爬虫(豆瓣电影Top250数据分析)学习笔记
- 学习了有关python爬虫的内容,也算有所收获,写下第一篇博客来对所学进行一个总结,也算督促自己进行主动研究学习的第一步。
主要内容:
- 首先总结一下学习的主要内容:
-
从豆瓣获取数据
-
建立SQLite数据库,将爬取的数据存入数据库中
-
用FLASK开发Web应用程序,即进行数据可视化
前两点主要是有关爬虫的知识,第三点则是有关数据可视化的前端内容。这篇博客就主要写写有关爬虫的内容吧
爬虫:
- 网络爬虫(又称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。简单来讲,爬虫就是一个探测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按钮,查查数据,或者把看到的信息背回来。就像一只虫子在一幢楼里不知疲倦地爬来爬去。
为什么学习爬虫
- 学习爬虫,可以私人订制一个搜索引擎,并且可以对搜索引擎的数据采集工作原理进行更深层次地理解。简单来说,学会了爬虫编写之后,就可以利用爬虫自动地采集互联网中的信息,采集回来后进行相应的存储或处理,在需要检索某些信息的时候,只需在采集回来的信息中进行检索,即实现了私人的搜索引擎。当然,信息怎么爬取、怎么存储、怎么进行分词、怎么进行相关性计算等,都是需要我们进行设计的,爬虫技术主要解决信息爬取的问题。
- 大数据时代,要进行数据分析,首先要有数据源,而学习爬虫,可以让我们获取更多的数据源,并且这些数据源可以按我们的目的进行采集,去掉很多无关数据。在进行大数据分析或者进行数据挖掘的时候,数据源可以从某些提供数据统计的网站获得,也可以从某些文献或内部资料中获得,但是这些获得数据的方式,有时很难满足我们对数据的需求,而手动从互联网中去寻找这些数据,则耗费的精力过大。此时就可以利用爬虫技术,自动地从互联网中获取我们感兴趣的数据内容,并将这些数据内容爬取回来,作为我们的数据源,从而进行更深层次的数据分析,并获得更多有价值的信息。
准备工作
-
下载python,我用的是Python3.9。
-
python的集成开发环境,本文使用Pycharm2020专业版进行开发。
-
运行爬虫需要的相关库。(当然实现的方法不止一种,有兴趣的话可以了解使用不同的库实现爬虫)
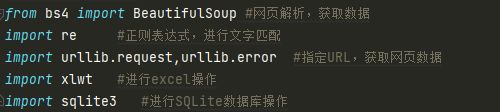
-
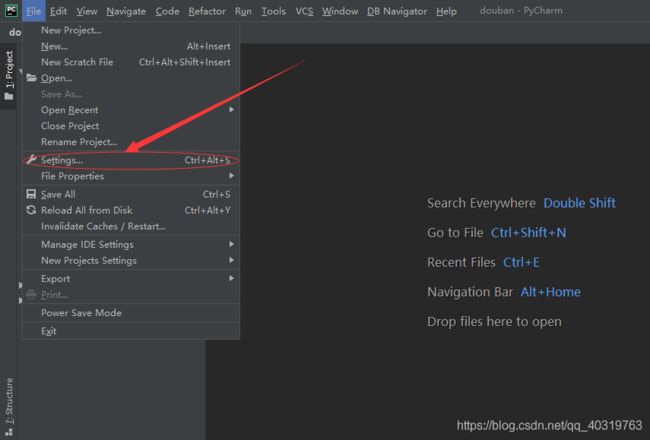
在Pycharm环境中安装库十分方便,在File栏中找到Settings,点击;
-
在弹出窗口中找到Project:xxx,其下有一个Python interpreter,点击,右边窗口有一个“+”号,点击。

-
搜索需要安装的库,点击左下角的Install Package即可安装(这里用安装bs4库为例)。

代码
# iml
#encoding='utf-8'
from bs4 import BeautifulSoup #网页解析,获取数据
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #指定URL,获取网页数据
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作
def main():
baseurl="https://movie.douban.com/top250?start="
datalist = getdata(baseurl)#获取数据存入列表
#savepath="豆瓣电影Top250.xls"#xls文件路径
dbpath="movie.db"#SQlite数据库路径
#saveData(datalist,savepath)#保存数据到xls文件
savedata2db(datalist,dbpath)#保存数据到数据库
#创建正则表达式对象,表示规则(字符串的模式)
#影片详情链接的规则
findLink = re.compile(r'')
#影片图片
findImgSrc = re.compile(r',re.S) #re.S 让换行符包含在字符中
#影片片名
findTitle = re.compile(r'(.*)')
#影片评分
findRating = re.compile(r'')
#找到评价人数
findJudge = re.compile(r'(\d*)人评价')
#找到概况
findInq = re.compile(r'(.*)')
#找到影片的相关内容
findBd = re.compile(r'(.*?)
