openGauss数据库源码解析系列文章—— AI技术之“自调优”
上一篇介绍了第七章执行器解析中“7.6 向量化引擎”及“7.7 小结”的相关内容,本篇我们开启第八章 AI技术中“8.1 概述”及“8.2 自调优”的相关精彩内容介绍。
AI技术最早可以追溯到20世纪50年代,甚至比数据库系统的发展历史还要悠久。但是,由于各种各样客观因素的制约,在很长的一段时间内,人工智能技术并没有得到大规模的应用,甚至还经历了几次明显的低谷期。随着信息技术的进一步发展,从前限制人工智能发展的因素已经逐渐减弱,所谓的ABC(artificial intelligence、big data、cloud computing)技术也应运而生。人工智能在某些领域的能力已经超过了人类,如AlphaGo战胜了人类的顶尖围棋选手事件、无处不在的“刷脸”验证、语音助手使人们看到人工智能在更多领域落地的可能。
在本章中,将介绍openGauss在人工智能与数据库结合领域的探索,包括自调优、智能索引推荐等领域的内容。
8.1 概述
数据库与AI相遇会摩擦出什么样的火花?近些年全球各大公司、顶尖高校都在尝试将AI与数据库融合。openGauss目前也已经取得了阶段性的成果,部分项目也已经在华为云上线并进行商用。openGauss在人工智能领域的探索可以分为两个主要方向:AI4DB与DB4AI。
(1)AI4DB就是指用AI使能数据库,从而获得数据库更好的执行表现、实现数据库系统的自治、免运维等。主要包括自调优、自诊断、自安全、自运维、自愈等子领域。
(2) DB4AI就是指打通数据库到人工智能应用的端到端流程,统一人工智能技术栈,达到AI应用的开箱即用、高性能、低成本等目的。例如通过类SQL语句使用推荐系统、图像检索、时序预测等功能,充分发挥openGauss高并行、列存储等优势,提高机器学习任务的执行效率。同时,在数据侧实现AI计算,还可以降低数据的网络传输成本,实现本地化计算、节省人力、降低成本。
下述8.2-8.6章节介绍AI4DB功能,8.7章节介绍DB4AI功能。
8.2 自调优
数据库自调优技术是一个比较大的范畴,通常包括对数据库参数配置、自身代价优化模型的调优等。本节主要介绍对数据库参数配置进行自动调优的功能。
8.2.1 参数自调优的使用场景
通常数据库系统会提供大量参数供DBA进行调优,openGauss提供了500多个参数。很多参数都与数据库的表现密切相关,如负载调度、资源控制、WAL机制等。
数据库参数调优的目的是满足用户对性能的期望,保障数据库系统的稳定可靠。大部分场景中,数据库参数调优依赖DBA去识别和调整,但DBA调优存在很多限制。主要包括三个方面。
(1) DBA要花费大量时间,在测试环境中对所要部署的业务进行调优;而每次上线新业务,调优过程需要重新来一遍,对于企业来说,人力成本巨大。
(2) DBA通常仅关注少部分关键调优参数,使得调优过程不能完全匹配业务,而且资源利用率及数据库性能并不一定是最优的。而且,其他次优参数与数据库表现的隐式关系也没有被充分挖掘出来。
(3) DBA通常只精通某一个特定的数据库调优,譬如擅长调优A数据库的DBA很可能不擅长调优B数据库,因为二者的底层实现存在很大差异,不可以使用同一套经验进行调优。同时,当硬件环境发生了变化,DBA的经验不一定能发挥作用。多业务混合负载场景下,也是如此。
针对上述调优限制,实现一种数据库参数自动调优的方法,来减少DBA运维代价,提升数据库整体的性能就显得尤为重要了。
8.2.2 现有的参数调优技术
参数调优在各个领域是一项通用的技术,该技术在各领域不断取得进展。与很多领域一样,数据库中也包含各种各样的参数用于调优,这些参数往往随着业务的变化需要不断进行调整。总体来看,数据库的参数调优主要有以下几种方法。
1. 基于规则
基于规则的参数调优是比较简单、通用的方法,通过对人工调优的经验进行整理,编写成各式各样的规则来对数据库系统进行调优。该方法的优点是速度快、可解释性好、稳定性高,缺点是规则随着系统的变化可能会不再适用、推荐的参数往往不是最优的。著名的采用该方法的工具为MySQKTuner-perl。
2. 基于搜索算法
假设数据库系统只需要调一个参数,且这个参数与性能之间的关系又非常简单(如二者呈线性相关、变化曲线呈二次函数关系),则可以通过二分搜索算法查找出最优的参数值。那么试想:如果系统需要调整多个参数,这些参数彼此之间又互相影响,这时应该如何去调优呢?显然,这不是通过二分法就可以解决的了,这在数学上属于一个组合优化问题,即在有限的对象集(此处指所有参数自由组合后的可能结果集)中找出最优对象(此时是最优参数配置)的问题。对于组合优化问题,一般的解法包括近似算法(approximation algorithm)、启发式算法(heuristic algorithm)、遗传算法等。由于启发式算法实现相对简单,结果比较稳定,因而广泛应用。如参数优化方法bestconf就属于此类。基于启发式算法的参数调优方法具有应用场景普遍、优化效果稳定的特点,一般不需要根据系统的变化而进行算法的重新适配,但是每次启动都需要重新探索、不能够重复利用历史探索经验、而且往往容易陷入局部最优。相关搜索算法在其他参数调优领域也有较多的实践,如AutoML中对机器学习算法超参数的调优。
3. 基于监督学习
监督学习(supervised learning)是一种通过显式地输入特征向量和结果标签,寻找二者之间映射关系的一种机器学习算法。它可以根据训练数据学习或建立一个模型,并基于此模型推测新的实例。如果监督学习模型的输出是连续的值则称为回归分析,如果预测一个分类标签则称为分类。
如果可以人为地建立数据库系统的特征(如workload特征、硬件环境特征等),并提供在该特征下的最优参数,那么就可以通过上述数据拟合出一个模型,并据此推测出新的数据库系统上何种参数最优。
该方法的优点是一旦训练好模型,推荐新参数的过程将非常快,缺点是训练模型比较复杂(需要收集大量的数据,这些数据本身就不是很容易获取)、模型的输入特征选择比较困难、如果系统发生变化则该模型需要重新训练。例如学术界比较著名的成果OtterTune便是采用了类似的方法。
4. 基于强化学习
