《python应用实战 爬虫文本分析与可视化》笔记 上

第一章 初识python
- 安装python(3.9) anaconda(3)
在JupyterNotebook中选择python3,并执行代码。

在这里插入图片描述

第一次打开JupyterNotebook终端/命令行会生成一个URL,为带有令牌密钥提示。需要将包含这个令牌密钥在内的整个URL复制到浏览器地址中,然后才能打开一个JupyterNotebook。此步骤执行一次即可,无需再次执行。

- 字符串操作
books = 'The Kite Runner'
字符串的索引和切片
print(books)
print(books[0])
print(books[1:5])
print(books[-3:-1])
字符控制方法
books.upper——'THE KITE RUNNER'
books.replace('Runner','Walking')——'The Kite Walking'
books.split('')——['The','Kite','Runner']
books.replace('n','T',1)——'The Kite RunTner'
格式化
'The Kite %s' %('Runner')——'The Kite Runner'
'The Kite {}'.format(5)——'The kite 5'
'The Kite {1}{0}'.format('Runner',5) ——'The kite 5 Runner'
- 列表
info = ['The Kite Runner','长篇小说',226000]
info.append('美籍阿富汗人')
print(info)
——['The Kite Runner','长篇小说',226000,'美籍阿富汗人']
info.insert(2,'上海人民出版社')
print(info)
——['The Kite Runner','长篇小说','上海人民出版社',226000,'美籍阿富汗人']
info.remove('长篇小说')
print(info)
——['The Kite Runner','上海人民出版社',226000,'美籍阿富汗人']
- 处理数据
1.判断
if 2003 in info:
print('这是一本2003年出版的书')
else:
info.insert(2,2003)
print('已添加该书的出版时间:2003年')
pass
2.循环
#遍历表中的内容 range以左闭右开方式取值
for i in range(0,10):
print(i,end='')
for novel in info:
print(novel)
3.嵌套
for novel in info:
if isinstance(novel,list):
for novel_L1 in novel:
print(novel_L1)
else:
print(novel)
pass
pass
- 函数 用关键字def定义
先使用,再调用,最后执行。
def area(): #再调用后执行
radius = 1.3
s1 = 3.14*radius**2
c1 = 2*3.14*radius
print('半径为',radius,'厘米的圆面积为:',s1)
print('半径为',radius,'厘米的圆周长为:',c1)
area() #先使用
- 模块
1. import导入模块
import random
print(random.randint(0,100))
2. from...import导入模块 #from 模块名 import 函数名
from random import *
print(randint(0,100))
3. 利用as起别名
import random as rd
print(rd.randint(0,100))
第二章 网页
-
准备 Chrome
-
网址:统一资源定位符URL,网页:页面,网站:由许多网页和其他资源(图片、视频等)组成
获取URL:右键—复制链接地址 -
HTML:创建网页的方块 HTML: html初识
单标签:'
,双标签:
标签属性:以属性值=“属性值(键值对)的形式出现;可以有多个属性,无先后关系”
<标签名称 属性1=“属性1” 属性2=“属性2”>元素内容

-
CSS与class:网页装饰
元素选择器: 通过标签名选择元素。格式:选择器{声明(特性:特征值)}h1 { color : grey; text-align : center;}
id选择器:对于,可以直接通过标签名称来定位其样式。比如:,而CSS规则的叠加性会使得所有的标签都具有同样效果。
类选择器:标签相同的CSS类名设置相同的样式。比如:定义一个大盒子类,JavaScript和id:增加网页互动
<html> <head> <title>Hello JavaScripttitle> <script> function sayHello(){ document.getElementByid("Hello").innerHTML = "Hello JavaScript!"; } function turnRed(){ document.getElementByid("Hello").style = "color : red;"; } script> //script中的代码就是JavaScript //使用document.getElementByid选择html元素 head> <body> <h1 id="hello">h1> <button onclick="sayHello()">Say hellobutton> <button onclick="turnRed">Turn redbutton> body> //document.getElementByid方法中传递id的值 html>网页中会显示两个按钮。点击
"Say hello"按钮会出现"Hello JavaScript!",点击"Turn red"按钮文本颜色变红。- 网页分析工具 ChromeF12 谷歌开发者工具详解 -Network
打开chrome,F12直接打开"开发者工具",将鼠标移到不同网页元素,html代码会跳转变化,相反也可用。

