爬虫5_QQ音乐《说好不哭》评论爬取及可视化
最近周杰伦的新歌《说好不哭》发布,我的朋友圈也是不断被刷屏,那就趁着热度,我们来看看网友们对这首歌的评论如何吧。
目标网址:https://y.qq.com/n/yqq/song/001qvvgF38HVc4.html?ADTAG=baiduald&play=1#comment_box
分析网页
我们打开QQ音乐找到《说好不哭》,页面下拉可以看到不少网友评论,起码在我爬的时候就已经有8800多页共22万条记录。
- 通过Ctrl+U我们无法从源码中查看到评论内容。
- 通过F12我们可以从渲染后的代码中找到评论内容。
- 所以这种时候我们可以使用Selenium进行爬取,因为Selenium可以爬取渲染后的数据。
- 但是这里我还是选择使用requests。
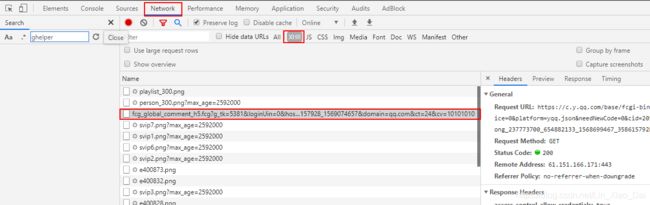
- F12–>Network–>XHR,我们就可以查看js加载的数据,可以看到我红框划出的这个url就是获取评论的接口url(https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg),"?"后面的都是querystring。
- 选中Preseve log,保证我们每次刷新页面的时候上一个页面js文件不会消失。
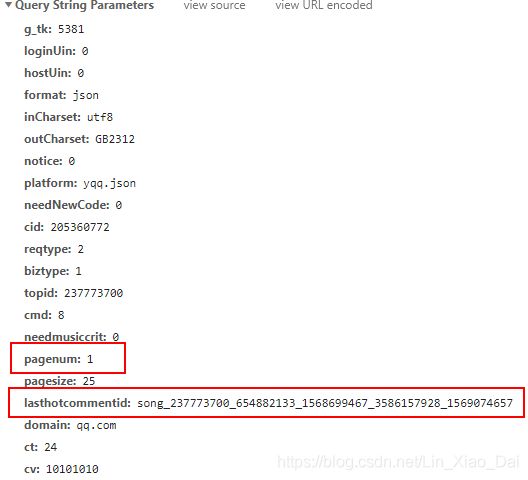
- 多往后翻几页评论我们查看一下url的规律,可以发现只有上图划出的
pagenum和lasthotcommentid是变化的,pagenum是当前评论的页数,lasthotcommentid是上一页评论列表里面的最后一条评论id。
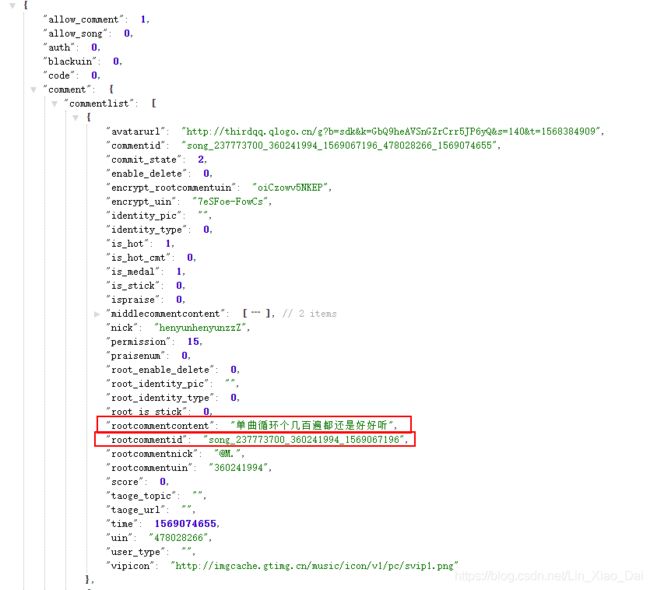
- 我们访问一下这个
Request URL(即在网址栏直接输入这个url),可以看到返回的都是json数据,我们要爬取的就是rootcommentcontent,每次调用API返回的一个json里面包括25条评论,所以最后一条评论的索引应该是24,就像response.json()['comment']['commentlist'][24]这样。

- 通过观察评论我们可以看到有很多用户会发表情,这在源码里的形式如上图红框所示,对于我们而言爬取下来是没有用的,所以在解析json的时候要把这个表情剔除。
小技巧
- 我们可以看到访问评论API的url特别特别长,有很多参数需要加,所以给大家带来一个偷懒的方法。
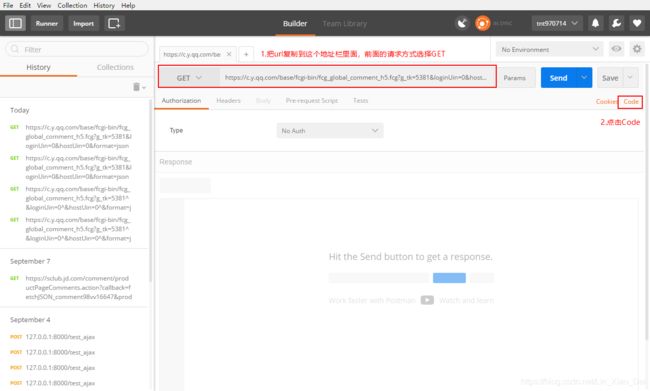
- 打开Postman(https://www.getpostman.com/),将需要访问的url复制黏贴到地址栏,根据网页的请求方式在地址栏前选择相应的请求方式,点击Code。
- 弹出的对话框单击左上角的下拉框,选择Python–>Requests。
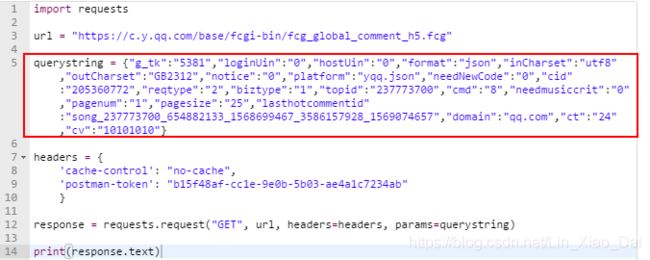
- 可以看到Postman就自动的生成了查询需要带入的参数字典。
- 我们可以直接复制这整个代码使用。
词云图

- 没有做词语的筛选,就直接按照之前爬取的评论做了张图,很奇怪怎么还会有薛之谦?
完整代码_爬取评论
"""
爬取周杰伦新歌《说好不哭》的评论
采用线程池,但好像并没有提速,直接存储在txt里面
自建的免费代理ip只有500多个所以我也就for循环了500页爬取了12500条数据
"""
import datetime
import re
from threading import RLock
import redis
import requests
from fake_useragent import UserAgent
from gevent.threadpool import ThreadPoolExecutor
class ShuoHaoBuKu(object):
def __init__(self):
"""
初始化线程池、锁、文件存储路径
"""
