opencv官方手册(四)
Shi-Tomasi 角点检测 & 适合于跟踪的图像特征
较Harris就采用了另一种打分方式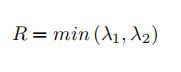
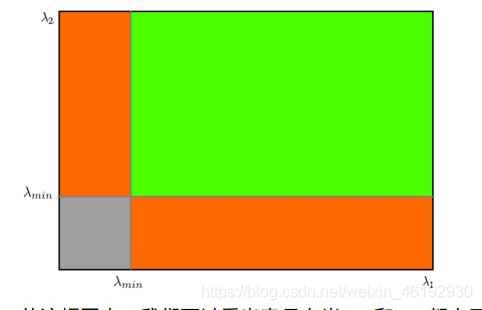
当 λ1 λ2 都大于最小值时就认为是角点(绿色部分)。
corners=cv.goodFeaturesToTrack(image, maxCorners, qualityLevel, minDistance[, corners[, mask[, blockSize[, useHarrisDetector[, k]]]]])
'''
image 8位单通道图像,灰度图
maxCorners 返回的最大角点数(最可能的),小于等于0就没有限制
qualityLevel 图像角点的最小可接受参数,质量测量值乘这个就是最小特征值,小于这个的就抛弃。
minDistance 返回的角点之间的最小欧式距离。
mask 检测区域。
blockSize 用于计算每个像素领域上的导数协变矩阵的平均块大小
useHarrisDetector 选择是否采用Harris角点检测, 默认false
k Harris 检测的自由参数。
通过设置角点的质量水平(0-1),低于的就抛弃,最后在设置两个角点之间的最短欧氏距离。
找到角点,将合格的角点按质量进行降排序,函数采用角点质量最高的那个,然后将周围(最小距离)内的
其他角点删除,按这样返回N 个最佳角点。
'''
img = cv2.imread('17.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
corners = cv2.goodFeaturesToTrack(gray,10,0.01,10) # 只要十个
corners = np.int0(corners)
for i in corners:
x,y = i.ravel()
cv2.circle(img,(x,y),9,(0,0,255),-1)
cv2.imshow('dst',img)
cv2.waitKey(0)
cv2.destroyAllWindows()

SIFT
尺度不变特征变换。可以看看以前的全景拼接小程序
使用的是python 3.6 opencv 3.4.2
img = cv2.imread('17.jpg')
gray= cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
sift = cv2.xfeatures2d.SIFT_create()
kp = sift.detect(gray,None)
img=cv2.drawKeypoints(gray,kp,None) # 加上这个flage 可以在关键点位置绘制圆圈
img2=cv2.drawKeypoints(gray,kp,None,flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imshow('dst',img)
cv2.imshow('dst2',img2)
cv2.waitKey(0)
cv2.destroyAllWindows() # 大小代表关键点大小,和方向。
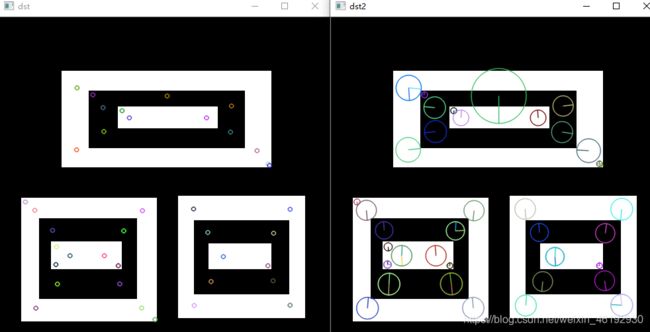
找到关键点就可以受用 sift.compute() (找到了关键点)or sift.detectAndCompute() (还没找到关键点就用这个一步到位直接找到关键点并计算描述符)计算关键点描述符
一般就用第二个方法,一步到胃
def get_kps_feature(image):
descriptor = cv2.xfeatures2d.SIFT_create()
kps,feature = descriptor.detectAndCompute(image,None) # 得到关键点列表和描述符
return np.float32([kp.pt for kp in kps]),feature
改进的SURF 算法
img = cv2.imread('5.jpg')
surf = cv2.xfeatures2d.SURF_create(400, nOctaves=4,
extended=False, upright=True)
kps,feature = surf.detectAndCompute(img,None)
print(len(kps),surf.getHessianThreshold())
>>> 3510 400.0 # 特征点有点多,增大阈值
surf.setHessianThreshold(30000)
kps,feature = surf.detectAndCompute(img,None)
print(len(kps),surf.getHessianThreshold(),surf.descriptorSize()) # 查看关键点描述符的大小
>>> 23 30000.0 64
img2 = cv2.drawKeypoints(img,kps,None,(255,255,0),4)
cv2.imshow('dst2',img2)
cv2.waitKey(0)
cv2.destroyAllWindows()