',re.S)
def getdata(baseurl): #获取数据的代码块
datalist=[]
for i in range(0,10):
url=baseurl+str(i*25)
html=askurl(url)
#逐一解析数据
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('div', class_="item"): # 查找符合要求的字符串,形成列表
#print(item) # 测试:查看电影item全部信息
data = [] # 保存一部电影的所有信息
item = str(item)
# 影片详情的链接
link = re.findall(findLink, item)[0] # re库用来通过正则表达式查找指定的字符串
data.append(link) # 添加链接
imgSrc = re.findall(findImgSrc, item)[0]
data.append(imgSrc) # 添加图片
titles = re.findall(findTitle, item) # 片名可能只有一个中文名,没有外国名
if (len(titles) == 2):
ctitle = titles[0] # 添加中文名
data.append(ctitle)
otitle = titles[1].replace("/", "") # 去掉无关的符号
data.append(otitle) # 添加外国名
else:
data.append(titles[0])
data.append(' ') # 外国名字留空
rating = re.findall(findRating, item)[0]
data.append(rating) # 添加评分
judgeNum = re.findall(findJudge, item)[0]
data.append(judgeNum) # 添加评价人数
inq = re.findall(findInq, item)
if len(inq) != 0:
inq = inq[0].replace("。", "") # 去掉句号
data.append(inq) # 添加概述
else:
data.append(" ") # 留空
bd = re.findall(findBd, item)[0]
bd = re.sub('
bd = re.sub('/', " ", bd) # 替换/
data.append(bd.strip()) # 去掉前后的空格
datalist.append(data) # 把处理好的一部电影信息放入datalist
return datalist
#得到指定一个URL的网页内容
def askurl(url):
head={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}#伪装成浏览器
request=urllib.request.Request(url,headers=head)#对网页头信息进行抓取
html=""
try:
response=urllib.request.urlopen(request)#读取结果
html=response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
#保存数据到excel表
# def savedata(datalist,savepath):
# print('save...')
# book=xlwt.Workbook(encoding='utf-8',style_compression=0)
# sheet=book.add_sheet('豆瓣Top250',cell_overwrite_ok=True)
# col=('电影详情链接','图片链接','中文名','外文名','评分','评价数','概括','相关信息')
# for i in range(0,8):
# sheet.write(0,i,col[i]) #列名
# for i in range(0,250):
# print("第%d条" %(i+1))
# data = datalist[i]
# for j in range(0,8):
# sheet.write(i+1,j,data[j]) #数据
# book.save(savepath)
def savedata2db(datalist,dbpath): #保存数据到数据库
init_db(dbpath) #在dbpath路径创建数据库
conn=sqlite3.connect(dbpath) #打开数据库连接
cur=conn.cursor() #获取操作游标
for data in datalist:
for index in range(len(data)):
if index==4 or index==5:
continue
data[index]='"'+data[index]+'"'
sql='''
insert into movie250(
info_link,pic_link,cname,ename,score,rated,introduction,info)