7.HTTPget和post请求
get请求:单纯获取网站信息。
post请求:将用户输入数据返回给网站。例如输入用户名和密码,这些数据就通过post请求发送给网站。状态码 含义 200 请求成功,请求的内容会和响应一起返回给浏览器 304 请求的内容与上次一样,浏览器缓存中有该内容 404 请求的资源在网站服务器中不存在 500 网站服务器出现错误 浏览器端cookie和服务器端session
尘世风—浅谈cookie、session
比如:
①用户输入了自己的用户名和密码,通过http的post请求发送给网站的服务器;
②网站服务器收到请求后,会对用户名和密码进行验证。如果通过验证,就会给用户保存一个会话(session)表示用户已经登录成功,同时返回给浏览器请求设置200的响应码,并将正确登录的html代码放在http响应的消息体里。并且,网站在响应的头部增加了一个信息Set=Cookie:session=abc123xyz,session=abc123xyz是用户在网站上登录会话的一个标识;
③浏览器在收到登陆成功的http相应时,会发现响应头里有Set=Cookie的信息,并且会把网站会话标识保存在浏览器的cookie中,cookie是保存在浏览器里的一个小文件。以后每次浏览器在访问网站时,都会在请求头部加上cookie,把session=abc123xyz发送给网站,网站将这个字符串与自己保存的会话相比较,如果确认用户已经登录过,则直接相应登录后的网页。
④登录的会话会被网站设置有效期,或者用户主动清除了cookie,则网站会判定没有登录过。http交互过程
利用chrome打开网址https://tools.ietf.org/html/rfc2616 并按下F12网页有三个请求,一个文档,三个png图片。

单击第一个条目,会出现第一个条目信息的HTTP请求/相应信息窗口。

可以通过这几个按钮切换视图,查看不同信息。
Headers:指的是http请求/响应的头部。包含了General、Response Headers(响应头部)、Request Headers(请求头部)。

General是总结性的信息,通常包含http的请求行(Request-line)和http相应的状态行(Status-line)信息。比如请求的URL,http请求方法,响应状态码等。

Response Headers(响应头部)和Request Headers(请求头部)信息较多

User-Agent是http请求用来向服务器传递浏览器信息,由于不需要登录,因此没有cookie相关信息。

Preview:对条目进行预览,结果与浏览器窗口显示内容一致。但如果点击"rfc.png",预览结果则是图片。

Response:用来显示http响应的消息体,第一个条目请求的是网页,窗口显示的就是对应网页的html代码。

8. 以URL结束URL的简单格式:https://网站域名/路径
示例:https://movie.douban.com/top250?start=0&filter=
其中以?开头的?start=0&filter=是URL的参数参数名 参数值 start 0 filter 空 那么URL格式就变成https://网站域名/路径?参数1=参数值1&参数2=参数值2…
这两个参数的作用在界面中显示为:

