java面试总结
JAVA基础部分:
使用泛型的好处
1,类型安全。 泛型的主要目标是提高 Java 程序的类型安全。通过知道使用泛型定义的变量的类型限制,编译器可以在一个高得多的程度上验证类型假设。没有泛型,这些假设就只存在于程序员的头脑中(或者如果幸运的话,还存在于代码注释中)。
2,消除强制类型转换。 泛型的一个附带好处是,消除源代码中的许多强制类型转换。这使得代码更加可读,并且减少了出错机会。
3,潜在的性能收益。 泛型为较大的优化带来可能。在泛型的初始实现中,编译器将强制类型转换(没有泛型的话,程序员会指定这些强制类型转换)插入生成的字节码中。但是更多类型信息可用于编译器这一事实,为未来版本的 JVM 的优化带来可能。由于泛型的实现方式,支持泛型(几乎)不需要 JVM 或类文件更改。所有工作都在编译器中完成,编译器生成类似于没有泛型(和强制类型转换)时所写的代码,只是更能确保类型安全而已。
三个字符串进行两两组合,把所有的情况进行输出
public void strTest() {
String[] strs = {"abc", "bcd", "efg"};
String[] ayyays = appendStrMethods(strs.length, strs);
for (String ayyay : ayyays) {
System.out.println(ayyay);
}
}
private String[] appendStrMethods(int length, String[] strs) {
Integer count = 0
String [] ayyays = new String[6];
for (int i = 0; i < strs.length; i++) {
for (int j = 0; j < strs.length; j++) {
if (j != i) {
ayyays[count++] = strs[i] + strs[j];
}
}
}
return ayyays;
}
abcbcd
abcefg
bcdabc
bcdefg
efgabc
efgbcd为什么 Java 中只有值传递?
按值调用(call by value)表示方法接收的是调用者提供的值,而按引用调用(call by reference)表示方法接收的是调用者提供的变量地址。一个方法可以修改传递引用所对应的变量值,而不能修改传递值调用所对应的变量值。 它用来描述各种程序设计语言(不只是 Java)中方法参数传递方式。Java 程序设计语言总是采用按值调用。也就是说,方法得到的是所有参数值的一个拷贝,也就是说,方法不能修改传递给它的任何参数变量的内容。
new String()创建几个字段
题目中的String创建方式,是调用String的有参构造函数,而这个有参构造函数的源码则是这样的public String(String original),这就是说,我们可以把代码转换为下面这种:
String temp = "hello"; // 在常量池中
String str = new String(temp); // 在堆上 12345
这段代码就创建了2个String对象,temp指向在常量池中的,str指向堆上的,而str内部的char value[]则指向常量池中的char value[],所以这里的答案是2个对象。(这里不再详述内部过程,之前的文章有写,参考深入浅出Java String)
那之前我为什么说答案是1个的也对呢,假如就只有这一句String str = new String("hello")代码,并且此时的常量池的没有"hello"这个String对象,那么答案是两个;如果此时常量池中,已经存在了"hello",那么此时就只创建堆上str,而不会创建常量池中temp,(注意这里都是引用),所以此时答案就是1个。
Map集合体系
Map常用的子类:
1、HashMap:内部结构是哈希表,线程不安全,支持null作为键和值。但是键的值不能重复,会覆盖原来的数据。 2.0.HashMap是Java中最常用的一个Map类,性能好、速度快,但不能保证线程安全,它可用null作为key/value 2.1.在多线程环境下,使用HashMap进行put操作会引起死循环,所以在并发情况下不能使用HashMap
2、Hashtable:内部结构是哈希表,线程安全的。不支持null作为键和值。 1.0.线程安全的Map类,其public方法均用synchronize修饰 ,这表示在多线程操作时,每个线程在操作之前都会锁住整个map,待操作完成后才释放 如线程1使用put进行元素添加,线程2不但不能使用put方法进行添加元素,也不能使用get方法来获取元素,所以竞争越激烈效率越低,这必然导致多线程时性能不佳.另外,Hashtable不能使用null作为key/value
3、ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment是一种可重入锁ReentrantLock,在ConcurrentHashMap中扮演锁的角色,HashEntry则用于存储键值对数据。一个ConcurrentHashMap中包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构。一个Segment里面包含一个HashEntry数组,每个HashEntry是一个链表的元素。每个Segment拥有一个锁,当对HashEntry数组的数据进行修改时,必须先获得对应的Segment锁,如图所示:
4、TreeMap:内部结构是二叉树,不是同步的,支持null作为键和值。TreeMap是一个有序的key-value集合,它内部是通过红-黑树实现的,它支持序列化 。
List集合体系
list有序重复
ArrayList:底层数组,查询块,增删慢,不安全,效率高,底层是数组
LinkedList:底层链表,查询慢,增删快,不安全,效率高 ,底层是双向链表
Vector:底层数组,查询慢,增删慢,线程安全,效率低
LinkedList与ArrayList差异
1、相同之处
a)都直接或者间接继承了AbstractList、都支持以索引的方式操作元素
b)都不必担心容量问题、ArrayList是通过动态数组来保存数据的、当容量不足时、数组会自动扩容、而LinkedList是以双向链表来保存数据的、不存在容量不足的问题
c) 都是线程不安全的、一般用于单线程的环境下、要想在并发的环境下使用可以使用Collections工具类包装。
2、不同之处
a)ArrayList是通过动态数组来保存数据的、而LinkedList是以双向链表来保存数据的
b)相对与ArrayList而言、LinkedList实现了Deque接口、Deque继承了Queue接口、同时LinkedList继承了AbstractSequencedList类、使得LinkedList在保留使用索引操作元素的功能的同时、也实现了双向链表所具有的功能、这就决定了LinkedList的特定
c)对集合中元素进行不同的操作效率不同、LinkedList善于删除、添加元素、ArrayList善于查找元素。本质就是不同数据结构之间差异。
ArrayList与Vector差异
1、相同之处:
a) 都是继承AbstractList、拥有相同的方法的定义。
b)内部都是以动态数组来存储、操作元素的、并且都可以自动扩容。
2、不同之处:
a) 线程安全:ArrayList是线程不安全的、适用于单线程的环境下、Vector是线程安全的、使用与多线程的环境下。
b)构造方法:Vector有四个构造方法、比ArrayList多一个可以指定每次扩容多少的构造方法。
c) 扩容问题:每当动态数组元素达到上线时、ArrayList扩容为:“新的容量”=“(原始容量x3)/2 + 1”、 而Vector的容量增长与“增长系数有关”,若指定了“增长系数”,且“增长系数有效(即,大于0)”;那么,每次容量不足时,“新的容量”=“原始容量+增长系数”。若增长系数无效(即,小于/等于0),则“新的容量”=“原始容量 x 2”。
d) 效率问题:因为Vector要同步方法、这个是要消耗资源的、所以效率会比较低下
e)Vector为摆脱fail-fast机制、自己内部多提供了一种迭代方法Enumeration、
set集合体系
set无序唯一 ,根据hashcode来进行数据的存储,所以位置是固定的但是位置不是用户用户可以控制的。
HashSet是基于散列表实现的,元素没有顺序;add、remove、contains方法的时间复杂度为O(1)。(contains为false时,就直接往集合里存)
