机器学习之linear regression(线性回归)
线性回归
前言
我们需要了解分类算法解决的目标值是离散的问题;而回归算法解决的是目标值连续的问题
什么是线性回归?
定义:线性回归通过一个或者多个自变量与因变量之间之间进行建模的回归分析。其中特点为一个或多个称为回归系数的模型参数的线性组合。
一元线性回归:涉及到的变量只有一个
多元线性回归:涉及到的变量两个或两个以上
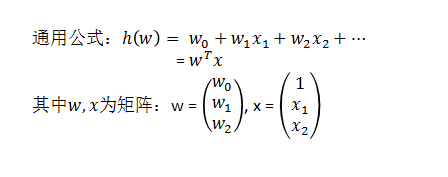
注:线性回归需要进行标准化,避免单个权重过大,影响最终结果
举例

单个特征:
- 试图去寻找一个k,b值满足:
- 房子价格 = 房子面积*k+b(b为偏置,为了对于单个特征的情况更多通用)

多个特征:(房子面积、房子位置,…)
- 试图去寻找一个k1,k2,…,b值满足:
- 房子价格 = 房子面积*k1 + 房子位置 *k2 +…+b
线性关系模型
试图找到一种属性和权重的组合来进行预测结果:

但是预测值总是会存在误差,所以需要利用损失函数计算误差
损失函数(最小二乘法)

如何去求模型当中的W(权重),使得损失最小? (目的是找到最小损失对应的W值)
优化
最小二乘法之正规方程(不太推荐)
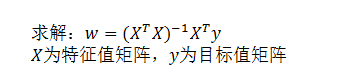
缺点:
- 当特征过于复杂,求解速度太慢
- 对于复杂的算法,不能使用正规方程求解(逻辑回归等)
损失函数直观图(单变量举例),如下:
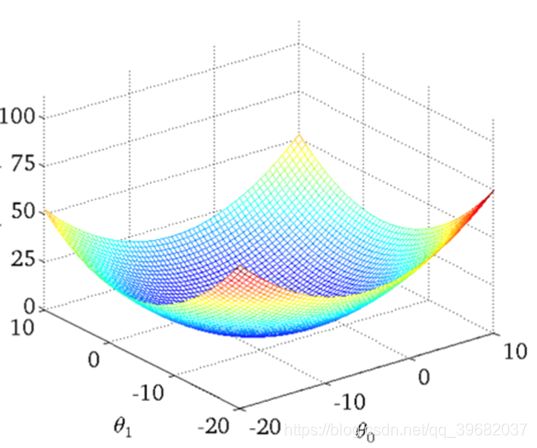
最小二乘法之梯度下降(❤️ ❤️ ❤️ )

理解:沿着这个函数下降的方向找,最后就能找到函数的最低点,然后更新W值。(不断迭代的过程)

知识储备
sklearn线性回归正规方程API
- sklearn.linear_model.LinearRegression()
coef_:回归系数
sklearn线性回归梯度下降API
- sklearn.linear_model.SGDRegressor()
coef_:回归系数
代码演示
正规方程案例
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression,SGDRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
def mylinear():
'''
线性回归预测房价
:return: None
'''
# 加载数据
lb = load_boston()
# 分割数据集到训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.25)
print(y_train,y_test)
# 进行标准化处理
# 特征值和目标值都需要进行标准化处理
# 扫描器要求的是二维数据类型,需要利用reshape
std_x = StandardScaler()
# 特征值
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
#目标值
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train.reshape(-1,1))
y_test = std_y.transform(y_test.reshape(-1,1))
# estimator预测
# 正规方程求解方程预测结果
lr = LinearRegression()
lr.fit(x_train,y_train)
print(lr.coef_)
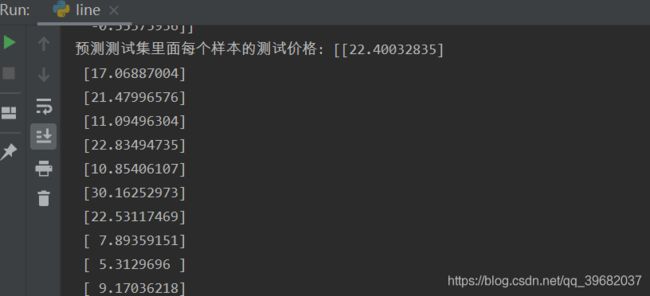
# 预测测试集的房价
y_predict = std_y.inverse_transform(lr.predict(x_test))
print("预测测试集里面每个样本的测试价格:",y_predict)
return None
if __name__ == "__main__":
mylinear()
梯度下降
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression,SGDRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
def mylinear():
'''
线性回归预测房价
:return: None
'''
# 加载数据
lb = load_boston()
# 分割数据集到训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.25)
print(y_train,y_test)
# 进行标准化处理
# 特征值和目标值都需要进行标准化处理
# 扫描器要求的是二维数据类型,需要利用reshape
std_x = StandardScaler()
# 特征值
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
#目标值
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train.reshape(-1,1))
y_test = std_y.transform(y_test.reshape(-1,1))
# estimator预测
# 正规方程求解方程预测结果
lr = LinearRegression()
lr.fit(x_train,y_train)
print(lr.coef_)
# 预测测试集的房价
y_lr_predict = std_y.inverse_transform(lr.predict(x_test))
print("正规方程预测测试集里面每个样本的测试价格:",y_lr_predict)
# 梯度下降进行房价预测
# 学习率参数 learning_rate 默认 learning_rate = invscaling
'''
learning_rate : string, default='invscaling'
The learning rate schedule:
'constant':
eta = eta0
'optimal':
eta = 1.0 / (alpha * (t + t0))
where t0 is chosen by a heuristic proposed by Leon Bottou.
'invscaling': [default]
eta = eta0 / pow(t, power_t)
'adaptive':
eta = eta0, as long as the training keeps decreasing.
Each time n_iter_no_change consecutive epochs fail to decrease the
training loss by tol or fail to increase validation score by tol if
early_stopping is True, the current learning rate is divided by 5.
'''
sgd = SGDRegressor()
sgd.fit(x_train, y_train)
print(sgd.coef_)
# 预测测试集的房价
y_sgd_predict = std_y.inverse_transform(sgd.predict(x_test))
print("梯度下降预测测试集里面每个样本的测试价格:",y_sgd_predict)
return None
if __name__ == "__main__":
mylinear()
回归性能评估

