《python应用实战 爬虫文本分析与可视化》笔记 下
第四章 文本处理
- 正则项表达式
可以理解为匹配模板,与目标字符串匹配,看是否一致。
比如:电子邮箱 [email protected]
匹配的正则项:[a-z]+@[a-z]+\.[a-z]+
① [a-z]+:[a-z]表示a-z的小写字符,+表示可以出现多次。这一项用于匹配zhangsan
② @[a-z]+:用来匹配@abc
③ \.[a-z]+:其中\.的\是转义字符,用来匹配单个英文句号,后面的[a-z]+作用于上面讲的一致
更多详见 python3笔记二十三:正则表达式之元字符
- python的re库
import re
email = '[email protected]'
matched = re.match('[a-z]+@[a-z]+\.[a-z]+',email)
if matched:
print('matched')
pass
else:
print('unmatched')
pass
print(matched.group())
![]()
将其中的email改成
email = '[email protected]'
![]() 其结果也是显示matched
其结果也是显示matched
这是因为re.match()方法在匹配时的过程:在进行字符串匹配时,会从目标字符的第1个字符开始从左至右进行,直到把所有的正则项表达式全部匹配完成。如果匹配成功,会返回一个匹配对象。而这个对象就包含了正则表达式从目标字符串开头到完全匹配的字符,也就是方框内部的部分。而对于剩余部分,re.match()是忽略不处理的,因此结果会显示匹配。

现在我们有一个字符串:###[email protected]###[email protected]
我们想找到其中包含的的电子邮箱,可以利用[a-z]+@[a-z]+\.[a-z]+来进行正则项匹配。
但是此处不能使用re.match()匹配,因为它是从文本的第1个字符开始匹配的。
此处应该使用re.search()方法,它可以从第1个字符中搜索文本中出现的目标字符串。
此处的正则项也应该修改为:[a-z]+@[a-z]+\.[a-z]+#+[a-z]+@[a-z]+\.[a-z]+

使用元字符()可以将()中的正则表达式匹配的内容进行标记
如下图,用()把优先地址的模式标出来,它的作用是将()内的子字符串暂存,供后续使用。这里序号1代表第1个子字符串,序号2代表第2个子字符串,group()和group(0)的效果是一样的,groups()使用了复数,这里会返回一个元组。

