【注】本文译自: [Saving Time with Structured Logging - Reflectoring](
https://reflectoring.io/struc...)
日志记录是调查事件和了解应用程序中发生的事情的终极资源。每个应用程序都有某种类型的日志。
然而,这些日志通常很混乱,分析它们需要付出很多努力。在本文中,我们将研究如何利用结构化日志来大大增加日志的价值。
我们将通过一些非常实用的技巧来提高应用程序日志数据的价值,并使用 Logz.io 作为日志平台来查询日志。
代码示例
本文附有 [GitHub 上](
https://github.com/thombergs/...)的工作代码示例。
什么是结构化日志?
“正常”日志是非结构化的。它们通常包含一个消息字符串:
2021-08-08 18:04:14.721 INFO 12402 --- [ main] i.r.s.StructuredLoggingApplication : Started StructuredLoggingApplication in 0.395 seconds (JVM running for 0.552)此消息包含我们在调查事件或分析问题时希望获得的所有信息:
- 日志事件的日期
- 创建日志事件的记录器的名称,以及
- 日志消息本身。
所有信息都在该日志消息中,但很难查询这些信息!由于所有信息都在一个字符串中,如果我们想从日志中获取特定信息,就必须解析和搜索这个字符串。
例如,如果我们只想查看特定记录器的日志,则日志服务器必须解析所有日志消息,检查它们是否具有识别记录器的特定模式,然后根据所需的记录器过滤日志消息。
结构化日志包含相同的信息,但采用结构化形式而不是非结构化字符串。通常,结构化日志以 JSON 格式呈现:
{
"timestamp": "2021-08-08 18:04:14.721",
"level": "INFO",
"logger": "io.reflectoring....StructuredLoggingApplication",
"thread": "main",
"message": "Started StructuredLoggingApplication ..."
}这种 JSON 结构允许日志服务器有效地存储,更重要的是检索日志。
例如,现在可以通过 timestamp 或 logger 轻松过滤日志,而且搜索比解析特定模式的字符串更有效。
但是结构化日志的价值并不止于此:我们可以根据需要向结构化日志事件中添加任何自定义字段! 我们可以添加上下文信息来帮助我们识别问题,或者我们可以向日志添加指标。
凭借我们现在触手可及的所有数据,我们可以创建强大的日志查询和仪表板,即使我们刚在半夜醒来调查事件,我们也能找到所需的信息。
现在让我们看几个用例,它们展示了结构化日志记录的强大功能。
为所有日志事件添加代码路径
我们首先要看的是代码路径。每个应用程序通常有几个不同的路径,传入请求可以通过应用程序。考虑这个图: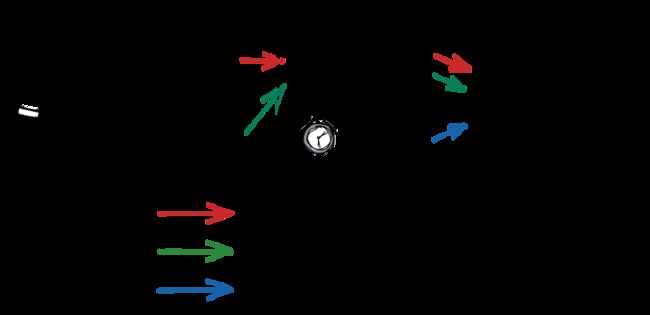
Java Spring Boot 项目中使用结构化日志节省时间
此示例具有(至少)三种不同的代码路径,传入请求可以采用这些路径:
- 用户代码路径:用户正在从他们的浏览器使用应用程序。浏览器向 Web 控制器发送请求,控制器调用领域代码。
- 第三方系统代码路径:应用程序的 HTTP API 也从第三方系统调用。在这个例子中,第三方系统调用与用户浏览器相同的 web 控制器。
- 计时器代码路径:与许多应用程序一样,此应用程序有一些由计时器触发的计划任务。
这些代码路径中的每一个都可以具有不同的特征。域服务涉及所有三个代码路径。在涉及域服务错误的事件期间,了解导致错误的代码路径将大有帮助!
