作者:陈航,BIGO 大数据消息平台团队负责人。
本期文章排版:Tango@StreamNative。
关于 Apache Pulsar
Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、高吞吐、低延时及高可扩展性等流数据存储特性。
GitHub 地址: http://github.com/apache/pulsar/
背 景
在上一篇博客中,我们讨论了 BIGO 在 Pulsar Broker 性能调优过程中遇到的一些问题并提出相应的解决方案。本篇博客,我们将讨论 BIGO 在 Pulsar 底层分布式存储服务 BookKeeper 的性能调优工作。
对于 BIGO 而言,Apache Pulsar 在 bookie 端(BookKeeper 的单个存储节点)的系统性能主要存在以下几个问题:
- 读请求耗时较长,排队严重;
- Bookie 出现 direct memory Out of Memory (OOM),导致进程挂掉;
- 压测的时候经常出现 broker direct memory OOM;
- 当 journal 盘为 HDD 时,虽然关闭了 fsync,但是 bookie add entry 99th latency 依旧很高, 写入性能很差;
- 当大量读请求进入 bookie 时,出现写被反压,add entry latency 上升。当 Ledger 盘为 HDD 时,表现更加明显。
保证 BookKeeper 的稳定性以及高吞吐和低延迟是 Pulsar 稳定、吞吐的基石。本文会基于 BookKeeper 基本原理介绍影响读写吞吐和稳定性的要素。我们计划主要从以下六个方面介绍 bookie 性能调优:
- Pulsar Topic Message 写入/读取流程
- BookKeeper Request IO 请求调优
- Ledger Memtable 刷盘策略调优
- Journal 刷盘策略调优
- Entry 读取性能调优
- GarbageCollector (GC) 性能优化
环境部署与监控
在介绍 Bookkeeper 性能调优之前,我们需要为系统添加详尽的监控指标,并且要明确各监控指标背后的含义及关联关系。我们已经在 Apache Pulsar 在 BIGO 的性能调优实战(上)中详细描述过环境部署与监控这部分内容,这里不再赘述。
Pulsar Topic Message 写入/读取流程
为了描述更加清晰易懂,我们首先从 Pulsar Topic message 写入/读取角度介绍消息流转全貌,然后结合 bookie 内部实现原理再进行介绍。
由于 Pulsar 默认使用 dbLedgerStorage 存储格式,所以本博客选取 dbLedgerStorage 的实现方式进行讲解。
Topic Message 写入流程
当客户端向 BookKeeper 中写入一条 entry(每条 entry 具备唯一的

- 将 entry 放入 Netty 线程处理队列中,等待 Netty 线程进行处理。
- Netty 线程会依次从队列中获取每一个 entry,根据该 entry 的 ledgerId 进行取模,选择写入的目标磁盘(ledger 盘)。取模算法为:
ledgerId % numberOfDirs,其中numberOfDirs表示 bookie 进程配置的 ledger 目录的个数。 - 选择目标磁盘对象后,将索引写入 cache 和 rocksDB 进行持久化存储,将 payload 写入 memtable(这是一个内存双缓冲),等待排序和回刷。
- 当 memtable 的一个缓冲存满之后,会触发 flush,将 payload flush 到 PageCache 中,再由 PageCache 回刷到 disk 中。
Topic Message 读取流程
当客户端需要读取某一个 entry(每条 entry 具备唯一的
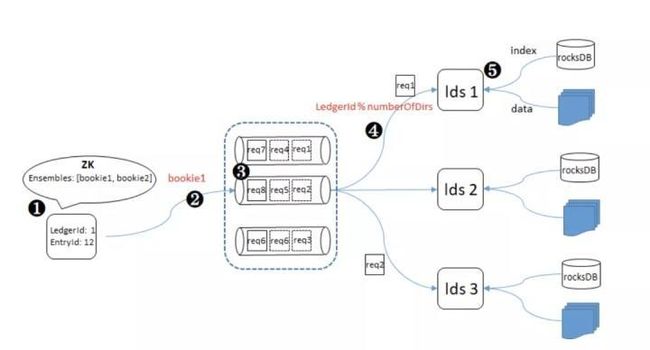