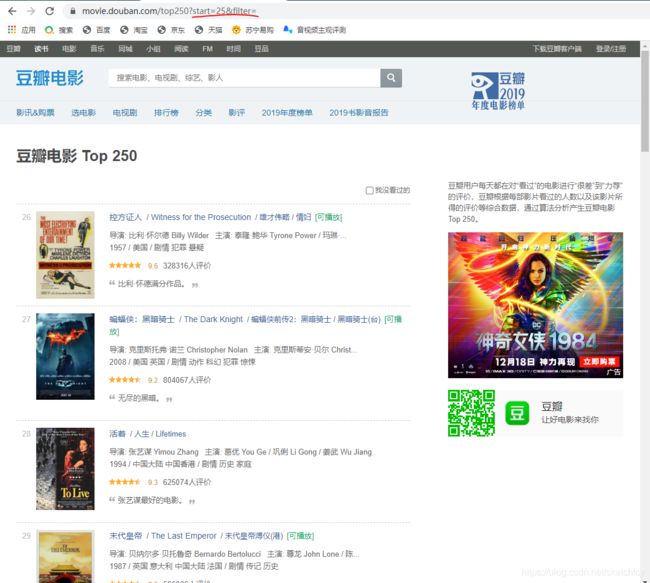

参数1start的作用是不是显而易见呢?那么另一个参数filter,没有参数值,但却一直以filter=的形式存在在URL的参数中。如果去掉,页面显示效果和未去掉一样。这说明如果filter参数为空,不传递也是可以的。
不止是翻页功能,URL参数还能控制网页的其他内容。
第三章 数据抓取
- 工具准备
anaconda开发工具套件里的request库,可直接在Jupyter里使用。
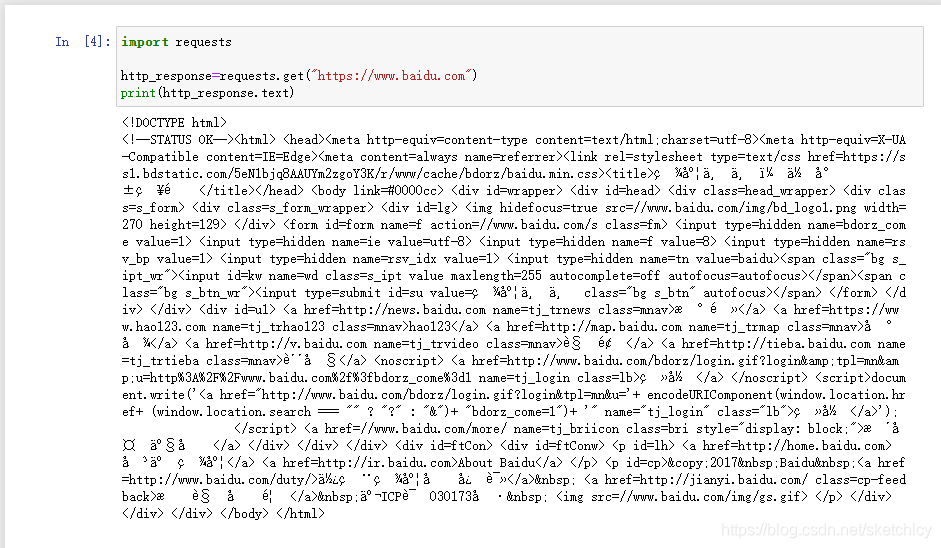
可能出现的问题:python interpreter is in a conda environment, but the environment has not been activate解决方法- 代码使用requests库发送了一个http的get请求。
http的请求直接保存在http_response变量里。
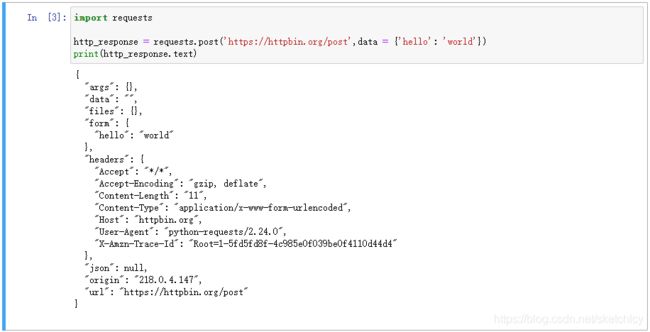
- 代码发送post请求。
post请求使用requests.post()方法向网站发送数据,把一个python字典{‘hello’: ‘world’}赋值给post()方法。字典里的数据将会作为POST请求的消息体传递给httpbin.org/post这个URL,响应如下:
- Xpath和lxml.html
lxml是用来处理XML和HTML的python第三档工具库,通常我们会使用到里面的html工具,也就是lxml.html。
而在lxml.html库中有一个常用方法:lxml.html.fromstring(),这个方法会把我们通过requests库获取的HTML文本文件,转换成可以分析的HTML对象。
这个HTML对象,可以当作通过chrome的开发者选项F12来分析的网页,可以通过鼠标来定位元素。XML是eXtensible Markup Language(可标记扩展语言)的缩写,它可以用来查找HTML元素及属性,它与HTML在结构上非常接近。但在代码中,我们无法用鼠标定位元素,因此XPath方法就能派上用场。XPath表达式形如:
//*[@id="screening"]/div[2]/ul/li[7]/ul/li[1]XPath使用实例:
根据下列html代码来获取元素<html> <head> <title>XPath示例title> head> <body> <div class="fruit"> #<body>中第一个<div>元素 水果列表: #<div>大盒子里有1个<ul>列表 <ul> #<ul>列表里有3个<li>元素 <li id="apple">苹果li> <li>香蕉li> <li class="special">西瓜li> ul> div> <div class="vehicle"> #<body>中第一个<div>元素 交通工具列表: #<div>大盒子里有1个<ul>列表 <ul> #<ul>列表里有3个<li>元素 <li>汽车li> <li>火车li> <li class="special">飞车li> ul> div> body> html>①选择所有
元素://div②选择所有“水果列表”的
元素://div[@class="fruit"]③选择所有“水果列表”的
元素下的元素://div[@class="fruit"]./li如果未加.,代码会无视当前位置而选择所有的元素④选择“苹果”元素:
//li[@id="apple"]在html中,id属性是唯一的⑤选择“交通工具列表”下,带有
class="special"属性的交通工具://div[@class="vehicle"]/li[@class="special"]⑥选择第一个
元素://div[1]
XPath的第一个元素是从1开始的,pythono从0开始⑦不使用
