JAVA实现双向链表超详解(图解)
这一篇,说一下双链表的实现,双向链表一定是在单链表的基础上,进行优化,才能成为双链表,关于单链表的文章,可以看下面这个链接:
https://blog.csdn.net/weixin_46726346/article/details/107687955
所以一些重复的东西就不会再说了,言归正传,我们开始说双向链表;
之前说过单链表的结构,我们再来看一下:

单链表的查询方式,只能通过顺序遍历一遍才能查询,这也是单链表的一个缺陷,那有没有什么解决办法,或者是优化办法,这个时候双向链表出现了!
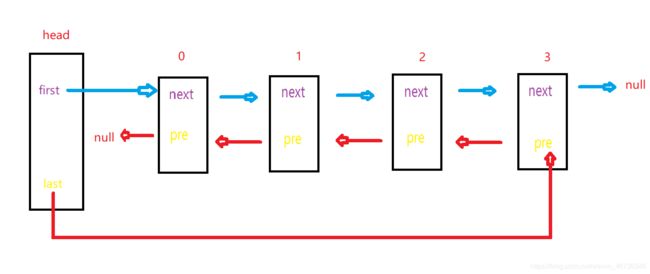
我们来看一下双向链表的结构:
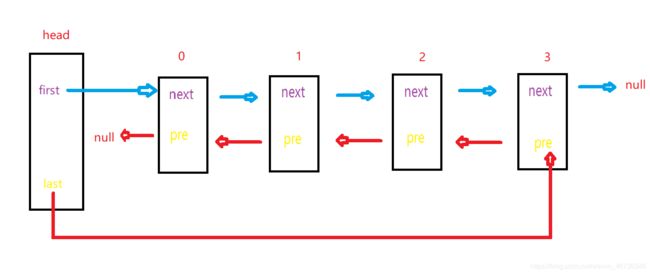
可以看到,头节点除了first,还有一个last指向最后一个节点的pre,每个节点除了next还有一个pre来指向上一个节点的地址。
那这么做有什么用呢,看图,如果我想找到3号元素,按以前的单链表,是不是只能先找0,再找1,再找2,最后找3.
现在呢,有了这个pre,我是不是直接last就是3,从后面找是不是就更快了。
那,知道了双向链表的结构,现在我们就可以开始写代码了!
一、节点类
节点类,只是在之前的情况下,加了一个pre对吧,我们再改一下构造函数,就可以了。
public class Node<E> {
E element;
Node pre;
Node next;
public Node(Node pre,Node next,E element) {
this.next=next;
this.pre=pre;
this.element=element;
}
}
然后链表类要加上一个last成员变量:
public class DoubleList<E> {
private Node first;
private Node last;
private int size;
}
二、获取节点的方法
获取节点的方法,就不能用以前单链表的了,我们要判断要获取节点的位置,如果在中间靠前,我们就依旧用next查询,如果靠后,那就要用pre来进行查询:
那怎么判断是在前面还是在后面呢,很简单的,我们有size啊,判断index和size>>1(size的一半)的大小就可以了。
private Node<E> node(int index){
Node x=first;
if(index>size>>1) {
x=last;
for(int i=size-1;i>index;i--) {
x=x.pre;
}
}
else {
for(int i=0;i<index;i++) {
x=x.next;
}
}
return x;
}
因为这个方法不被外界调用,所以我们可以设置成私有的;
三、添加元素
我们先来考虑特殊的情况。
如果我们第一次添加元素的话,头节点的first和last应该都为空;
并且,记住啊,此时size=index=0.
