Python中比较numpy的Kmeans算法和不用numpy算法的效率
kemans算法
K-means算法是硬聚类算法,是典型的基于原型的目标函数聚类方法的代表,它是数据点到原型的某种距离作为优化的目标函数,利用函数求极值的方法得到迭代运算的调整规则。K-means算法以欧式距离作为相似度测度,它是求对应某一初始聚类中心向量V最优分类,使得评价指标J最小。算法采用误差平方和准则函数作为聚类准则函数。
要求随机取1000个点,其中随机5个为中心点,.求其余995个点与每个中心点的距离距离最小的,将此点和对应的中心点归为一类.类中求平均值作为新的中心点如果新中心点和旧中心点的误差小于某个阈值,停止,否则重复以上操作。
代码实现(使用numpy的) 未使用numpy的Kmeans算法在本篇文章的下一篇
#引入需要的模块
import numpy as np
import matplotlib.pyplot as plt
import random
import time #检验效率,时间少的效率高
figure = plt.figure()
#用numpy的方法
subplot1 = figure.add_subplot(1,2,1)
class KMeans():
def __init__(self, k=1):
'''
:param k: k代表分类数
'''
self.__k = k
self.__data = None # 存放原始数据
self.__pointCenter = None # 存放中心点,第一次获得的中心点通过随机方式在__data里随机出来
self.__result = [] # 存放分类结果
for i in range(k):
self.__result.append([]) # [[],[],[],[],[]]
pass
pass
def fit(self, data, threshold, times=50000):
'''
进行模型训练
:param data: 训练数据
:param threshold: 阈值,退出条件
:return:
'''
self.__data = data
self.randomCenter()
# print(self.__pointCenter)
centerDistance = self.calPointCenterDistance(self.__pointCenter, self.__data)
# 对原始数据进行分类,将每个点分到离它最近的中心点
i = 0
for temp in centerDistance:
index = np.argmin(temp)
self.__result[index].append(self.__data[i])
i += 1
pass
# 打印分类结果
# print(self.__result)
oldCenterPoint = self.__pointCenter
newCenterPoint = self.calNewPointCenter(self.__result)
while np.sum(np.sum((oldCenterPoint - newCenterPoint)**2, axis=1)**0.5)/self.__k > threshold:
times -= 1
result = []
for i in range(self.__k):
result.append([])
pass
# 保存上次的中心点
oldCenterPoint = newCenterPoint
centerDistance = self.calPointCenterDistance(newCenterPoint, self.__data)
# 对原始数据进行分类,将每个点分到离它最近的中心点
i = 0
for temp in centerDistance:
index = np.argmin(temp)
result[index].append(self.__data[i]) # result = [[[10,20]]]
i += 1
pass
newCenterPoint = self.calNewPointCenter(result)
self.__result = result
pass
self.__pointCenter = newCenterPoint
return newCenterPoint, self.__result
pass
def calPointCenterDistance(self, center, data):
'''
计算每个点和每个中心点之间的距离
:return:
'''
centerDistance = []
flag = False
for temp in data:
centerDistance.append([np.sum((center - temp) ** 2, axis=1) ** 0.5])
pass
# print(centerDistance)
return np.array(centerDistance)
pass
def calNewPointCenter(self, result):
'''
计算新的中心点
:param result:
:return:
'''
newCenterPoint = None
flag = False
for temp in result:
# 转置
temps = np.array(temp)
point = np.mean(temps, axis=0)
if not flag:
newCenterPoint = np.array([point])
flag = True
pass
else:
newCenterPoint = np.vstack((newCenterPoint, point))