使用regx来替换
re.sub()与re.search()的搜索方式一致,都是从第1个文本开始匹配正则表达式。
sub()会用到三个参数,第1个是正则表达式,第2个是用来进行替换的字符串,第3个是目标字符串。
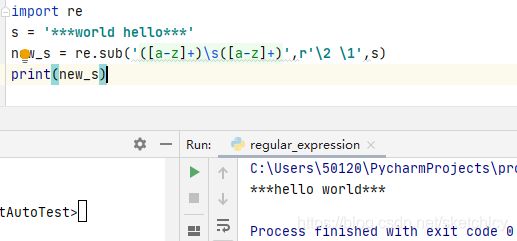
先使用()保存在引用里,\s用来代表空格。使用\number表达式来获取对应的单词,并将匹配的字符串进行替换。
而’\2 \1’前面的r表示原始字符串,因为在直接使用’\2 \1’会导致转义成不能被显示的字符:
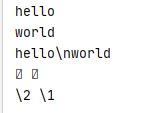
s1 = 'hello\nworld'
s2 = r'hello\nworld'
print(s1) #输出换行
print(s2) #输出不换行
s3 = '\2 \1'
s4 = r'\2 \1'
print(s3) #输出换行
print(s4) #输出不换行
更方便查找 re.findall()
如果想要查找多个邮箱地址,可以使用findall()方法
比如:###[email protected]###[email protected]###[email protected]
import re
email = '###[email protected]###[email protected]###[email protected] '
matched = re.findall('[a-z]+@[a-z]+\.[a-z]+',email)
print(matched)
![]()
返回一个含有所有匹配对象的列表
控制标志
忽略大小写 re.IGNORECASE
import re
s = "APPLE"
matched = re.match("[a-z]+", s)
print(matched) # 结果输入None,不匹配
matched = re.match("[a-z]+", s, re.IGNORECASE)
print(matched) # 匹配
匹配换行符后的字符 re.DOALL
import re
s = "hello\nworld"
matched = re.match(".+", s)
# 由于默认只会匹配"hello"
print(matched)
matched = re.match(".+", s, re.DOTALL)
# 使用re.DOTALL"hello"将匹配整个"hello\nworld"
print(matched)
匹配多行 re.MULTILINE
import re
# 这个字符串其实是3行
s = "Apple\nBanana\n"
print(s)
print("------")
# 默认search()只能匹配第1行
# 而Banana这个单词在第2行
matched = re.search("^B.+", s)
print(matched)
# 开启re.MULTILINE的标志,
# search()就能够匹配多行
matched = re.search("^B.+", s, re.MULTILINE)
print(matched)
对文字替换:replace()和re.sub
replace
# 两个词语之间有2个空格,需要替换掉1个空格
s1 = "Hello Python"
# 使用replace()把会空格全部替换掉
new_s1 = s1.replace(" ", "")
print(new_s1)
# 利用replace()的第3个参数控制替换数量
new_s2 = s1.replace(" ", "", 1)
print(new_s2)
# 替换2个空格
s2 = "Hello Python"
new_s3 = s1.replace(" ", "", 2)
print(new_s3)
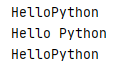
默认情况,replace()会替换所有内容,可以通过第3个参数来限制替换个数。
import re
s3 = 'Hello Python'
new_s3 = re.sub("\s+"," ", s3)
print(new_s3)
s4 = 'The quick brown fox jumps over the lazy dog'
new_s4 = re.sub("\s+", " ", s4)
print(new_s4)
![]()
\s+ 表示多个空格
在re.sub()中,第1个参数表示正则项,第2个参数表示要替换的内容。
- 去掉两端不要的字符
strip()
strip()会替换前后所有目标字符。
import re
s = ' 你好 Python '
new_s = s.strip()
print('{}: |{}|'.format("strip()', new_s))
new_s = re.sub('^\s+|\s+$', '', s)
print('{}: |{}|'.format("re.sub()', new_s))
![]()
拆分方法 re.split()
s = '阿甘正传 Forrest Gump 福雷斯特·冈普'
print(s.split())
但是split()方法会将字符串中的空格也分割,变成如下结果:
![]()
如果使用正则表达式的话:
对于第1个参数,使用\s来匹配空格,结合{2,}来匹配2个及以上的空格。
s = "阿甘正传 Forrest Gump 福雷斯特·冈普"
titles = re.split('\s{2,}', s)
print(titles)
![]()
提取中文 :\w
有时抓取网页会遇到中文和英文混合的情况,要想将中文从混合文本中抓取出来,我们需要用到Unicode编码的范围:\u4E00—\u9FA5。这个范围是常用的中文编码范围,基本覆盖生活中所使用的中文。
import re
s = '肖申克的救赎 /The Shawshank Redemption /月黑高飞(港) / 刺激1995(台)'
chinese = re.findall('\w+', s)
# 输出里英文跟数据也被匹配到了
print(chinese)
# 通过中文的unicode范围来进行匹配
chinese = re.findall('[\u4E00-\u9FA5]+', s)
print(chinese)
# 可以在[ ]元字符里加班一些额外需要匹配的字符
chinese = re.findall('[\u4E00-\u9FA5()0-9]+', s)
print(chinese)

- 电影数据处理
///
第五章 数据分析——Pandas
Pandas是基于python的一个高效、强大的数据分析工具,同时还能结合matplotlib让我们对数据进行可视化。另外,利用python中的Numpy库,他是用来进行科学基础计算的,提供了强大的多维数组对象、复杂的计算方法、随机数及线性代数等众多功能。