均方误差回归损失
mean_squared_error(y_true, y_pred)
- y_true:真实值
- y_pred:预测值
- return:浮点数结果
注:真实值,预测值为标准化之前的值
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression,SGDRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
def mylinear():
'''
线性回归预测房价
:return: None
'''
# 加载数据
lb = load_boston()
# 分割数据集到训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.25)
print(y_train,y_test)
# 进行标准化处理
# 特征值和目标值都需要进行标准化处理
# 扫描器要求的是二维数据类型,需要利用reshape
std_x = StandardScaler()
# 特征值
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
#目标值
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train.reshape(-1,1))
y_test = std_y.transform(y_test.reshape(-1,1))
# estimator预测
# 正规方程求解方程预测结果
lr = LinearRegression()
lr.fit(x_train,y_train)
print(lr.coef_)
# 预测测试集的房价
y_lr_predict = std_y.inverse_transform(lr.predict(x_test))
#print("正规方程预测测试集里面每个样本的测试价格:",y_lr_predict)
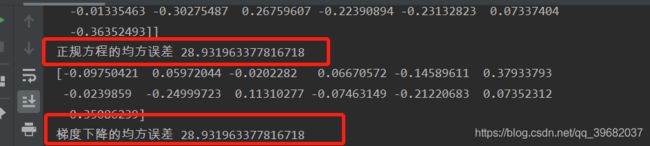
print("正规方程的均方误差",mean_squared_error(std_y.inverse_transform(y_test),y_lr_predict))
# 梯度下降进行房价预测
# 学习率参数 learning_rate 默认 learning_rate = invscaling
'''
learning_rate : string, default='invscaling'
The learning rate schedule:
'constant':
eta = eta0
'optimal':
eta = 1.0 / (alpha * (t + t0))
where t0 is chosen by a heuristic proposed by Leon Bottou.
'invscaling': [default]
eta = eta0 / pow(t, power_t)
'adaptive':
eta = eta0, as long as the training keeps decreasing.
Each time n_iter_no_change consecutive epochs fail to decrease the
training loss by tol or fail to increase validation score by tol if
early_stopping is True, the current learning rate is divided by 5.
'''
sgd = SGDRegressor()
sgd.fit(x_train, y_train)
print(sgd.coef_)
# 预测测试集的房价
y_sgd_predict = std_y.inverse_transform(sgd.predict(x_test))
#print("梯度下降预测测试集里面每个样本的测试价格:",y_sgd_predict)
print("梯度下降的均方误差",mean_squared_error(std_y.inverse_transform(y_test),y_lr_predict))
return None
if __name__ == "__main__":
mylinear()
总结

特点:线性回归器是最为简单、易用的回归模型。
从某种程度上限制了使用,尽管如此,在不知道特征之间关系的前提下,我们仍然使用线性回归器作为大多数系统的首要选择。
小规模数据:LinearRegression(不能解决拟合问题)以及其它
大规模数据:SGDRegressor