pass
# print(newCenterPoint)
return newCenterPoint
pass
def randomCenter(self):
'''
从原始的__data里随机出最开始进行计算的k个中心点
:return:
'''
if not self.__pointCenter:
index = random.randint(0, len(self.__data) - 1)
self.__pointCenter = np.array([self.__data[index]])
pass
while len(self.__pointCenter) < self.__k:
# 随机一个索引
index = random.randint(0, len(self.__data) - 1)
# 判断中心点是否重复,如果不重复,加入中心点列表
if self.__data[index] not in self.__pointCenter:
self.__pointCenter = np.vstack((self.__pointCenter, self.__data[index]))
pass
pass
pass
pass
if __name__ == "__main__":
# 原始数据改为nunmpy结构
data = np.random.randint(0, 100, 20000).reshape(10000, 2)
# print(data)
startTime = time.time()
kmeans = KMeans(k=5)
centerPoint, result = kmeans.fit(data, 0.0001)
print('numpy方法的kmeans算法的时间',time.time() - startTime)
# print(centerPoint)
i = 0
tempx = []
tempy = []
color = []
for temp in result:
temps = [[temp[x][i] for x in range(len(temp))] for i in range(len(temp[0]))]
color += [i] * len(temps[0])
tempx += temps[0]
tempy += temps[1]
i += 2
pass
subplot1.scatter(tempx, tempy, c=color, s=30)
#不用numpy的方法
subplot2 = figure.add_subplot(1,2,2)
class KMeans():
def __init__(self, k=1): #k代表分类数,默认为1,可以改变
self.__k = k
self.__data = [] # 存放原始数据
self.__pointCenter = [] # 存放中心点,第一次获得的中心点通过随机方式在__data里随机出来
self.__result = [] #类里的数据
for i in range(k):
self.__result.append([]) # [[],[],[],[],[]] #有几个类添加几个列表
pass
pass
#进行模型训练
def fit(self, data, threshold, times=500): #data: 训练数据 threshold: 阈值,退出条件
self.__data = data
self.randomCenter() #调用此方法随机出最开始的中心点
# print(self.__pointCenter) #输出中心点列表,无实意
centerDistance = self.calPointCenterDistance(self.__pointCenter, self.__data) #计算每个点和每个中心点的距离
# 对原始数据进行分类,将每个点分到离它最近的中心点
i = 0 #从第一个点开始
for temp in centerDistance:
index = temp.index(min(temp))
self.__result[index].append(self.__data[i])
i += 1
pass
# print(self.__result) # 打印分类结果
oldCenterPoint = self.__pointCenter #将中心点赋值给它
newCenterPoint = self.calNewPointCenter(self.__result) #调用此方发,计算新的中心点
#判断:如果前后两次中心点之间的距离是否小于某个阈值
while self.calCenterToCenterDistance(oldCenterPoint, newCenterPoint) > threshold: #如果大于,重复while语句的操作,次数在times次内
times -= 1
result = []
for i in range(self.__k):
result.append([])
pass
oldCenterPoint = newCenterPoint # 保存上次的中心点
centerDistance = self.calPointCenterDistance(newCenterPoint, self.__data) #计算新中心点和个点之间的距离
# 对原始数据进行分类,将每个点分到离它最近的中心点
i = 0
for temp in centerDistance:
index = temp.index(min(temp))
result[index].append(self.__data[i]) # result = [[[10,20]]]
