python爬取B站视频2.0
参考文章
爬取B站视频 - m4s文件的相关研究
Python实现B站MP4格式音频与视频的合并!超详细的教程!
环境
win10+requests+chrome浏览器
唠嗑
初衷是为了下载B站微信8.0状态视频,B站是将视频和音频分开的,需要自己进行合并,方法就是Python实现B站MP4格式音频与视频的合并!超详细的教程!
开始讲解
之前第一次的B站爬取视频教学,当时视频格式是flv,可以直接请求下载
这次视频格式换成了m4s这种片段,一个视频由许多的m4s小块组成,将所有的m4s小块拼接出来肯定就是完整的视频
分析
先随便找到一个B站视频主页,然后开启开发者模式,然后刷新一下,选中xhr类型和筛选m4s,可以得到下列类似情况
这些肯定是请求的视频或音频片段.
我们尝试直接请求,发现返回403,这显然是因为我们的请求头不对,不然肯定会返回

观察请求头
这是一个get,参数有一大堆,先不用管
主要是请求头有个range参数,表示请求的数据范围,在爬取B站视频 - m4s文件的相关研究方法中是改成另一个形式,但是现在直接去掉这个参数就是请求完整的视频或音频
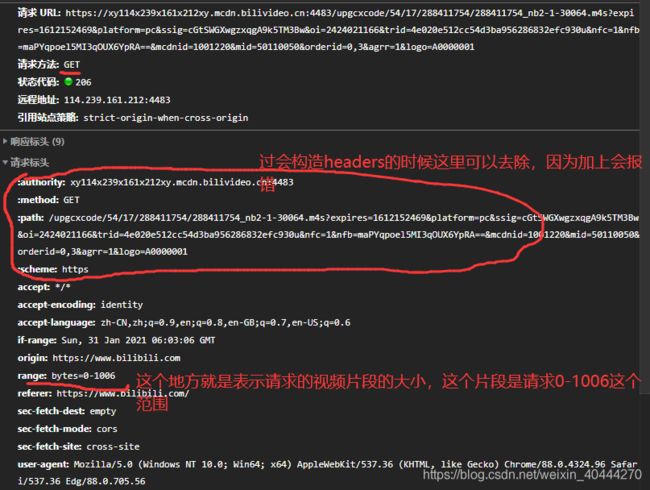
构造请求头
这里面其实很多参数也是可以去除的,我暂时没有去试验。
headers = {
'scheme': 'https',
'accept': '*/*',
'accept-encoding': 'identity',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'if-range': "lm-vGohi8aMA0bE4dtHLYBU9m_vs",
'origin': 'https://www.bilibili.com',
'referer': 'https://www.bilibili.com/',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'cross-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36 Edg/88.0.705.53',
}
试验是否成功
这个链接可能会失效,因为时间变成,get的参数会过期,大家自己找一个新的链接,从第一个图上请求的链接中复制一条尝试一下
应该是可以成功下载一个视频或音频
url = 'https://cn-cq-gd-bcache-25.bilivideo.com/upgcxcode/82/00/288510082/288510082-1-30066.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1612111185&gen=playurl&os=bcache&oi=1778576240&trid=578cada0ff4f45548d5b30ef12d8f75au&platform=pc&upsig=fb5b6e62d21c6ac271b1151e68d070e0&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,platform&cdnid=20320&mid=0&orderid=0,3&agrr=1&logo=80000000'
h = requests.get(url,headers=headers,timeout=8,verify=False)
print(h.status_code)
if h.status_code== 200:
with open("audio2.mp3","wb") as f:
f.write(h.content)
寻找视频下载链接
现在已经发现通过这些链接可以找到完整视频和音频,那么现在的问题是怎么 找到
一般分为两种情况
- 直接在网页源代码,这种是最简单的,直接requests的get请求就可以得到
- 在网页源代码中,但是get不到,说明是js加载的
- 可以看是不是异步加载,在xhr那一栏寻找是否有返回的json包,里面包含上述的类似链接
- 直接使用selenium来模拟浏览器(无头模式),这种比较暴力,但是有用
这次我们先查看网页源代码,ctrl+f ,显然在网页源代码里,audio的链接对应音频


在提取链接时不能使用一些解析包xpath、pyquery等包,因为它在js标签栏里,无法解析到。
我们使用正则表达式匹配,正则表达式的使用不讲,自行百度查
下面程序可以得到网页中所有的视频或音频下载链接
def get_video_audio_url(url='https://www.bilibili.com/video/BV1S5411E73f'):
#这个请求头其实没必要这么多,可以少一点
headers = {
'scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'if-range': "lm-vGohi8aMA0bE4dtHLYBU9m_vs",
'origin': 'https://www.bilibili.com',
'cache-control': 'max-age=0',
'referer': 'https://www.bilibili.com/',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'cross-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36 Edg/88.0.705.53',
}
h = requests.get(url, headers=headers, timeout=8)
if h.status_code == 200:
#解码
t = h.content.decode('utf-8')
#匹配所有的链接
#正则表达式 .*? 表示匹配尽可能少, .* 表示匹配尽可能多
video_pattern = re.compile(r'video.*?baseUrl":"(.*?)"')
video_url_lists = re.findall(video_pattern, t)
audio_pattern = re.compile(r'audio.*?baseUrl":"(.*?)"')
audio_url_lists = re.findall(audio_pattern, t)
title_pattern = re.compile(r'(.*?)')
video_title = re.findall(title_pattern, t)[0]
if len(video_url_lists) == 0 or len(audio_url_lists) == 0:
print("没有找到视频的视频下载连接或音频下载链接,下载失败")
return
else:
return video_url_lists, audio_url_lists, video_title
else:
print("请求失败,请求状态为{}".format(h.status_code))
return
总结
程序非常简单,但是对m4s的请求分析还是比较费劲的。
完整代码见Github
题外话
这个还是比较简单的,因为下载链接都已经在网页源代码中,而不是一个需要POST请求才能得到的json包中,POST请求构造它的请求参数才是最难的(可以看一下之前网易云评论)