数据分析初级操作学习【预处理、集中与离散分析、相关分析】
数据分析初级学习
大家好!我是未来村村长!就是那个“请你跟我这样做,我就跟你那样做!”的村长!
上次发布了[Pandas库的使用教程,每个程序都配图,两万字保姆教学轻松学会],接着上次的教程,和我进一步拓展数据分析之路!
一、数据预处理
1、数据去重
十分简单,只需要调用**duplicated()**函数就可以知道哪行数据出现了重复。
调用**drop_duplicates()**即可直接删除重复行。
df = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息3.csv',header=0,names=['店铺名称','评论分数','评论人数','人均价格','口味','环境','服务'])
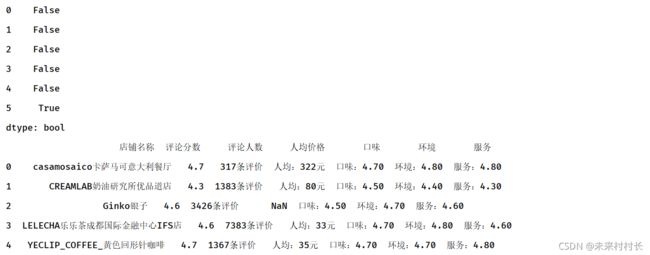
print(df.duplicated())
df2 = df.drop_duplicates()
print(df2)
2、数据清理
① 缺失值处理
三个相关操作
| 函数 | 说明 |
|---|---|
| dropna() | 删去含有丢失数据行或列 |
| fillna() | 填充缺失数据 |
| isnull/notnull | 检查是否含有缺失数据 |
dropna()
df.dropna(axis=0,how=‘any’ ,subset=None,inplace=False)
| 参数 | 简介 |
|---|---|
| axis | 数据删除维度 |
| how | any:删除带有Nan的行;all:删除全为Nan的行 |
| subset | 删除指定列空值数据 |
| inplace | 是否用新生成的列表替换原列表 |
#删除指定列含有空值的行
df.dropna(how='any',subset=['服务'],inplace=True)
#删除带有空值的行
df.dropna(how='any',inplace=True)
#删除全为空值的列
df.dropna(axis='columns',how='all',inplace=True)
fillna()
method : {‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}, default None
-
pad/ffill:用前一个非缺失值去填充该缺失值
-
backfill/bfill:用下一个非缺失值填充该缺失值
-
None:指定一个值去替换缺失值
方法一:全部填写为同一特定值
df.fillna(value=10
,method=None
,axis=None
,inplace=False)
#均值
df.fillna(value=df.mean())
#中位数
df.fillna(value=df.median())
#最值
df.fillna(value=df.max())
df.fillna(value=df.min())
方法二:按列填写不同特定值
values = {
'A':11,'B':22,'C':33,'D':44}
df.fillna(value=values
,method=None
,axis=None
,inplace=False)
#或写为
df.fillna({
'A':11,'B':22,'C':33,'D':44})
方法三:‘ffill’ 填充或bfill填充
df.fillna(method='ffill'
,axis=None
,inplace=False)
统计缺失值占比
# 计算data每一行有多少个缺失值的值,即按行统计缺失值
rows_null = df.isnull().sum(axis=1)
# 下面则是按列统计缺失值
col_null = df.isnull().sum(axis=0)
# 统计整个df的缺失值
all_null = df.isnull().sum().sum()
# 统计某一列的缺失值
idx_null = df['人均价格'].isnull().sum(axis=0)
# 统计缺失占比
null_rate = df.isnull().sum(axis=0).sum()/df['店铺名称'].size