i += 1
pass
newCenterPoint = self.calNewPointCenter(result)
# print(self.calCenterToCenterDistance(oldCenterPoint, newCenterPoint))
self.__result = result
pass
self.__pointCenter = newCenterPoint
return newCenterPoint, self.__result #将新中心点和所有类中的点返回
pass
#计算两次中心点之间的距离,求和求均值
def calCenterToCenterDistance(self, old, new): #old:上次的中心点 new:新计算的中心点
total = 0
for point1, point2 in zip (old, new):
total += self.distance(point1, point2) #有几个中心点求几次
pass
return total / len(old) #返回前后两次中心点距离之和的平均值
pass
#计算每个点和每个中心点之间的距离
def calPointCenterDistance(self, center, data):
centerDistance = []
for temp in data:
centerDistance.append([self.distance(temp, point) for point in center]) #调用distance方法求各点到各中心点的距离
pass
# print(centerDistance)
return centerDistance #返回距离
pass
#计算新的中心点
def calNewPointCenter(self, result):
newCenterPoint = []
for temp in result:
# 转置:将每个点与所有中心点的距离列表 转置成 每个中心点与同一类的所有点的列表
temps = [[temp[x][i] for x in range(len(temp)) ] for i in range(len(temp[0]))]
point = []
for t in temps:
# 对每个维度(类)求和,取平均即为新的中心点
point.append(sum(t)/len(t)) # mean
pass
newCenterPoint.append(point)
pass
# print(newCenterPoint)
return newCenterPoint #返回新中心点的列表
pass
#计算两个点之间的距离,支持任意维度,欧式距离
def distance(self, pointer1, pointer2):
distance = (sum([(x1 - x2)**2 for x1, x2 in zip(pointer1, pointer2)]))**0.5 #公式,几个未知数和集合都可以,支持任意维度,这里是二维的
return distance #返回距离
pass
#从原始的__data里随机出最开始进行计算的k个中心点
def randomCenter(self):
while len(self.__pointCenter) < self.__k:
# 随机一个索引 所有点中随机取几个中心点
index = random.randint(0, len(self.__data) - 1)
# 判断中心点是否重复,如果不重复,加入中心点列表 避免因重复导致的中心点个数不够
if self.__data[index] not in self.__pointCenter:
self.__pointCenter.append(self.__data[index])
pass
pass
pass
pass
if __name__ == "__main__":
data = [[random.randint(1, 100), random.randint(1, 100)] for i in range(10000)] #随机10000个点
start = time.time()
kmeans = KMeans(k=5) #几个中心点(几个类)
centerPoint, result = kmeans.fit(data, 0.0001) #调用fit方法,参数中的0.0001为阈值
print('普通方法的kmeans算法的时间',time.time()-start)
# print(centerPoint)
#界面可视化,可以清晰的看到散点图,需引入 matplotlib模块
i = 0
tempx = []
tempy = []
color = []
for temp in result: #遍历类中的点,用同一种颜色,需转置
temps = [[temp[x][i] for x in range(len(temp))] for i in range(len(temp[0]))]
color += [i] * len(temps[0])
tempx += temps[0]
tempy += temps[1]
i += 2
pass
subplot2.scatter(tempx, tempy, c=color, s=30) #x轴,y轴,点的颜色,点的大小
plt.show()
运行结果:
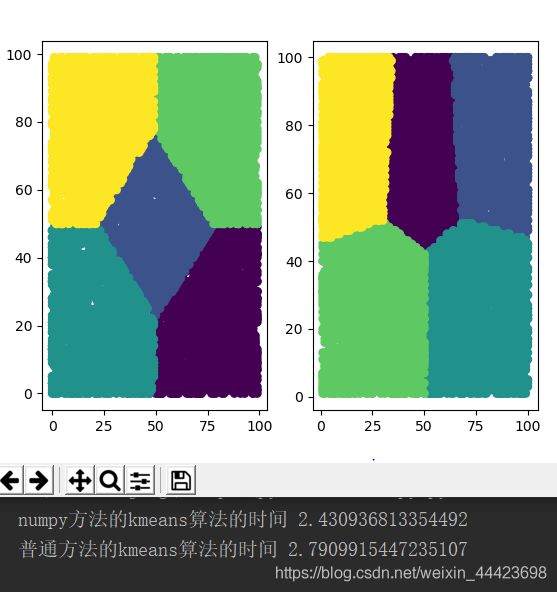
按照道理说使用numpy的Kmeans算法效率更高,但是发现在运行时,numpy的Kmeans中途可能需要做数据类型转换,这就耽误了很多时间,在把不必要的print语句注释掉效率还是蛮快的 。