Python采集群人员数据,记录JavaScript逆向分析过程
目录
前言
准备工作
分析(x0)
分析(x1)
分析(x2)
分析(x3)
代码
结语
前言
本人所有文章内容、源码,除官方企业外,禁止个人转载,谢谢配合。
....太多培训机构拿我的文章源码去讲公开课了,还有很多培训机构的招生员拿我源码自己编个小故事直接就是一篇文章(但凡这种都是一大堆废话+源码,毫无分析逻辑)。
大家好,我叫善念。有大概一月没有来更新博文了,一个原因是反响并不理想,第二个原因则是每篇文章都是现写的,花费的时间并不少。
在这里真心感谢一直在支持我的那几个粉丝,谢谢你们的持续关注点赞。

准备工作
使用到的模块
from selenium import webdriver
import json
import requests
import execjs
import jsonpath模块的安装
主要利用到这五个模块,其中json为内置模块,其它均为第三方模块。安装方式如下所示:
pip install selenium
pip install requests
pip install PyExecjs
pip install jsonpath插件的安装
关于selenium这个模块,咱们来重点介绍一下:
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。
如果不能够理解我就讲点白话,如果你是web开发人员,开发好了几百个网站,那么如果你认为的去一个个的测试BUG,是不是很浪费时间?而selenium这个框架就是用来模拟人去自动化操控浏览器的,那么是不是就节约了很多时间呢。
既然selenium能够操控浏览器,那么它们之间必须要有一个桥梁,总不能无中生有吧?
那么操控的浏览器款式不一样,中间的桥梁也是不一样的。比如我更喜欢用chrome浏览器,那么咱们需要下载一个selenium与Chrome的桥梁——Chromedriver插件
下载地址

下载与你当前谷歌浏览器版本最相近的Chromedriver
那么像我的话,下载 即可。
即可。
Windows系统需下载32位,其它的自己看着办。点进去下载win32即可。
那么如何让Python与selenium连接起来呢,这里咱们需要配置一个环境变量,就是把Python与selenium处于同一个目录:

到此为止,咱们的环境就搭建好了。
分析(x0)
进入咱们的目标网站:目标网站

点击登录后点击群管理:
再点击成员管理,进入咱们的数据页面: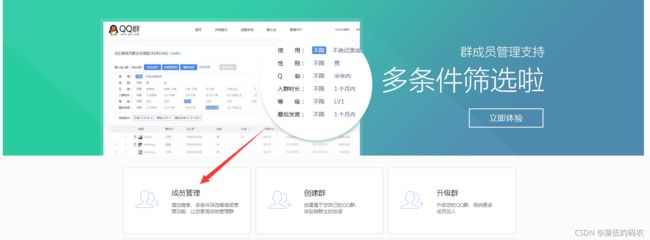
在这个页面可以看到有很多的群,我们随便点击一个就可以看到当群的成员数据:
可以看到咱们的群的号码其实就在当前网页的url中....不难想到它的url就是随咱们的群的号码变化的。
以此群为例,咱们看下网页源代码中是否包含咱们的数据,直接搜一下自己的号码即可,因为我自己是肯定在群当中的嘛: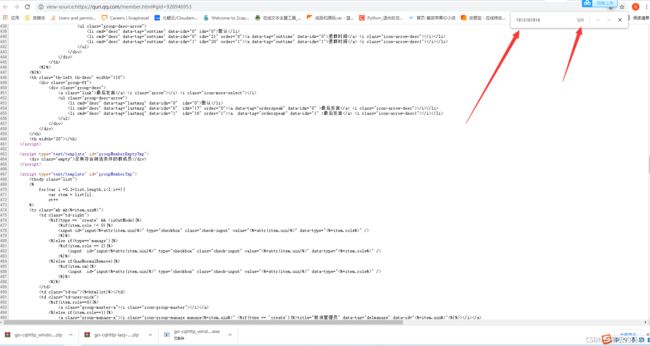
emmm什么都没有,再去网页元素中看一下吧: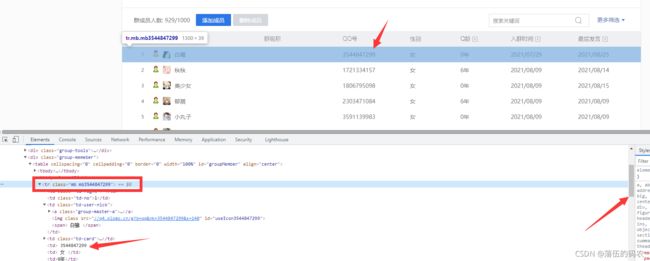
网页元素中是有的,一个tr标签保存了一个成员信息。不过我群里九百多个人,为什么右边的进度条这么粗....
说明什么?异步加载咯,经常说到得瀑布流,当我们拉动下滑条的时候才会刷新出更多得成员数据