TreeSet是基于树实现的(红黑树),元素是有序的;add、remove、contains方法的时间复杂度为O(log (n))(contains为false时,插入前需要重新排序)。
因为元素是有序的,它提供了若干个相关方法如first(), last(), headSet(), tailSet()等;
LinkedHashSet介于HashSet和TreeSet之间,是基于哈希表和链表实现的,支持元素的插入顺序;基本方法的时间复杂度为O(1);
java中的设计模式
-
1.问:你对设计模式了解多少? 回答:了解过几个设计模式 问:那请你简单描述一下几个你最熟悉的设计模式
回答:我先回答了设计模式一共有23种,然后我用spring的IOC和AOP,为例子,简单介绍了一下工厂模式和代理模式,我又举了单例模式。IoC就是典型的工厂模式,通过sessionfactory去注入实例。AOP就是典型的代理模式的体现。
单例模式:
ArrayList怎样去扩容
ArrayList默认容量是10,如果初始化时一开始指定了容量,或者通过集合作为元素,则容量为指定的大小或参数集合的大小。每次扩容为原来的1.5倍,如果新增后超过这个容量,则容量为新增后所需的最小容量。如果增加0.5倍后的新容量超过限制的容量,则用所需的最小容量与限制的容量进行判断,超过则指定为Integer的最大值,否则指定为限制容量大小。然后通过数组的复制将原数据复制到一个更大(新的容量大小)的数组。
Servlet在Java中的作用
在Java web b/s架构中,servlet扮演了重要的角色,作为一个中转处理的容器,他连接了客户端和服务器端的信息交互和处理。简单来说,客户端发送请求,传递到servlet容器,而servlet将数据转换成服务器端可以处理的数据再发送给服务器端,再数据处理之后,再传递到servlet容器,servlet再转译到客户端,完成了一次客户端和服务器端的信息交互。Servlet是通过Java编写的,因为他也具备了Java的一些特点,比如跨平台性,可扩展性高,然而他的优点不仅仅是局限于语言方面,因为Servlet的出现,可以使我们将JSP页面中的一些JAVA代码移植到Servlet中来,可无疑使前端人员深受喜欢,方便了项目的修改完善,而Servlet的使用也是非常的简单。Servlet的生命周期有四个阶段,第一个阶段,实例化,会调用构造方法,第二个阶段是初始化,会调用init()方法,第三个阶段是请求处理,调用service方法,第四个阶段,服务终止也就是销毁阶段,调用destroy方法。前台如何将数据传递给Servlet?也是非常简单的,只需表单提交就可以轻松完成,Servlet可以使用request.getParameter来接受,传递给前台就可以使用request.setA什么的来赋值。页面提交的时候有get和post,俩种方式,这俩种方式都会在Servlet中处理,如果是get则会调用doget,post则会dopost,而同时使用,只需要post调用doget方法就可以。
java中的apache的类库以及java中的Collections和collection
apache的类库有:Beanutils,Httpclient,FileUpload,StringUtils,
Collection是集合类的上级接口,继承与他有关的接口主要有List和Set
Collection ├List │├LinkedList │├ArrayList │└Vector │ └Stack └Set
Map ├Hashtable ├HashMap └WeakHashMap
Collections是针对集合类的一个帮助类,他提供一系列静态方法实现对各种集合的搜索、排序、线程安全等操作 稍微举个例子: java代码 public static void main(String args[]) { //注意List是实现Collection接口的 List list = new ArrayList(); double array[] = { 112, 111, 23, 456, 231 }; for (int i = 0; i < array.length; i++) { list.add(new Double(array[i])); } Collections.sort(list); //把list按从小到大排序 for (int i = 0; i < array.length; i++) { System.out.println(list.get(i)); } // 结果:23.0 111.0 112.0 231.0 456.0 }
然后还有混排(Shuffling)、反转(Reverse)、替换所有的元素(fill)、拷贝(copy)、返回Collections中最小元素(min)、返回Collections中最大元素(max)、返回指定源列表中最后一次出现指定目标列表的起始位置(lastIndexOfSubList)、返回指定源列表中第一次出现指定目标列表的起始位置(IndexOfSubList)、根据指定的距离循环移动指定列表中的元素(Rotate)
多线程的使用场景、注意的事项以及实现方式
使用场景
-
1.同时启动多个任务,需要多线程
-
2.想提高系统资源利用率
-
3.需要异步操作的时候使用
注意事项
-
1、线程使用中要注意,如何控制线程的调度和阻塞,例如利用事件的触发来控制线程的调度和阻塞,也有用消息来控制的。
-
2、线程中如果用到公共资源,一定要考虑公共资源的线程安全性。一般用LOCK锁机制来控制线程安全性。一定要保证不要有死锁机制。
-
3、合理使用sleep,何时Sleep,Sleep的大小要根据具体项目,做出合理安排。一般原则非阻塞状态下每个循环都要有SLeep,这样保证减少线程对CPU的抢夺。每次线程的就绪和激活都会占用一定得资源,如果线程体如果有多个循环,多处使用SLEEP将导致性能的下降。
-
4、线程的终止一般要使线程体在完成一件工作的情况下终止,一般不要直接使用抛出线程异常的方式终止线程。
-
5、线程的优先级一定根据程序的需要要有个整体的规划。
实现方式: 1、实现Thread类。 开启的线程中数据是不共享的,每一个线程都有自己独立的数据副本 2、继承Runnable接口 数据是共享的,所有线程共享一个数据副本 3、使用Execute框架
public class MyThread extends Thread {
//定义总票数量
private int total = 5;
//定义票的编号
private int ticketNO = total + 1;
//定义一个线程同步的对象
private Object object = new Object();
private String name;
public MyThread(String name) {
this.name = name;
}
@Override
public void run() {
while (true) {
//使用同步锁机制
synchronized (this.object) {
if (this.total > 0) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
String ticketMsg = Thread.currentThread().getName()+this.name + "***输出第:" + (this.ticketNO - this.total);
System.out.println(ticketMsg);
this.total--;
} else {
System.out.println("票已售完,敬请等待!");
System.exit(0);
}
}
}
}
public static void main(String [] args) {
MyThread myThread1 = new MyThread("售票窗口001");
MyThread myThread2 = new MyThread("售票窗口002");
myThread1.start();
myThread2.start();
}
//输出
Thread-0售票窗口001***输出第:1
Thread-1售票窗口002***输出第:1
Thread-0售票窗口001***输出第:2
Thread-1售票窗口002***输出第:2
Thread-1售票窗口002***输出第:3
Thread-0售票窗口001***输出第:3
Thread-1售票窗口002***输出第:4
Thread-0售票窗口001***输出第:4
Thread-1售票窗口002***输出第:5
票已售完,敬请等待!
