Linux内核网络协议栈笔记
Linux内核网络协议栈笔记0:序言(附参考书籍)
转自:http://www.th7.cn/system/lin/2011/08/11/18810.shtml
自己是研究网络的,但实际上对Linux中网络协议栈的实现知之甚少。最近看完《深入理解Linux内核》前几章之后(特别是与网络子系统密切相关的软中断),觉得可以而且应该看一下网络协议栈了。这部分网上的文章大部分都没有什么结构和思路,很少有能够条分缕析的把协议栈讲述明白的。当然,个人水平有限,还是希望朋友们能够批评指正。
参考书籍《Understanding Linux Network Internals》以及《The Linux Networking Architecture Design and Implementation of Network Protocols in the Linux Kernel》,在我的Skydrive里(点这里)可以下到英文chm版。
先大体说说这两本巨著吧。前者确实是一本关于internals的书,前三个part:General Background/System Initialization/Transmission and Reception以及第5个part:IPv4比较有用,而且思路也与本文所采用的吻合:从系统初始化到数据包的发送与接收。而后者也确实是一本architecture的书,采用了与TCP/IP协议栈(不是OSI 7层)一样的5层架构自底向上讲述了Linux内核的相关内容。
全系列文章都基于Linux内核2.6.11版本,如果最新版本(当前是2.6.30)有较大变化,也会给与标出。
Linux内核网络协议栈笔记1:协议栈分层/层次结构
大家都知道TCP/IP协议栈现在是世界上最流行的网络协议栈,恐怕它的普及的最重要的原因就是其清晰的层次结构以及清晰定义的原语和接口。不仅使得上层应用开发者可以无需关心下层架构或者内部机制,从而相对透明的操作网络。这个明显的层次结构也可以在Linux内核的网络协议栈中观察到。
主要的参考文献是:Linux网络栈剖析(中文版)/Anatomy of Linux networking stack(英文原版)by Tim Jones.
以及:Linux内核2.4.x的网络接口结构
另外一些参考资料可以从这个页面找到:http://www.ecsl.cs.sunysb.edu/elibrary/linux/network/ (纽约州立大学石溪分校的页面)
Linux内核网络协议栈采用了如下的层次结构:
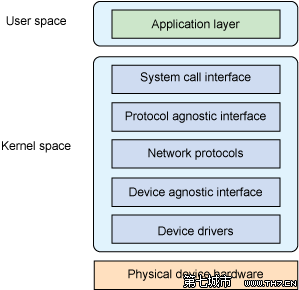
内核中的五层分别是(从上到下):
系统调用接口(详见Jones的另一篇文章:使用Linux系统调用的内核命令)
协议无关接口(BSD socket层)
网络协议(或者简称网络层。这是一个协议的集合,从链路层到传输层的协议都包括在内。不同的协议在/net文件夹下除core以外的子目录下,例如基于IP的协议簇都在/net/ipv4目录下,以太网协议在/net/ethernet目录下)
驱动无关接口(又称通用设备层--generic device layer/驱动接口层/设备操作层--device handling layer。属于网络协议栈最核心的部分,文件位于内核/net/core文件夹下,所以又叫网络核心层。其中包括了核心的数据结构skbuff文件中的sk_buff/dev.c文件中net_device,这些数据结构将在下篇文章中介绍)
设备驱动程序(在/driver/net文件夹内)
不像OSI或者TCP/IP协议栈,事实上并没有一个命名标准,因此在这里,这些层次的名称并不是通用的,但是其语义是清晰的,而且在大多数其他的文章里只是个别字上的差别。分层详细介绍可以参考Jones的文章。
Linux内核网络协议栈笔记2:初始化
参考文献《Understanding Linux Network Internals》中用了整整一章(part II)来介绍system initialization。本文只提供一个简单的概述,如果需要详细信息,还请看参考文献。
我们这里所说的初始化过程指的是从硬件加电启动,到可以从网络接收或发送数据包之前的过程。在Linux系统中,网卡拥有双重身份:struct pci_dev和struct net_device。pci_dev对象代表通用硬件的性质,是作为一个标准的PCI的设备插入了PCI的卡槽,由驱动程序进行管理;另一方面,net_device对象代表网络传输的性质,与内核的网络协议栈交互,进行数据传输。因此我们也必须通过两个方面来进行初始化,但是后者是我们的重点。而且我们并不关心内核与硬件的交互细节,例如寄存器读写与I/O映射等。
内核在初始化时,也会初始化一些与网络相关的数据结构;而且对应我们前面的日志所提及的内核网络协议栈层次结构(点这里),内核也需要一定的初始化工作来建立这种层次结构。
笔者认为初始化最重要的就是重要数据结构(通常用粗体标注)。因此也希望读者能够记住重要的数据结构的作用。
下面我们将分层,自底向上的分析整个初始化过程:
(一)驱动程序层
本文中以一个realtek 8139系列网卡作为例子,因为其驱动只有一个c文件(/drivers/net/8139too.c),比较容易分析。读者也可以参考e1000网卡的另一篇文章(点这里)。内核版本基于2.6.11。
驱动程序加载/注册主要包括以下的步骤:
(a)将设备驱动程序(pci_driver)添加到内核驱动程序链表中;
(b)调用每个驱动中的probe函数(其中重要一步就是初始化net_device对象)。
下面进行详细分解。
通常,在Linux中使用insmod命令加载一个驱动程序模块,例如8139too.o目标文件。加载之后,Linux会默认执行模块中的module_init(rtl8139_init_module)宏函数,其中的参数rtl8139_init_module是一个函数指针,指向在具体的驱动程序8139too.o中声明的rtl8139_init_module函数。这个函数定义如下:
static int __init rtl8139_init_module (void ){ return pci_module_init (&rtl8139_pci_driver); }
pci_module_init是一个宏定义,实际上就等于pci_register_driver函数。(在2.6.30内核版本中,直接变成了return pci_register_driver(&rtl8139_pci_driver) )。pci_register_driver函数的注释说明了它的作用:register a new pci driver.Adds the driver structure to the list of registered drivers。也就是把如下的这样一个驱动程序(pci_driver类型)挂到系统的驱动程序链表中:
static struct pci_driver rtl8139_pci_driver = {.name = DRV_NAME,
.id_table = rtl8139_pci_tbl,
.probe = rtl8139_init_one,
.remove = __devexit_p(rtl8139_remove_one),
#ifdef CONFIG_PM
.suspend = rtl8139_suspend,
.resume = rtl8139_resume,
#endif /* CONFIG_PM */
};
这一步我们应该这样理解(熟悉面向对象编程的读者):所有的pci_driver应该提供一致的接口(比如remove卸载/suspend挂起);但是这些接口的每个具体实现是不同的(pci声卡和pci显卡的挂起应该是不同的),所以采用了这样的函数指针结构。这个pci_driver结构其中最重要的就是probe函数指针,指向rtl8139_init_one,具体后面会解释。
但是pci_register_driver并不仅仅完成了注册驱动这个任务,它内部调用了driver_register函数(/drivers/base/driver.c中):
{
INIT_LIST_HEAD(&drv-> devices);
init_MUTEX_LOCKED(&drv-> unload_sem);
return bus_add_driver(drv);
}
前两个就是实现了添加到链表的功能,bus_add_driver才是主要的函数(/drivers/base/bus.c中),内部又调用了driver_attach函数,这个函数的主体是一个list_for_each循环,对链表中的每一个成员调用driver_probe_device函数(哈哈,出现了probe!),这个函数就调用了drv->probe(dev)(drv就是pci_driver类型的对象)!这样也就调用了驱动程序中的probe函数指针,也就是调用了rtl8139_init_one函数。
函数rtl8139_init_one的主要作用就是给net_device对象分配空间(分配空间由函数rtl8139_init_board完成)并初始化。分配空间主要是内存空间。分配的资源包括I/O端口,内存映射(操作系统基本概念,请自行google)的地址范围以及IRQ中断号等。而初始化主要是设置net_device对象中的各个成员变量及成员函数,其中比较重要的是hard_start_xmit(通过硬件发送数据)/poll(轮训)/open(启动)等函数(粗体标注),代码如下:
static int __devinit rtl8139_init_one (struct pci_dev *pdev, const structpci_device_id * ent){
struct net_device *dev = NULL;
rtl8139_init_board (pdev, & dev);
/* The Rtl8139-specific entries in the device structure. */
dev ->open = rtl8139_open;
dev->hard_start_xmit = rtl8139_start_xmit;
dev->poll = rtl8139_poll;
dev->stop = rtl8139_close;
dev->do_ioctl = netdev_ioctl;
}
整个的调用链如下:pci_register_driver ==> driver_register ==> bus_add_driver ==> driver_attach ==> driver_probe_device ==> drv->probe ==> rtl8139_init_one(生成net_device)。