self.redis_conn = redis.StrictRedis(host='localhost', port=6379, db=1)
self.COMMENTT_TEXT = "./说好不哭评论.txt"
self.threadpool = ThreadPoolExecutor(max_workers=50)
self.lock = RLock()
self.count = 0 # 记录爬取了多少条评论
def get_proxy(self):
"""
弹出一个代理并拼接成一个字典进行返回
:return:
"""
proxy = str(self.redis_conn.spop("http_proxy", 1)[0])[2:-1] # 这边根据实际的ip进行更改
print(proxy)
return {
"http": proxy,
}
def start_request(self, url, querystring):
"""
调用self.get_comment_s()函数,返回最后一个comment_id
:param url:
:param querystring:
:return:
"""
last_comment_id = self.get_comment_s(url, querystring)
return last_comment_id
def get_comment_s(self, url, querystring):
"""
获取querystring,请求url
解析json数据
调用self.save_comment_list()循环解析comment_list
:return:
"""
try:
headers = {
'cache-control': "no-cache",
'User-Agent': UserAgent().random,
'postman-token': "87c8f8ff-3604-0736-8658-b4a9ae179516",
}
res = requests.get(url=url, headers=headers, params=querystring, proxies=self.get_proxy())
res.raise_for_status()
res.encoding = "UTF-8"
comment_list = res.json()['comment']['commentlist']
self.threadpool.submit(self.save_comment_list, comment_list)
return comment_list[24]['commentid']
except Exception as e:
print(e)
pass
def save_comment_list(self, comment_list):
"""
获得comment_list
循环comment_list获得每个comment的rootcommentcontent并存入本地
:param json_data:
:return:
"""
self.lock.acquire()
with open(self.COMMENTT_TEXT, "a", encoding='utf-8') as f:
for comment in comment_list:
content = comment['rootcommentcontent']
# 将所有的表情符号都替换为空
r = re.compile(r"\[em].*[/em].", re.S)
content = re.sub(r, '', content)
f.write(content + "\n")
self.count += 1
print(f"\r以爬取{self.count}条评论", end="")
self.lock.release()
def main():
s = ShuoHaoBuKu()
url = "https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg"
querystring = {