Thread-0售票窗口001***输出第:5
票已售完,敬请等待!public class MyRunnable implements Runnable {
//定义票的总数
private int total = 10;
//定义票的编号
private int no = total+1;
//定义一个线程同步对象
private Object obj = new Object();
@Override
public void run() {
while(true){
//同步锁
synchronized(this.obj){
if(this.total > 0){
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
String msg = Thread.currentThread().getName()+" 售出第 "+(this.no -this.total) +" 张票";
System.out.println(msg);
this.total--;
}else{
System.out.println("票已售完,请下次再来!");
System.exit(0);
}
}
}
}
public static void main(String [] args) {
MyRunnable myRunnable = new MyRunnable();
System.out.println(myRunnable);
Thread thread1 = new Thread(myRunnable, "售票窗口001");
Thread thread2 = new Thread(myRunnable, "售票窗口002");
Thread thread3 = new Thread(myRunnable, "售票窗口003");
thread1.start();
thread2.start();
thread3.start();
}
//输出
售票窗口001 售出第 1 张票
售票窗口001 售出第 2 张票
售票窗口001 售出第 3 张票
售票窗口001 售出第 4 张票
售票窗口001 售出第 5 张票
售票窗口003 售出第 6 张票
售票窗口003 售出第 7 张票
售票窗口003 售出第 8 张票
售票窗口003 售出第 9 张票
售票窗口002 售出第 10 张票
票已售完,请下次再来!总结:实现Runnable接口比继承Thread类所具有的优势: 1):适合多个相同的程序代码的线程去处理同一个资源 2):可以避免java中的单继承的限制 3):增加程序的健壮性,代码可以被多个线程共享,代码和数据独立
ThreadLocal的实现原理
-
每个Thread的对象都有一个ThreadLocalMap,当创建一个ThreadLocal的时候,就会将该ThreadLocal对象添加到该Map中,其中键就是ThreadLocal,值可以是任意类型。
在该类中,我觉得最重要的方法就是两个:set()和get()方法。当调用ThreadLocal的get()方法的时候,会先找到当前线程的ThreadLocalMap,然后再找到对应的值。set()方法也是一样。
-
ThreadLocal底层实现是一个Map结构的表,key是Thread.currentThread(),而Value则是我们想要保存的对象
ThreadLocal的原理与实例:
概述: 线程同步机制是多个线程共享同一个变量,而ThreadLocal是为每个线程创建一个单独的变量副本,每个线程都可以改变自己的变量副本而不影响其它线程所对应的副本。
ThreadLocal定义了四个方法:
-
get():返回此线程局部变量当前副本中的值
-
set(T value):将线程局部变量当前副本中的值设置为指定值
-
initialValue():返回此线程局部变量当前副本中的初始值
-
remove():移除此线程局部变量当前副本中的值
-
ThreadLocal还有一个特别重要的静态内部类ThreadLocalMap,该类才是实现线程隔离机制的关键。get()、set()、remove()都是基于该内部类进行操作,ThreadLocalMap用键值对方式存储每个线程变量的副本,key为当前的ThreadLocal对象,value为对应线程的变量副本。 试想,每个线程都有自己的ThreadLocal对象,也就是都有自己的ThreadLocalMap,对自己的ThreadLocalMap操作,当然是互不影响的了,这就不存在线程安全问题了,所以ThreadLocal是以空间来交换安全性的解决思路。
//假设每个线程都需要一个计数值记录自己做某件事做了多少次,各线程运行时都需要改变自己的计数值而且相互不影
//响,那么ThreadLocal就是很好的选择,这里ThreadLocal里保存的当前线程的局部变量的副本就是这个计数值。
public class SeqCount {
//初始化ThreadLocal内部的计数值
private static ThreadLocal seqCount = new ThreadLocal() {
@Override
protected Integer initialValue() {
return 0;
}
};
//计数器加一
public int nextSeq() {
seqCount.set(seqCount.get() + 1);
return seqCount.get();
}
public static void main(String[] args) {
SeqCount seqCount = new SeqCount();
SeqThread seqThread1 = new SeqThread(seqCount);
SeqThread seqThread2 = new SeqThread(seqCount);
SeqThread seqThread3 = new SeqThread(seqCount);
seqThread1.start();
seqThread2.start();
seqThread3.start();
}
public static class SeqThread extends Thread {
private SeqCount seqCount;
public SeqThread(SeqCount seqCount) {
this.seqCount = seqCount;
}
@Override
public void run() {
for (int i = 0; i < 3; i++) {
System.out.println(Thread.currentThread().getName() + "---seqCount:" + seqCount.nextSeq());
}
}
}
}
//输出
Thread-0---seqCount:1
Thread-0---seqCount:2
Thread-0---seqCount:3
Thread-1---seqCount:1
Thread-2---seqCount:1
Thread-2---seqCount:2
Thread-1---seqCount:2
Thread-2---seqCount:3
Thread-1---seqCount:3
//解决SimpleDateFormat的线程安全
//我们知道SimpleDateFormat在多线程下是存在线程安全问题的,那么将SimpleDateFormat作为每个线程的局部变量的副本就是每个线程都拥有自己的SimpleDateFormat,就不存在线程安全问题了。
public class SimpleDateFormatDemo {
public static final String DATE_FORMAT = "yyyy-MM-dd HH:mm:ss";
private static ThreadLocal threadLocal = new ThreadLocal<>();
/**
* 获取线程的变量副本,如果不覆盖initialValue方法,第一次get将返回null,
* 故需要创建一个DateFormat,放入threadLocal中
*
* @return
*/
public DateFormat getDateFormat() {
DateFormat df = threadLocal.get();
if (df == null) {
df = new SimpleDateFormat(DATE_FORMAT);
threadLocal.set(df);
}
return df;
}
public static void main(String[] args) {
SimpleDateFormatDemo simpleDateFormatDemo = new SimpleDateFormatDemo();
Myrunnable myrunnable1 = new Myrunnable(simpleDateFormatDemo);
Myrunnable myrunnable2 = new Myrunnable(simpleDateFormatDemo);
Myrunnable myrunnable3 = new Myrunnable(simpleDateFormatDemo);
Thread thread1 = new Thread(myrunnable1);
Thread thread2 = new Thread(myrunnable2);
Thread thread3 = new Thread(myrunnable3);
thread1.start();
thread2.start();
thread3.start();
}
public static class Myrunnable implements Runnable {
private SimpleDateFormatDemo simpleDateFormatDemo;
public Myrunnable(SimpleDateFormatDemo dateFormatDemo) {