强化学习(reinforcement learning,RL)在近些年发展迅速,基于深度学习的强化学习算法如DQN(deep q-networks,深度Q学习)、DDPG(deep deterministic policy gradient,深度确定性策略梯度算法)与PPO(proximal policy optimization,近端策略优化)等算法先后诞生,该类算法在游戏领域取得了比较好的效果,能够实现自动打游戏甚至游戏操作优于大多数的人类选手。与此同时,强化学习与监督学习不同,强化学习并不需要用户给定一个数据集,而是通过与环境进行交互,通过奖惩机制来学习哪些应该做,哪些不能做,从而给出更优的决策。
显然,强化学习能够应用到游戏领域,是因为游戏结果的好坏是比较明显的奖惩机制。输赢本身就是一个很好的价值导向,甚至能够不断获得经验值的游戏过程还能够得到连续不断的奖励,这就更容易让算法学到如何获取更多的经验。而反观数据库的调优过程,其实与游戏过程类似。数据库性能的好坏是比较明显的价值导向,数据库的参数配置就相当于游戏过程中的动作,数据库的状态信息也是可以获得的。因此,通过强化学习来进行数据库参数的调优是一个比较好的方案,该方法能够模仿DBA的调优过程,通过数据库性能的高低来激励好的参数配置。该方法的特点是能够从历史经验中进行学习,用训练后的模型进行参数推荐的过程也比较快,而且并不需要用户给定大量的训练数据。缺点是模型的训练过程比较复杂,算法中的奖励机制、数据库系统的状态等都需要精心设计,强化学习训练过程也比较慢。采用该类方法的代表性项目是由清华大学提出的QTune。
通过上述介绍,可以得出似乎并没有一种非常完美的方法能够覆盖到所有的应用场景。严格地讲,每类方法本身并没有优劣之分,只有更加适合业务场景的方法才能够称之为最优方法。因此,接下来将介绍一下openGauss开源的数据库参数调优工具X-Tuner,该工具综合了上述多种调优策略的优势。
8.2.3 X-Tuner的调优策略
总的来说,对数据库进行参数调优可以分为两大类,分别是离线参数调优和在线参数调优,X-Tuner同时支持上述两类调优模式。
(1) 离线参数调优是指在数据库脱离生产环境的基础上进行调优的,一般是在上线真实业务前进行压力测试,并通过压力测试的反馈结果进行参数调优。
(2) 在线参数调优是指不阻塞数据库的正常运行,在数据库运行中进行参数调优或推荐的过程。
具体来说,调优程序X-Tuner包含三种运行模式。
(1) recommend:获取当前正在运行的workload特征信息,根据上述特征信息生成参数推荐报告。报告当前数据库中不合理的参数配置和潜在风险等;输出当前正在运行的workload行为和特征;输出推荐的参数配置。该模式是秒级的,不涉及数据库的重启操作,其他模式可能需要反复重启数据库。
(2) train:通过用户提供的benchmark信息,迭代地进行参数修改和benchmark(一种用于测量硬件或软件性能的测试程序)执行过程,训练强化学习模型。通过反复的迭代过程,训练强化学习模型,以便用户在后面通过tune模式加载该模型进行调优。
(3) tune:使用优化算法进行数据库参数的调优,当前支持两大类算法,一种是深度强化学习,另一种是全局搜索算法(全局优化算法)。深度强化学习模式要求先运行train模式,生成训练后的调优模型,而使用全局搜索算法则不需要提前进行训练,可以直接进行搜索调优。如果在tune模式下,使用深度强化学习算法,要求必须有一个训练好的模型,且训练该模型时的参数与进行调优时的参数列表(包括max与min)必须一致。
无论是离线参数调优还是在线参数调优,X-Tuner都是支持的,他们的基本结构也是共用的。如图8-1所示,是X-Tuner各个模块的结构示意图以及交互形式。
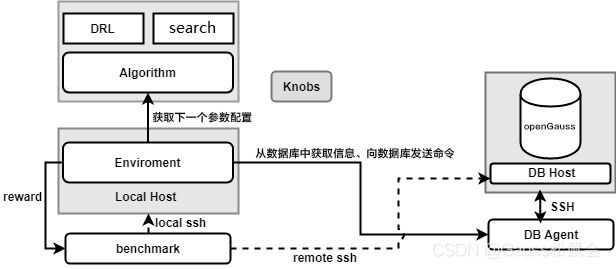
如图8-1所示,X-Tuner可以大致分为DB侧、算法侧、主体逻辑模块以及benchmark,它的各个部分的功能说明如表8-1所示。
| X-Tuner结构 | 说明 |
|---|---|
| DB侧 | 通过DB_Agent模块对数据库实例进行抽象,通过该模块可以获取数据库内部的状态信息、当前数据库参数、以及设置数据库参数等。DB侧包括登录数据库环境使用的SSH连接 |
| 算法侧 | 用于调优的算法包,包括全局搜索算法(如贝叶斯优化、粒子群算法等)和深度强化学习(如DDPG) |
| X-Tuner主体逻辑模块 | 通过Enviroment模块进行封装,每一个step就是一次调优过程。整个调优过程通过多个step进行迭代 |
| benchmark | 由用户指定的benchmark性能测试脚本,用于运行benchmark作业,通过跑分结果反映数据库系统性能优劣 |
1. 离线参数调优流程概述
X-Tuner利用长期在openGauss上进行参数调优的先验规则,根据系统的workload、环境特征推荐初始参数调优范围,该范围便是待搜索的配置参数空间。利用算法(如强化学习、启发式算法等)在给定的参数空间上不断进行搜索,即可找到最优的参数配置。
常规评价调优效果好坏的方法是运行benchmark,包括TPC-C、TPC-H以及用户自定义的banchmark,用户只需要进行少量适配即可。离线参数调优的流程图如图8-2所示。
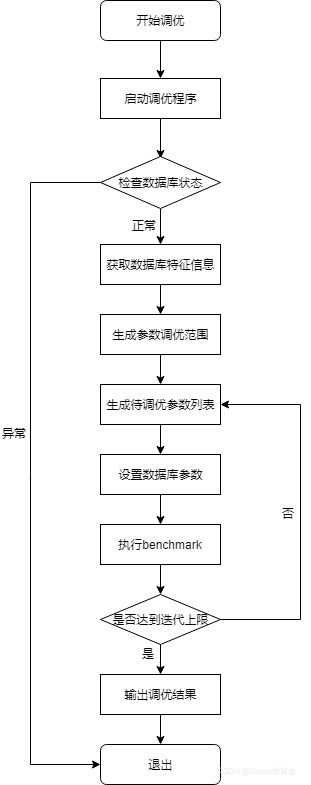
对于离线调优,用户通过benchmark模拟真实环境中的workload,使用调优工具X-Tuner根据不同参数在benchmark上的表现来判断什么参数能够取得最佳表现。需要注意的是,整个离线调优过程是迭代式的,即设置完一次参数后,执行一次benchmark用于检验本次设置的参数好坏。上述过程称之为一次调优过程,那么X-Tuner只需要多次执行上述过程,即可找到一个最佳的参数配置。X-Tuner可以根据上一个调优过程的反馈,决定下一次调优中参数的寻找方向,这个过程也是优化算法的探索过程。
细心的读者可能会发现,上述过程是需要有一个初始参数配置的,这个初始参数配置对于已经训练好的强化学习模型来说,会利用模型进行初始化。若是采用搜索算法,则根据先验规则进行初始化。
由于某些数据库参数需要重启后方可生效,因此离线参数调优过程也可能是需要频繁地重启数据库的。离线调优过程与DBA手动调优过程比较相似,都是通过观察-试探-再观察-再试探进行的,只不过这个试探过程不是基于DBA的人工经验,而是通过算法的分析进行的。该过程也是比价耗时的,主要耗在执行benchmark上。