如果我们不知道代码路径,我们很容易在事件调查期间做出毫无结果的猜测。
所以,我们应该将代码路径添加到日志中!以下是我们如何使用 Spring Boot 做到这一点。
为传入的 Web 请求添加代码路径
在 Java 中,SLF4J 日志库提供了 MDC 类(消息诊断上下文)。这个类允许我们向在同一线程中发出的所有日志事件添加自定义字段。
要为每个传入的 Web 请求添加自定义字段,我们需要构建一个拦截器,在每个请求的开头添加 codePath 字段,甚至在我们的 Web 控制器代码执行之前。
我们可以通过实现 HandlerInterceptor 接口来做到这一点:
public class LoggingInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)
throws Exception {
if (request.getHeader("X-CUSTOM-HEADER") != null) {
MDC.put("codePath", "3rdParty");
} else {
MDC.put("codePath", "user");
}
return true;
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler,
ModelAndView modelAndView) {
MDC.remove("codePath");
}
}在 preHandle() 方法中,我们调用 MDC.put() 将 codePath 字段添加到所有日志事件中。如果请求包含标识请求来自第三方方系统的标头,我们将代码路径设置为 3rdParty,否则,我们假设请求来自用户的浏览器。
根据应用的不同,这里的逻辑可能会有很大的不同,当然,这只是一个例子。
在 postHandle() 方法中,我们不应该忘记调用 MDC.remove() 再次删除所有先前设置的字段,否则线程仍会保留这些字段,即使它返回到线程池,以及下一个请求 由该线程提供服务的那些字段可能仍然设置为错误的值。
要激活拦截器,我们需要将其添加到 InterceptorRegistry 中:
@Componentpublic
class WebConfigurer implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new LoggingInterceptor());
}
}就是这样。在传入日志事件的线程中发出的所有日志事件现在都具有 codePath 字段。
如果任何请求创建并启动子线程,请确保在新线程生命周期开始时调用 MDC.put()。
在计划作业中添加代码路径
在 Spring Boot 中,我们可以通过使用 @Scheduled 和 @EnableScheduling 注解轻松创建计划作业。
要将代码路径添加到日志中,我们需要确保调用 MDC.put() 作为调度方法中的第一件事:
@Componentpublic
class Timer {
private final DomainService domainService;
private static final Logger logger = LoggerFactory.getLogger(Timer.class);
public Timer(DomainService domainService) {
this.domainService = domainService;
}
@Scheduled(fixedDelay = 5000)
void scheduledHello() {
MDC.put("codePath", "timer");
logger.info("log event from timer");
// do some actual work
MDC.remove("codePath");
}
}这样,从执行调度方法的线程发出的所有日志事件都将包含字段 codePath。我们也可以创建我们自己的 @Job 注解或类似的注解来为我们完成这项工作,但这超出了本文的范围。
为了使预定作业的日志更有价值,我们可以添加其他字段:
job_status:指示作业是否成功的状态。job_id:已执行作业的 ID。job_records_processed:如果作业进行一些批处理,它可以记录处理的记录数。- ......
通过日志中的这些字段,我们可以在日志服务器获取到很多有用的信息!
将用户 ID 添加到用户启动的日志事件
典型 Web 应用程序中的大部分工作是在来自用户浏览器的 Web 请求中完成的,这些请求会触发应用程序中的线程,为浏览器创建响应。
想象一下发生了一些错误,日志中的堆栈跟踪显示它与特定的用户配置有关。但是我们不知道请求来自哪个用户!
为了缓解这种情况,在用户触发的所有日志事件中包含某种用户 ID 是非常有帮助的。
由于我们知道传入的 Web 请求大多直接来自用户的浏览器,因此我们可以在创建的同一个 LoggingInterceptor 中添加 username 字段以添加 codePath 字段:
public class LoggingInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)
throws Exception {
Object principal = SecurityContextHolder.getContext().getAuthentication().getPrincipal();
if (principal instanceof UserDetails) {
String username = ((UserDetails) principal).getUsername();
MDC.put("username", username);
} else {
String username = principal.toString();
MDC.put("username", username);
}
return true;
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler,
ModelAndView modelAndView) {
MDC.remove("username");
}
}这段代码假设我们使用 Spring Security 来管理对 Web 应用程序的访问。我们使用 SecurityContextHolder 来获取 Principal 并从中提取用户名以将其传递给 MDC.put()。
从服务请求的线程发出的每个日志事件现在都将包含用户名字段和用户名。
有了这个字段,我们现在可以过滤特定用户请求的日志。如果用户报告了问题,我们可以根据他们的姓名过滤日志,并极大地减少我们必须查看的日志。
根据规定,您可能希望记录更不透明的用户 ID 而不是用户名。
为错误日志事件添加根本原因
当我们的应用程序出现错误时,我们通常会记录堆栈跟踪。堆栈跟踪帮助我们确定错误的根本原因。如果没有堆栈跟踪,我们将不知道是哪个代码导致了错误!