更快的 FAST 算法
用于SLAM(同步定位与地图构建),移动机器人啥的。

图像中选择一个像素点p,判断是不是关键点,Ip 是P 点的灰度值,t0 就是选择的阈值,对p 点周围选择 16个像素进行测试,如果存在n 个连续像素点的灰度值高于 Ip + t0 ,或者低于 Ip - t0 ,就认为是一个角点。
为了更快的效果会对候选点的周围每个90度的点 1,9,5,13 进行测试(先 1,9 符合阈值再测试 5,13),四个点中有三个就认为是角点。否则就放弃,效率很高但问题是候选点很多,可能都连在一起,选择也不是最优的。
所以采用了机器学习的角点检测器。
- 选择一组训练图片,
- 使用 FAST 算法找出每幅图像的特征点
- 对每一个特征点将其周围 16 个像素存储成一个向量,对所有图像都这样做构建一个特征向量P。
- 每个特征点的16 像素点都属于一下三类

- 根据这些像素点的分类,将特征向量P 也分成 3 个子集 Pd, Ps, Pb。
- 定义布尔值 Kp, 如果P 是角点就 是 True, 否则就是 False
- 使用ID3 (决策树分类器)根据 Kp 进行分类,
- 递归地将其应用于所有子集,直到其熵为零为止。
- 将构建好的决策树模型运用于其他图像的快速检测。
- 非极大值抑制解决检测到的特征点相连的问题,为所有特征点构建一个打分函数V,V 像素点P 与周围 16 个像素点差值的绝对值之和。计算临近的两个特征点的打分,忽略V 值低的特征点。
FAST 最快,但再噪声很高的时候不稳定。
'''
邻域设置为下列 3 中之一:
cv2.FAST_FEATURE_DETECTOR_TYPE_5_8,c
v2.FAST_FEATURE_DETECTOR_TYPE_7_12
和 cv2.FAST_FEATURE_DETECTOR_TYPE_9_16
'''
img = cv2.imread('p2.jpg',0)
fast = cv2.FastFeatureDetector_create(
threshold=40,
nonmaxSuppression=True,
type=cv2.FAST_FEATURE_DETECTOR_TYPE_9_16)
kp = fast.detect(img,None)
img2 = cv2.drawKeypoints(img,kp,None,color=[255,25,0])
print ("Threshold: ", fast.getThreshold()) # 阈值
print ("nonmaxSuppression: ", fast.getNonmaxSuppression()) # bool值是否使用非极大值抑制
print ("Total Keypoints with nonmaxSuppression: ", len(kp)) # 特征点的个数
Threshold: 40
nonmaxSuppression: True
Total Keypoints with nonmaxSuppression: 221 # 这是使用了非极大值抑制的结果
fast.setNonmaxSuppression(0)
kp = fast.detect(img,None)
print ("Total Keypoints with nonmaxSuppression: ", len(kp)) # 特征点的个数
img3 = cv2.drawKeypoints(img, kp,None, color=(255,0,0))
cv2.imshow('yes',img2)
cv2.imshow('no',img3)
cv2.waitKey(0)
cv2.destroyAllWindows()
Total Keypoints with nonmaxSuppression: 471 # 没有使用的结果,可以看到特征点都连一块了。

BRIEF(Binary Robust Independent Elementary Features)
SIFT SURF 都需要找到描述符,但这样会占用大量内存(64维 512 个字节),BRIEF 就是不计算描述符直接找到一个二进制字符串,然后通过汉明距离进行匹配。BRIEF 是一种特征描述符,不提供查找特征的方式,所以还需要使用其他特征检测器,STAR,SIFT SURF 等。
主要思路就是在特征点附近随机选取若干点对,将这些点对的灰度值的大小,组合成一个二进制串,并将这个二进制串作为该特征点的特征描述子。BRIEF最大的优点在于速度快,然而其缺点也相当明显,主要有以下几方面:
- 不具有旋转不变性;
- 不具有尺度不变性;
- 对抗噪声性能差。
img = cv2.imread('p2.jpg',0)
star = cv2.xfeatures2d.StarDetector_create() # 创建STAR 选择器 BRIEF 提取器
brief = cv2.xfeatures2d.BriefDescriptorExtractor_create()
kp = fast.detect(img,None) # 找特征点
kp, des = brief.compute(img, kp) # 计算描述符
print(brief.descriptorSize()) # 描述符的字节数,默认32 可以 16, 64
print(des.shape,len(kp))
>>> 32
(2322, 32) 2322
ORB
是有专利保护的 SIFT SURF 的替代品。基本就是 FAST BRIEF 关键点描述器的结合体并增强的性能。比SURF 还要快,描述符也好得多。
也就是说可以再opencv 4中使用了。。。