明显看得到吧,当我们拉动下滑条后,元素中的元素变多了,那个进度条变短了。
分析(x1)
那么就可以总结出来思路了,就是当我们用selenium模拟人打开一个浏览器,然后我们登录、点开群管理、找到需要采集的群点击(或者直接进入到当前群的url也是可行的)、最后就是拉动下滑条然后用selenium从网页元素上爬取数据咯。
应该不难理解吧,这其实就是我们刚才人为做的一个事情。我只是用selenium代替我们人去模拟这个事情再做一遍。
而我反复强调过:selenium的速度太慢太慢,尽量不要去使用它!
那么怎么办?抓包呗,网页源代码中没有数据,而下拉滑动条后网页元素中出现了该数据,不就是说明当我们拉动下滑条就执行了一些JavaScript脚本或者一些接口从而产生了数据?
数据也是不可能无中生有的,总有个来源,咱们监听下服务器与客服端的一个交流过程:
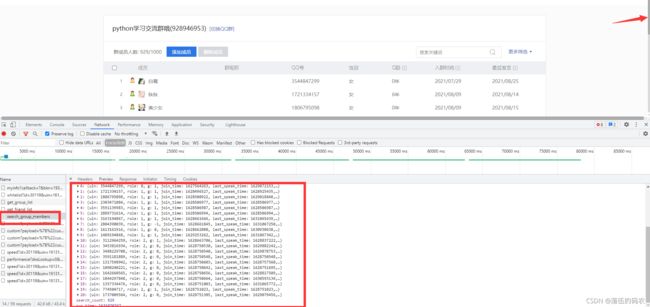
刷新当前网页抓包后,可以看到咱们抓的包当中生成了0-20就是21条数据,然后再看看这个包需要的参数:
是一个post请求,然后参数的话...gc貌似就是群的号码,然后st为0、end为20啥的估计就是说0-20总共21条数据吧,bkn......大头菜,明显不是一个时间戳,按道理是JavaScript加密。
我们再拉动点滑动条往下面拉,再抓一个包看看有没有什么参数发生变化:

果然0-20就是代表一个数据的排序,比如我第一个包是0-20是前面的21条数据,那么第二个包当然就是21-41了。
果然,第三个包也是按21的步差来的,而sort为零不变,bkn也不变。
分析(x2)
走吧,开始去分析咱们的bkn是如何生成的:

上次有人问我,这个玩意该怎么搜...我这里告诉你们了,先点一下那三个点,然后点击search:

可以看到就一个JS文件中包含bkn,简直完美了,事情变得越来越简单。

请不要遇到JavaScript加密就闹心,静下心来好好看看
o.data.bkno字典里面的data里面的bkn就是个嵌套而已,也就是说明bkn属于o字典里面的一个键,然后它居然赋值给了一个函数function,注意看结尾用了一个()啥意思?
把把函数赋值给一个变量bkn,然后调用该函数。说明什么?bkn就为函数中return的值呀......是不是很简单?看不懂多看几遍。
函数里面的话就是个循环咯,当条件不满足时就一直加,知道条件满足为止。看不懂可以去学学基本的JavaScript语法,不学也问题不大,咱们直接抠JavaScript代码也行。
for (var e = $.cookie("skey"), t = 5381, n = 0, o = e.length; n < o; ++n)
t += (t << 5) + e.charAt(n).charCodeAt();
return 2147483647 & te为cookie中"skey"键所对应的值,o为e这个字符串的长度,n起始值为0.....居然都是已知数据,压根没有变量,那么咱们看看skey对应的值是啥:
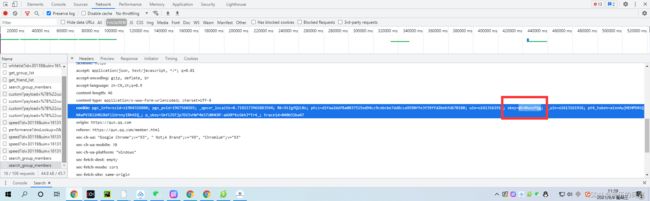
好像问题是已经解决了吧,那么咱们来测试一下:
看下与咱们的post参数是否相同: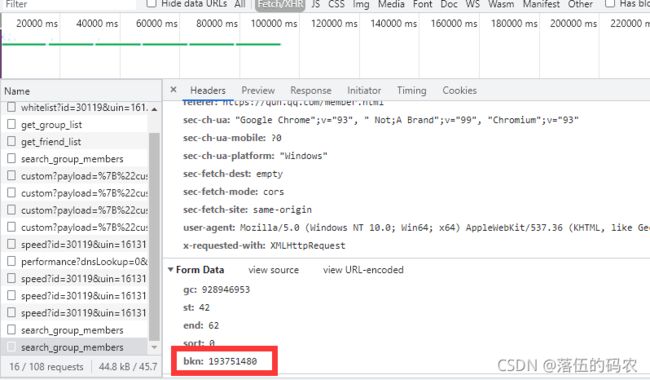
emmmmm,大功告成拉!
分析(x3)
总结下思路:
1.利用selenium打开浏览器然后登录
2.获取cookies保存(后期用来解密bkn的)
3.解密JavaScript
4.发送post请求想要采集的群号
代码
JS代码:
function GetBkn(e) {
for (t = 5381, n = 0, o = e.length; n < o; ++n) t += (t << 5) + e.charAt(n).charCodeAt();
return 2147483647 & t
}Python代码:
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2019/6/02 21:44
# @Author : 善念
# @File : demo12.py
# @Software: PyCharm
from selenium import webdriver
# from time import sleep
import json
import requests
import execjs
import jsonpath
# import sys
def get_cookies():
driver = webdriver.Chrome()
driver.get('https://qun.qq.com/manage.html#click')
driver.find_element_by_xpath('//*[@id="headerInfo"]/p[1]/a').click()
# sleep(5)
input('登陆后请按Enter')
cookie_list = driver.get_cookies()
cookie = {}
for i in cookie_list:
cookie[i["name"]] = i["value"]
with open("cookies.txt", "w") as f:
f.write(json.dumps(cookie))
f = open("cookies.txt")
# 字符串转字典
cookies = json.loads(f.read())
f.close()
driver.close()
return cookies
def get_bkn(cookies):
e = cookies['skey']
with open("gtk.js", encoding='utf-8') as f:
jsData = f.read()
js_text = execjs.compile(jsData)
bkn = js_text.call('GetBkn', e)
return bkn
def get_data(bkn, cookies):
headers = {
'origin': 'https://qun.qq.com',
'referer': 'https://qun.qq.com/member.html',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.29 Safari/537.36',
'x-requested-with': 'XMLHttpRequest',
}
qq_group = input('请输入你要查询的QQ群号码:')
offset = 21
max_num = []
for index, i in enumerate(range(0, 5000, offset)):
data = {
'gc': qq_group,
'st': i,
'end': 20 + offset*index,
'sort': '0',
'bkn': bkn,
}
req = requests.post('https://qun.qq.com/cgi-bin/qun_mgr/search_group_members', headers=headers, data=data, cookies=cookies).json()
qq_numbers = jsonpath.jsonpath(req, '$..uin',)
qq_names = jsonpath.jsonpath(req, '$..nick',)
try:
max_num.append(len(qq_numbers))
for QQ_number, QQ_name in zip(qq_numbers, qq_names):
with open(qq_group+'.txt', 'a', encoding='utf-8')as f:
f.write(str(QQ_number)+'@qq.com'+'\n')
print('共获得成员数:%d' % sum(max_num))
except TypeError:
exit()
def go():
cookies = get_cookies()
bkn = get_bkn(cookies)
get_data(bkn, cookies)
if __name__ == '__main__':
go()
结语
当你毫无保留的信任一个人,最终只会有两个结果,不是生命中的那个人,就是生命中的一堂课。
但凡文章内容中有不懂之处,欢迎及时私信于我。我每天都会抽时间给我的粉丝解答,给与一些学习资源。
原创不易,再次谢谢大家~