- 工具准备
配置JupyterNotebook。通过下面的代码导入Pandas和Numpy
import pandas as pd # 起别名为pd
import numpy as np # 起别名为np
# 设置输出的最大行数跟列数
pd.set_option("display.max_columns", 10)
pd.set_option("display.max_rows", 10)
import matplotlib
# 直接在Notebook中显示Matplotlib绘图
%matplotlib inline
# 设置绘图的字体以及字体大小
matplotlib.rc("font", family="SimHei", size=14)
# 设置绘制的图片大小(单位:英寸)
matplotlib.rc("figure", figsize=(6, 4))
Numpy库的应用
import pandas as pd
import numpy as np
np.random.rand(3) 随机生成一维小数数组
np.random.rand(3,2) 随机生成3*2维小数数组
np.random.uniform(10,50,4)
np.random.uniform(-20.5,40.8,(3,4))
前两个参数是生成数据的范围;第三个参数若是单个数字,则生成数量相同的1维数组;
如果是元组形式,则声称多维数组。
np.random.randint(50,100,(2,4)) 生成int格式数组
Pandas的数据结构常用两种格式:
一种是Series格式,类似于数组,可以用来保存数据;
另一种是DataFrame格式,更接近于Excel表格。
- Series——带有标签index的一维数组
Series中存储的数据类型不仅有数字,还可以是字符串、字典、对象等。

创建数组的方法
import pandas as pd
import numpy as np
numbers=[1,3,5,7]
s1=pd.Series(numbers)
s1
s2=pd.Series(numbers,index=['a','b','c','d'])
s2
前面的数字就是索引,pd.Series()方法会自动加上索引
输出结果都是:
字典中的"Key"被自动转化成了索引
data = {
"a": 1,
"b": 3,
"c": 5,
"d": 7,
"e": 9,
"f": 3,
"g": 7,
"h": 7
}
s = pd.Series(data)
s
获取Series信息
#利用列表或字典属性
list(s.value) 将数据转化成列表
s.size 获取数据长度
s.shape 获取形状
s.dtypes 获取保存的数据类型
s.index 获取series索引
list(s.index) 将索引转换成表
#利用iloc和loc
s.iloc[2:4] 切片
s.iloc[[3,2,0]] 直接根据序号索引
s.loc['a']
s.loc[['d','a','c']] 直接索引数据下标
s.loc[:'c'] 索引到元素'c'
Series进行数学运算
s+10 索引下标全部右移10
s>=3 逻辑运算,结果是bool类型
s[(s>=3)&(s<7)]
一个更详细的例子:
import calendar
# 生成10~100之内的随机小数,共12个
data = np.random.uniform(10,100,12)
# 生成英文月份
month = [calendar.month_abbr[i] for i in range(1,13)]
report2020 = pd.Series(data, index=month)
report2020
report2020.sum() 统计总额
report2020.max() 最大销量
report2020.min() 最小销量
report2020.idmax() 最大销量月份
report2020.idmin() 最小销量月份
report2020.mean() 销量平均值
report2020.median() 销量中间值
report2020.sort_valuse() 降序排列 默认参数ascending=False
字符串数据操作:
str_series=pd.Series(['a quick Fox','jumps over','the lazy Dog'])
str_series
str_series.str.upper() 全部大写
str_series.str.lower() 全部小写
str_series.str.captalize() 首字母大写
str_series.str.contains('fox',case='False') 检查是否包含某字符串
str_series.str.split() 拆分字符串
Series用法 更多详见
- DataFrame——带有标签index的二维数组
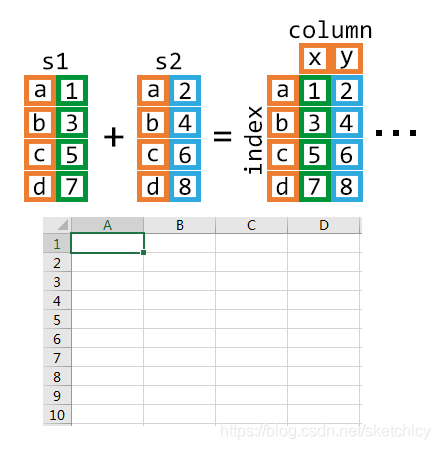
随机生成数组:
import pandas as pd
import numpy as np
array_2d=np.random.rand(2,3)
print(array_2d)
df=pd.DataFrame(array_2d)
df

数据的导入与导出
1. 先生成多个年份的销售报表
import calendar
# 生成英文月份
index = [calendar.month_abbr[i] for i in range(1,13)]
# 生成12行3列的数据,每一列代表每年的1-12月的销量
data = np.random.uniform(10,100,(12,3))
report = pd.DataFrame(data, index=index,
columns=["2018","2019","2020"])
report
利用report.to_csv('report.csv')导出报表为csv格式
利用report.to_excel('report.xls')导出报表为xls格式