一个简单的net_device生命周期示意图如下(左边为初始化,右边为卸载):

这个net_device数据结构的生成,标志着网络硬件和驱动程序层初始化完毕。也意味着,网络协议栈与硬件之间的纽带已经建立起来。
。
(二)设备无关层/网络协议层/协议无关接口socket层
Linux内核在启动后所执行的一些内核函数如下图所示:

系统初始化的过程中会调用do_basic_setup函数进行一些初始化操作。其中2.6.11内核中就直接包括了driver_init()驱动程序初始化,以及sock_init函数初始化socket层。然后do_initcalls()函数调用一组前缀为__init类型(这个宏就表示为需要在系统初始化时执行)的函数。与网络相关的以__init宏标记的函数有:net_dev_init初始化设备无关层;inet_init初始化网络协议层。
(fs_initcall和module_init这两个宏也具有类似的作用。由于这一阶段处于系统初始化,宏定义比较多,欲详细了解各种宏的使用的读者请参阅参考文献《Understanding Linux Network Internals》Part II Chapter 7)
我们下面详细介绍一下这三个初始化函数都进行了哪些工作。
(a)net_dev_init(在文件/net/core/dev.c中):设备操作层
static int __init net_dev_init(void ){
if (dev_proc_init())
if (netdev_sysfs_init())
INIT_LIST_HEAD(& ptype_all);
for (i = 0; i < 16; i++ )
INIT_LIST_HEAD(& ptype_base[i]);
for (i = 0; i < ARRAY_SIZE(dev_name_head); i++ )
INIT_HLIST_HEAD(& dev_name_head[i]);
for (i = 0; i < ARRAY_SIZE(dev_index_head); i++ )
INIT_HLIST_HEAD(& dev_index_head[i]);
//Initialise the packet receive queues.
for (i = 0; i < NR_CPUS; i++ ) {
struct softnet_data * queue;
queue = & per_cpu(softnet_data, i);
skb_queue_head_init(&queue-> input_pkt_queue);
queue->throttle = 0 ;
queue->cng_level = 0 ;
queue->avg_blog = 10; /* arbitrary non-zero */
queue ->completion_queue = NULL;
INIT_LIST_HEAD(&queue-> poll_list);
set_bit(__LINK_STATE_START, &queue-> backlog_dev.state);
queue->backlog_dev.weight = weight_p;
queue->backlog_dev.poll = process_backlog;
atomic_set(&queue->backlog_dev.refcnt, 1 );
}
open_softirq(NET_TX_SOFTIRQ, net_tx_action, NULL);
open_softirq(NET_RX_SOFTIRQ, net_rx_action, NULL);
}
这个函数所做的具体工作主要包括:初始化softnet_data这个数据结构(每个CPU都有一个这样的队列,表示要交给此CPU处理的数据包);注册网络相关软中断(参见我关于软中断的文章,点这里)。
(b)inet_init(在文件/net/ipv4/af_inet.c中):网络层
由于各种网络协议是按照协议族(protocol family,PF或者address family,AF)为单位组织起来的。我们在这里仅以Internet协议族(AF_INET或者PF_INET,在内核中这二者是等价的)为例。
有时候这一层又被称为INET socket层(对应的数据结构为struct sock),请注意与BSD socket层区别(对应数据结构为struct socket):BSD socket层提供一组统一的接口,与协议无关;但具体到网络层就必须与协议相关了,因此操作也会有一些不同。
代码如下(有删节):
static int __init inet_init(void ){
struct sk_buff * dummy_skb;
struct inet_protosw * q;
struct list_head * r;
rc = sk_alloc_slab(&tcp_prot, "tcp_sock" );
rc = sk_alloc_slab(&udp_prot, "udp_sock" );
rc = sk_alloc_slab(&raw_prot, "raw_sock" );
//Tell SOCKET that we are alive
(void)sock_register(& inet_family_ops);
//Add all the base protocols.