对于一些场景,可以采用explain命令替代,这样就可以省掉了执行benchmark的时间,但是explain并不能直接反映参数对缓冲区、WAL等数据库系统内部模块的影响,因此可使用的场景是有限的。业内的一个比较前沿的方法,是通过AI的方法,预估数据库的性能表现,一般称之为性能评估模型(performance model),通过该模型,可以省去执行benchmark的时间,从而压缩调优时间。不过该方法主要停留在理论界,距离在普适场景上的应用尚有差距,目前也在openGauss的演进方向中。
X-Tuner目前支持的强化学习算法主要为DDPG,支持的搜索算法主要为粒子群算法(particle swarm optimization,PSO)与贝叶斯优化算法(bayesian optimization)。
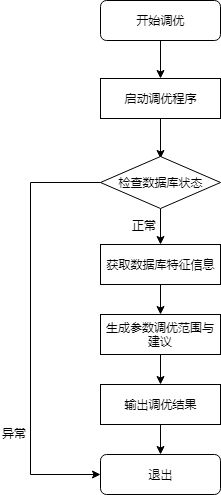
2. 在线参数调优流程概述
X-Tuner采集操作系统的统计信息和workload特征,根据训练好的监督学习模型或先验规则,推荐给用户对应的参数修改建议。在线参数调优过程的流程图如图8-3所示。
8.2.4 openGauss关键源码解析
X-Tuner在项目中的源代码路径为:openGauss-server/src/gausskernel/dbmind/tools/xtuner。
1. 项目结构
X-Tuner文件结构如表8-2所示。
文件结构 |
说明 |
setup.py |
安装脚本 |
share |
配置文件示例 |
test |
单元测试文件的目录 |
tuner |
调优程序主代码目录 |
tuner/algorithms |
算法子模块 |
tuner/algorithms/pso.py |
粒子群算法 |
tuner/benchmark |
压力测试驱动脚本存储的目录 |
tuner/benchmark/sysbench.py |
sysbench驱动脚本 |
tuner/benchmark/template.py |
压力测试驱动脚本的模板 |
tuner/benchmark/tpcc.py |
TPC-C驱动脚本 |
tuner/benchmark/tpcds.py |
TPC-DS驱动脚本 |
tuner/benchmark/tpch.py |
TPC-H驱动脚本 |
tuner/character.py |
获取系统workload特征的模块 |
tuner/db_agent.py |
封装数据库操作的模块 |
tuner/db_env.py |
离线调优流程控制模块 |
tuner/env.py |
保持与强化学习gym库的接口一致 |
tuner/exceptions.py |
定义常见异常 |
tuner/executor.py |
封装shell连接 |
knobs/knob.py |
定义参数相关类 |
knobs/main.py |
入口文件 |
knobs/recommend.py |
定义参数推荐的算法与规则 |
knobs/recorder.py |
记录调优过程的模块 |
knobs/utils.py |
定义一些工具函数 |
knobs/xtuner.conf |
默认配置文件 |
knobs/xtuner.py |
调优主流程控制模块 |
knobs/README.md |
安装脚本 |
2. 总体流程解析
入口总体流程在main.py中给出,main函数的核心代码如下:
def main():
…
# 通过命令行参数或连接信息文件构建db_info字典,利用该字典中的信息可以登录到数据库实例和宿主机上
db_info = build_db_info(args)
if not db_info:
parser.print_usage()
return -1
# 解析配置文件中给定的配置项
config = get_config(args.tuner_config_file)
if not config:
return -1
try:
# 当获取到足够的信息后,进入工具的执行流程
return procedure_main(mode, db_info, config)
except Exception as e:
logging.exception(e)
print('FATAL: An exception occurs during program running. '
'The exception information is "%s". '
'For details about the error cause, please see %s.' % (e, config['logfile']),
file=sys.stderr, flush=True)
return -1
可以看到main函数主要是做一些参数、命令行的校验、收集工作,核心流程定义在xtuner.py的procedure_main函数中,该函数的核心代码如下:
def procedure_main(mode, db_info, config):
# 权限最小化
os.umask(0o0077)
# 初始化日志模块
set_logger(config['logfile'])
logging.info('Starting... (mode: %s)', mode)
# 利用new_db_agent函数构造DB_Agent对象,该对象是唯一对数据库操作进行封装的对象
db_agent = new_db_agent(db_info)
# 如果用户没有通过配置文件指定负载类型,则通过预定义的算法或规则进行自动判断
if config['scenario'] in WORKLOAD_TYPE.TYPES:
db_agent.metric.set_scenario(config['scenario'])
else:
config['scenario'] = db_agent.metric.workload_type
# 同上,如果用户设置为自动模式,则使用下述默认规则补充
if config['tune_strategy'] == 'auto':