this.simpleDateFormatDemo = dateFormatDemo;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "当前时间:" + simpleDateFormatDemo.getDateFormat().format(new Date()));
}
}
总结: 1、ThreadLocal不是用来解决共享变量的问题,也不是协调线程同步,他是为了方便各线程管理自己的状态而引用的一个机制。 2、每个ThreadLocal内部都有一个ThreadLocalMap,他保存的key是ThreadLocal的实例,他的值是当前线程的局部变量的副本的值。
java中的动态代理:
JDK动态代理和CGLIB动态代理字节码生成的区别: 1、静态代理是通过在代码中显式定义一个业务实现类一个代理,在代理类中对同名的业务方法进行包装,用户通过代理类调用被包装过的业务方法; 2、JDK动态代理是通过接口中的方法名,在动态生成的代理类中调用业务实现类的同名方法; 3、CGlib动态代理是通过继承业务类,生成的动态代理类是业务类的子类,通过重写业务方法进行代理;
JDK动态代理: jdk动态代理所用到的代理类必须实现接口,通过反射的机制动态的创建一个字节码文件,然后通过此代理类对象对相应的方法进行调用。 注意: 如果业务类中创建了接口中没有的方法,则动态代理不能够对相应的方法进行调用增强。
CGLIB动态代理: CGLIB动态代理通过对原有的业务类进行实现而生成一个子类,覆盖其中的业务方法实现代理。因为使用的是继承所以不能对final修饰的类进行代理。
具体案例:
public interface UserMapper {
public void addUser(String id, String password);
public void delUser(String id);
}
public class UserManagerImpl implements UserMapper {
@Override
public String toString() {
return "UserManagerImpl{}";
}
@Override
public void addUser(String id, String password) {
System.out.println("addUser开始运行,接收到的参数数据为:id=" + id + ":password=" + password);
}
@Override
public void delUser(String id) {
System.out.println("addUser开始运行,接收到的参数数据为:id=" + id);
}
}
//---------------------JDK动态代理--------------------
/**
* JDK动态代理所用到的代理类在程序调用到代理类对象时才由JVM真正创建,JVM根据传进来的 业务实现类对象 以及 方法名 ,动态地
* 创建了一个代理类的class文件并被字节码引擎执行,然后通过该代理类对象进行方法调用。我们需要做的,只需指定代理类的预处理、
* 调用后操作即可。
*
* JDK动态代理的代理对象在创建时,需要使用业务实现类所实现的接口作为参数(因为在后面代理方法时需要根据接口内的方法名进行调用)。
* 如果业务实现类是没有实现接口而是直接定义业务方法的话,就无法使用JDK动态代理了。并且,如果业务实现类中新增了接口中没有的方法,
* 这些方法是无法被代理的(因为无法被调用)。
**/
public class JDKProxy implements InvocationHandler {
//需要代理的目标对象
private Object target;
//获取代理对象
private Object getJdkProxy(Object targetObject) {
this.target = targetObject;
//通过反射机制,创建一个代理类对象实例并返回。用户进行方法调用时使用
//创建代理对象时,需要传递该业务类的类加载器(用来获取业务实现类的元数据,在包装方法是调用真正的业务方法)、接口、handler实现类
Object object = Proxy.newProxyInstance(targetObject.getClass().getClassLoader(), targetObject.getClass().getInterfaces(), this);
return object;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("JDK动态代理开始!");
Object invoke = method.invoke(target, args);
System.out.println("JDK动态代理结束了!");
return invoke;
}
public static void main(String[] args) {
JDKProxy jdkProxy = new JDKProxy();
UserMapper userMapper = (UserMapper) jdkProxy.getJdkProxy(new UserManagerImpl());
userMapper.addUser("1001", "Jack");
}
}
JDK动态代理开始!
addUser开始运行,接收到的参数数据为:id=1001:password=Jack
JDK动态代理结束了!
//-----------------------CGLIB动态代理--------------------------------
public class CglibProxyDemo implements MethodInterceptor {
//业务类对象,供代理方法中进行真正的业务方法调用
private Object target;
//获取一个动态代理对象
public Object getInstance(Object target) {
//给业务对象赋值
this.target = target;
//创建一个对象的加强器,用来创建动态代理类
Enhancer enhancer = new Enhancer();
//为加强器指定要加强的业务类
enhancer.setSuperclass(this.target.getClass());
//设置回调:对于代理类上所有方法的调用,都会调用CallBack,而Callback则需要实现intercept()方法进行拦
enhancer.setCallback(this);
//创建动态代理类对象并且返回
return enhancer.create();
}
@Override
public Object intercept(Object object, Method method, Object[] args, MethodProxy methodProxy) throws Throwable {
System.out.println("***********动态代理执行前**********");
methodProxy.invokeSuper(object, args);
if (args.length == 2) {
System.out.println("这是一个双参数的方法");
} else {
System.out.println("这是一个单个参数的方法");
}
System.out.println("***********动态代理执行后**********");
return "运行成功";
}
/**
* 创建业务类和代理类对象,然后通过 代理类对象.getInstance(业务类对象)
* 返回一个动态代理类对象(它是业务类的子类,可以用业务类引用指向它)。
* 最后通过动态代理类对象进行方法调用。
* @param args
*/
public static void main(String[] args) {
UserManagerImpl userManagerImpl = new UserManagerImpl();
CglibProxyDemo cglibProxy = new CglibProxyDemo();
UserManagerImpl cglibProxyInstance = (UserManagerImpl) cglibProxy.getInstance(userManagerImpl);
cglibProxyInstance.delUser("1002");
}
}
***********动态代理执行前**********
addUser开始运行,接收到的参数数据为:id=1002
这是一个单个参数的方法
***********动态代理执行后**********java中各个代码块执行顺序:
public class Demo {
private String message = init_message();
private static String msg = init_msg();
private String init_message() {
System.out.println("普通成员赋值!");
return "目标类的普通成员的属性数据";
}
private static String init_msg() {
System.out.println("为静态静态成员赋值!");
return "目标类的静态成员属性";
}
static {
System.out.println("这是一个静态的代码块!");
}
{
System.out.println("这是一个代普通码块!");
}
public Demo(String message) {
this.message = message;
System.out.println("这是一个有参数的构造函数");
}
public Demo() {
System.out.println("这是一个无参数的构造函数");
}
public static void main(String[] args) {
Demo demo = new Demo();
}
}
为静态静态成员赋值!
这是一个静态的代码块!
普通成员赋值!
这是一个代普通码块!