- 从 ZooKeeper 中获取 entry 所在 ledger 的 metadata。metadata 存储该 ledger 副本所在的 bookie 节点地址,如:Ensembles: [bookie1, bookie2]。
- 向其中一个 bookie 发送 entry 读取请求(为了叙述方便,此处省略客户端执行的一系列容错、熔断策略)。
- bookie1 收到 read entry 请求后,根据 ledgerId 进行 hash,选择对应的 readerThread,并将请求放入该 readerThread 的请求处理队列。
- readerThread 依次从请求队列中取出请求,根据 ledgerId 取模,选择该 ledger 所在的磁盘。
- 选择目标磁盘对象后,首先检查 memtable、readAheadCache 中是否已经缓存目标 entry。如果有,则直接返回。否则,读取 rocksDB 索引,进而读取磁盘上的目标数据,并将读取到的数据加载到 readAheadCache 中。
以上是 message 写入/读取的主体逻辑。那么 message 具体处理细节是怎样的?当我们的生产系统中出现 message 写入慢、读取慢等情况时,我们如何快速定位问题,并进行针对性优化?这就需要我们对 BookKeeper 的 IO 模型具有较为深入的理解,必要时需要结合 Linux IO 协议栈进行针对性调优。
BookKeeper Request IO 请求调优
我们首先介绍 BookKeeper 使用 Netty 处理 Request IO 模型,包括 Add Entry Request 和 Read Entry Request 处理流程,并附上每一个处理步骤的监控项名称和含义,然后再针对 BIGO 生产环境遇到的性能问题给出相关解决方案。
BookKeeper Request IO 请求流程使用以下监控指标。
bookkeeper_server_BookieReadThreadPool_queue_[0..16]:队列中排队的请求个数;bookkeeper_server_READ_ENTRY_REQUEST:Request 从进入请求队列到被处理完成的时延;bookkeeper_server_BookieReadThreadPool_total_tasks_0:正在被 read 线程处理的请求个数(衡量 read 吞吐能力);bookie_read_entry:Read 请求从开始处理到处理完成的耗时。
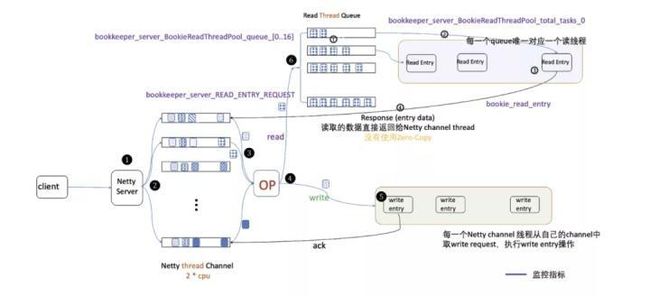
根据图示的步骤,下面简要介绍从 BookKeeper Client 发起 Request 请求到被 Bookie 处理的整个过程:
- Bookie Server 启动过程中,首先启动 Netty Server(epoll)。默认分配两倍 CPU 核数的线程(thread)处理网络请求。每一个线程拥有独立的 thread channel(默认长度为 10000),缓存接收到的 Request,并监听网络端口(默认端口:3181)。
- 当 Netty Server 接收到 Client 的 request 请求时,会根据 client sessionId 进行哈希取模,映射到对应的 Netty thread Channel 中,等待相应的 Netty thread 进行处理。
- 每个网络处理线程会从各自的 thread channel 中取出待处理的 Request,依次进行如下处理:
LengthFieldBasedFrameDecoder、LengthFieldPrepender、RequestDecoder、ResponseEncoder、ServerSideHandler、requestHandler。其中requestHandle是真正处理请求的操作,其他的都是进行解包等预处理。 - 在
