #超时时间
connect-timeout: 601 #连接超时时间
thumb-image: # 缩略图
width: 60
height: 60
tracker-list: # tracker地址
- 192.168.175.135:22122
6.增加配置类
import com.github.tobato.fastdfs.FdfsClientConfig;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.EnableMBeanExport;
import org.springframework.context.annotation.Import;
import org.springframework.jmx.support.RegistrationPolicy;
@Configuration
@Import(FdfsClientConfig.class)
@EnableMBeanExport(registration = RegistrationPolicy.IGNORE_EXISTING)
public class FastClientImporter {
}
单元测试
import com.github.tobato.fastdfs.domain.StorePath;
import com.github.tobato.fastdfs.domain.ThumbImageConfig;
import com.github.tobato.fastdfs.service.FastFileStorageClient;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
@SpringBootTest
class DemoApplicationTests {
@Autowired
private FastFileStorageClient storageClient;
@Autowired
private ThumbImageConfig thumbImageConfig;
@Test
public void testUpload() throws FileNotFoundException {
File file = new File("C:/Users/Administrator/Desktop/up.png");
// 上传
StorePath storePath = this.storageClient.uploadFile(
new FileInputStream(file), file.length(), "png", null);
// 带分组的路径
System.out.println(storePath.getFullPath());
// 不带分组的路径
System.out.println(storePath.getPath());
}
@Test
public void testUploadAndCreateThumb() throws FileNotFoundException {
File file = new File("G:\\LeYou\\upload\\spitter_logo_50.png");
// 上传并且生成缩略图
StorePath storePath = this.storageClient.uploadImageAndCrtThumbImage(
new FileInputStream(file), file.length(), "png", null);
// 带分组的路径
System.out.println(storePath.getFullPath());
// 不带分组的路径
System.out.println(storePath.getPath());
// 获取缩略图路径
String path = thumbImageConfig.getThumbImagePath(storePath.getPath());
System.out.println(path);
}
}
访问图片地址:
http://192.168.175.128:8888/group1/M00/00/00/wKivgF6ZzFWAa9KfAACRNhf3vVk267.png
九、消息队列 rabbitmq(自)
拉取 rabbitmq 的镜像
docker pull rabbitmq:3.8.3-management
启动 rabbitmq 镜像
docker run --name rabbitmq -d -p 15672:15672 -p 5672:5672 rabbitmq:3.8.3-management
设置 rabbitmq 开机启动
docker update rabbitmq --restart=always
访问rabbitmq浏览器端口
http://192.168.175.128:15672/
默认用户名guest,密码也是guest
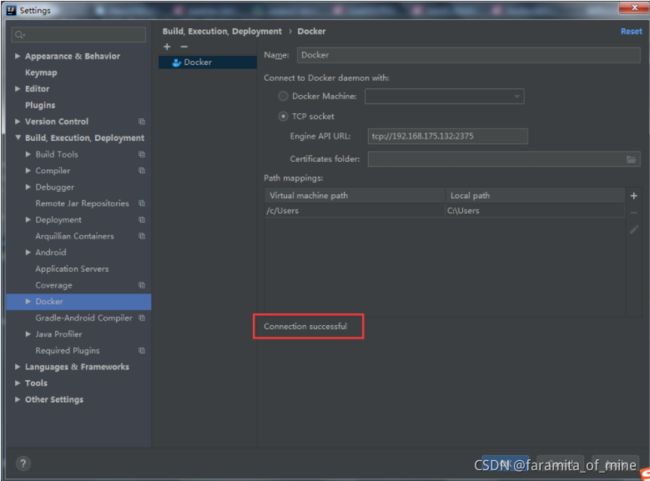
十、docker 远程连接(自)
1.在 /usr/lib/systemd/system/docker.service,配置远程访问。
-H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock \

系统重新加载文件
systemctl daemon-reload
重启 docker
systemctl restart docker
创建 Dockerfile 在 idea 的项目目录下
FROM java:8
VOLUME /tmp
ADD target/docker-demo.jar /app.jar
ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"]