这是一个无参数的构造函数由上述案例可以看出执行的顺序为: 类按照 静态成员 --> 静态代码块 --> 普通成员 --> 普通代码块 --> 构造方法 的顺序来加载.
volatile关键字:
java中的volatile可以被看作是synchronized的一种轻度实现。可以保证线程中的变量在多线程的情况下同步。 Volatile与synchronized的不同之处:
1.volatile是线程同步的轻量级实现,所以volatile的性能要比synchronize好;volatile只能用于修饰变量,synchronize可以用于修饰方法、代码块。随着jdk技术的发展,synchronize在执行效率上会得到较大提升,所以synchronize在项目过程中还是较为常见的;
2.多线程访问volatile不会发生阻塞;而synchronize会发生阻塞;
3.volatile能保证变量在私有内存和主内存间的同步,但不能保证变量的原子性;synchronize可以保证变量原子性;
4.volatile是变量在多线程之间的可见性;synchronize是多线程之间访问资源的同步性;
5.对于volatile修饰的变量,可以解决变量读时可见性问题,无法保证原子性。对于多线程访问同一个实例变量还是需要加锁同步。
原子性、有序性、可见性三大性质总结:
原子性: 原子性是指一个操作是不可中断的,要么全部执行成功要么全部执行失败,有着“同生共死”的感觉。及时在多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程所干扰。 synchronized满足原子性 .
有序性: synchronized语义表示锁在同一时刻只能由一个线程进行获取,当锁被占用后,其他线程只能等待。因此,synchronized语义就要求线程在访问读写共享变量时只能“串行”执行,因此synchronized具有有序性。
可见性: 可见性是指当一个线程修改了共享变量后,其他线程能够立即得知这个修改。通过之前对synchronzed内存语义进行了分析,当线程获取锁时会从主内存中获取共享变量的最新值,释放锁的时候会将共享变量同步到主内存中。从而,synchronized具有可见性。 synchronized: 具有原子性,有序性和可见性; volatile:具有有序性和可见性 ;
接口与抽象类的区别:
抽象类: 含有abstract修饰符的class即为抽象类,abstract 类不能创建实例对象。含有abstract方法的类必须定义为abstract class,abstract class类中的方法不必是抽象的。abstract class类中定义抽象方法必须在具体(Concrete)子类中实现,所以,不能有抽象构造方法或抽象静态方法。如果子类没有实现抽象父类中的所有抽象方法,那么子类也必须定义为abstract类型。
接口(interface): 可以说成是抽象类的一种特例,接口中的所有方法都必须是抽象的。接口中的方法定义默认为public abstract类型,接口中的成员变量类型默认为public static final。
两者的区别:
-
抽象类可以有构造方法,接口中不能有构造方法。
-
抽象类中可以有普通成员变量,接口中没有普通成员变量
-
抽象类中可以包含非抽象的普通方法,接口中的所有方法必须都是抽象的,不能有非抽象的普通方法。
-
抽象类中的抽象方法的访问类型可以是public,protected和(默认类型,虽然eclipse下不报错,但应该也不行),但接口中的抽象方法只能是public类型的,并且默认即为public abstract类型。
-
抽象类中可以包含静态方法,接口中不能包含静态方法
-
抽象类和接口中都可以包含静态成员变量,抽象类中的静态成员变量的访问类型可以任意,但接口中定义的变量只能是public static final类型,并且默认即为public static final类型。
-
一个类可以实现多个接口,但只能继承一个抽象类。
具体的应用场景: 接口更多的是在系统架构设计方法发挥作用,主要用于定义模块之间的通信契约 。 抽象类主要的是关注于系统的具体的业务代码实现,可以实现系统的代码重用。 案例: 模板方法设计模式是抽象类的一个典型应用,假设某个项目的所有Servlet类都要用相同的方式进行权限判断、记录访问日志和处理异常,那么就可以定义一个抽象的基类,让所有的Servlet都继承这个抽象基类,在抽象基类的service方法中完成权限判断、记录访问日志和处理异常的代码,在各个子类中只是完成各自的业务逻辑代码。
public abstract class BaseServlet extends HttpServlet{
public final void service(HttpServletRequest request, HttpServletResponse response) throws IOExcetion,ServletException {
//记录访问日志 抽象类掌控全局实现
//进行权限判断 抽象类掌控全局实现
if(具有权限){
try{
doService(request,response);
}
catch(Excetpion e) {
记录异常信息
}
}
}
protected abstract void doService(HttpServletRequest request, HttpServletResponse response) throws IOExcetion,ServletException;
//注意访问权限定义成protected,显得既专业,又严谨,因为它是专门给子类用的
}
//具体的业务实现类
public class MyServlet1 extends BaseServlet
{
protected void doService(HttpServletRequest request, HttpServletResponse response) throws IOExcetion,ServletException
{
本Servlet只处理的具体业务逻辑代码
}
}
父类方法中间的某段代码不确定,留给子类干,就用模板方法设计模式。 备注: 这道题的思路是先从总体解释抽象类和接口的基本概念,然后再比较两者的语法细节,最后再说两者的应用区别。比较两者语法细节区别的条理是:先从一个类中的构造方法、普通成员变量和方法(包括抽象方法),静态变量和方法,继承性等6个方面逐一去比较回答,接着从第三者继承的角度的回答,特别是最后用了一个典型的例子来展现自己深厚的技术功底。
java中的正则表达式:
正则表达式中的匹配符: 字符簇:表示一个匹配的范围. 字符簇 含义 [a-z] 匹配字符a到字符z之间的任一字符 [A-Z] 匹配字符A到字符Z之间的任一字符 [0-9] 匹配数字0到9之间的任一数字 [0-9a-z] 匹配数字0到9或字符a到字符z之间的任一字符 [0-9a-zA-Z] 匹配数字0到9或字符a到字符z或字符A到字符Z之间的任一字符 [abcd] 匹配字符a或字符b或字符c或字符d [1234] 匹配数字1或数字2或数字3或数字
在字符族中可以使用一个^表示取反的含义: 字符簇 含义 a-z 匹配除字符a到字符z以外的任一字符 0-9 匹配除数字0到9以外的任一字符 abcd 匹配除a、b、c、d以外的任一字符
元字符: 字符簇 含义 \d 匹配一个数字字符,与使用[0-9]等价 \D 匹配一个非数字字符,还可以使 0-9 \w 匹配包括下划线的任何字母数字下划线字符,还可以使用 [0-9a-zA-Z_] \W 匹配任何非字母数字下划线字符,还可以使用 \w \s 匹配任何空白字符 \S 匹配任何非空白字符,还可以使用\s . 匹配除 "\n" (换行符) 之外的任何单个字符 [\u4e00-\u9fa5] 匹配中文 字符
匹配的限定符:决定匹配多少个:
| * | 匹配前面的子表达式零次或多次,0到多 |
|---|---|
| + | 匹配前面的子表达式一次或多次,1到多 |
| ? | 匹配前面的子表达式零次或一次,0或1 |
| {n} | 匹配确定的 n 次 |
| {n,} | 至少匹配 n 次 |
| {n,m} | 最少匹配 n 次且最多匹配 m 次 |
"=="与"equals"的区别?