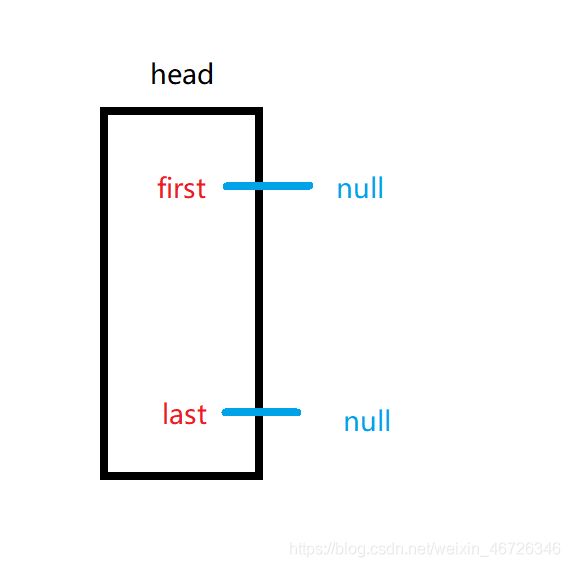
我现在新插入一个节点,是不是应该让firs和last都t指向新节点,并且新节点的next和pre都是空,因为只有自己一个节点啊。
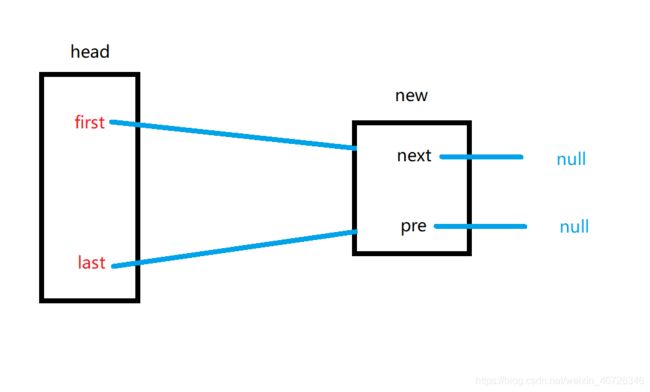
好记住这个逻辑,我们再看第二种情况,在尾部添加节点。
直接看上面这个图就行,我要在这个new节点后面再加一个,是不是new这个节点的next从null变成指向新节点,pre不变,first不变,但last是不是要指向新的节点,新节点的next要设置为空,新节点的pre要指向这个new。对吧,注意的是,此时的size=index=1,没毛病吧!
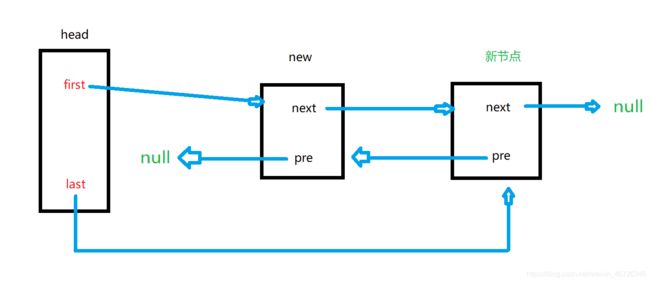
OK ,现在我们思考一个问题,除了这两种情况(无节点情况,在末尾添加节点),还有没有size=index的情况了,没有,很确定,没有了。那我是不是就可以把这两种情况综合为size==index的判断条件中呢?
if(index==size) {
Node l=last;
Node newNode=new Node(l,null,element);
last=newNode;
if(l==null) {
first=newNode;
}
else {
l.next=newNode;
}
}
我现在再把实现这个过程的代码拿出来,对照着这个图,是不是就可以理解了!l=null代表的就是没有节点的情况,仔细看看代码。
现在我们再来考虑index!=size的情况,看最开始的那张图:
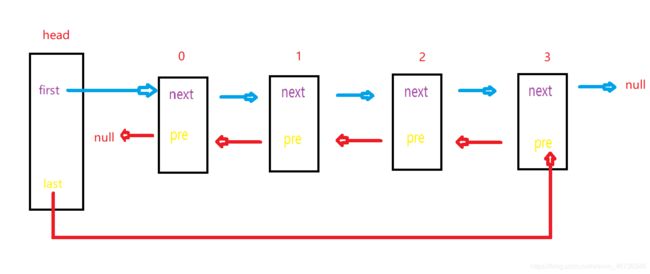
我如果想在1号位置添加节点,是不是就相当于是,在原来的0号节点和1号节点中间添加一个new节点,然后0的next指向new,1的pre指向new,new的next指向1,new的pre指向0;
有点绕,逻辑就是这样:
看一下图吧,我画的有点乱
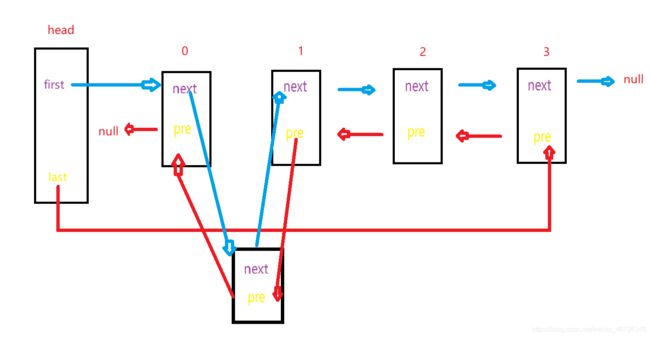
逻辑出来了,那就用代码来实现一下:
else {
Node node=node(index);
Node pre=node.pre;
Node newNode=new Node(pre,node,element);
node.pre=newNode;
if(pre==null) {
first=newNode;
}
else {
pre.next=newNode;
}
}
那,在代码里面,有一个值得注意的问题,就是我们判断了一下pre这个节点是不是空,代表了什么呢,如果pre是空,是不是就是说你要在0号节点添加元素,也就是在0号元素前面插上一个节点,那么我就让first指向new出来的节点不就行了嘛。
然后我们就来总的看一下这个方法:
public void add(int index,E element) {
if(index==size) {
Node l=last;
Node newNode=new Node(l,null,element);
last=newNode;
if(l==null) {
first=newNode;
}
else {
l.next=newNode;
}
}
else {
Node node=node(index);
Node pre=node.pre;