//的方法:需要写出完整路径/html/body/div/ul/liXPath会选择所有的6个元素XPath的表达式 功能 / 从当前html根目录中选择元素。如 /html/body/div会选择html目录下,body元素中所有div元素// 选择所有目录下的所有元素。如 //div,会选择html目录中所有div元素. 选择当前元素。如 .//li,会选择当前元素下面的所有li元素@ 选择html元素的属性。 //element[n] 选择所有element元素的第n个元素 //*[@attr=“abc”] 选择所有attr="abc"的任何元素 实战:利用lxml.html来进行XPath的实际应用
先将上面的代码保存成lxml.html文件,在python中运行代码。import lxml.html with open('xpath.html', 'r', encoding='utf-8') as f: # 通过lxml.html.fromstring()方法 # 将保存在xpath.html中的HTML代码转换成HTML对象 html = lxml.html.fromstring(f.read()) print('HTML对象: {}'.format(html)) print('\n实例一:选择所有的元素(2个):') all_div = html.xpath('//div') print(all_div) print('\n实例二:选择“水果列表”的元素(1个):') fruit_div = html.xpath('//div[@class="fruit"]') print(fruit_div) print('\n实例三:选择所有的- 元素(6个):'
) all_li = html.xpath('//li') print(all_li) print('\n实例四:先选择“水果列表”再选择下面的- ') # 由于xpath()方法会返回一个列表,而且这个列表只有一个元素, # 所以使用序号0来选择列表中的元素 fruit_div = html.xpath('//div[@class="fruit"]')[0] # XPath使用"."表示从当前
开始选择 fruit_li = fruit_div.xpath('.//li') # XPath不使用"." wrong_fruit_li = fruit_div.xpath('//li') print('使用了"."的选择结果(3个):') print(fruit_li) print('未使用"."的选择结果(6个):') print(wrong_fruit_li) print('\n实例五:选择“苹果”元素(1个):') apple_li = html.xpath('//li[@id="apple"]') print(apple_li) print('\n实例六:选择“交通工具列表”下面带有“class="special"”属性的交通工具(1个):') # 这种方式就需要提供完整的嵌套路径,如/div/ul/li的上一级 vehicle_special_li = html.xpath('//div[@class="vehicle"]/ul/li[@class="special"]') print(vehicle_special_li) print('\n实例七:选择第一个元素(1个):') first_div = html.xpath('//div[1]') print(first_div) print('\n实例八:选择所有带有class="special"的元素(2个):') special_li = html.xpath('//*[@class="special"]') print(special_li) print('\n实例九:不使用"//"的选择方式(6个):') full_path = html.xpath('/html/body/div/ul/li') print(full_path)
- robots.txt
Web Robot也称为网络机器人,通常是搜索引擎用来索引互联网内容的程序。爬虫也属于网络机器人的一类。
存在于网站域名下的robots.txt规定了网站的哪些内容可以被抓取,哪些内容不能被抓取。
robots.txt通常有User-Agent、Allow和Disallow几个关键字,User-Agent就是HTTP头部的User-Agent,Allow和Disallow后面通常指定了特定的URL前缀,表示允许或者禁止访问的页面。