BookieRequestProcessor##processRequest方法中,根据请求类型调用不同方法进行处理,处理方法有:ADD_ENTRY、READ_ENTRY、FORCE_LEDGER、AUTH、WRITE_LAC、READ_LAC、GET_BOOKIE_INFO、START_TLS等。这是 bookie server 处理不同类型 request 的总入口(这里我只使用最常用的ADD_ENTRY和READ_ENTRY进行分析)。 - ADD_ENTRY
- 将 request 和 channel 传给 WriteEntryProcessorV3 生成相应实例,并调用 run 方法启动。
run方法中,首先调用addEntry方法将 entry 写入 bookie 中,并返回处理结果。- 将处理结果封装到 sendResponse 中,调用 writeChannel 写出到 netty thread channel,并发送给客户端。
- READ_ENTRY
- 将 Read Request 封装成 ReadEntryProcessorV3 实例,使用 LedgerId 按照线程池大小取模选择一个 Reader 处理线程,并将 Read Request 加入该线程的处理队列中(每个线程拥有独立的队列,长度默认配置为 2500。如果排队长度超过最大值,则会被阻塞)。
- Reader 处理线程不断从自己的队列中取出 Read Request,调用 ReadEntryProcessorV3 实例的
safeRun方法读取数据。 - 数据读取过程是根据 LedgerId 选择对应的 Ledger 实例将 entry data 读取回来,并塞入 readResponse 中。
- 将 Read Response 返回给 Netty Thread Channel,再由 Netty 统一发送给客户端。
在压测过程中,我们发现某些 ledger 读取很慢。结合监控,我们发现 reader 处理线程的等待队列排队情况分布不均,某些 reader 处理线程排队严重。
结合 READ_ENTRY 处理模型,ledger 读取是按照总 reader 线程数取模。可以采取以下两种解决方案缓解这个问题:
- 增加 reader 处理线程数,缓解处理压力。
- 为 topic 增加 partition,分散读取压力。
由于所有读写请求在被处理之前都会被加入相应队列中排队,控制参数分别为: maxPendingReadRequestsPerThread 和 maxPendingAddRequestsPerThread。如果下游处理变慢,可能造成等待队列排满,加大 Direct Memory OOM 的风险。缓解方案如下:
- 控制等待队列长度。对于无法快速处理的请求,直接返回 error。
- 加快 Journal 写入和 Ledger 写入/读取的处理速度。
Ledger Memtable 刷盘策略调优
数据写入 Journal 之前,需要先保证 Memtable 写成功。Memtable 的设计是一个内存双缓冲,单个缓冲区默认容量大小为 Direct Memory Size * 1/4 * 1/numberOfLedgers * ½。
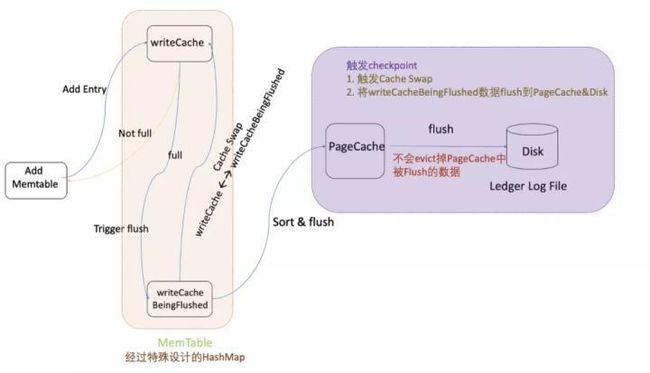
当我们向 Memtable 中写入一条 Entry 数据时,会直接将 entry 写入 WriteCache,此时有三种情况:
- 如果 WriteCache 仍有剩余空间,直接将 entry 写入 WriteCache,然后返回成功。
- 如果 WriteCache 已经写满,但是 writeCacheBeingFlushed 是空的,则触发双缓冲旋转,将 entry 写入空 WriteCache 中,并启动独立线程触发排序和回刷。
- 如果 WriteCache 已经写满,writeCacheBeingFlushed 尚未完成回刷,entry 写入被阻塞直到 writeCacheBeingFlushed 回刷完成。
WriteCache 排序回刷过程如下:
- 使用快速排序算法对 WriteCache(经过特殊设计的 HashMap)中的数据进行排序。排序后,同一 Ledger 的相近 entry 排在一起,便于读取的时候 OS 预读。