1、对于==,比较的是值是否相等 如果作用于基本数据类型的变量,则直接比较其存储的 “值”是否相等; 如果作用于引用类型的变量,则比较的是所指向的对象的地址 2、对于equals方法,注意:equals方法不能作用于基本数据类型的变量,equals继承Object类,比较的是是否是同一个对象 如果没有对equals方法进行重写,则比较的是引用类型的变量所指向的对象的地址; 诸如String、Date等类对equals方法进行了重写的话,比较的是所指向的对象的内容。
图解两者之间的关系:
代码测试图解: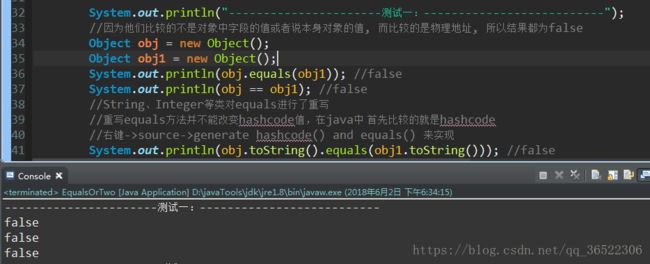
java中String常用的函数有哪些?
构造函数: public String():创建String对象 public String(byte[] bytes):把字节数组转成字符串。 public String(byte[] bytes,int index,int length):把字节数组中的一部分转成字符串 public String(char[] value):把字符数组转成字符串 public String(char[] value,int index,int count):把字符数组的一部分转成字符串 public String(String original):把字符串转成字符串
String类的判断功能: boolean equals(Object obj):比较字符串的内容是否相同,严格区分大小写 boolean equalsIgnoreCase(String str):比较字符串的内容是否相同,不考虑大小写 boolean contains(String str):判断是否包含指定的小串 boolean startsWith(String str):判断是否以指定的字符串开头 boolean endsWith(String str):判断是否以指定的字符串结尾 boolean isEmpty():判断字符串的内容是否为空
String类的获取功能: int length():返回字符串的长度。字符的个数。 char charAt(int index):返回字符串中指定位置的字符。 int indexOf(int ch):返回指定字符在字符串中第一次出现的位置 int indexOf(String str):返回指定字符串在字符串中第一次出现的位置 int indexOf(int ch,int fromIndex):返回指定字符从指定位置开始在字符串中第一次出现的位置 int indexOf(String str,int fromIndex):返回指定字符串从指定位置开始在字符串中第一次出现的位置 String substring(int start):返回从指定位置开始到末尾的子串 String substring(int start,int end):返回从指定位置开始到指定位置结束的子串----注意左包右不包
String的转换功能: byte[] getBytes():把字符串转换为字节数组 char[] toCharArray():把字符串转换为字符数组 static String valueOf(char[] chs):把字符数组转成字符串 static String valueOf(int i):把int类型的数据转成字符串
把任意类型转换为字符串的方法。 String toLowerCase():把字符串转小写 String toUpperCase():把字符串转大写 String concat(String str):字符串的连接
替换功能: String replace(char old,char new) String replace(String old,String new)
去除字符串两空格: String trim()
按字典顺序比较两个字符串 a-z int compareTo(String str) int compareToIgnoreCase(String str)
//字符串相等的时候 返回0
//两个字符串 长度相等时 一位一位比较 长度不相等 返回的是长度的差值
String string1 = "asd";
String string2 = "asd";
int number = string1.compareTo(string2);
System.out.println(number); //输出结果:0
String string3 = "asdf";
String string4 = "asd";
int number1 = string3.compareTo(string4);
System.out.println(number1); //输出结果为:1
String string5 = "as";
String string6 = "asd";
int number2 = string5.compareTo(string6);
System.out.println(number2); //输出结果:-1
String string7 = "asd";
String string8 = "asf";
int number3 = string7.compareTo(string8);
System.out.println(number3); //输出结果:-2 两者的ASCII值相减
char c = '轩';
System.out.println((int)c); //输出结果: 36713 Unicode码 ASCII码是Unicode码的一部分java中的final,finally,final, finally, finalize之间的区别 ?
1.简单区别: final用于声明属性,方法和类,分别表示属性不可交变,方法不可覆盖,类不可继承。 finally是异常处理语句结构的一部分,表示总是执行。 finalize是Object类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,供垃圾收集时的其他资源回收,例如关闭文件等。
2.深入解读 虽然这三个单词在Java中都是关键字,但是本质上没有任何关联,只是长得像而已。 final: Java中关键字,修饰符。 如果一个类被声明为final,则意味着该类不能被继承,无法派生出新的子类。所以,一个类不能同时被abstract和final修饰。如果将变量或者方法声明为final,可以保证变量和方法在以后的使用中,不会被修改。被final修饰的变量必须在声明时赋初值,在以后的引用中只能读取,不能修改。被final修饰的方法只能使用,不能被重写。
finally: 表示一种异常处理机制。 finally是对Java异常处理模型的最佳补充。finally结构使代码总会执行,而不管无异常发生。使用finally可以维护对象的内部状态,并可以清理非内存资源。特别是在关闭数据库连接这方面,如果程序员把数据库连接的close()方法放到finally中,就会大大降低程序出错的几率。
finalize: Java中的Object类的一个方法名。 Java中,垃圾收集器在将对象从内存中清除出去前,需要使用finalize()方法做一些必要的清理工作。这个方法是由垃圾收集器在确定该对象没有被引用时,对该对象调用finalize()方法。因为该方法是在Object类中定义的,因此所有的类都继承了该方法。子类可以覆盖该方法来整理系统资源或者执行其他的清理工作。
重载和重写的区别?
override(重写)
-
方法名、参数、返回值相同。
-
子类方法不能缩小父类方法的访问权限。
-
子类方法不能抛出比父类方法更多的异常(但子类方法可以不抛出异常)。
-
存在于父类和子类之间。
-
方法被定义为final不能被重写。
overload(重载)
-
方法名相同。
-
参数类型、个数、顺序至少有一个不相同。
-
不能重载只有返回值不同的方法名。
-
存在于父类和子类、同类中。
session和cookie 区别?
