【Python爬虫实战】scrapy爬取某资讯网站并存入MySQL
本次爬取目标网站为 https://www.nanjixiong.com/forum-2-1.html
任务是爬取列表页+详情页数据
在爬取过程中发现几点问题:
- 每次运行scrapy爬取内容的顺序都不一致。
原因:百度原因是scrapy是一个异步处理框架,也就是说Scrapy发送请求之后,不会等待这个请求的响应(也就是不会阻塞),而是可以同时发送其他请求或者做别的事情。而我们知道服务器对于请求的响应是由很多方面的因素影响的,如猫之良品所说的网络速度、解析速度、资源抢占等等,其响应的顺序是难以预测的。 - 在使用普通的同步写入方法时,发现部分数据最后写不到数据库中。
原因:百度原因是同步异步(但我还不是很理解这个地方,如有大佬朋友清楚原因,请指教下本小白,感谢!!)。①同步: 同步写入数据速度比较慢, 而爬虫速度比较快,普通的mysql操作是同步操作,插入数据的速度(即I/O读写)远远低于spider中解析数据的速度。 可能导致数据最后写不到数据库中。②异步: 是将爬虫的数据先放到一个连接池中, 再同时将连接池的数据写入到数据库中, 这样既可以提高数据库的写入速度, 同时也可以将爬取到的所有数据都写到数据库中, 保证数据的完整性。
使用实现代码如下:
分别测试了延迟与正常状态下的同步写入和异步写入,效果如下
spider部分
import scrapy
import re
from copy import deepcopy
from up3Dprint.items import Up3DprintItem
class NanjixiongSpider(scrapy.Spider):
name = 'nanjixiong'
allowed_domains = ['nanjixiong.com']
start_urls = ['https://www.nanjixiong.com/forum-2-1.html']
def parse(self, response, **kwargs):
new_list = response.xpath('//*[@id="threadlisttableid"]/tbody')
for new in new_list:
item = Up3DprintItem()
item['id'] = new.xpath('./@id').extract_first()
item['title'] = new.xpath('./tr/th/div[1]/a[2]/text()').extract_first()
item['href'] = new.xpath('./tr/th/div[1]/a[2]/@href').extract_first()
yield scrapy.Request(
url='https://www.nanjixiong.com/' + item['href'],
callback=self.parse_detail,
meta={
'item':deepcopy(item)}
)
def parse_detail(self, resopnse):
item = resopnse.meta['item']
item['publish_year'] = resopnse.xpath('//*[@id="wp"]/div[2]/div[2]/div[1]/div/div[1]/b/text()').extract_first()
item['publish_month'] = resopnse.xpath('//*[@id="wp"]/div[2]/div[2]/div[1]/div/div[2]/text()').extract_first()
item['publish_date'] = resopnse.xpath('//*[@id="wp"]/div[2]/div[2]/div[1]/div/div[3]/text()').extract_first()
item['image'] = resopnse.xpath('//*[@id="ct"]//td[@class="t_f"]//ignore_js_op//img/@zoomfile').extract()
content = resopnse.xpath('//*[@id="ct"]//td[@class="t_f"]/text() | '
'//*[@id="ct"]//td[@class="t_f"]/strong//text() | '
'//*[@id="ct"]//td[@class="t_f"]/font//text() | '
'//*[@id="ct"]//td[@class="t_f"]/ul//text()').extract()
content = [i for i in content if re.match(r'[\r\n]+$', i) is None]
item['content'] = ''.join([b + '\n' if b.endswith(('。', '!', ';', '?')) else b for b in content])
if item['image'] is not None:
item['image'] = ['https://www.nanjixiong.com/' + image for image in item['image']]
yield item
item部分:
import scrapy
class Up3DprintItem(scrapy.Item):
id = scrapy.Field()
title = scrapy.Field()
href = scrapy.Field()
publish_year = scrapy.Field()
publish_month = scrapy.Field()
publish_date = scrapy.Field()
image = scrapy.Field()
content = scrapy.Field()
middlewares部分:
import random
class RandomUserAgentMiddleware:
def process_request(self,request,spider):
ua = random.choice(spider.settings.get('USER_AGENT_LIST'))
request.headers['User-Agent'] = ua
settings部分:
# Scrapy settings for up3Dprint project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'up3Dprint'
SPIDER_MODULES = ['up3Dprint.spiders']
NEWSPIDER_MODULE = 'up3Dprint.spiders'
LOG_LEVEL = 'ERROR'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT_LIST = ['Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 Edg/87.0.664.75',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv,2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Windows NT 6.1; rv,2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5',
'Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5',
'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36 SE 2.X MetaSr 1.0',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4094.1 Safari/537.36']
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
MYSQL_HOST = '***'
MYSQL_USER = '***'
MYSQL_PASSWORD = '***'
MYSQL_DB_NAME = '***'
MYSQL_PORT = 3306
MYSQL_CHARSET = 'utf8'
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 1
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'up3Dprint.middlewares.Up3DprintSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'up3Dprint.middlewares.RandomUserAgentMiddleware': 543,
}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'up3Dprint.pipelines.Up3DprintPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
同步写入的pipelines部分:
import pymysql
from up3Dprint.settings import MYSQL_HOST,MYSQL_USER,MYSQL_PASSWORD,MYSQL_DB_NAME,MYSQL_PORT,MYSQL_CHARSET
class Up3DprintPipeline:
conn = None
cursor = None
def open_spider(self, spider):
self.conn = pymysql.connect(host=MYSQL_HOST,user=MYSQL_USER,passwd=MYSQL_PASSWORD,db=MYSQL_DB_NAME,port=MYSQL_PORT,charset=MYSQL_CHARSET)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
try:
sql = 'insert into 3dprint_nanjixiong(id,title,href,publish_year,publish_month,publish_date,image,content) values(%s,%s,%s,%s,%s,%s,%s,%s)'
data = [item['id'],item['title'],item['href'],item['publish_year'],item['publish_month'],item['publish_date'],str(item['image']),item['content']]
self.cursor.execute(sql,data)
self.conn.commit()
print(f'{item["id"]} 插入成功!')