在 Docker 上出现运行图标,点击运行创建镜像
右键通过镜像创建容器,创建容器时指定端口映射即可成功部署。
十一、docker 安装 elasticsearch 和 ik 分词
拉取镜像
docker pull elasticsearch:7.6.2
启动容器
docker run --name es -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -d elasticsearch:7.6.2
进入容器
docker exec -it es /bin/bash
进入 bin 目录后执行下载安装 ik 分词器命令
elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.6.2/elasticsearch-analysis-ik-7.6.2.zip
成功标志:-> Installed analysis-ik
退出容器:exit
重启容器:
docker restart es
发送原生 json 请求测试分词效果
地址:
http://192.168.2.128:9200/_analyze
数据:ik_smart 最少切分;ik_max_word 最细粒度划分!穷尽词库所有可能
{
"analyzer": "ik_smart",
"text": "河南科技大学"
}
返回:
{
"tokens": [
{
"token": "河南",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "科技大学",
"start_offset": 2,
"end_offset": 6,
"type": "CN_WORD",
"position": 1
}
]
}
ES索引相关的基本操作
# 创建索引(数据库)
# 索引库名称:csp ,文档类型名称:mytype ,文档id:1
PUT /csp/mytype/1
{
"name":"兴趣使然的草帽路飞",
"age":"22"
}
# 创建一个csp2索引库:
# 索引库名称:csp2
# 索引库中3个字段:name,age,birthday
# 3个字段的类型为:text,integer,date
PUT /csp2
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "integer"
},
"birthday":{
"type": "date"
}
}
}
}
# 获得索引csp2的相关信息
GET csp2
# 创建索引csp3,文档类型使用默认的_doc,文档id:1
# 数据为:nage,age,birthday
PUT /csp3/_doc/1
{
"name":"兴趣使然的草帽路飞",
"age":22,
"birthday":"1999-01-29"
}
# 查看索引csp3默认的信息
GET csp3
# 查看es健康状态
GET _cat/health
# 查看所有索引库简要信息
GET _cat/indices?v
# 修改索引csp3数据
# 修改的字段name
POST /csp3/_doc/1/_update
{
"doc":{
"name":"海贼王路飞"
}
}
# 删除csp索引库
DELETE csp
ES文档相关的基本操作
# 创建索引my_index,文档类型user,文档id:1
# user:1
PUT /my_index/user/1
{
"name":"草帽路飞",
"age":22,
"description":"海贼王,我当定了!",
"tags":["吃货","船长","未来的海贼王","橡胶果实能力者"]
}
# user:2
PUT /my_index/user/4
{
"name":"海贼猎人索隆1",
"age":22,
"description":"背后的伤疤,是剑士的耻辱!",
"tags":["路痴","副船长","未来的世界第一大剑豪","三刀流剑客"]
}
PUT /my_index/user/5
{
"name":"海贼猎人索隆2",
"age":25,
"description":"背后的伤疤,是剑士的耻辱!",
"tags":["路痴","副船长","未来的世界第一大剑豪","三刀流剑客"]
}
PUT /my_index/user/2
{
"name":"海贼猎人索隆3",
"age":24,
"description":"背后的伤疤,是剑士的耻辱!",
"tags":["路痴","副船长","未来的世界第一大剑豪","三刀流剑客"]
}
# user:3
PUT /my_index/user/3
{
"name":"黑足山治",
"age":22,
"description":"为了天下女性而活!",
"tags":["色胚","厨师","未来海贼王船上的初始","踢技炫酷"]
}
# 获取数据
# 获取user:1
GET /my_index/user/1
# 搜索数据
GET /my_index/user/_search?q=name:路飞
# 搜索数据,通过json构建查询参数
# 搜索得到的结果中:
# hits: 表示索引和文档相关信息
# "total":
# "value": 查询到的结果的总记录数
# "relation": 搜索结果和搜索参数的关系:eq表示相等 lt小于 gt大于
# "_index": 表示索引名称
# "_tyoe": 表示文档类型
# "_id": 表示文档id
# "_score": 表示搜索结果的权重
# "_source": 表示文档中的数据
# 文档中数据的字段名称以及值
GET /my_index/user/_search
{
"query": {
"match": {