1、存储的位置大小以及存储的范围: cookie 在服务端创建,保存在于客户端,在我们本地磁盘的临时文件中; session存在于服务器的内存中,一个session域对象为一个用户浏览器服务。 Cookie有大小限制,单个的cookie存储在4k左右,浏览器在存cookie的个数也有限制一般在20左右。Session理论来讲是没有大小限制的,即使有也和服务器的内存大小有关。 Cookie与session都是一键值对的方式存储数据,但是cookie只能存储字符串类型的数据,而session就没有此方面限制。 2、安全性 cookie是以明文的方式存放在客户端的,安全性低,可以通过一个加密算法进行加密后存放; session存放于服务器的内存中,所以安全性好。 3、网络传输量 cookie的使用需要客户端与服务器进行交互,造成一定的流量传输; session本身存放于服务器,使用时不会有传送流量消耗。 4、生命周期 cookie的生命周期是累计的,同时我们可以通过setMaxAge 函数来设置cookie的存活时间,若设置cookie的存活时间为20分钟,设置后就开始计时,20分钟后,cookie生命周期结束,如果没有设置cookie的存活时间,当我们关闭浏览器时,cookie就自动消亡了; session的生命周期是间隔的,Tomcat中的session默认失效时间为20分钟。 从创建时,开始计时如在20分钟,没有访问session,那么session生命周期被销毁。但是,如果在20分钟内(如在第19分钟时)访问过session,那么,将重新计算session的生命周期。关机会造成session生命周期的结束,但是对cookie没有影响。同时关闭tomcat、reload web应用、session时间到、调用session中的invalidate方法 5、访问范围 cookie为多个用户浏览器共享; session为一个用户浏览器独享。
java中的static关键字:
概述: static称为静态的,其可以用来修饰类、成员变量、方法、内部类等。
static修饰类: 在我们使用static修饰一个内部类,我们可以直接使用"类.内部类"进行内部类的实例化操作。但是普通的类不能通过static修饰。
static修饰变量: 按照是否静态的对类成员变量进行分类可分两种:一种是被static修饰的变量,叫静态变量或类变量;另一种是没有被static修饰的变量,叫实例变量。静态变量与实例变量的区别主要是:静态变量被所有的对象所共享,在内存中只有一个副本,它当且仅当在类初次加载时会被初始化。而实例变量是对象所拥有的,在创建对象的时候被初始化,存在多个副本,各个对象拥有的副本互不影响。
static修饰方法: static方法也叫静态方法,也可以直接使用“类.方法()”来直接调用。但是需要注意一下几点:一是静态方法中不能使用this和super关键字;二是静态方法中不能使用非静态成员变量,也不能调用非静态方法;三是静态方法与静态变量一样都是独立于任何实例,所以静态方法不能使用abstract修饰,即static方法不能为抽象方法。
static修饰代码块: 对于静态块的使用,在我初学Java时,我是拒绝使用的,总觉得这样用不好。但是,当我在实习做项目时,通过各种调试工具分析代码时,突然发现了静态块的妙用。首先,静态块顾名思义就是使用static{}的一段代码块。静态块是在JVM加载类的时候执行的,并且只会执行一次。由于这个特性,所以在一些场景非常好用。我在项目中遇到的过的使用场景主要有在实例化一个日志对象时,使用static块;然后就是实例化一些在类中常用但不需要多次实例化的变量等。
static关键字会改变类中成员的访问权限吗? 在Java中能够影响到访问权限的只有private、public、protected(包括包访问权限)这几个关键字。static并不能改变类成员的访问权限。
能通过this访问静态成员变量吗?
public class PersonTest {
public static int Value = 1001;
public void printValue() {
int Value = 101;
System.out.println(this.Value);
}
public static void main(String[] args) {
new PersonTest().printValue();
}
}
输出:1001this代表什么?this代表当前对象,那么通过new Main()来调用printValue的话,当前对象就是通过new Main()生成的对象。而static变量是被对象所享有的,因此在printValue中的this.value的值毫无疑问是33。在printValue方法内部的value是局部变量,根本不可能与this关联,所以输出结果是33。在这里永远要记住一点:静态成员变量虽然独立于对象,但是不代表不可以通过对象去访问,所有的静态方法和静态变量都可以通过对象访问(只要访问权限足够)。
static能作用于局部变量么? static是不允许用来修饰局部变量。不要问为什么,这是Java语法的规定.
经典案例:
public class Test extends Base{
static{
System.out.println("test static");
}
public Test(){
System.out.println("test constructor");
}
public static void main(String[] args) {
new Test();
}
}
class Base{
static{
System.out.println("base static");
}
public Base(){
System.out.println("base constructor");
}
}
//输出
base static
test static
base constructor
test constructor流程分析:分析下这段代码的执行过程:
-
找到main方法入口,main方法是程序入口,但在执行main方法之前,要先加载Test类
-
加载Test类的时候,发现Test类继承Base类,于是先去加载Base类
-
加载Base类的时候,发现Base类有static块,而是先执行static块,输出base static结果
-
Base类加载完成后,再去加载Test类,发现Test类也有static块,而是执行Test类中的static块,输出test static结果
-
Base类和Test类加载完成后,然后执行main方法中的new Test(),调用子类构造器之前会先调用父类构造器
-
调用父类构造器,输出base constructor结果
-
然后再调用子类构造器,输出test constructor结果
public class Test {
Person person = new Person("Test");
static{
System.out.println("test static");
}
public Test() {
System.out.println("test constructor");
}
public static void main(String[] args) {
new MyClass();
}
}
class Person{
static{
System.out.println("person static");
}
public Person(String str) {
System.out.println("person "+str);
}
}
class MyClass extends Test {
Person person = new Person("MyClass");
static{
System.out.println("myclass static");
}
public MyClass() {
System.out.println("myclass constructor");
}
}
输出:
test static
myclass static
person static
person MyClass
myclass constructor过程分析:
-
找到main方法入口,main方法是程序入口,但在执行main方法之前,要先加载Test类
-
加载Test类的时候,发现Test类有static块,而是先执行static块,输出test static结果
-
然后执行new MyClass(),执行此代码之前,先加载MyClass类,发现MyClass类继承Test类,而是要先加载Test类,Test类之前已加载
-
加载MyClass类,发现MyClass类有static块,而是先执行static块,输出myclass static结果
-
然后调用MyClass类的构造器生成对象,在生成对象前,需要先初始化父类Test的成员变量,而是执行Person person = new Person("Test")代码,发现Person类没有加载
-
加载Person类,发现Person类有static块,而是先执行static块,输出person static结果
-
接着执行Person构造器,输出person Test结果
-
然后调用父类Test构造器,输出test constructor结果,这样就完成了父类Test的初始化了
-
再初始化MyClass类成员变量,执行Person构造器,输出person MyClass结果
-
最后调用MyClass类构造器,输出myclass constructor结果,这样就完成了MyClass类的初始化了
常见的算法:
java中的排序算法:
JAVA框架部分:
Spring框架的AOP、IOC、DI讲解:
IOC: IOC(inversion of Control),控制反转。使用IOC的思想意味着你将设计好的对象交给容器控制,而不是传统的在你的对象内部直接控制。IOC即是将对像的控制转给了spring容器;以前我们使用对像是自己new一个;然后再调对应的方法与属性;这叫主动控制;IOC即将生成对像的控制权交给了容器;IOC也是一种思想;以前对像之间相互调用;之间就存在了耦合,当代码复杂后耦合性就更强了;容易造成迁一发而动全身;使用了IOC容器后;各个对像之间都通过ioc进行运行;减少了耦合; DI: 为什么也叫依赖注入;即通过容器将该对像生成后注入到对像中;使用有依赖关系的对像是通过IOC容器注入这种依赖关系的;
为什么要控制反转呢,谁在控制谁呢,反转了什么东西呢?