values(%s)'''%",".join(data)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
def init_db(dbpath): #创建数据库
sql='''
create table movie250
(
id integer primary key autoincrement,
info_link text,
pic_link text,
cname varcher,
ename varcher,
score numeric,
rated numeric,
introduction text,
info text
)
'''
conn=sqlite3.connect(dbpath)
cursor=conn.cursor()
cursor.execute(sql)
conn.commit()
conn.close()
if __name__=='__main__':
main()
代码解析
首先我们要有一个具体的爬虫思路:
- 爬取网页
- 对爬取的网页数据进行解析
- 建立数据库,将解析好的数据分别存入
根据这个思路,我们可以建立主函数(这里有一些注释的代码是把数据存入excel表的,不多赘述,有兴趣的可以尝试以下,代码块是savedata):
def main():
baseurl="https://movie.douban.com/top250?start="
datalist = getdata(baseurl)#获取数据存入列表
#savepath="豆瓣电影Top250.xls"#xls文件路径
dbpath="movie.db"#SQlite数据库路径
#saveData(datalist,savepath)#保存数据到xls文件
savedata2db(datalist,dbpath)#保存数据到数据库
-
首先确定我们的初始地址"https://movie.douban.com/top250?start="
豆瓣top250里有250部电影的信息,以25部为一页,start=0~249,数字代表从某一部电影开始往下数25部作为一页的信息,大家可以点击上面的链接自己在网址那里加数字试试。了解了这个,我们之后就可以利用这个特点做一个循环来遍历每一页的信息啦。 -
接下来我们编写获取数据模块和存储数据模块的函数。
1. 爬取数据
- 在对数据进行解析之前,我们首先得来爬取网页,将网页的信息提取出来。所以我们来定义一个askurl的函数。
#得到指定一个URL的网页内容
def askurl(url):
head={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}#伪装成浏览器
request=urllib.request.Request(url,headers=head)#对网页头信息进行抓取
html=""
try:
response=urllib.request.urlopen(request)#读取结果
html=response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
- 这里名为head的字典有什么用呢?其实这里head是用来“装”的,只有伪装成浏览器的头部信息,你才能获得你想要的网页内容,之后对信息进行抓取时就令头部信息为head了,否则一些网站有反爬程序,能够识别出你是一只爬虫,从而导致程序报错——418(我是一只茶壶)。(如何获得浏览器头部信息呢?这里说一个方法:打开百度,按下“Fn”+“F12”,右边便会有网页的内容弹窗,将网页刷新一下,按下弹窗里有个红色的圆圈,在时间轴那里点一下,然后点击弹窗的左下角name栏中的www.baidu.com,再将右边弹出的Headers滚动条拉到最下面就可以看到啦。)
- 用Request函数将url和头部信息进行封装,再用urlopen来打开url,存入response里,这样就有网页的信息了。再将response里的信息读取到参数html中,这时我们就成功读取了网页的信息了。
2. 解析数据
- 接下来就可以开始对获得的数据进行处理了,网页信息复杂繁多,我们要怎么获得我们需要的信息呢?首先我们可以在豆瓣top250网站的检查网页源代码来找到需要提取的信息,以影片“肖申克的救赎”(Top1)为例,操作如下。

- 然后实际上,假如我们仔细观察网页这一部分代表影片的html代码,会发现我们所需要的信息是有规律的,可以用正则表达式来建立规则,这样就可简单的找到我们所要的信息。
#创建正则表达式对象,表示规则(字符串的模式)
findLink = re.compile(r'') #影片详情链接的规则
findImgSrc = re.compile(r',re.S) #影片图片
findTitle = re.compile(r'(.*)')#影片片名
findRating = re.compile(r'')#影片评分
findJudge = re.compile(r'(\d*)人评价')#找到评价人数
findInq = re.compile(r'(.*)')#找到概况
findBd = re.compile(r'(.*?)