Node newNode=new Node(pre,node,element);
node.pre=newNode;
if(pre==null) {
first=newNode;
}
else {
pre.next=newNode;
}
}
size++;
}
然后add还有一个在末尾添加的方法,这里也不多说了,在上一篇文章有说过,直接看代码。
public void add(E element) {
add(size,element);
}
四、获取和修改方法
这和单链表的是一样的,也不说了:
public E get(int index) {
if(index<0||index>size) {
throw new IndexOutOfBoundsException("索引越界异常");
}
return node(index).element;
}
public E set(int index,E element) {
if(index<0||index>size) {
throw new IndexOutOfBoundsException("索引越界异常");
}
Node<E> node=node(index);
E oldElement=node.element;
node.element=element;
return oldElement;
}
五、toString方法
依旧是和单链表一样,这里也不说啦:
public String toString() {
StringBuilder str=new StringBuilder();
if(size==0) {
return "[]";
}
else {
str.append("[");
Node x=first;
for(Node i=x;i!=null;i=i.next) {
if(i.next==null) {
str.append(i.element).append("]");
}
else {
str.append(i.element).append(" ");
}
}
return str.toString();
}
}
奥,最后一个,删除节点,又是恶心的来了,来,奥利给!
六、删除节点
依旧是很恶心,我们还是分情况来看,首先呢,不管什么情况,你要删除某个节点的话,一定要获取到这个节点的前一个节点和后一个节点对吧;
Node <E>node=node(index);
Node pre=node.pre;
Node next=node.next;
然后我们说第一种另类情况,假如我们删除最后一个节点,也就是next=null的情况对吧;
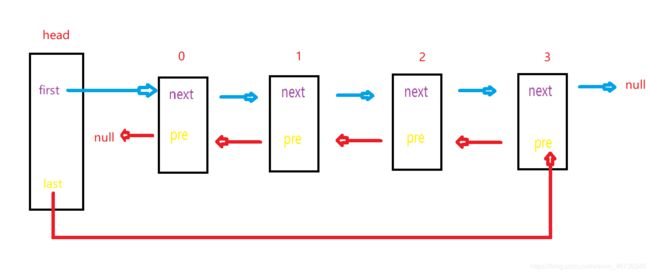
也就是删除3号节点,应该让2号节点的next为null,然后让last指向2号节点对吧;
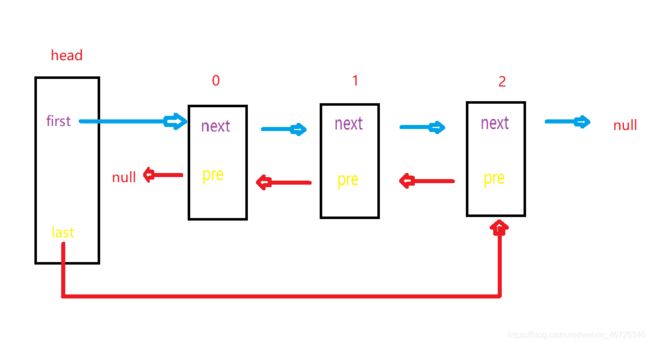
逻辑跟简单吧,好,现在我们记住这个逻辑,然后我们来看另一种情况,删除0号元素这种特殊情况。
如果我们想删除0号元素。
是不是应该让first指向1号元素,然后让1号元素的pre指向空。
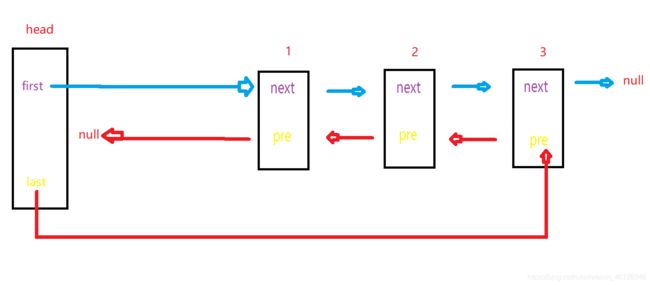
OK,这个逻辑也要记住,那现在要思考一个问题,我在删除0号元素有没有特殊的情况,否定了这种逻辑呢。那就往特殊的逻辑里面想啊。
如果我链表中只有一个节点,是不是逻辑就变了!