if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0 );
if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0 );
/* Register the socket-side information for inet_create. */
for (r = &inetsw[0]; r < &inetsw[SOCK_MAX]; ++ r)
INIT_LIST_HEAD(r);
for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++ q)
inet_register_protosw(q);
//Set the ARP module up
arp_init();
//Set the IP module up
ip_init();
tcp_v4_init(& inet_family_ops);
/* Setup TCP slab cache for open requests. */
tcp_init();
//dev_add_pack(&ip_packet_type);
}
module_init(inet_init);
这个函数中包括的主要函数包括:
sock_register:在以前的文章中说过,Linux内核网络协议栈采用了分层结构,所以层与层之间肯定是松耦合的。上层的socket层并不知道下面的网络协议层都具体包括哪些协议。因此本函数有两个作用:(a)周知INET协议族;(b)注册到socket模块上。
inet_add_protocol:在协议族中添加具体的协议。
inet_register_protosw:各种inet协议族中的协议在内核中是保存在inetsw_array[]数组,其中元素为inet_protosw类型(/include/net/protocol.h文件中),每一个元素对应一个协议。每一个协议又有两个数据结构:struct proto/struct proto_ops。这两个结构中都是一些函数操作,但proto表示每个协议独特的操作,而proto_ops是通用的socket操作(包含在struct socket中);这种区别就类似于INET socket和BSD socket的区别。
(c)sock_init(在文件/net/socket.c中):BSD socket层
定义如下(代码有删节):
void __init sock_init(void ){
//Initialize sock SLAB cache.
sk_init();
//Initialize skbuff SLAB cache
skb_init();
//Initialize the protocols module.
init_inodecache();
register_filesystem(& sock_fs_type);
sock_mnt = kern_mount(& sock_fs_type);
//The real protocol initialization is performed when do_initcalls is run.
netfilter_init();
}
此函数主要执行的工作是:初始化sock和sk_buff数据结构(这些重要的数据结构在后面的文章中还会涉及);由于sock属于linux文件系统的一部分,因此要注册成为文件系统;以及如果使用netfilter,也要进行初始化。
Linux内核网络协议栈笔记3:重要数据结构sk_buff
sk_buff,全称socket buffers,简称skb,中文名字叫套接字缓存。它可以称得上是Linux内核网络协议栈中最重要的数据结构,没有之一。它作为网络数据包的存放地点,使得协议栈中每个层都可以对数据进行操作,从而实现了数据包自底向上的传递。
主要参考资料是《Understanding Linux Network Internals》Part I--Chapter 2.1中关于sk_buff的介绍。由于这个结构比较庞大,笔者主要选择比较重要的部分进行介绍,其余的还请看参考资料。
(1)一些重要字段
struct sock *sk;
指向拥有这个缓存的那个sock(注意,这里是sock,不是socket,缓存是由具体协议拥有的)。
struct net_device *dev;
接收或者发送这个数据包队列的网络设备。参见笔者前面所写的文章(点这里)。
(2)sk_buff的创建和销毁
dev_alloc_skb/dev_kfree_skb函数负责sk_buff的创建和销毁,其内部分别调用了alloc_skb/kfree_skb。其内部实现就不再介绍了,但关于销毁和资源释放有一点需要注意:由于同一个sk_buff有可能被很多对象使用,所以使用了引用计数(reference count),当没有人使用之后,才能释放其资源。
(3)布局(Layout)
sk_buff的实现方式是双向链表。不仅每个节点有next指针指向下一元素,prev指针指向前一元素,又包含一个指向头结点的指针;同时链表的头结点比较特殊,包括了链表长度和一个自旋锁用于同步,因此形成了如下的结构:

关于布局,sk_buff实现的另一个重要功能就是:当数据包从最底层的数据链路层向上传递到传输层时,进行一些处理。例如,IP层把数据包交给传输层时,就需要把IP头去掉。下面的图演示了一个UDP的数据包在发送时添加UDP报头和IP报头的过程:
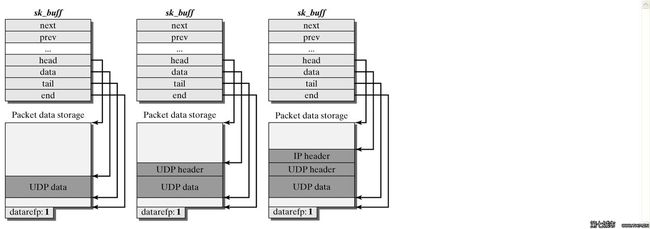
这个功能还需要另外三个成员变量,分别指向了传输层的头部(h),网络层的头部(nh=network header),数据链路层的头部(mac):
