Javaweb笔记(mysql+jdbc+tomcat+servlet基础)
2021-9-9
1.Junit单元测试
2.反射
3.注解
Junit单元测试:
测试分类 :
1.黑盒测试:不关注具体实现逻辑,给input,看程序是否能输出期望的值
2.白盒测试:关注程序的具体流程
Junit使用:白盒测试
1.定义一个测试类
1.测试类名:被测试的类名Test
2.定义一个测试方法,可以独立运行
1.testAdd()
2.void
3.空参
3.给方法加@Test
4.导入junit依赖
5.判定结果:绿色成功,红色成功
@Before:修饰的方法会在测试方法之前被自动执行,资源打开
@After:修饰的方法会在测试方法结束后被自动执行,资源关闭
断言判断测试结果
Assert.assertEquals(期望值,实际值);
反射:框架设计的灵魂
框架:在其基础上进行软件开发,简化编码
反射概念:将类的各个组成部分封装为其他对象。
1.可以在程序运行的过程中,操作这些对象
2.可以解耦,提高程序的可扩展性
获取Class类对象的三种方式:
1.class.forName("全类名")
多用于配置文件,读取文件加载类
2.类名.class
多用于参数的传递
3.对象.getClass()
三种方式获取的Class类对象是同一个
获取Field:
getField():获取public修饰的成员变量
getDeclaredFields():获取所有的成员变量
获取之后,new一个类对象,可以设置类对象的值
setAccessible(true)-------暴力反射
注解:
1.编译检查(override)
2.详细描述@author,@since,@version,@param,{生成文档doc文档}
3.代码分析,通过代码里表示的注解对代码进行分析
JDK中预定义的注解:
1.override:方法是或否继承自父类
2.deprecated:方法是否过时
3.suppressWarnings:压制所有的警告
自定义注解:
元注解
public @interface 注解名称{}
注解本质是一个接口,默认继承Annotation接口
接口里可以定义属性和方法
2021-9-10
JavaWeb课程介绍
1.什么是javaweb?
使用java语言开发互联网项目
2.课程介绍:30天
1.数据库:5天
2.网页前端:5天
3.web核心技术:15天
4.旅游管理系统:5天
数据库基本概念:
1.数据库英文单词:DataBase,DB是一个文件系统
2.特点:
1.持久化存储数据
2.方便存储和管理数据
3.使用了统一的方式操作 --SQL
SQL
1.什么是SQL?
Structured Query Language:结构化查询语言,定义了关系型数据库的规则2
2.SQL通用语句
单行或多行书写,以分号结尾
单行注释:-- (注释内容)或者# (注释内容)
多行注释:/* 注释 */
3.SQL语句分类:
1.DDL(操作数据库、表)
2.DML(增删改表中数据)
3.DQL(查询表中数据)
DDL
1.操作数据库:CRUD
1.Create
create database '数据库名称';
2.Retrieve
show databases;查询所有数据库的名称
3.Update
4.Delete
drop databse '数据库名称';
5.使用数据库
select database();查询正在使用的数据库
use '数据库名称';使用(进入)数据库
2.操作表:
1.Create
create table 表名(
列名1 数据类型1,
列名2 数据类型2,
···
列名n 数据类型n
);
最后一列不用逗号
2.Retrieve
show tables;查询表
3.Delete
drop table 表名
4.Update
alter table 表名 rename to 新的表名;修改表名
alter table 表名 add 列名 数据类型:添加一列
alter table 表名 modify column 列名 新类型
alter table 表名 drop 列名
DML
1.添加数据:
insert into 表名(列名1,列名2,···,列名n) values(值1···)
2.删除数据:
delete from 表名 where(条件)(不加条件则删除所有)
3.更新数据:
update 表名 set 字段 = 值 where 条件
DQL
1.查询所有语句:
select * from 表名;
2.语法:
select (distinct)去除重复的结果集
字段列表,可以有多个字段
ifnull(表达式1,表达式2):若表达式1的值为null,则用表达式2替代
as 起别名
from
表名列表
where
条件列表
group by
分组字段
having
分组之后的条件
order by
排序
limit
分页
3.条件查询where:
>,<,!=,or,and,
between A and B:在A和B之间包含A,B
in (A,B,C):查询值A,B,C
4.模糊查询
like占位符:
_:单个占位符
%:多个字符 SELECT NAME FROM student WHERE birthday LIKE '2001%';
5.排序查询
order by 排序字段 排序方式(ASC:升序 默认)(DESC:降序)
6.聚合函数:将一列数据作为一个整体,进行纵向的计算
1.count:计算个数
选择非空字段:主键
2.max
3.min
4.sum
5.avg
7.分组查询
group by 分组字段;
查询的字段为:分组字段或者聚合函数
8.分页查询
约束
多表之间的关系
事务
1.概念:如果一个包含多个步骤的业务操作被事务管理,那么这些操作要么同时成功,要么同时失败
2.操作
1.开启事务 start transaction
2.回滚 rollback
3.提交事务 commit
1.一条DML语句会自动提交事务
2.手动提交需要先开启,提交,回滚
3.事务四大特征
1.原子性
2.持久性
3.隔离性:多个事务之间相互独立
4.一致性:事务操作前后,数据总量不变
JDBC
1.本质:定义了操作所有关系型数据库的规则(接口)
2.快速入门:
1.导入驱动jar包
1.复制jar包到项目包下
2.add as library
2.注册驱动
3.获取数据库连接对象 Connection
4.定义sql