# If more iterations are allowed, reinforcement learning is preferred.
if config['rl_steps'] * config['max_episode_steps'] > 1500:
config['tune_strategy'] = 'rl'
else:
config['tune_strategy'] = 'gop'
logging.info("Configurations: %s.", config)
# 如果在配置文件中指定了tuning_list配置项,并且非reocmmend模式,则加载该待调优参数列表的配置文件,否则通过recommend_knobs函数智能获取待调优参数列表
if config['tuning_list'].strip() != '' and mode != 'recommend':
knobs = load_knobs_from_json_file(config['tuning_list'])
else:
print("Start to recommend knobs. Just a moment, please.")
knobs = recommend_knobs(mode, db_agent.metric)
if not knobs:
logging.fatal('No recommended best_knobs for the database. Stop the execution.')
return -1
# 如果是调优和训练模式,由于某些数据库参数是需要重启后才生效的,因此可能会伴随着反复的重启过程
if mode != 'recommend': # 不为recommend模式,就只能是tune或者train模式,而这两种模式都是离线过程,需要反复迭代
prompt_restart_risks() # 告知用户调优过程中有数据库重启的风险
# 初始化调优中的记录类
recorder = Recorder(config['recorder_file'])
# 分别读取配置文件中的三个配置项:benchmark_script、benchmark_path以及benchmark_cmd,通过这三个配置项就可以获取到benchmark驱动脚本的实例,可以用它来衡量数据库的性能
bm = benchmark.get_benchmark_instance(config['benchmark_script'],
config['benchmark_path'],
config['benchmark_cmd'],
db_info)
# 初始化数据库调优环境实例,该对象封装了迭代过程,保持与强化学习库gym.Env的接口一致
env = DB_Env(db_agent, benchmark=bm, recorder=recorder,
drop_cache=config['drop_cache'],
mem_penalty=config['used_mem_penalty_term'])
env.set_tuning_knobs(knobs)
# 识别不同的模式,不同模式执行对应的子程序
if mode == 'train':
rl_model('train', env, config)
elif mode == 'tune':
…
# 执行到此处时,已经完成调优过程。下述代码负责将调优结果输出
knobs.output_formatted_knobs()
if config['output_tuning_result'] != '':
with open(config['output_tuning_result'], 'w+') as fp:
# train模式是强化学习独有的模式,在该模式下,只输出调优参数,不输出报告参数(建议参数)。这是因为,在强化学习的tune模式下,待调优参数列表应当与train模式下保存的调优列表需要完全相同,即调优参数名相同、调优范围相同、各个参数的顺序相同,否则会导致输入特征不符合。
knobs.dump(fp, dump_report_knobs=mode != 'train')
logging.info('X-Tuner is executed and ready to exit. '
'Please refer to the log for details of the execution process.')
return 0
综上,调优程序是一个独立于数据库内核之外的工具,需要提供数据库及其所在实例的用户名和登录密码信息,以便控制数据库执行benchmark进行性能测试;在启动调优程序前,要求用户测试环境交互正常,能够正常跑通benchmark测试脚本、能够正常连接数据库。
3. benchmark模块解析
benchmark的驱动脚本存放路径为X-Tuner的benchmark子目录。X-Tuner自带常用的benchmark驱动脚本,例如TPC-C、TPC-H等。X-Tuner通过调用benchmark/init.py文件中的get_benchmark_instance函数来加载不同的benchmark驱动脚本,获取benchmark驱动实例。其中,benchmark驱动脚本的格式如表8-3所示。
脚本格式 |
说明 |
驱动脚本文件名 |
表示benchmark的名字,该名字用于表示驱动脚本的唯一性,可通过在X-Tuner的配置文件中的配置项benchmark_script来指定选择加载哪个benchmark驱动脚本 |
驱动脚本内容三要素 |
path变量、cmd变量以及run函数 |
benchmark目录中的template.py文件是benchmark驱动脚本的模板,在该目录中,有TPC-C、TPC-H等预先写好的示例,都是基于该模板实现的。该模板定义了benchmark驱动脚本的基本结构,每个benchmark驱动脚本对调优程序来说,都可以认为是一个黑盒,只需要明确输入、输出的格式即可。下面来看看template.py中定义的benchmark驱动脚本格式。
# 提示:你需要先把数据导入到数据库中
# 调优程序会自动调用下述函数,该函数返回结果值就是benchmark测试结果
# path 变量表示实际benchmark所在路径
path = ''
# cmd变量定义了使用什么shell命令才可以启动benchmark
cmd = ''
# 函数定义了远端和本地的命令行接口,通过exec_command_sync()方法执行shell命令
def run(remote_server, local_host) -> float:
return 0
下面给出几个具体的例子,tpcc.py中给出的TPC-C测试脚本的例子如下:
from tuner.exceptions import ExecutionError
# 提示:你需要自己下载benchmark-sql测试工具,同时使用openGauss的JDBC驱动替换PostgreSQL目录下的JDBC驱动文件。你需要自己配置好TPC-C测试配置
# 测试程序通过下述命令运行
path = '/path/to/benchmarksql/run' # TPC-C测试脚本benchmark-sql的存放路径
cmd = "./runBenchmark.sh props.gs" # 自定义一个名为props.gs的benchmark-sql测试配置文件
def run(remote_server,local_host):
# 切换到TPC-C脚本目录下,清除历史错误日志,然后运行测试命令
# 此处最好等待几秒钟,因为benchmark-sql测试脚本生成最终测试报告是通过一个shell脚本实现的,整个过程会有延迟
# 为了保证能够获取到最终的tpmC数值报告,这里选择等待3秒钟
stdout, stderr = remote_server.exec_command_sync(['cd %s' % path, 'rm -rf benchmarksql-error.log', cmd, 'sleep 3'])
# 如果标准错误流中有数据,则报异常退出
if len(stderr) > 0:
raise ExecutionError(stderr)
# 寻找最终tpmC结果
tpmC = None
split_string = stdout.split() # 对标准输出流结果进行分词
for i, st in enumerate(split_string):
# 在benchmark-sql 5.0中,tpmC最终测试结果数值在‘(NewOrders)’关键字的后两位,正常情况下,找到该字段后直接返回即可
if "(NewOrders)" in st:
tpmC = split_string[i + 2]
break