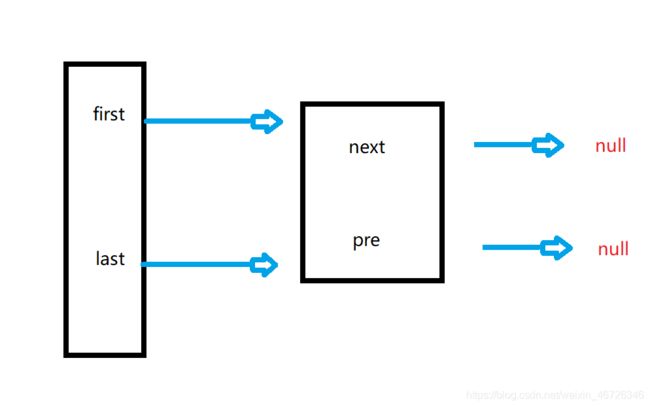
我现在要把这个节点删除掉的话,是不是要让first和last都指向空就完了,不需要指向其他的节点了,否则会发生空指针异常的!
所以光特殊的情况就有三种呢,现在来看一下最普通的情况:
我们要删除1号节点的话,是不是让0的next指向2,2的pre指向0,1号节点不就滚犊子了吗,对吧;
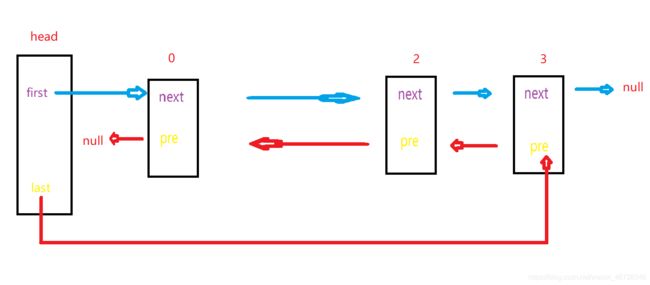
OKK,现在所有的逻辑已经说完了,我们就来看一下代码是怎么实现这个逻辑的!
public E remove(int index) {
if(index<0||index>size) {
throw new IndexOutOfBoundsException("索引越界异常");
}
Node <E>node=node(index);
Node pre=node.pre;
Node next=node.next;
if(pre==null) {
first=next;
if(next==null) {
last=null;
}
else {
next.pre=null;
}
}
else {
pre.next=next;
}
if(next==null) {
last=pre;
}
else {
next.pre=pre;
}
size--;
return node.element;
}
还是解释一下吧,直接自己看可能还是有点费劲,前三行是获取当前节点,还有前一个和后一个。然后判断pre是不是null,不就是判断删除的节点是不是0号节点吗。然后在这个判断中,又判断了next是不是null,不就是判断了链表中是否就有一个节点吗。然后下一个if语句中判断next是否为null,判断的不就是该节点是否为最后一个节点的情况吗。
然后就完事了,整个删除方法也就全写完了!
七、测试方法
public class Test {
public static void main(String[] args) {
DoubleList<Integer> list=new DoubleList();
list.add(1);
list.add(2);
list.add(3);
System.out.println(list);
list.add(0,2);
System.out.println(list);
list.set(0, 7);
System.out.println(list);
System.out.println(list.get(3));
list.remove(2);
System.out.println(list);
}
}
然后我们再看一下输出结果吧!
[1 2 3]
[2 1 2 3]
[7 1 2 3]
3
[7 1 3]
也是没有问题的啊。
OK ,这就是双向链表,完全是基于单向链表的一个优化,所以想学习双向链表,一定要知道单向链表的实现是如何做到的,再次分享一下链接:
https://blog.csdn.net/weixin_46726346/article/details/107687955
OK,分享结束。