一般在数据抓取之前,会查看域名下是否有robots.txt文件。通过浏览器打开域名/robots.txt来检查协议内容,确定要抓去的数据是否被协议所允许。但是我们不能无限制抓取,避免给服务器造成过大压力。在需要限制程序抓取频率时,使用python中的time.sleep()实现。- 实例:抓取豆瓣电影(movie.douban.com)排名第一的电影标题

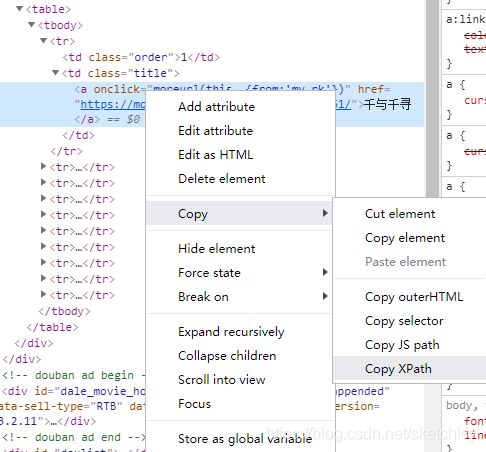
通过上面的操作抓取到的XPath(规范化后的HTML代码)://*[@id="billboard"]/div[2]/table/tbody/tr[1]/td[2]/a
在获取html文本后,利用lxml.html.fromstring()将其转换成可以使用XPath分析的对象,并保存在变量html中,再调用html.path(),把前面从浏览器里获取的XPath作为xpath()参数传进来,这样就可以获取电影标题的元素了,这里的html.path()方法返回值是数组类型。最后使用title[0].text_content()来获取排名第一的电影标题。import requests import lxml.html # 获取豆瓣电影首页 http_response = requests.get('https://movie.douban.com', headers=myheaders) # 设置中文编码 http_response.encoding = 'utf-8' html = lxml.html.fromstring(http_response.text) # 通过xpath来获取排名第一个电影 title = html.xpath('//*[@id="billboard"]/div[2]/table/tr[1]/td[2]/a') print(title) print(title[0].text_content())
总结网页抓取步骤:
①获取html文本:通常使用requests库实现,使用get或post方法发送http请求。有时会设置请求的头部,或者一些中文编码,以防止乱码出现
②转换html对象:使用lxml.html.fromstring()将html代码转换成可以使用XPath分析的对象
③使用谷歌开发者工具获取元素的XPath:找到网页代码,copy XPath
④获取元素:使用lxml.html的xpath()方法获取元素,最后使用title.text_content()方法获取文本6.1 抓取豆瓣电影(movie.douban.com)所有排名的电影标题
import requests import lxml.html # 获取豆瓣电影首页 http_response = requests.get('https://movie.douban.com', headers=myheaders) # 设置中文编码 http_response.encoding = 'utf-8' html = lxml.html.fromstring(http_response.text) # 通过xpath来获取所有电影 titles = html.xpath('//*[@id="billboard"]/div[2]/table/tr/td[2]/a') for title in titles: print(title.text_content())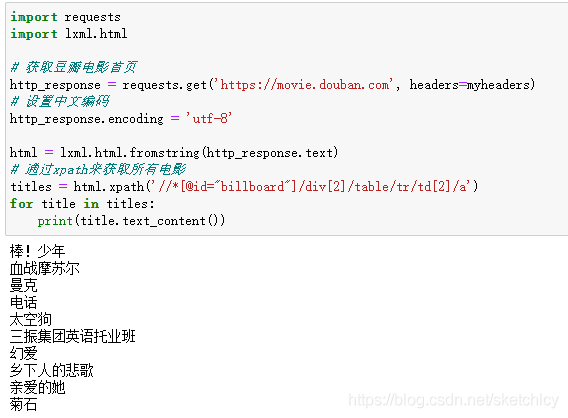
- 另类网页的抓取
对于URL不固定的网页,比如会自动加载数据的网页豆瓣电影排行榜
中任选一个电影分类:惊悚片