5.获取执行sql语句对象 Statement
6.执行sql,接受返回结果
7.处理结果
8.释放资源
3.详解各个对象
1.DriverManager:驱动管理对象
1.注册驱动
Class.forName("com.mysql.jdbc.Driver")是静态代码块,自动执行
mysql5之后的驱动jar包可以省略注册驱动的步骤
2.获取数据库连接:static Connection getConnection
url:jdbc:mysql://ip地址:端口号/数据库名
user:用户名
password:密码
2.Connection:数据库连接对象
1.获取执行sql的对象Statement createStatement(String sql)//PerparedStatement
2.管理事务
1.开启事务:setAutoCommit() 设置false,开启
2.提交事务:commit()
3.回滚事务:rollback()
3.Statement:执行sql的对象
1.execute()执行任意的sql
2.executeUpdate(String sql) 执行DML,DDL语句,返回影响的行基数
3.executeQuery(String sql) 执行DQL语句,返回ResultSet
4.ResultSet:executeResultSet()结果集对象,封装查询结果
next():游标向下移动一行
getXXX():获取数据
+ XXX代表数据类型 如getInt()
+ 参数:Int:代表列的编号,结果编号从1开始。String:代表列名
使用时:
1.游标向下移动一行
2.判断是否有数据
next()若返回false则已经到了末尾的下一行
while(resultset.next())判断是否到了最后一行
3.获取数据
将结果封装为对象,然后装载集合,返回
1.定义Student类
2.定义方法 public List findAll()
3.实现select * from Student;d
5.PerparedStatement
4.练习(注意事项)
1.异常要捕获不要抛出
2.在finally中释放资源
5.简化JDBC配置文件,抽取工具类JDBCUtils(** 静态 **方法)
1.获取连接对象:配置文件--jdbc.properties,使用静态代码块读取
2.释放资源
3.注册驱动
4.动态获取src下资源的路径,统一资源定位符
ClassLoader classLoader = JDBCUtils.class.getClassLoader()
URL res = classLoader.getResource("jdbc.properties")
String path = res.getPath()
6.PreparedStatement:执行sql的对象
1.SQL注入问题:在拼接sql时,有一些sql关键字参与字符串的拼接。
2.使用PreparedStatement预编译sql,参数使用?作为占位符
1.select * from user where username = ? and password = ?;
2.setXxx(参数1,参数2)用来赋值.
参数1:参数的位置
参数2:参数的值
3.pstat = conn.preparedStatement(sql)
4.pstat.setString();
5.rs = pstat.executeQuery()
7.JDBC事务操作
1.在执行操作开启事务
conn.setAutoCommit(false);
2.在操作执行完关闭事务
conn.commit();
3.在catch进行回滚
conn.rollback();
8.数据库连接池
1.概念
存放数据库连接的容器,在容器中获取连接,然后用完还回来
2.好处
节约资源,高效
3.实现
1.C3P0
2.Druid
4.C3P0(放弃不学)
5.Druid
1.导入jar包
2.定义配置文件
3.加载配置文件
Properties pro = new Properties();
InputStream input DruidDemo.class.getClassLoader().getResourceAsStream("druid.properties");
pro.load(input);
4.通过工厂类来获取数据库连接池对象
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
Connection conn = dataSource.getConnection();
5.getConnection()获取数据库连接
6.定义工具类JDBCUtils
1.提供静态代码块加载配置文件,初始化连接池对象
2.通过数据库连接池获取链接
3.释放资源
4.获取连接池的方法
9.Spring JDBC:Spring框架对JDBC的简单封装
1.导入jar包
2.创建JdbcTemplate对象,以来于数据源DataSource
JdbcTemplate template new JdbcTeplate(dataSource);
3.调用JdbcTemplate执行CRUD操作
1.update执行DML语句
2.queryForMap()
一条返回记录对应一个Map集合,有多条记录不能封装为Map集合
字段为key,值为value
3.queryForList()
将每一条记录封装为Map集合,再将Map集合封装为List
4.queryForObject()
5.query()
List list = template.query(sql, new BeanPropertyRowMapper(Emp.class))
new BeanPropertyRowMapper<>()直接将查询到的结果封装为Emp对象,参数通过反射得到
XML
1.概念:可扩展(标签是自定义)标记语言,可存储数据
功能:
1.配置文件
2.在网络中传输
2.语法
1.必须要写一个根标签
2.xml第一行为文档的声明
3.标签必须正确关闭
3.组成部分
1.文档声明
1.格式
2.属性列表:
version:版本号1.0
encoding:编码方式
standalone:是否独立
2.指令(已弃用)
3.标签
1.名字不包含空格,包含数字字母下划线
2.名字自定义
4.属性
id属性值唯一
5.文本
字符符号需要html转义,或者使用CDATA区.