② 数据行列的删除
有时候我们得到的数据有一些无关紧要或者我们不关系的数据,我们可以直接删除。
行的删除
方法一:使用index参数 []内是索引名,不是序号,要注意!
df.drop(index=[0,1],inplace=False)
方法二:使用labels和axis参数
df.drop(labels=[0,1],axis=0,inplace=False)
列的删除
方法一:使用columns参数
df.drop(columns=['A','B'],inplace=False)
方法二:使用labels和axis参数
df.drop(labels=['A','B'],axis=1,inplace=False)
3、变量操作
① 修改变量名
rename(index,columns,inplace)
df.rename(index={
0:'第一家',1:'第二家'},columns={
"店铺名称":'店铺名'},inplace=True)
② 根据条件创建变量
df[‘属性1’] = np.where(df[‘属性2’]运算符和变量,‘符合变量’,‘不符合变量’)
df['是否超出我的消费水平'] = np.where(df['人均价格']>50,'贵死了','还可以')

③ 创建哑变量
df.join(pd.get_dummies(df[类别属性’]))
函数介绍
join(self, other, on=None, how=“left”, lsuffix="", rsuffix="", sort=False)
- other:DataFrame, Series, or list of DataFrame,另外一个dataframe, series,或者dataframe list。
- on: 参与join的列,与sql中的on参数类似。如果两个表中行索引和列索引重叠,那么当使用join()方法进行合并时,使用参数on指定重叠的列名即可
- how: {‘left’, ‘right’, ‘outer’, ‘inner’}, default ‘left’, 与sql中的join方式类似
- lsuffix: 左DataFrame中重复列的后缀
- rsuffix: 右DataFrame中重复列的后缀
- sort: 按字典序对结果在连接键上排序
get_dummies(data, prefix=None, prefix_sep=’_’, dummy_na=False, columns=None, sparse=False, drop_first=False, dtype=None)
- data: DataFrame或Series对象
- prefix: 编码后特征名称的前缀
- prefix_sep: 编码后特征名称的前缀,默认使用“_”进行分隔
实例
df2 = df.join(pd.get_dummies(df['地点'],prefix_sep="DD"))

离散化装箱
pd.cut(df[],ndarray)
df2 = df.join(pd.get_dummies(pd.cut(df['人均价格'],[50,100,300]),prefix="价格"))

pd.cut(df[‘属性’],bins=[],labels=[‘对应箱名1’,‘对应箱名2’,‘对应箱名3’])
cut将根据值本身来选择箱子均匀间隔,即每个箱子的间距都是相同的
qcut是根据这些值的频率来选择箱子的均匀间隔,即每个箱子中含有的数的数量是相同的
④ 删除变量
| 函数 | 说明 |
|---|---|
| del | del直接影响原DataFrame |
| pop | pop函数返回被删除的数据 |
| drop | drop可以制定多列删除 |
del df['属性名']
df.pop('属性名')
df.drop(['属性名1','属性名2'],axis='columns')
⑤ 选择变量
df2 = df1['属性名1']
df2 = df1[['属性名1','属性名2']]
注意这里是[[]],即多个属性要使用两个双括号
4、样本选择
① 利用索引选择
#前五行
df[:5]
#中间制定行数
df[5:10]
② 利用条件选择
df[df['属性名']运算式子]
③ 随机抽样选择
df.sample(n=行数,replace=False)
#随机抽取df中的5行,无放回
df.sample(n=5)
#有放回
df.sample(n=5,replace=True)
5、数据集操作
一般纵向拼接使用concat,横向拼接使用merge较合适。
① merge
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)
- left: 拼接的左侧DataFrame对象
- right: 拼接的右侧DataFrame对象
- on: 要加入的列或索引级别名称。 必须在左侧和右侧DataFrame对象中找到。 如果未传递且left_index和right_index为False,则DataFrame中的列的交集将被推断为连接键。
- how: One of ‘left’, ‘right’, ‘outer’, ‘inner’. 默认inner。inner是取交集,outer取并集。比如left:[‘A’,‘B’,‘C’];right[’'A,‘C’,‘D’];inner取交集的话,left中出现的A会和right中出现的买一个A进行匹配拼接,如果没有是B,在right中没有匹配到,则会丢失。'outer’取并集,出现的A会进行一一匹配,没有同时出现的会将缺失的部分添加缺失值。
df = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息3.csv',header=0,names=['店铺名称','评论分数','评论人数','人均价格','口味','环境','服务'])
df2 = pd.DataFrame({
"地点":['贵州','上海','重庆','武汉','上海']})
df3 = df2.join(df['店铺名称'])
print(df3)
df4 = pd.merge(df,df3,on='店铺名称')
print(df4)