union {...} h
union {...} nh
union {...} mac
在2.6.30内核中这三个字段改为了:
sk_buff_data_t transport_header;
sk_buff_data_t network_header;
sk_buff_data_t mac_header;
下面的例子表示了在经过mac层的传输过程中data字段的变化,被mac层接收之后,data指向了IP包头开始的地方(请回忆相关的网络知识):
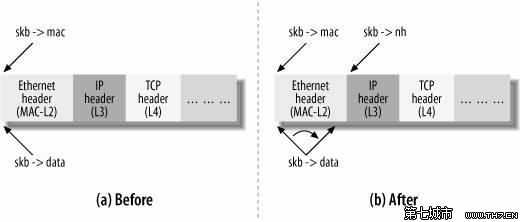
(4)管理函数
skb_reserve, skb_put, skb_push, and skb_pull等函数可以用于缓存的空间管理。例如,在数据包从上层向下传输时,因为要添加下层协议的报头,这个时候就可以根据最大可能添加的长度预留空间,这样就无需每经过一层分配一次空间,降低了系统开销。
还有另外一些以skb_queue开头的函数,表示对双向链表操作的函数。
Linux内核网络协议栈笔记4:接收网络数据包详细过程
网络数据接收过程,从数据包到达网卡的物理接口开始,然后由网卡的驱动程序交给网络协议栈,最后经过协议栈的一层层处理之后交给应用程序。大致上是这样的过程,但实际上有更多的细节。本文中主要介绍第一个和第二个步骤。
我们本文中依然以一个Realtek 8139网卡为例(驱动程序为/drivers/net/8139too.c)。请注意在内核代码中receive都是用rx简写的。
(1)注册与激活软中断
在生成net_device对象及初始化的函数rtl8139_init_one中已经初始化dev->open方法为rtl8139_open函数(在本系列文章2:初始化中的net_device对象中已经介绍,点这里查看)。在rtl8139_open函数(这个函数在网卡启动时被调用)中注册了一个中断函数rtl8139_interrupt:
retval = request_irq (dev->irq, rtl8139_interrupt, SA_SHIRQ, dev->name, dev);所以只要当网卡开启后(状态为up),当网络数据包到达时,都会产生一个硬件中断(这不同于后面的软中断)。这个硬件中断由内核调用中断处理程序rtl8139_interrupt函数处理。这个函数比较重要,网卡发送或者接收数据时内核都会调用这个函数处理中断,而中断的类型是根据网卡状态寄存器的不同而确定的。本文中仅涉及接收数据的中断,因此只给出了接收的代码:
static irqreturn_t rtl8139_interrupt (int irq, void *dev_instance, struct pt_regs* regs){
if (status & RxAckBits){
if (netif_rx_schedule_prep(dev))
__netif_rx_schedule (dev);
}
}
主要函数为__netif_rx_schedule(函数名意为:network interface receive schedule,即网络接口接收调度),因为当网卡接收到数据包之后,马上告知CPU在合适的时间去启动调度程序,轮询(poll)网卡。
请注意:Linux接收网络数据实际上有两种方式。(a)中断。每个数据包到达都会产生一个中断,然后由内核调用中断处理程序处理。
(b)NAPI(New API)。Linux内核2.6版本之后加入的新机制,核心方法是:不采用中断的方式读取数据,而代之以首先采用中断唤醒数据接收的服务程序,然后以POLL的方法来轮询数据。
因此本文中只介绍NAPI的接收方式。我们不再详细介绍这种机制,网上可找到比较多的资料,可以参考IBM的技术文章:NAPI 技术在 Linux 网络驱动上的应用和完善。
__netif_rx_schedule函数的定义如下:
static inline void __netif_rx_schedule(struct net_device * dev){
local_irq_save(flags);// disable interrupt
//Add interface to tail of rx poll list
list_add_tail(&dev->poll_list, & __get_cpu_var(softnet_data).poll_list);
//activate network rx softirq
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
local_irq_restore(flags);
}
这个函数最核心的就是三步:
(a)local_irq_save:禁用中断
(b)list_add_tail:将设备添加到softnet_data的poll_list中。
(c)激活一个软中断NET_RX_SOFTIRQ。
======================================
说到这里我们必须介绍一个关键数据结构softnet_data,每个CPU都拥有一个这样的网络数据队列(所以函数中使用了__get_cpu_var函数取得),定义如下:
struct softnet_data{
int throttle; /*为 1 表示当前队列的数据包被禁止*/
int cng_level; /*表示当前处理器的数据包处理拥塞程度*/
int avg_blog; /*某个处理器的平均拥塞度*/
struct sk_buff_head input_pkt_queue; /*接收缓冲区的sk_buff队列*/