nfeature 要保留特征的最大数目,
scoreType 设置使用 harris or fast 进行打分对特征进行排序,默认 harris 。
WTA_K 决定了产生每个描述符需要使用的像素点的数目,默认一次两个点。
img = cv2.imread('p2.jpg',0)
orb = cv2.ORB_create()
kp = orb.detect(img,None)
kp,des = orb.compute(img,kp)
img2 = cv2.drawKeypoints(img,kp,None,color=(0,255,0), flags=0)
cv2.imshow('yes',img2)
cv2.waitKey(0)
cv2.destroyAllWindows()
特征匹配
Brute-Force 暴力匹配
选取一副图像的一个关键点然后一次与第二幅图像的每个关键点进行描述符距离测试,然后返回距离最近的关键点。cv2.BFMatcher() 两个可选参数
normType 指定距离测试类型,默认 cv2.Norm_L2,适合SIFT SURF 。对于ORB BRIEF 等,使用cv2.NORM_HAMMING 汉明距离。
crossCheck 默认False,设置为 True,匹配条件就更加严格,就是两个特征点互相都是距离最近的才可以。
匹配方法:BFMatcher.match() 和 BFMatcher.knnMatch() ,第一个返回最佳匹配,第二个返回 K 个最佳匹配。就是每个点绘制 K 条匹配直线。
然后就可以使用 cv2.drawMatches() 来绘制匹配点了。会将两幅图像水平排列再最佳匹配点之间绘制直线。
img1 = cv2.imread(r'D:\opencv\sources\samples\data\box.png') # 查询图像
img2 = cv2.imread(r'D:\opencv\sources\samples\data\box_in_scene.png')# 训练图像
orb = cv2.ORB_create()
kp1, des1 = orb.detectAndCompute(img1,None) # 查找关键点和描述符
kp2, des2 = orb.detectAndCompute(img2,None)
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True) # 对应OBR 的距离
matches = bf.match(des1,des2) # 计算最佳匹配
matches = sorted(matches, key = lambda x:x.distance) # 以描述符的距离排序
'''
将匹配结果按特征点之间的距离进行降序
排列,这样最佳匹配就会排在前面了。最后我们只将前 10 个匹配绘制出来
matches 是一个 DMatch对象的列表,具有以下属性
• DMatch.distance - 描述符之间的距离。越小越好。
• DMatch.trainIdx - 目标图像中描述符的索引。
• DMatch.queryIdx - 查询图像中描述符的索引。
• DMatch.imgIdx - 目标图像的索引。
'''
draw_params = dict(matchColor = (0,255,0),flags=2) # flags 可以试试 0 4
img3 = cv2.drawMatches(img1,kp1,img2,kp2,matches[:10],None,**draw_params)
cv2.imshow('vis',img3)
cv2.waitKey(0)
cv2.destroyAllWindows()

img1 = cv2.imread(r'D:\opencv\sources\samples\data\box.png') # 查询图像
img2 = cv2.imread(r'D:\opencv\sources\samples\data\box_in_scene.png')# 训练图像
sift = cv2.xfeatures2d.SIFT_create()
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
bf = cv2.BFMatcher()
matches = bf.knnMatch(des1,des2, k=2)
# 比值测试,首先获取与 A 距离最近的点 B(最近)和 C(次近),只有当 B/C
# 小于阈值时(0.75)才被认为是匹配,
good = []
for m,n in matches:
if m.distance < 0.4*n.distance:
good.append([m])
img3 = cv2.drawMatchesKnn(img1,kp1,img2,kp2,good[:10],flags=2,outImg = None)
cv2.imshow('vis',img3)
cv2.waitKey(0)
cv2.destroyAllWindows()