4.使用
用户编写xml,软件解析xml
1.能够在xml中引入约束文档
2.引入xsi前缀,xmlns:xsi:"http://www.w3.org/2001/XMLSchema-instance"
3.引入xsd文件命名空间 xsi:schemaLocation="http://www.itcast.cn/xml student.xsd"
2.能够简单读懂约束文档
web相关概念
1.软件架构
1.C/S:客户端/服务器端
2.B/S:浏览器/服务器端
2.资源分类
1.动态资源:用户访问相同资源,结果可能不同。被访问后需要被转换为静态资源,再返回到浏览器,成为响应(servlet,php)
2.静态资源:用户访问后,结果相同。可以直接被浏览器解析(HTML,CSS,JS)
浏览器先发送请求给服务器,服务器返回静态资源,浏览器解析资源
3.网络通信按要素
1.IP:电脑在网络中的唯一标识
2.端口:应用程序在计算机中的唯一标识
3.传输协议:规定了数据通信的规则
web服务器软件
1.服务器:安装了服务器软件的计算机
2.服务器软件:接受用户的请求,处理请求,做出响应
3.Java相关的web服务器软件:Tomcat
Tomcat
1.目录结构
1.bin:可执行文件
2.conf:配置文件
3.lib:依赖的jar包
4.logs:日志文件
5.temp:临时文件
6.webapps:存放web项目
7.work:存放运行时的数据
2.启动:bin/startup.bat
3.关闭:ctrl+c或者点击x
4.配置
1.直接将项目放到webapps目录下(将项目打成一个war包,将war包放到webapps目录下,自动解压缩)
2.配置conf/server.xml文件
3.在conf/Catalina/localhost新建任意名称的xml文件,在文件中编写
5.Java动态项目的目录结构
--项目的根目录
--WEB-INF目录(动态项目)
--web.xml:核心配置文件
--clases:字节码文件
--lib:防止依赖的jar包
6.Tomcat集成到IDEA中,创建JavaEE
注意:创建完JavaEE项目后,要将其部署到Tomcat中
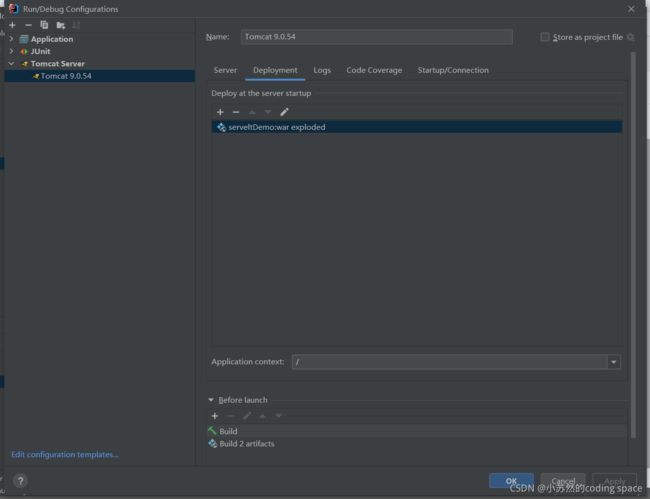
Servlet
1.概念:运行在服务器端的小程序,定义了Java类被tomcat识别的规则
2.快速入门
1.创建JavaEE项目
2.定义一个类,实现
3.配置servlet
<servlet>
<servlet-name>demo1servlet-name>
<servlet-class>servlet.ServletDemoservlet-class>
servlet>
<servlet-mapping>
<servlet-name>demo1servlet-name>
<url-pattern>/demo1url-pattern>
servlet-mapping>
4.实现原理
1.在web.xml解析http请求,在servlet-mapping找url-pattern,根据对应的servlet-name找到servlet里的servlet-name,调用servlet-class的类
2.根据反射,创造class对象,调用service方法
3.生命周期
1.init():只执行一次
2.service():每次访问都会执行
3.destroy():服务器正常关闭会执行
4.注解配置(不需要web.xml)
1.创建JavaEE项目,选择servlet3.0以上
2.定义servlet实现类
3.复写方法
4.@WebServlet("路径")