except Exception as e:
print('插入数据失败', e)
self.conn.rollback()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
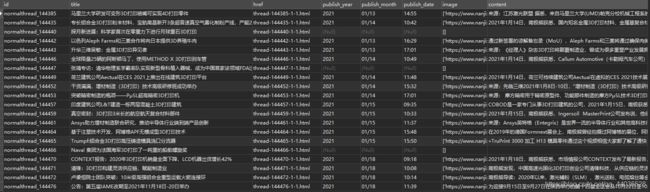
同步写入时,分别测试了无延迟和延迟1秒的情况,但都有部分数据无法写入数据库。
类似这样:部分详情页数据为null
异步写入的pipelines部分:
import pymysql
from twisted.enterprise import adbapi
class Up3DprintPipeline(object):
# 初始化函数
def __init__(self, db_pool):
self.db_pool = db_pool
# 从settings配置文件中读取数据库连接参数
@classmethod
def from_settings(cls, settings):
# db_params接收连接数据库的参数
db_params = dict(
host=settings['MYSQL_HOST'],
user=settings['MYSQL_USER'],
password=settings['MYSQL_PASSWORD'],
port=settings['MYSQL_PORT'],
database=settings['MYSQL_DB_NAME'],
charset=settings['MYSQL_CHARSET'],
# 设置游标类型
cursorclass=pymysql.cursors.DictCursor
)
# 创建一个数据库连接池对象,这个连接池可以包含多个connect连接对象
# 参数1:操作数据库的包名
# 参数2:连接数据库的参数
db_pool = adbapi.ConnectionPool('pymysql', **db_params)
# 返回一个pipeline对象
return cls(db_pool)
# 使用twisted将mysql插入变为异步执行
def process_item(self, item, spider):
# 把要执行的sql放入连接池
# 参数1:在线程中被执行的sql语句
# 参数2:要保存的数据
result = self.db_pool.runInteraction(self.insert, item)
# 给result绑定一个回调函数,用于监听错误信息.如果sql执行发送错误,自动回调addErrBack()函数
result.addErrback(self.handle_error, item, spider)
# 返回Item
return item
# sql函数执行具体的插入操作
def insert(self, cursor, item):
sql = 'insert into 3dprint_nanjixiong(id,title,href,publish_year,publish_month,publish_date,image,content) values(%s,%s,%s,%s,%s,%s,%s,%s)'
data = [item['id'],item['title'],item['href'],item['publish_year'],item['publish_month'],item['publish_date'],str(item['image']),item['content']]
cursor.execute(sql, data)
print(f'{item["id"]} 插入成功!')
# 错误函数
def handle_error(self, failure, item, spider):
# 输出错误信息
print(failure)
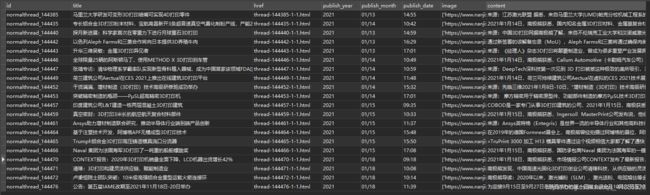
异步写入时,分别测试了无延迟和延迟1秒的情况,结果延迟1秒时候数据成功写入数据库,无延迟时还是存在部分数据无法写入。
*************后面又尝试多几次,发现好像不管是否延迟,都会存在有部分数据无法写入的情况。。而且无法写入的数据好像都是随机的。这是为什么呢。。。