② concat
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False,
copy=True
objs:Series,DataFrame或Panel对象的序列或映射。如果传递了dict,则排序的键将用作键参数,除非它被传递,在这种情况下,将选择值(见下文)。任何无对象将被静默删除,除非它们都是无,在这种情况下将引发一个ValueError。axis:默认为0,纵向合并,若定义1,则为横向合并join:{‘inner’,‘outer’},默认为“outer”。如何处理其他轴上的索引。outer为并集和inner为交集。ignore_index:boolean,default False。如果为True,请不要使用并置轴上的索引值。结果轴将被标记为0,…,n-1。如果要连接其中并置轴没有有意义的索引信息的对象,这将非常有用。注意,其他轴上的索引值在连接中仍然受到尊重。join_axes:Index对象列表。用于其他n-1轴的特定索引,而不是执行内部/外部设置逻辑。keys:序列,默认值无。使用传递的键作为最外层构建层次索引。如果为多索引,应该使用元组。levels:序列列表,默认值无。用于构建MultiIndex的特定级别(唯一值)。否则,它们将从键推断。names:list,default无。结果层次索引中的级别的名称。verify_integrity:boolean,default False。检查新连接的轴是否包含重复项。这相对于实际的数据串联可能是非常昂贵的。copy:boolean,default True。如果为False,请勿不必要地复制数据。
df = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息3.csv',header=0,names=['店铺名称','评论分数','评论人数','人均价格','口味','环境','服务'])
df2 = pd.DataFrame({
"地点":['贵州','上海','重庆','武汉','上海']})
df3 = df2.join(df['店铺名称'])
df4 = pd.concat([df,df3],axis=1)
print(df4)

df = pd.read_csv(r'C:\Users\官二的磊子\Desktop\总体信息3.csv',header=0,names=['店铺名称','评论分数','评论人数','人均价格','口味','环境','服务'])
df2 = pd.DataFrame({
"地点":['贵州','上海','重庆','武汉','上海']})
df3 = df2.join(df['店铺名称'])
df4 = pd.concat([df,df3],axis=0,join='outer',ignore_index=True)
print(df4)

df4 = pd.concat([df,df3],axis=0,join=‘outer’,ignore_index=True)
二、数据分析初级
describe() #数据描述函数
#数值类型强制转换
df[['评论分数','评论人数','人均价格','口味','环境','服务']]=df[['评论分数','评论人数','人均价格','口味','环境','服务']].astype('float64')
#---
print(df.describe())