stdout, stderr = remote_server.exec_command_sync(
"cat %s/benchmarksql-error.log" % path)
nb_err = stdout.count("ERROR:") # 判断整个benchmark运行过程中,是否有报错,记录报错的错误数
return float(tpmC) - 10 * nb_err # 这里将报错的错误数作为一个惩罚项,惩罚系数为10,越高的惩罚系数表示越看中报错的数量
其中,TPC-C配置文件props.gs的关键内容如下:
db=opengauss
driver=org.postgresql.Driver
// 配置连接信息
conn=jdbc:postgresql://192.168.1.100:5678/tpcc
…
// 定义数据量
warehouses=1
loadWorkers=4
// 定义并发量
terminals=100
//To run specified transactions per terminal- runMins must equal zero
runTxnsPerTerminal=10
//To run for specified minutes- runTxnsPerTerminal must equal zero
runMins=0
//Number of total transactions per minute
limitTxnsPerMin=300
…
有关TPC-C的测试脚本benchmark-sql的使用,网上公开的教程和资料非常多,此处不再赘述。openGauss的JDBC驱动可以在官方网站上进行下载,下载地址为:https://opengauss.org/zh/download.html。
下面再看一下TPC-H的例子。
import time
from tuner.exceptions import ExecutionError
# 提示:你需要先自行导入数据,然后准备sql测试文件
# 下述程序会自动采集整体运行时延
path = '/path/to/tpch/queries' # 存放TPC-H测试用的SQL脚本目录
cmd = "gsql -U {user} -W {password} -d {db} -p {port} -f {file}" # 需要运行TPC-H测试脚本的命令,一般使用'gsql -f 脚本文件'来运行
# 需要指出的是,由于可能会通过gsql连接数据库,因此可能会需要用户名、密码等信息,可以通过上述占位符,如{user}、{password}等进行占位,X-Tuner会自行渲染
def run(remote_server, local_host):
…
# 代价为全部测试用例的执行总时长
cost = time.time() - time_start
# 取相反数,适配run 函数的定义:返回结果越大表示性能越好。
return - cost
TPC-H脚本的全局变量cmd中存在占位符{user}、{password}等,这些会通过X-Tuner进行渲染,相关代码存在于benchmark/init.py中,如下所示:
def get_benchmark_instance(script, path, cmd, db_info):
…
# 验证benchmark 脚本有效性,如果没有指定path与cmd变量,会抛出异常
if (not getattr(bm, 'path', False)) or (not getattr(bm, 'cmd', False)) or (not getattr(bm, 'run', False)):
raise ConfigureError('The benchmark script %s is invalid. '
'For details, see the example template and description document.' % script)
# 检查run函数是否存在,且参数数量为2,即本地和远程两个shell接口
check_run_assertion = isinstance(bm.run, types.FunctionType) and bm.run.__code__.co_argcount == 2
if not check_run_assertion:
raise ConfigureError('The run function in the benchmark instance is not correctly defined. '
'Redefine the function by referring to the examples.')
# cmd与path变量,优先使用配置文件中的配置项,如果没有对应的配置项,则默认使用脚本中的内容
if path.strip() != '':
bm.path = path
if cmd.strip() != '':
bm.cmd = cmd
# 渲染cmd命令中的占位符
bm.cmd = bm.cmd.replace('{host}', db_info['host']) \
.replace('{port}', str(db_info['port'])) \
.replace('{user}', db_info['db_user']) \
.replace('{password}', db_info['db_user_pwd']) \
.replace('{db}', db_info['db_name'])
# 将数据库宿主机的shell接口包装起来
def wrapper(server_ssh):
return bm.run(server_ssh, local_ssh)
return wrapper
4. 数据库交互部分源码解析
首先来看一下数据库需要调整的参数是如何在程序中存储的。数据库的参数可能是布尔型的,如off或on,也可以是整数型的或浮点型的。但是,计算机算法(如强化学习、全局搜索算法等)只能接受数值结果,因此需要数值化。这就需要定义一个名为Knob的类,封装数据库的参数。
class Knob(object):
def __init__(self, name, knob):
…
# 将整形数值转换为数据库可以接受的字符串型字面量
def to_string(self, val):
…
# 将字符串型的字面量转换为数值型
def to_numeric(self, val):
…
当DB_Agent类需要被告知要调节的参数时,通过Knob类将待调优的参数包装起来,并作为该类的一个属性存储在内存中。
DB_Agent类实现了对数据库行为的封装,是X-Tuner与数据库进行交互的唯一接口,该类的代码实现如下:
class DB_Agent:
def __init__(self, host, host_user, host_user_pwd,
db_user, db_user_pwd, db_name, db_port, ssh_port=22):
…
# 设置语句的执行时间不限
self.set_knob_value("statement_timeout", 0)
# 初始化数据库的特征指标接口
self.metric = openGaussMetric(self)
def check_connection_params(self):
# 检查数据库连接参数是否正确
…
def set_tuning_knobs(self, knobs):
# 设置调优参数,参数类型为RecommendedKnobs, 该类在knob.py文件中定义
if not isinstance(knobs, RecommendedKnobs):
raise TypeError
self.knobs = knobs
self.ordered_knob_list = self.knobs.names()
…
def exec_statement(self, sql, timeout=None):
# 在数据库内执行SQL语句,是通过调用gsql命令来实现的
command = "gsql -p {db_port} -U {db_user} -d {db_name} -W {db_user_pwd} -c \"{sql}\";".format(
db_port=self.db_port,
db_user=self.db_user,
db_name=self.db_name,
db_user_pwd=self.db_user_pwd,
sql=sql
)
…
def is_alive(self):
# 检查数据库是否运行
...
def exec_command_on_host(self, cmd, timeout=None, ignore_status_code=False):
# 在数据库的宿主机上执行shell命令
...