FLANN 匹配器
快速近邻包,对大数据集和高维特征进行最近邻搜索,对大数据集效果更好。
这个匹配器我们需要传入两个字典,一个指定使用的算法和相关参数。一个指定递归遍历的次数,越高越准确。
img1 = cv2.imread(r'D:\opencv\sources\samples\data\box.png') # 查询图像
img2 = cv2.imread(r'D:\opencv\sources\samples\data\box_in_scene.png')# 训练图像
sift = cv2.xfeatures2d.SIFT_create()
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
'''
FLANN_INDEX_LSH = 6
index_params= dict(algorithm = FLANN_INDEX_LSH, # 针对 ORB 的参数
table_number = 6, # 12
key_size = 12, # 20
multi_probe_level = 1) #2
'''
FLANN_INDEX_KDTREE = 0 # 这些字典指定使用的算法和相关参数。
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks=50) # or pass empty dictionary
flann = cv2.FlannBasedMatcher(index_params,search_params)
matches = flann.knnMatch(des1,des2,k=2)
# Need to draw only good matches, so create a mask
matchesMask = [[0,0] for i in range(len(matches))]
# ratio test as per Lowe's paper
for i,(m,n) in enumerate(matches):
if m.distance < 0.4*n.distance:
matchesMask[i]=[1,0]
draw_params = dict(matchColor = (0,255,0),
singlePointColor = (255,0,0), # 关键点的颜色
matchesMask = matchesMask,
flags = 0)
img3 = cv2.drawMatchesKnn(img1,kp1,img2,kp2,matches,None,**draw_params)
cv2.imshow('vis',img3)
cv2.waitKey(0)
cv2.destroyAllWindows()

使用特征匹配和单应性查找对象
在目标图像中准确找到查找对象,
import cv2
import numpy as np
import os
os.chdir(r'/home/nero/opencv/samples/data')
MIN_MATCH_COUNT = 10
img1 = cv2.imread('box.png',0)
img2 = cv2.imread('box_in_scene.png',0)
orb = cv2.ORB_create()
kp1,des1 = orb.detectAndCompute(img1,None)
kp2,des2 = orb.detectAndCompute(img2,None)
FLANN_INDEX_LSH = 6
index_params= dict(algorithm = FLANN_INDEX_LSH, # 针对 ORB 的参数
table_number = 6, # 12
key_size = 12, # 20
multi_probe_level = 1) #2
search_params = dict(checks = 50)
flann = cv2.FlannBasedMatcher(index_params,search_params)
matches = flann.knnMatch(des1,des2,k=2)
# matchesMask = [[0,0] for i in range(len(matches))]
#
# # ratio test as per Lowe's paper
# for i,(m,n) in enumerate(matches):
# if m.distance < 0.6*n.distance:
# matchesMask[i]=[1,0]
#
# draw_params = dict(matchColor = (0,255,0),
# singlePointColor = (255,0,0), # 关键点的颜色
# matchesMask = matchesMask,
# flags = 0)
#
# img3 = cv2.drawMatchesKnn(img1,kp1,img2,kp2,matches,None,**draw_params)
good = []
for m,n in matches:
if m.distance < 0.6*n.distance:
good.append(m)
MIN_MATCH_COUNT=10
if len(good) >= MIN_MATCH_COUNT:
src_pts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1,1,2)
dst_pts = np.float32([kp2[m.trainIdx].pt for m in good]).reshape(-1, 1, 2)
'''
参数就是需要映射的点,计算矩阵的方法,CV_RANSAC CV_LMEDS or 0 ,第四个参数
1-10 拒绝一个点对的阈值,原图像的点经过变化后与目标图像上对应点的误差,超过误差就认为不是正确的点。
'''
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0)
matchesMask = mask.ravel().tolist()
h,w = img1.shape
# 使用得到的变换矩阵对原图像的四个角进行变换,获得在目标图像上对应的坐标。
pts = np.float32([[0,0],[0,h-1],[w-1,h-1],[w-1,0]]).reshape(-1,1,2)
dst = cv2.perspectiveTransform(pts,M)
# 用白色绘制边框
cv2.polylines(img2,[np.int32(dst)],True,255,3,cv2.LINE_AA)
else:
print('not enough matches are found - %d/%d ' % (len(good),MIN_MATCH_COUNT))
matchesMask = None
draw_params = dict(matchColor = (0,255,0), # draw matches in green color
singlePointColor = None,
matchesMask = matchesMask, # draw only inliers
flags = 2)
img3 = cv2.drawMatches(img1,kp1,img2,kp2,good,None,**draw_params)
cv2.imshow('img1',img3)
cv2.waitKey(0)
cv2.destroyAllWindows()
 终于发现了 ubuntu 真香。。。。
终于发现了 ubuntu 真香。。。。