struct list_head poll_list; /*POLL设备队列头*/
struct net_device output_queue; /*网络设备发送队列的队列头*/
struct sk_buff completion_queue; /*完成发送的数据包等待释放的队列*/
struct net_device backlog_dev; /*表示当前参与POLL处理的网络设备*/
};
大致说明一下这个数据结构的意义。某个网卡产生中断之后,内核就把这个网卡挂载到轮询列表(poll_list)中。一个CPU会轮询自己的列表中的每一个网卡,看看它们是不是有新的数据包可以处理。我们需要先用一个比喻说明这个数据结构与轮询的关系:网卡就是佃户,CPU就是地主。佃户有自己种的粮食(网络数据包),但地主家也有粮仓(softnet_data)。地主要收粮的时候,就会挨家挨户的去催佃户交粮,放到自己的粮仓里。
=======================================
(2)软中断处理
我们知道:激活软中断之后,并不是马上会被处理的。只有当遇到软中断的检查点时,系统才会调用相应的软中断处理函数。
所有的网络接收数据包的软中断处理函数都是net_rx_action。这个函数的详细注释可以看IBM的那篇技术文章。其核心语句就是一个轮询的函数:
dev->poll就调用了相应设备的poll函数。也就是说,当CPU处理软中断时,才去轮询网卡,把数据放入softnet_data中。
下面是整个中断和轮询过程的一个示意图:

下面我们解释一下poll函数具体干了什么事情。
而我们知道,在Realtek 8139网卡的net_device对象中我们已经注册了一个poll函数:
dev->poll = rtl8139_poll那么一次poll就表示从网卡缓冲区取出一定量的数据。而rtl8139_poll函数中调用的主要函数就是rtl8139_rx函数。这个函数是完成从网卡取数据,分配skb缓冲区的核心函数。其核心代码如下:
static int rtl8139_rx(struct net_device *dev, struct rtl8139_private *tp, int budget){
skb = dev_alloc_skb (pkt_size + 2 );
eth_copy_and_sum (skb, &rx_ring[ring_offset + 4], pkt_size, 0);//memcpy
skb->protocol = eth_type_trans (skb, dev);
netif_receive_skb (skb);
}
工作主要分为4部分:
(a)给sk_buff数据结构(skb)分配空间。
(b)从网卡的环形缓冲区rx_ring中拷贝出网络数据包放到sk_buff对象skb中。这个函数实质上就是一个memcpy函数。
(c)在skb中标识其协议为以太网帧。
(d)调用netif_receice_skb函数。
netif_receive_skb函数相对比较重要。函数主体是两个循环:
{
if (!ptype->dev || ptype->dev == skb-> dev)
{
if (pt_prev)
ret = deliver_skb(skb, pt_prev);
pt_prev = ptype;
}
}
list_for_each_entry_rcu(ptype, &ptype_base[ntohs(type)&15 ], list) {
if (ptype->type == type && (!ptype->dev || ptype->dev == skb-> dev))
{
if (pt_prev)
ret = deliver_skb(skb, pt_prev);
pt_prev = ptype;
}
}
两个循环分别遍历了两个链表:ptype_all和ptype_base。前者是内核中注册的sniffer,后者则是注册到内核协议栈中的网络协议类型。如果skb中的协议类型type与ptype_base中的类型一致,那么使用deliver_skb函数发送给这个协议一份,定义如下:
static __inline__ int deliver_skb(struct sk_buff *skb, struct packet_type* pt_prev){
atomic_inc(&skb-> users);
return pt_prev->func(skb, skb-> dev, pt_prev);
}
这个函数只是一个封装函数,实际上调用了每个packet type结构中注册的处理函数func。
struct packet_type {unsigned short type;
struct net_device *dev;
int (*func) (struct sk_buff *,
struct net_device *, struct packet_type * );
void * af_packet_priv;
struct list_head list;
};
例如:IP包类型的处理函数就是ip_rcv(定义在/net/ipv4/ip_output.c文件中),定义如下:
static struct packet_type ip_packet_type = {.type = __constant_htons(ETH_P_IP),
.func = ip_rcv,
};
这个包的类型是在ip_init协议初始化时添加到全局的ptype_base哈希数组中的:
void __init ip_init(void ){
dev_add_pack(& ip_packet_type);
}