- 将排序后的索引写入 RockDB 中。
- 将排序后的数据 flush 到 PageCache 中。
我们可以配置参数 flushEntrylogBytes 来控制将 entry 从 PageCache 中 flush 到 Disk 的频率。
需要注意的是,PageCache 中的 entry flush 到 disk 后,不会 evict 掉 PageCache 中的数据,目的是为 entry 读取提供缓存。
在 HDD 作为 Ledger 盘的场景下,如果一次从 PageCache 中 flush 到 Disk 的数据量太大,容易导致磁盘 IO Util 持续打满,PageCache 回刷变慢,WriteCache flush 到 PageCache 的速度也会变慢,最终导致 entry 写入被阻塞。
正常情况下,WriteCache 中的数据排序后,flush 到 PageCache 中即可返回。整个过程都是写内存,无非是将数据从用户态拷贝到内核态,PageCache 回刷和 WriteCache flush 是异步解耦的,PageCache 回刷变慢不应该影响 WriteCache flush 速度。问题在于,WriteCache flush 的数据最终都会写进 entry log 文件中。当 entry log 文件发生滚动时,需要等待所有 PageCache 中相关数据都 flush 到 disk 中才会将 entry log 文件关闭,并创建新 entry log 文件接收新数据的写入。因此,一旦 PageCache 回刷变慢,最终也会影响 WriteCache flush 到 PageCache 的速度。
在 Catchup Read 场景下,由于 Ledger 盘需要提供 entry 读取,会形成磁盘宏观上随机读,微观上顺序读(排序带来的效果)。此时既有数据写入,也有数据读取,对于磁盘而言,这是读写混合的场景。为了提供读写吞吐,我们需要想办法降低磁盘读的频率,这部分的调优需要从 Linux IO 协议栈出发。
Journal 刷盘策略调优
ADD_ENTRY 操作最终采用调用 Bookie#addEntry 方法执行 entry 写入操作。Entry 写入首先会写 Memtable,待写成功后再写 Journal,这个过程是串行的。
假设我们配置了多个 journal 目录,那么我们具体选择哪一个 journal 进行写入?我们采用 ledgerId % numberOfJournalDirs 取模算法,选择 journal 实例。然后将 add request(包含数据 payload)放入待处理队列中,由专门的 journal thread 进行处理。用户可以通过配置 bookkeeper.conf 中 numJournalCallbackThreads 参数,控制 journal thread 线程数,默认为 8。
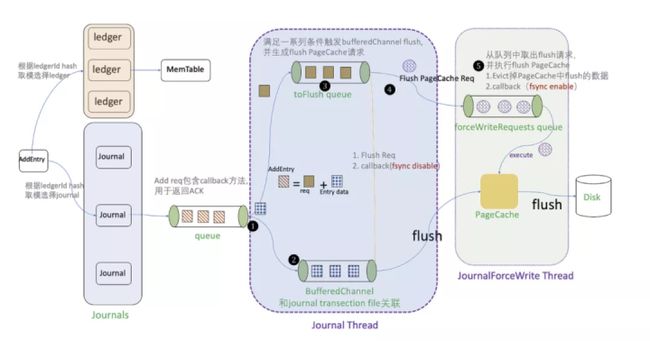
写请求放入 journal 待处理队列后,处理步骤如下:
- Journal 实例有独立运行的后台线程,不断从 queue 中取出 QueueEntry 进行以下后续处理(如果 queue 中没有 QueueEntry,则阻塞)。
- 将 QueueEntry 中 entry data 剥离出来,写入 BufferedChannel(每个 journal file 对应一个 BufferedChannel。当上一个 journal file 滚动时,需要创建下一个 journal file 并与新的 BufferedChannel 进行关联)。
- 将已剥离 entry data 的 request meta 放入 toFlush qeueue 中。一旦满足以下任一条件,toFlush queue 就会进行 flush 操作:
- toFlush queue 中的 entry 等待时间超过了阈值。
- toFlush queue 大小超过了 buffWrite 阈值或者 bufferedEntries 阈值。