"name": "索隆"
}
}
}
# 搜索数据,通过json构建查询参数,加上结果过滤
# query:构建要搜索的条件,match:构建要匹配的内容
# _source: 结果过滤,只获取name和age字段数据
# sort: 排序条件 age:要排序的字段 order:desc 降序
# from:从第几条数据开始0表示第一条,size:每页显示几条数据
GET /my_index/user/_search
{
"query": {
"match": {
"name": "索隆"
}
},
"_source": ["name","age"],
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 1
}
# 搜索数据:使用bool多条件精确查询
# 查询22岁的所有用户,且名字中带有索隆的
# bool: 多条件精确查询
# must: [] 数组中的所有条件都需要符合 === 且and的关系
GET /my_index/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"age": "22"
}
},
{
"match": {
"name": "索隆"
}
}
]
}
}
}
# 搜索数据:使用bool多条件精确查询
# 查询22岁的所有用户,或者名字中带有索隆的所有用户
# bool: 多条件精确查询
# shoud: [] 数组中的所有条件只要有一个符合就行 === 或or的关系
GET /my_index/user/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"age": "22"
}
},
{
"match": {
"name": "索隆"
}
}
]
}
}
}
# 搜索数据:使用bool多条件精确查询,filter过滤
# 查询所有用户,名字中有索隆的,且年龄在22-25之间
# bool: 多条件精确查询,filter:按照字段过滤 === gt lt eq gte大于等于 lte 小于等于
GET /my_index/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "索隆"
}
}
],
"filter": {
"range": {
"age": {
"lt": 22,
"gt": 25
}
}
}
}
}
}
# 根据tags数组中的内容搜索,以空格分割查询条件
# 结果:可以得到路飞和山治的信息
GET /my_index/user/_search
{
"query": {
"match": {
"tags": "厨师 船长"
}
}
}
# 精确查询:
# term: 精确查询,直接通过倒排索引指定的词条进行精确查找
# match: 会使用分词器解析(先分析文档,然后再通过分析的文档进行查询)
# 两个类型: text 和 keyword
# 新建一个索引
PUT my_index2
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"description":{
"type": "keyword"
}
}
}
}
# 向my_index2插入数据
PUT /my_index2/_doc/1
{
"name":"蒙奇D路飞",
"description":"海贼王我当定了!"
}
# 使用分词器查询
# "analyzer": "keyword" 使用ik分词器查询
GET _analyze
{
"analyzer": "keyword",
"text": "海贼王我当定了!"
}
# 使用分词器查询
# "analyzer": "standard" 使用默认分词器查询
# 该分词器会逐个拆分每个词(字)
GET _analyze
{
"analyzer": "standard",
"text": "海贼王我当定了!"
}
# term 精确查询
# 由结果得出:
# keyword类型(description)的字段不会被分词器解析
# text类型(name)的字段会被分词器解析
GET /my_index2/_search
{
"query": {
"term": {
"name": {
"value": "路"
}
}
}
}
# 插入模拟数据
PUT /my_index2/_doc/3
{
"t1":"33",
"t2":"2020-1-17"
}
PUT /my_index2/_doc/4
{
"t1":"44",
"t2":"2020-1-18"
}
PUT /my_index2/_doc/5
{
"t1":"55",
"t2":"2020-1-19"
}
PUT /my_index2/_doc/6
{
"t1":"66",
"t2":"2020-1-20"
}
# 精确查询多个值
GET /my_index2/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"t1": {
"value": "44"
}
}
},
{
"term": {
"t1": {
"value": "55"
}
}
}
]
}
}
}
# (重点)高亮查询:
# highlight:搜索结果高亮展示
# fields:对应的字段数组
# pre_tags: 高亮展示结果的标签前缀,默认是
# post_tags: 高亮展示结果的标签后缀,默认是
GET /my_index/user/_search
{
"query": {
"match": {
"name": "索隆"
}
},
"highlight": {
"pre_tags": ""
,
"post_tags": "",
"fields": {
"name":{
}
}
}
}