但是,如果我们想在应用程序中运行错误统计信息,堆栈跟踪是非常笨拙的。假设我们想知道我们的应用程序每天总共记录了多少错误,以及其中有多少是由哪个根本原因异常引起的。我们必须从日志中导出所有堆栈跟踪,并对它们进行一些手动过滤,才能得到该问题的答案!
但是,如果我们将自定义字段 rootCause 添加到每个错误日志事件,我们可以通过该字段过滤日志事件,然后在日志服务器的 UI 中创建不同根本原因的直方图或饼图,甚至无需导出数据。
在 Spring Boot 中执行此操作的一种方法是创建一个 @ExceptionHandle:
@ControllerAdvicepublic
class WebExceptionHandler {
private static final Logger logger = LoggerFactory.getLogger(WebExceptionHandler.class);
@ExceptionHandler(Exception.class)
@ResponseStatus(HttpStatus.INTERNAL_SERVER_ERROR)
public void internalServerError(Exception e) {
MDC.put("rootCause", getRootCause(e).getClass().getName());
logger.error("returning 500 (internal server error).", e);
MDC.remove("rootCause");
}
private Throwable getRootCause(Exception e) {
Throwable rootCause = e;
while (e.getCause() != null && rootCause.getCause() != rootCause) {
rootCause = e.getCause();
}
return rootCause;
}
}我们创建了一个用 @ControllerAdvice 注解的类,这意味着它在我们所有的 web 控制器中都是有效的。
在类中,我们创建了一个用 @ExceptionHandler 注解的方法。对于任何 Web 控制器中出现的异常,都会调用此方法。它将 rootCause MDC 字段设置为导致错误的异常类的完全限定名称,然后记录异常的堆栈跟踪。
就是这样。所有打印堆栈跟踪的日志事件现在都有一个字段 rootCause,我们可以通过这个字段进行过滤以了解我们应用程序中的错误分布。
向所有日志事件添加跟踪 ID
如果我们运行多个服务,例如在微服务环境中,分析错误时事情会很快变得复杂。一个服务调用另一个服务,另一个服务调用再一个服务,并且很难(如果可能的话)跟踪一个服务中的错误到另一个服务中的错误。
跟踪 ID 有助于连接一个服务中的日志事件和另一个服务中的日志事件:
在上面的示例图中,服务 1 被调用并生成跟踪 ID“1234”。然后它调用服务 2 和 3,将相同的跟踪 ID 传播给它们,以便它们可以将相同的跟踪 ID 添加到其日志事件中,从而可以通过搜索特定的跟踪 ID 来连接所有服务的日志事件。
对于每个传出请求,服务 1 还会创建一个唯一的“跨度 ID”。虽然跟踪跨越服务 1 的整个请求/响应周期,但跨度仅跨越一个服务和另一个服务之间的请求/响应周期。
我们可以自己实现这样的跟踪机制,但是有一些跟踪标准和工具可以使用这些标准集成到跟踪系统中,例如 Logz.io 的分布式跟踪功能。
我们还是使用标准工具吧。在 Spring Boot 世界中,这就是 Spring Cloud Sleuth,我们可以通过简单地将它添加到我们的 pom.xml,从而把该功能集成到我们的应用程序中:
org.springframework.cloud
spring-cloud-dependencies
2020.0.3
pom
import
org.springframework.cloud
spring-cloud-starter-sleuth
这会自动将跟踪和跨度 ID 添加到我们的日志中,并在使用支持的 HTTP 客户端时通过请求标头将它们从一个服务传播到下一个服务。您可以在“使用 Spring Cloud Sleuth 在分布式系统中进行跟踪”一文中阅读有关 Spring Cloud Sleuth 的更多信息。
添加某些代码路径的持续时间
我们的应用程序响应请求所需的总持续时间是一个重要的指标。如果速度太慢,用户会感到沮丧。