- 将数据 flush 到 PageCache。
- 将 BufferedChannel 中的数据 flush 到 OS 的 PageCache 中。
- 满足以下任一条件,就生成 forceWriteRequest 请求,并将 forceWriteRequest 请求加入 forceWriteRequests 队列(BookKeeper 4.9.2 版本,只要满足前两个条件中的任一条件就会 flush;BookKeeper 4.10 版本每次都会 flush;当前 master 分支代码需要满足以下任一条件就会 flush):
- 开启 journalSyncData。
- Journal file 达到了最大 size,需要进行文件滚动。
- 距离上一次 flush PageCache 间隔达到了最长间隔(默认 1s)。
- 将 PageCache 中数据 flush 到 Disk。forceWriteRequests queue 拥有独立的后台线程,不断从队列中取出 forceWriteRequest,然后将 PageCache 中数据 flush 到 Disk。这里会涉及到 ADD_ENTRY ACK 时机的问题,主要区别在于是否开启了 JournalSyncData(Pulsar 默认开启,即每次刷盘完成之后才返回 ACK)。
- 如果开启 JournalSyncData,则在 flush Disk(步骤 5)之后才返回 ACK。
- 如果关闭 JournalSyncData,则在 flush PageCache(步骤 4) 之后就会执行回调, 返回 ACK。
为了更加清晰地发现 journal 写入过程中的瓶颈,我们需要弄清楚每一个监控项的含义,并配置 Grafana 监控指标,便于快速定位问题。下图是每一个 queue 的长度监控以及每一阶段的处理耗时。
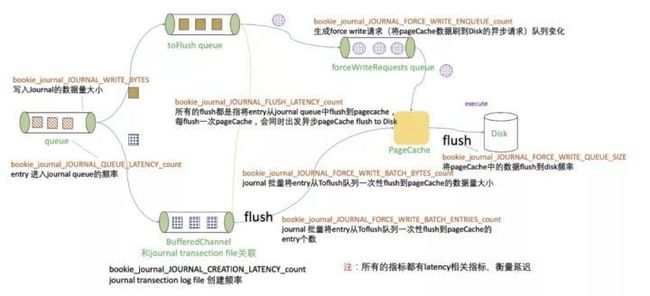
需要注意的是:
- BufferedChannel 与 journal transection file 直接关联。如果没有创建新的 journal file,journal add request 处理会被阻塞。虽然上一个 journal file roll 与下一个 journal file 创建是异步进行,但是如果此刻 journal 盘 io util 持续打满,新 journal file 创建被阻塞(IO 等待时间较长),journal 写入耗时就会上涨。需要关注的指标为:
bookie_journal_JOURNAL_CREATION_LATENCY。 - 当 journal 盘为 HDD 时,我们一般会将 journalSyncData 开关关闭,让数据写入到 PagaCache 中就返回 ACK,从而降低 entry 写入延迟。但是,在压测过程中,我们发现关闭 journalSyncData 后,add entry 99th latency 十分不稳定,偶尔会到几秒甚至十几秒。这是由于 PageCache 回刷带来的磁盘 IO 抖动。触发 PageCache 中数据回刷到磁盘有三个时机:
- OS 每间隔 30s 回刷一次。
- PageCache dirty page 超过阈值会触发回刷。
- Roll File 会触发回刷。
这三种回刷策略的共同之处在于一次回刷的数据量很大。一次回刷大量数据会造成 HDD 磁盘短时间内持续 IO Util 打满,内核下发的其他 IO 请求会在调度队列中排队,包括 new journal file create 请求。为此,我们在 PR 2287 中提出了分时 flush PageCache 的策略,控制单次从 PageCache 中 flush 到 disk 的数据量,从而控制 disk io util 打满时间。从 BIGO 压测实践来看,开启此策略后,HDD 达到了近似 SATA SSD 的性能。