获取到的XPath地址://*[@id="content"]/div/div[1]/div[6]/div
使用下面的代码获取电影元素
import requests import lxml.html http_response = requests.get('https://movie.douban.com/typerank?type_name=%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action=', headers=myheaders) http_response.encoding = 'utf-8' html = lxml.html.fromstring(http_response.text) movies = html.xpath('//*[@id="content"]/div/div[1]/div[6]/div') print(movies)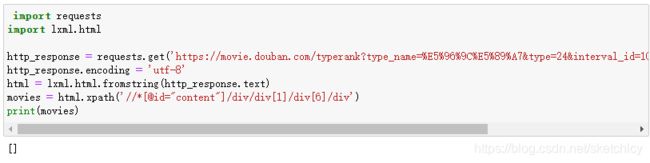
此时不会获取任何元素。这是因为我们在抓取静态页面时,我们将数据定义在JavaScript的变量里,通过这些数据增加表单的内容。而通过筛选http请求,其中有一个分类是XHR,通常用来加载JavaScript需要的数据。
通过不断下拉页面,左边网页增加内容时,右边的数据资源列表也会新增。用代码抓取网页没有数据的原因:因为这些数据是通过浏览器JavaScript代码之后加载数据重新生成的网页,而抓取网页的代码是没有运行JavaScript的功能的,所以只是抓取到了未运行JavaScript之前的html代码,因此也会有电影的数据了。看一下最后一条数据的XHR请求的资源:

网页中的XHR请求,通常会返回一个json数组,而json数组可以和python字典,通过json库进行转换。对于这种类型的网页,我们一般不使用
lxml.html库。因为可以直接通过分析出来的URL获取数据。
复制网页URL:https://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action=&start=40&limit=20
我们可以参照抓取多页数据的方法:import requests http_response = requests.get('https://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action=&start=40&limit=20', headers=myheaders) # 直接读取返回的JSON数据 movie_data = http_response.json() print(type(movie_data)) for movie in movie_data: print(movie) print('----------------分隔----------------')
由于请求的URL相应是一个json数组,通过http_response的json()方法可以直接获取。代码中
print(type(movie_data))直接打印movie_data的类型,可以确认http_response.json()方法把json数组转换成了python列表对象。for movie in movie_data: print(movie)直接利用for循环把列表里的电影数据打印,每个电影数据都是一个python字典。上面抓取的网页有一个人特点,它通常是浏览器里下载的一些网页,然后再通过浏览器的一些事件,如用户鼠标滑动,发送一些XHR请求来获取服务器响应的数据。收到数据后利用JavaScript处理数据,将网页内容更新。对于动态的网页,通常直接通过抓取XHR请求的URL来直接完成。
你可能感兴趣的:(学习,javascript,爬虫,数据可视化)