def get_knob_normalized_vector(self):
# 获取待调优参数的结果,并将其进行归一化(映射到0与1之间)。返回结果是一个列表
nv = list()
for name in self.ordered_knob_list:
val = self.get_knob_value(name)
nv.append(self.knobs[name].to_numeric(val))
return nv
def set_knob_normalized_vector(self, nv):
# 与get_knob_normalized_vector()方法对应,参数nv表示normalized_vector,即都是已经映射到0与1之间的、经过数值化的参数值,将这些参数值设置到数据库上
restart = False
for i, val in enumerate(nv):
name = self.ordered_knob_list[i]
knob = self.knobs[name]
self.set_knob_value(name, knob.to_string(val))
restart = True if knob.restart else restart
# 如果这些待设置的参数中有需要重启数据库的,则重启数据库以便使设置后的参数生效
if restart:
self.restart()
def get_knob_value(self, name):
# 单独获取某个参数的值,该参数值是不经标准化的
check_special_character(name)
sql = "SELECT setting FROM pg_settings WHERE name = '{}';".format(name)
_, value = self.exec_statement(sql)
return value
def set_knob_value(self, name, value):
# 单独设置某个参数的值,该参数值是不经标准化的,通过gs_guc命令设置数据库参数值
logging.info("change knob: [%s=%s]", name, value)
try:
self.exec_command_on_host("gs_guc reload -c \"%s=%s\" -D %s" % (name, value, self.data_path))
except ExecutionError as e:
if str(e).find('Success to perform gs_guc!') < 0:
logging.warning(e)
def reset_state(self):
# 重置数据库的状态,例如对 pg_stat_database等系统表进行重置
self.metric.reset()
def set_default_knob(self):
# 设置数据库的参数值为默认值,该默认值通过knob类型指定,即在对应的配置文件中指定的值
restart = False
for knob in self.knobs:
self.set_knob_value(knob.name, knob.default)
restart = True if knob.restart else restart
self.restart()
def restart(self):
# 重启数据库
...
def drop_cache(self):
# 对于openGauss数据库来说,drop cache可以使每次benchmark的跑分更加稳定,但是这需要root权限
# 如果用户需要drop cache,则可以向/etc/sudoers中写入'username ALL=(ALL) NOPASSWD: ALL'
...
5. 算法模块源码解析
可以将数据库的离线参数调优过程看作一个组合优化过程,即找到使数据库性能最好时的参数配置,该过程可以通过下述数学表达式描述。
其中,表示数据库在某个参数配置下的性能,表示数据库的参数配置,表示数据库参数的可配置集合。
X-Tuner支持的算法包括DDPG、PSO、贝叶斯优化,虽然实现原理不同,但他们都可以搜寻上述表达式中的,即数据库的最优参数配置。DDPG算法和贝叶斯优化算法通过引入第三方库实现,PSO算法则自行实现,实现代码在algorithms/pso.py文件中。
在tuner/xtuner.py文件中定义了全局搜索算法与强化学习算法的执行流程,其中强化学习算法的流程代码如下:
def rl_model(mode, env, config):
# 由于加载tensorflow的过程过于耗时,且并非是必要的,因此采用懒加载的模式
from tuner.algorithms.rl_agent import RLAgent
# 启动强化学习代理类
rl = RLAgent(env, alg=config['rl_algorithm'])
# 训练和调优两种模式对应不同的执行流程
# 模型需要先训练,然后才可以利用该模型进行调优。训练和调优过程的输出是待调优参数列表,由于共用一套模型,因此两种模式下,要求待调优的参数列表必须是一致的,否则会抛出输出维度不同的异常。
if mode == 'train':
logging.warning('The list of tuned knobs in the training mode '
'based on the reinforcement learning algorithm must be the same as '
'that in the tuning mode. ')
# 比较关键的参数是最大迭代轮次rl_steps,理论上越长越精准,但是也更加耗时
# max_episode_steps是强化学习算法中的每一轮的最大回合次数,在X-Tuner实现中,该参数被弱化了,一般默认即可
rl.fit(config['rl_steps'], nb_max_episode_steps=config['max_episode_steps'])
rl.save(config['rl_model_path'])
logging.info('Saved reinforcement learning model at %s.', config['rl_model_path'])
elif mode == 'tune':
…
全局优化算法的流程代码如下:
def global_search(env, config):
method = config['gop_algorithm']
# 判断选择使用哪种算法
if method == 'bayes':
from bayes_opt import BayesianOptimization
action = [0 for _ in range(env.nb_actions)]
pbound = {name: (0, 1) for name in env.db.ordered_knob_list}
# 定义一个黑盒函数,用于适配第三方库的接口
def performance_function(**params):
assert len(params) == env.nb_actions, 'Failed to check the input feature dimension.'
for name, val in params.items():
index = env.db.ordered_knob_list.index(name)
action[index] = val
s, r, d, _ = env.step(action)
return r # 期望结果越大越好
optimizer = BayesianOptimization(
f=performance_function,
pbounds=pbound
)
optimizer.maximize(
# 最大迭代轮次越大结果越精准,但是也更耗时
n_iter=config['max_iterations']
)
elif method == 'pso':
from tuner.algorithms.pso import Pso
def performance_function(v):
s, r, d, _ = env.step(v, False)
return -r # 因为PSO算法的实现中是寻找全局最小值,这里取相反数,就改为取全局最大值
pso = Pso(
func=performance_function,
dim=env.nb_actions,
particle_nums=config['particle_nums'],
# 最大迭代轮次越大结果越精准,但是也更耗时
max_iteration=config['max_iterations'],
x_min=0, x_max=1, max_vel=0.5
)
pso.minimize()
else:
raise ValueError('Incorrect method value: %s.' % method)
上述代码描述的是离线调优过程的策略,对于在线调优,则主要是以启发式规则的方法实现的,其主要代码存在于tuner/recommend.py中,此处逻辑大同小异,下面以shared_buffer参数推荐为例:
@cached_property
def shared_buffers(self):
# 此处应用的是DBA普遍认同的调优策略:在大内存环境下,shared_buffer占比可更高一些,小内存情况下占比应下调
mem_total = self.metric.os_mem_total # unit: kB
if mem_total < 1 * SIZE_UNIT_MAP['GB']:
default = 0.15 * mem_total
elif mem_total > 8 * SIZE_UNIT_MAP['GB']:
default = 0.4 * mem_total
else:
default = 0.25 * mem_total
recommend = default / self.metric.block_size
if self.metric.is_64bit:
database_blocks = self.metric.all_database_size / self.metric.block_size
# 如果数据库文件的比较小,则shared_buffer 也无须设置得太大,否则便是浪费资源
if database_blocks < recommend:
self.report.print_warn("The total size of all databases is less than the memory size. "
"Therefore, it is unnecessary to set shared_buffers to a large value.")