由于所有 Journal 写请求首先都会被放到 Journal Queue 中,如果下游处理速度变慢,Journal Queue 中可能积攒大量 Add Request 等待处理,且消耗大量内存,增加 Direct Memory OOM 的风险。缓解方案如下:
- 使用 journalQueueSize 参数控制 Journal Queue 大小,默认为 10000。
- 加快 Journal 线程数据写入处理速度。
Entry 读取性能调优
Entry 读取处理流程如下图所示,传入参数为(ledgerId, entryId)。
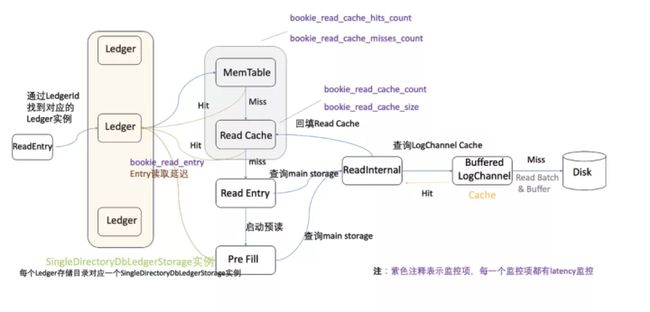
- 根据 ledgerId 按照
ledgerId % numberOfLedgers取模,选择 entry 所在的目标 Ledger 磁盘实例。 - 检查该 Ledger 实例对应的 MemTable(writeCache 和 WriteCacheBeingFlushed)中是否存在想要读取的 entry(按照
- 检查 Read Cache 中是否有想要读取的 entry(按照
为 Key,从索引中查询,时间复杂度为 O(1))。如果 Read Cache 命中,则直接返回 entry。 - 如果 Read Cache 也没有命中,就从主存中读取数据,并且启动预读(预读是一次读一个 entry,多次循环读取)并将读取的所有 entry 加入 Read Cache 进行缓存。整个预读流程是串行的,预读的 entry 数量由参数
dbStorage_readAheadCacheBatchSize控制。这个参数配置的越大,Read Cache Miss 时带来的长尾延迟越高。
预读流程如下:
- 获取 LedgerId 对应的 Ledger File 实例,并查询 BufferedLogChannel 中是否存在想要读取的 entry。
- 如果有,则直接返回 entry。
- 如果没有,启动 RandomAccessFile 并套上 internalNioBuffer,批量从文件中读取一个 batch 数据到 readBuffer 中。batch 大小由 readBufferSizeBytes 参数控制。
- 将预读取的 entry 放入 BufferedLogChannel Cache 中缓存,并将结果返回。
预读过程中,如果读取的是热数据,仍在 PageCache 中,则直接从 PageCache 读取,否则从 Disk 读取。从 Disk 读取数据时,OS 是有预读功能的,会将读取的数据缓存在 PageCache 中。由于 Bookie 并不完全依赖 PageCache 做缓存命中,所以 Catch up 读带来的 PageCache 污染对整体影响较小。
当读取某一个 entry 时,需要根据目标 entry 在 entry log file 中的偏移量(索引)进行读取。Bookie 为了加速索引读取,将索引保存在 RocksDB 中,我们需要保证索引在 RocksDB 中查询的命中率,那么 RocksDB 缓存大小配置成为关键,相关配置参数为 dbStorage_rocksDB_blockCacheSize。
GarbageCollector(GC)性能优化
Bookie 在处理数据写入时,会将同一段时间内写入的数据(可能归属于多个 ledger 的 entry)经过排序后 flush 到同一个 entry log 文件中,将索引存放在 RocksDB 中。这就带来了一个问题:当某些 topic 数据过期或者被删除时,过期数据关联的所有 ledger 都应该被清理掉。但是,由于多个 ledger 同一段时间内的数据被写入到同一个 entry log 文件,清理过程就会变得稍微复杂些。