1、集中趋势
计算集中趋势时,不建议直接对表格进行操作,因为含有不能取到的字段。
① 算术平均数
df.mean()
② 中位数
df.median()
③ 分位数
df.describe()
25%,50%,75%分别表示第一个四分位数、第二个四分位数、第三个四分位数
④ 众数
df['属性名'].mode()
⑤ 几何平均数
几何平均数是n个变量值连乘积的n次方根
from scipy import stats
stats.gmean(df)
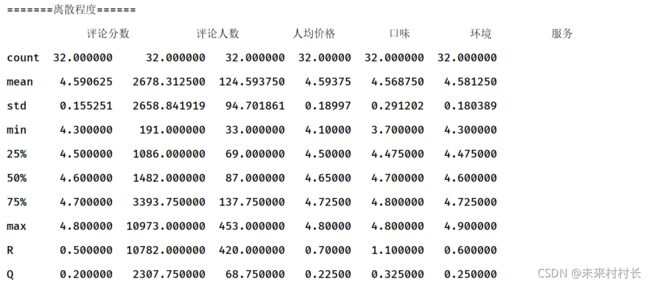
2、离散程度
① 极差与四分位差
极差是描述离散程度最简单的测量值,只能说明两个极端变量值的差异范围,不能反映各个单位变量值的变异程度,易受极端数值的影响。
四分位差反映中间50%数据的离散程度,其数值越小,说明中间的数据越集中;数值越大,说明中间的数据越分散。
stat = df.describe()
stat.loc['R'] = stat.loc['max'] - stat.loc['min']
stat.loc['Q'] = stat.loc['75%'] - stat.loc['25%']
print(stat)
loc[var],这里默认取的是行,若取列则为loc[:,var]
③ 平均离差
平均差也称平均离差,是各变量与其平均数之差的绝对值之和的平均数。
一般平均差的数值越大,其平均数的代表性越小,说明该组变量值分布越分散;反之,平均差的数值越小,其平均数的代表性越大,说明该组变量值分布越集中。
df..mad()
#df.loc[:,:].mad()
④ 标准差与方差
标准差又称均方差,是各样本变量与其平均数之差的平方的平均数的方根。
标准差的本质是求各变量与其平均数的距离和,即先求出各变量值与其平均数离差的平方,再求其平均数,最后开方。
再正态分布条件下,它和平均数有明确的数量关系,是真正度量离散趋势的标准。
df.std()
#df.loc[:,:].std()
方差是各变量值与其算术平均数之差的平方和的平均数,即标准差的平方
df.var()
⑥ 离散系数
必将两个样本集的离散程度时,若度量单位或平均数不同,就不能用标准差来比较,要用离散系数比较,即标准差与平均数的比值。
stat = df.describe()
stat.loc['V'] = stat.loc['std']/stat.loc['mean']
print(stat)

3、分布状态
① 分布的偏态[偏态系数]
利用众数、中位数、平均数之间的关系可以判断数据的分布是对称、左偏还是右偏。但要测量偏斜程度则需要计算偏态系数。
当偏态系数为正数,表示正偏离差值较大,可判断为正偏或右偏。当偏态系数为负数,表示负偏离差值较大,可判断为负偏或左偏。偏态系数越接近0,则偏斜度越小,偏态系数越接近±3,则偏斜度越大。
df.skew()

② 分布的峰度[峰度系数]
峰度是分布集中趋势高峰的形状,再变量的分布特征中,常以正态分布为标准,观察变量分布曲线顶峰的尖平程度。
若分布形状比正态分布更高更瘦,则为尖峰分布。若分布形状比正态分布更矮更胖,则为平峰分布。
若峰度系数大于0,则为尖峰分布;若峰度系数小于0,则为平顶分布。
df.kurt()

4、相关分析
相关分析即对两个变量的因果关系分析,查看两者是否有关联。确定变量之间的相关关系,一般可以通过图形观测和指标度量来确定相关关系。图形观测方法可以通过变量之间的散点图来进行分析确定,指标度量观测是通过计算相关系数来确定。
① 散点图
import matplotlib.pyplot as plt
plt.scatter(df['人均价格'],df['评论分数'])
plt.xlabel('人均价格')
plt.ylabel('评论分数')
plt.show()

可以看出:其实不太好看出。
② 相关系数
print(df.loc[:,['评论分数','评论人数','人均价格','口味','环境','服务']].corr())

可绘制关系矩阵图
import seaborn as sns
df.rename(columns={
'评论分数':'Score','评论人数':'P_number','人均价格':'Price','口味':'Taste','环境':'Environ','服务':'Server'},inplace=True)
corr = df.loc[:,['Score','P_number','Price','Taste','Environ','Server']].corr()
sns.heatmap(corr,linewidths=0.1,vmax=1.0, square=True,linecolor='white', annot=True)
plt.show()

Seaborn 是以 matplotlib为底层,更容易定制化作图的Python库。
Seaborn 其实是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易。
在大多数情况下使用Seaborn就能做出很具有吸引力的图,而使用matplotlib就能制作具有更多特色的图,换句话说,matplotlib更加灵活,可定制化,而seaborn像是更高级的封装,使用方便快捷。
经验:这里需要将字体改为英文否则会报错,所以最好拿到数据,我们就将其属性名命名为英文。