recommend = min(database_blocks, recommend)
upper = recommend * 1.15
lower = min(0.15 * mem_total / self.metric.block_size, recommend)
return Knob.new_instance(name="shared_buffers",
value_default=recommend,
knob_type=Knob.TYPE.INT,
value_max=upper,
value_min=lower,
restart=True)
else:
# 对于非64位操作系统,shared_buffer无须设置得太大
upper = min(recommend, 2 * SIZE_UNIT_MAP["GB"] / self.metric.block_size) # 32-bit OS only can use 2 GB mem.
lower = min(0.15 * mem_total / self.metric.block_size, recommend)
return Knob.new_instance(name="shared_buffers",
value_default=recommend,
knob_type=Knob.TYPE.INT,
value_max=upper,
value_min=lower,
restart=True)
不同的参数应用的规则都不相同,主要参考数据库的workload特征、硬件环境、当前状态等。即对于AP与TP场景,参数配置是不同的,如果用户没有通过配置文件明确指定场景的类型,则根据character.py文件中定义的workload_type()方法自动判断,获取数据库特征的方法都在character.py文件中定义。
8.2.5 使用示例
1. 运行源码的方法
可以通过两种方式运行X-Tuner,一种是直接通过源码运行,另一种则是通过python的setuptools将X-Tuner安装到系统上,而后直接通过gs_xtuner命令调用。下面分别介绍两种运行X-Tuner的方法。
方法一:直接通过源代码运行。
(1) 切换到X-Tuner的代码根目录下,执行下述命令安装所需依赖。
pip install -r requirements.txt
(2) 安装成功后需要添加环境变量PYTHONPATH,然后执行main.py主文件,方法如下:
cd tuner # 切换到main.py文件所在的目录中
export PYTHONPATH='..' # 将上一级目录添加到PYTHONPATH环境变量中,即可寻找到包所在的路径
python main.py --help # 执行相应的功能,此处以获取帮助为例
方法二:将X-Tuner安装到系统中。
使用如下命令直接执行源码根目录中的setup.py文件。
python setup.py install
如果python的bin目录被添加到PATH环境变量中,则gs_xtuner命令也可以在任何地方被直接调用。例如,可以通过下述命令获取帮助信息。
gs_xtuner --help
2. 参数推荐模式使用示例
在了解如何运行X-Tuner后,可以看一下运行X-Tuner的几种模式,首先介绍一下在线参数推荐模式,执行下述命令,填写对应的数据库连接信息,并输入对应密码后即可获得参数推荐结果。
gs_xtuner recommend --db-name opengauss --db-user omm --port 5678 --host 192.168.1.100 --host-user omm
当然,上面的数据库连接信息比较长,也可以通过json文件的格式传入,某个包含数据库连接信息的json格式文件内容如下:
{
"db_name": "opengauss", # 数据库名
"db_user": "omm", # 登录到数据库上的用户名
"host": "127.0.0.1", # 数据库宿主机的IP地址
"host_user": "omm", # 登录到数据库宿主机的用户名
"port": 5432, # 数据库的侦听端口号
"ssh_port": 22 # 数据库宿主机的SSH侦听端口号
}
假设上述文件名为connection.json,则通过下述命令即可使用该文件。
gs_xtuner recommend –f connection.json
经过几秒钟的诊断,会给出数据库参数配置的诊断信息以及推荐的参数调优列表,结果示例如图8-4所示。

在图8-4报告中,推荐了该环境上的数据库参数配置,并进行了风险提示。报告同时生成了当前workload的特征信息,其中有几个特征是比较有参考意义的,这些特征的具体获取方法都在character.py文件中可以看到,详细说明如表8-4所示。
特征名称 |
特征说明 |
temp_file_size |
产生的临时文件数量,如果该结果大于0,则表明系统使用了临时文件。使用过多的临时文件会导致性能不佳,如果可能的话,需要提高work_mem参数的配置 |
cache_hit_rate |
shared_buffer的缓存命中率,表明当前workload使用缓存的效率 |
read_write_ratio |
数据库作业的读写比例 |
search_modify_ratio |
数据库作业的查询与修改数据的比例 |
ap_index |
表明当前workload的AP(analytical processing,分析处理)指数,取值范围是0到10,该数值越大,表明越偏向于数据分析与检索 |
workload_type |
根据数据库统计信息,推测当前负载类型,分为AP、TP以及HTAP三种类型 |
checkpoint_avg_sync_time |
数据库在checkpoint时,平均每次同步刷新数据到磁盘的时长,单位是毫秒 |
load_average |
平均每个CPU核心在1分钟、5分钟以及15分钟内的负载。一般地,该数值在1左右表明当前硬件比较匹配workload、在3左右表明运行当前作业压力比较大,大于5则表示当前硬件环境运行该workload压力过大(此时一般建议减少负载或升级硬件) |
3. 训练模式使用示例
在使用训练和调优模式前,用户需要先导入benchmark所需数据并检查benchmark能否正常跑通,并备份好此时的数据库参数,查询当前数据库参数的SQL语句如下所示:
select name, setting from pg_settings;
训练模式和调优模式的过程类似,区别仅在于对配置文件的配置。X-Tuner模式使用的配置文件路径可以通过–help命令获取,代码如下所示:
...
-x TUNER_CONFIG_FILE, --tuner-config-file TUNER_CONFIG_FILE
This is the path of the core configuration file of the
X-Tuner. You can specify the path of the new
configuration file. The default path is /path/to/xtuner/xtuner.conf.
You can modify the configuration file to control the
tuning process.
...