通常,将请求持续时间作为指标公开并创建显示请求持续时间的直方图和百分位数的仪表板是一个好主意,这样我们就可以一目了然地了解应用程序的健康状况,甚至可能在违反某个阈值时收到警报。
然而,我们并不是一直在查看仪表板,我们可能不仅对总请求持续时间感兴趣,而且对某些代码路径的持续时间感兴趣。在分析日志以调查问题时,了解代码中特定路径执行所需的时间可能是一个重要线索。
在 Java 中,我们可能会这样做:
void callThirdPartyService() throws InterruptedException {
logger.info("log event from the domain service");
Instant start=Instant.now();
Thread.sleep(2000); // simulating an expensive operation
Duration duration=Duration.between(start,Instant.now());
MDC.put("thirdPartyCallDuration",String.valueOf(duration.getNano()));
logger.info("call to third-party service successful!");
MDC.remove("thirdPartyCallDuration");
}假设我们正在调用第三方服务并希望将持续时间添加到日志中。使用 Instant.now() 和 Duration.between(),我们计算持续时间,将其添加到 MDC,然后创建日志事件。
这个日志事件现在将包含字段 thirdPartyCallDuration,我们可以在日志中过滤和搜索该字段。 例如,我们可能会搜索这个调用耗时过长的实例。 然后,我们可以使用用户 ID 或跟踪 ID,当这需要特别长的时间时,我们也可以将它们作为日志事件的字段来找出模式。
在Logz.io中查询结构化日志
如果我们按照关于 per-environment logging 的文章中的描述设置了日志记录到 Logz.io,我们现在可以在 Logz.io 提供的 Kibana UI 中查询日志。
错误分布
例如,我们可以查询在 rootCause 字段中具有值的所有日志事件:
__exists__: "rootCause"这将显示具有根本原因的错误事件列表。
我们还可以在 Logz.io UI 中创建一个可视化来显示给定时间范围内的错误分布: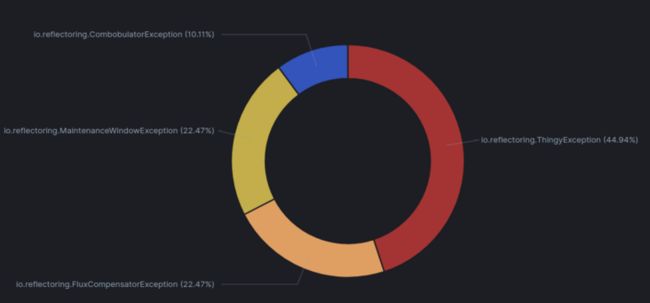
此图表显示几乎一半的错误是由 ThingyException 引起的,因此检查是否可以以某种方式避免此异常可能是个好主意。如果无法避免,我们应该将其记录在 WARN 而不是 ERROR 上,以保持错误日志的清洁。
跨代码路径的错误分布
例如,假设用户抱怨预定的作业没有正常工作。如果我们在调度方法代码中添加了一个 job_status 字段,我们可以通过那些失败的作业来过滤日志:
job_status: "ERROR"为了获得更高级的视图,我们可以创建另一个饼图可视化,显示 job_status 和 rootCause 的分布: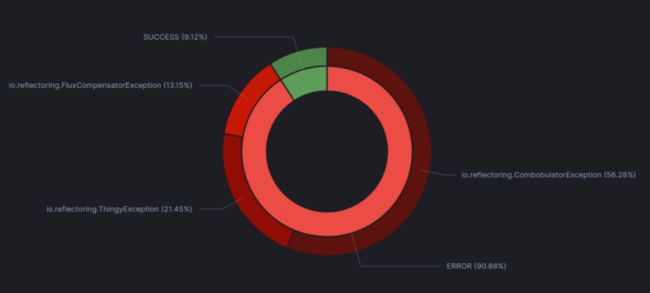
我们现在可以看到大部分预定的作业都失败了!我们应该为此添加一些警报! 我们还可以查看哪些异常是大多数计划作业的根本原因并开始调查。
检查用户的错误
或者,假设用户名为 “user” 的用户提出了一个支持请求,指定了它发生的大致日期和时间。我们可以使用查询 username: user 过滤日志以仅显示该用户的日志,并且可以快速将用户问题的原因归零。
我们还可以扩展查询以仅显示具有 rootCause 的该用户的日志事件,以直接了解何时出了什么问题。
username: "user" AND _exists_: "rootCause"结构化您的日志
本文仅展示了几个示例,说明我们如何向日志事件添加结构并在查询日志时使用该结构。以后可以在日志中搜索的任何内容都应该是日志事件中的自定义字段。添加到日志事件中的字段在很大程度上取决于我们正在构建的应用程序,所以在编写代码时,一定要考虑哪些信息可以帮助您分析日志。
您可以在 [GitHub 上](
https://github.com/thombergs/...)找到本文中讨论的代码示例。