BookKeeper 的处理方案是:启动一个独立的 GarbageCollector(GC)线程来完成清理工作。GC清理线程分为 minorCompaction 和 majorCompaction,两者的区别在于阈值不同。默认情况下, minorCompaction 清理间隔为 1 小时,阈值为 0.2; majorCompaction 清理间隔为 24 小时,阈值为 0.5。这里阈值指一个 entry log file 中有效数据占比。当 Topic 中有数据过期时,系统会将对应 ledger 在 ZooKeeper 中的 metadata 标记为已过期。GC 线程会定时扫描每个 entry log 中所有 ledger 的过期情况,并统计剩余有效数据比例。
GC 的处理方式为依次读取 entry log 文件中每一个 entry,判断 entry 是否过期。如果已经过期,则直接丢弃,否则将其写入新 entry log 文件中,并更新 entry 在 RocksDB 中的索引信息。
虽然 GC 过程是依次读取 entry log 文件中的 entry,对磁盘而言是顺序读,但是如果此时有大量数据写入,则变成了读写混合场景,机械硬盘在读写混合场景下性能会急剧下降。从现象来看,当bookie 发生 GC 时,数据读写吞吐会出现抖动。
为了降低 GC 带来的影响,BookKeeper 提供了两种限速策略:按照 entry 限速和按照 bytes 限速。默认按照 entry 来限速,即每秒读取 entry 的最大数量,由参数 compactionRate 进行控制,默认值是 1000。也可以按照 bytes 来限速,即每秒读取多少字节数据,由参数 isThrottleByBytes 和 compactionRateByBytes 一起控制,默认值是 1000000。
由于每个 entry 承载的数据量大小各异,按照 entry 限速可能会引起从磁盘读取的数据量抖动,从而影响正常数据读写。因此建议按照 bytes 进行限速。
Linux IO 协议栈优化
对于 Linux IO 协议栈,我们建议从以下方面进行优化:
- HDD 磁盘使用 CFQ(Completely Fair Queuing,完全公平队列调度算法)调度算法,SSD 磁盘使用 NOOP 调度算法。
- 使用基于 OpenCAS 的 SSD 进行读缓存加速。在缓存层采用不同的替换策略,降低读请求下沉到 ledger 盘的概率,尽可能保证 ledger 盘的顺序读写,从而提高读写吞吐。这一部分 BIGO 正在进行相关压测工作,后续进展会及时同步。
总 结
本文从 message 写入和读取角度介绍了 BookKeeper 消息处理运行机制,并详细说明对性能产生影响的关键要点。在叙述过程中,我们着重结合每一个环节的监控指标对运行机制进行讲解。在遇到性能或者稳定性问题时,大家可以先根据监控指标进行排查,快速定位出问题所在,并结合原理进行分析和处理。
在机械硬盘场景下,如何优化 IO 性能是保证 BookKeeper 稳定性和吞吐量的关键。在设计上,BookKeeper 尽可能保证了 Journal 和 Ledger 的顺序写,但依旧无法避免读写混合的干扰,如Catch up 读、Compaction、Auto Recovery 等,机械硬盘在读写混合场景下性能会急剧下降。对于 Compaction 和 Auto Recovery,我们可以通过限速来缓解这个问题,对于 Catch up 读,我们可以考虑采用 SSD 缓存来提高读命中率,降低随机 IO 下沉到机械硬盘的概率。BIGO 消息队列团队会持续在 IO 层进行一系列优化,定制相关缓存策略,保证系统吞吐和稳定。
关于作者

陈航,BIGO 大数据消息平台团队负责人,负责承载大规模服务与应用的集中发布-订阅消息平台的创建与开发。他将 Apache Pulsar 引入到 BIGO 消息平台,并打通上下游系统,如 Flink、ClickHouse 和其他实时推荐与分析系统。他目前聚焦 Pulsar 性能调优、新功能开发及 Pulsar 生态集成方向。
相关阅读
- Apache Pulsar 在 BIGO 的性能调优实战(上)
- Apache Pulsar 在能源互联网领域的落地实践
- Apache Pulsar 在腾讯 Angel PowerFL 联邦学习平台上的实践

点击 链接,获取 Apache Pulsar 硬核干货资料!