通过help命令可以找到默认读取的配置文件路径,如果希望指定别的读取路径,则可以通过–x参数来完成。该配置文件的各个配置项的含义如表8-5所示。
参数名 |
参数说明 |
取值范围 |
logfile |
生成的日志存放路径 |
- |
output_tuning_result |
可选,调优结果的保存路径 |
- |
verbose |
是否打印详情 |
on,off |
recorder_file |
调优中间信息的记录日志存放路径 |
- |
tune_strategy |
调优模式下采取哪种策略 |
rl,gop,auto |
drop_cache |
是否在每一个迭代轮次中进行drop cache,drop cache可以使benchmark跑分结果更加稳定。若启动该参数,则需要将登录的系统用户加入到/etc/sudoers列表中,同时为其增加NOPASSWD权限(由于该权限可能过高,建议临时启用该权限,调优结束后关闭) |
on,off |
used_mem_penalty_term |
数据库使用总内存的惩罚系数,用于防止通过无限量占用内存而换取的性能表现。该数值越大,惩罚力度越大 |
0 ~ 1 |
rl_algorithm |
选择何种RL算法 |
ddpg |
rl_model_path |
RL模型保存或读取路径,包括保存目录名与文件名前缀。在train模式下该路径用于保存模型,在tune模式下则用于读取模型文件 |
- |
rl_steps |
RL算法迭代的步数 |
- |
max_episode_steps |
每个回合的最大迭代步数 |
- |
test_episode |
使用RL算法进行调优模式的回合数 |
|
gop_algorithm |
采取何种全局搜索算法 |
bayes,pso,auto |
max_iterations |
全局搜索算法的最大迭代轮次(并非确定数值,可能会根据实际情况多跑若干轮) |
- |
particle_nums |
PSO算法下的粒子数量 |
- |
benchmark_script |
使用何种benchmark驱动脚本,该选项指定加载benchmark路径下同名文件,默认支持TPC-C、TPC-H等典型benchmark |
tpcc,tpch,tpcds,sysbench… |
benchmark_path |
benchmark脚本的存储路径,若没有配置该选项,则使用benchmark驱动脚本中的配置 |
- |
benchmark_cmd |
启动benchmark脚本的命令,若没有配置该选项,则使用benchmark驱动脚本中的配置 |
- |
scenario |
用户指定的当前workload所属的类型 |
tp,ap,htap |
tuning_list |
准备调优的参数列表文件,可参考share/knobs.json.template文件 |
- |
(1) rl_algorithm:用于训练强化学习模型的算法,当前支持设置为ddpg。
(2) rl_model_path:训练后生成的强化学习模型保存路径。
(3) rl_steps:训练过程的最大迭代步数。
(4) max_episode_steps:每个回合的最大步数。
(5) scenario:明确指定的workload类型,如果为auto则为自动判断。在不同模式下,推荐的调优参数列表也不一样。
(6) tuning_list:用户指定需要调哪些参数,如果不指定,则根据workload类型自动推荐应该调的参数列表。如需指定,则tuning_list表示调优列表文件的路径。调优列表配置文件的文件内容示例如下所示:
{
"work_mem": {
"default": 65536,
"min": 65536,
"max": 655360,
"type": "int",
"restart": false
},
"shared_buffers": {
"default": 32000,
"min": 16000,
"max": 64000,
"type": "int",
"restart": true
},
"random_page_cost": {
"default": 4.0,
"min": 1.0,
"max": 4.0,
"type": "float",
"restart": false
},
"enable_nestloop": {
"default": true,
"type": "bool",
"restart": false
}
}
待上述配置项配置完成后,可以通过下述命令启动训练:
gs_xtuner train -f connection.json
训练完成后,会在配置项rl_model_path指定的目录中生成模型文件。
4. 调优模式使用示例
tune模式支持多种算法,包括基于强化学习的DDPG算法、基于全局搜索算法(global optimization algorithm,GOP)算法的贝叶斯优化算法以及PSO。
与tune模式相关的配置项如下。
(1) tune_strategy:指定选择哪种算法进行调优,支持RL、GOP以及auto(自动选择)。若该参数设置为RL,则RL相关的配置项生效。除train模式下生效的配置项外,test_episode配置项也生效,该配置项表明调优过程的最大回合数,该参数直接影响了调优过程的执行时间(一般地,数值越大越耗时)。
(2) gop_algorithm:选择何种全局搜索算法,支持bayes以及PSO。
(3) max_iterations:最大迭代轮次,数值越高搜索时间越长,效果往往越好。
(4) particle_nums:在PSO算法上生效,表示粒子数。
(5) 待上述配置项配置完成后,可以通过下述命令启动调优。
gs_xtuner tune -f connection.json
训练、调优过程的日志保存在配置文件指定的目录中,运行事件的记录日志文件名为opengauss-tuner.log,调优参数中间结果保存在名为recorder.log的文件中。在调优过程中,可以通过tail –f命令观察详细的运行过程。
8.2.6 对X-Tuner的二次开发
在8.2.3 X-Tuner的调优策略小节和8.2.5使用示例小节中已经展示了X-Tuner各个模块的作用,从结构上看,可以针对下述几个部分进行扩展。
(1) benchmark模块:可以通过benchmark/template.py模板文件的内容,自定义与生产环境类似的workload,并启动离线调优。
(2) 离线参数推荐规则:可以通过修改recommend.py文件,对openGaussKnobAdvisor类进行扩展或修改,即可增加或修改待调优的参数。
(3) 离线调优算法模块:可以通过增加新的优化算法来寻找最优的参数配置,在xtuner.py文件中修改对应流程。
8.2.7 X-Tuner的演进路线
对于离线参数调优过程来说,运行时间长、迭代次数多是该过程缓慢的主要原因,因此,找到一种高效的参数评估方法就显得尤为重要了。常见的可替代方案包括DBA经验估计,explain代价估计等。但是,上述方法都只能覆盖部分数据库参数,且误差往往不可控。未来,openGauss将聚焦通过算法手段高效评估数据库性能,实现一套完整的性能评估模型。
感谢大家学习第8章 AI技术中“8.1 概述”及“8.2 自调优”的精彩内容,下一篇我们开启“8.3 慢SQL发现”的相关内容的介绍。
敬请期待。