"g_tk": "5381", "loginUin": "0", "hostUin": "0", "format": "json", "inCharset": "utf8",
"outCharset": "GB2312", "notice": "0", "platform": "yqq.json", "needNewCode": "0",
"cid": "205360772", "reqtype": "2", "biztype": "1", "topid": "237773700", "cmd": "8",
"needmusiccrit": "0", "pagenum": "0", "pagesize": "25",
"lasthotcommentid": "song_237773700_642435955_1569067902", "domain": "qq.com", "ct": "24",
"cv": "10101010"}
for i in range(500):
querystring['pagenum'] = str(i)
last_comment_id = s.start_request(url=url, querystring=querystring)
# 因为每次访问下一个API都要带上上一个评论列表的最后一个评论id,所以我能想到的也只有这么写了
querystring['lasthotcommentid'] = last_comment_id
if __name__ == '__main__':
start = datetime.datetime.now()
main()
print("共耗时:", datetime.datetime.now() - start)
完整代码_词云图
import jieba
from wordcloud import WordCloud
file = "./说好不哭评论.txt"
img = "shbk.png"
f = open(file, 'r', encoding='utf-8').read()
text = jieba.cut(f)
jieba_text = " ".join(text)
wordcloud = WordCloud(
font_path='./font.ttf',
width=1920,
height=1080,
).generate(jieba_text)
wordcloud.to_file(img)
总结
- 先不管评论怎么样,我感觉歌还挺好听。
- 这次的代码参照了小帅比的公众号,挺不错的一个公众号,写的许多怪东西都是可以用得上的。
https://mp.weixin.qq.com/s?__biz=MzU2ODYzNTkwMg==&mid=2247485571&idx=1&sn=094517114b22a4684988008aecab2639&chksm=fc8bb012cbfc39046339dc5a5711081c8df2ef8217b8acce8ba5c005c6a658d0d1a0c5b465bf&scene=0&xtrack=1&key=d6525bec48886bec7ef1ca46848cf85a7fe078275417e341aa12807abb8c00778f5477ba4de51822d4ba26d8566c8aa7266f89a4007bdc343ae36bba59ffbf11231d5c5dab5d934f8ba92b6cfc785ada&ascene=1&uin=MTM0NTcyMTA0Mg%3D%3D&devicetype=Windows+10&version=62060841&lang=zh_CN&pass_ticket=AkqLQ2zEWlu%2BMqD%2FbanS7gxBaoZ1PzBuxpNW6Fc3zWnaPFIgMAWCmdroW9Y2qnxx
- 这次使用线程池爬取了这12500条评论耗时25分钟,感觉有点慢,可能的原因
– 我也想知道 - 代码后期还是需要完善,希望朋友们能给我一些改进的建议。
- 写的不好还请各位海涵,欢迎各位在底下留言或私信,谢谢。