',re.S)#找到影片的相关内容
- 这样获取了网页的源代码并建立正则表达式的规则后,就可以开始获取想要的数据。
def getdata(baseurl): #获取数据的代码块
datalist=[]
for i in range(0,10):
url=baseurl+str(i*25)
html=askurl(url)
#逐一解析数据
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('div', class_="item"): # 查找符合要求的字符串,形成列表
#print(item) # 测试:查看电影item全部信息
data = [] # 保存一部电影的所有信息
item = str(item)
# 影片详情的链接
link = re.findall(findLink, item)[0] # re库用来通过正则表达式查找指定的字符串
data.append(link) # 添加链接
imgSrc = re.findall(findImgSrc, item)[0]
data.append(imgSrc) # 添加图片
titles = re.findall(findTitle, item) # 片名可能只有一个中文名,没有外国名
if (len(titles) == 2):
ctitle = titles[0] # 添加中文名
data.append(ctitle)
otitle = titles[1].replace("/", "") # 去掉无关的符号
data.append(otitle) # 添加外国名
else:
data.append(titles[0])
data.append(' ') # 外国名字留空
rating = re.findall(findRating, item)[0]
data.append(rating) # 添加评分
judgeNum = re.findall(findJudge, item)[0]
data.append(judgeNum) # 添加评价人数
inq = re.findall(findInq, item)
if len(inq) != 0:
inq = inq[0].replace("。", "") # 去掉句号
data.append(inq) # 添加概述
else:
data.append(" ") # 留空
bd = re.findall(findBd, item)[0]
bd = re.sub('
bd = re.sub('/', " ", bd) # 替换/
data.append(bd.strip()) # 去掉前后的空格
datalist.append(data) # 把处理好的一部电影信息放入datalist
return datalist
- 用for循环语句,一共有10页数据,根据上面提到的豆瓣网址start=0、26、51…201,即是25页网址,将html用html.parser解析器进行解析,存入soup,每一次循环中,soup就存储一页的所有数据(包括了一些不属于影片内容的数据)。然后如何提取需要的影片数据呢?可以用find_all函数,它可以查找到符合要求的字符串。用print(item)测试一下,可以看到如下一部一部的影片信息:

- 在for循环中,根据对应建立的正则表达式规则分别匹配影片详情链接、影片海报、片名(有的电影没有外文名,就用一个if语句:若有外文名两者正常添加,否则外文名留空“”)、评分、评分人数、概述和相关内容(相关内容中有一些无效信息,可以一概替换)存入data列表,再将data列表添加到建立的空列表datalist中,这样就成功的获取了影片的相关信息并保存到了一个列表里。
3.保存数据
- 将提取出来的影片信息存入一个数据库里,那么我们首先要建立一个数据库,文章开头已经声明了sqlite库。
def init_db(dbpath): #创建数据库
sql='''
create table movie250
(
id integer primary key autoincrement,
info_link text,
pic_link text,
cname varcher,
ename varcher,
score numeric,
rated numeric,
introduction text,
info text
)
'''
conn=sqlite3.connect(dbpath)
cursor=conn.cursor()
cursor.execute(sql)
conn.commit()
conn.close()
-
此处主要是使用数据库语句来建立表格,创建好之后,可以测试一下,会发现自动生成了这样一个库。其中,id:排名,info_link:详情链接,pic_link:图片链接,cname:中文名,enamel:外文名,score:评分,rated:评价人数,introduction:概述,info:相关信息。

-
创建好数据库,然后打开数据库连接并获取游标。用sql语句执行,把datalist中的数据存到建立的数据库中。这里因为创建数据库时只声明了score和rated是数字类型,其他的都可以用文本类型,所以可以把其他的数据加上双引号。
def savedata2db(datalist,dbpath): #保存数据到数据库
init_db(dbpath) #在dbpath路径创建数据库
conn=sqlite3.connect(dbpath) #打开数据库连接
cur=conn.cursor() #获取操作游标
for data in datalist:
for index in range(len(data)):
if index==4 or index==5:
continue
data[index]='"'+data[index]+'"'
sql='''
insert into movie250(
info_link,pic_link,cname,ename,score,rated,introduction,info)
values(%s)'''%",".join(data)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
- 好了,到此为止,所有的模块都已编写完毕,运行主函数,就可以在数据库里得到所有影片的信息了。
- 噔噔噔噔!!!展示部分效果。

总结
- 这次学爬虫感觉复杂度一般,不过收获很多,首先巩固了一些不牢固的代码知识,然后也见识了一些python的用法,一些常用的方法比如正则表达式,数据库语言等等之类的还是需要补上的。python的应用方面很广,菜狗程序猿要学的还蛮多,之后大概会了解一下之后以后的python学习主要用于什么方面,再去深入研究。奥里给!!!
- 这篇博客也是我的第一篇博客,写的不是很成熟,也欢迎各位大佬指正,之后假如又有什么想法也希望能写下来,感觉还不错。