-
谁在控制谁? 一般来讲,我们直接new一个对象,是我们运行的这个程序去主动的创建依赖对象;但是IoC时会有一个IoC容器来负责这些对象的创建。这个时候IoC容器控制了对象,控制了外部资源获取。
-
反转了什么呢?在传统的程序里面,我们在对象中主动控制去直接获取依赖对象,而现在,这个过程反了过来。
依赖(在A类里面创建了B类的实例,这样A依赖于B)
AOP: AOP即面向切面:AOP技术利用一种称为“横切”的技术,解剖封装的对象内部,并将那些影响了多个类的公共行为封装到一个可重用模块,这样就能减少系统的重复代码,降低模块间的耦合度,并有利于未来的可操作性和可维护性。AOP把软件系统分为两个部分:核心关注点和横切关注点。业务处理的主要流程是核心关注点,与之关系不大的部分是横切关注点。横切关注点的一个特点是,他们经常发生在核心关注点的多处,而各处都基本相似。比如权限认证、日志、事务处理。 简言:把java对象进行横切; 即在对像执行功能时进行了插入;设置了切点;在对象执行操作前,后分别做点啥事;但又不影响对像自己的功能执行; 具体业务实现通过JDK动态代理和Cglib动态代理实现。jdk动态代理面向接口实现,Cglib动态代理面向类实现。spring会根据具体的需要代理的对象自动在jdk与cglib中进行切换。
Spring框架中的Bean为啥要默认的认为是单例模式
-
1.只在初始化时实例化一次,提高了效率
-
2.减少了内存开销
spring中配置事物的方式
Spring配置文件中关于事务配置总是由三个组成部分,分别是DataSource、TransactionManager和代理机制这三部分,无论哪种配置方式,一般变化的只是代理机制这部分。
1.通过xml配置文件进行配置事务:
2.通过开启注解的方式进行事务的配置
SpringMvc执行的流程
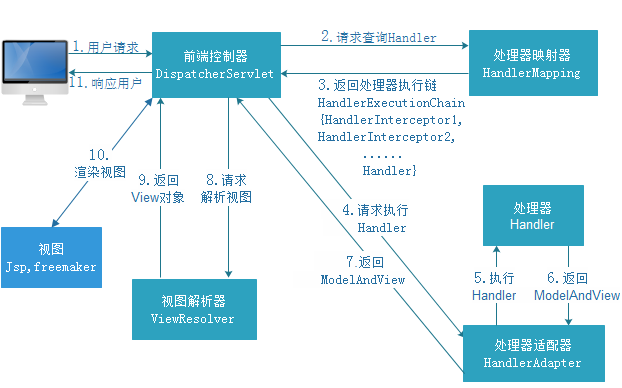
SpringMVC的核心处理流程: 第一步:发起请求到前端控制器(DispatcherServlet) 第二步:前端控制器请求HandlerMapping查找 Handler。 可以根据xml配置、注解进行查找 第三步:处理器映射器HandlerMapping向前端控制器返回Handler 第四步:前端控制器调用处理器适配器去执行Handler 第五步:处理器适配器去执行Handler 第六步:Handler执行完成给适配器返回ModelAndView 第七步:处理器适配器向前端控制器返回ModelAndView,ModelAndView是springmvc框架的一个底层对象,包括Model和view 第八步:前端控制器请求视图解析器去进行视图解析,根据逻辑视图名解析成真正的视图(jsp) 第九步:视图解析器向前端控制器返回View 第十步:前端控制器进行视图渲染,视图渲染将模型数据(在ModelAndView对象中)填充到request域 第十一步:前端控制器向用户响应结果
mybatis中常用的标签
-
insert: 插入标签
-
select:查询标签
-
delete:删除标签
-
update:更新标签
-
Association: 一对一查询的方式
-
if:这个一般用于动态选项的查询,即多值结合查询,选项值有可能为空,因此需要用到动态if标签来判断多个值存在与否。
示例:
-
where:补充相应的where的sql语句,解决了if标签在上面所容易造成错误的问题。更好地简化了where的条件判断。
示例:
-
choose:相当于switch语句,通常与when和otherwise搭配使用。
示例:
-
set:类似于where功能,主要用于sql赋值更新操作。
update admin aname=#{aname}, age=#{age}, password=#{password}, -
foreach:类似于for循环,循环的对象可以是list和数组。 时常用于sql的批量操作,如批量删除,批量添加数据等。
示例:
insert into amdin (aid,aname,pwd,city,address) values (#{item.aid},#{item.aname},#{item.pwd},#{item.city},#{item.address) -
Collection: 一对多查询的方式.
-
mybatis使用mapper接口规则
-
Mapper接口的方法名和mapper.xml中定义的每个sql的Id相同。
-
Mapper.xml文件中的namespace必须是我们mapper接口的路经。
-
Mapper接口的输入参数类型和我们的sql语句中的parameterType的类型一样。
-
Mapper接口的输出的参数类型和我们的sql语句中的resultType的类型相同。
SpringBoot框架
简介:
其实人们把Spring Boot 称为搭建程序的脚手架。其最主要作用就是帮我们快速的构建庞大的spring项目,并且尽可能的减少一切xml配置,做到开箱即用,迅速上手,让我们关注与业务而非配置。
为什么要学习SpringBoot
java一直被人诟病的一点就是臃肿、麻烦。当我们还在辛苦的搭建项目时,可能Python程序员已经把功能写好了,究其原因注意是两点:
-
复杂的配置,
项目各种配置其实是开发时的损耗, 因为在思考 Spring 特性配置和解决业务问题之间需要进行思维切换,所以写配置挤占了写应用程序逻辑的时间。
-
一个是混乱的依赖管理。
项目的依赖管理也是件吃力不讨好的事情。决定项目里要用哪些库就已经够让人头痛的了,你还要知道这些库的哪个版本和其他库不会有冲突,这难题实在太棘手。并且,依赖管理也是一种损耗,添加依赖不是写应用程序代码。一旦选错了依赖的版本,随之而来的不兼容问题毫无疑问会是生产力杀手。
而SpringBoot让这一切成为过去!
Spring Boot 简化了基于Spring的应用开发,只需要“run”就能创建一个独立的、生产级别的Spring应用。Spring Boot为Spring平台及第三方库提供开箱即用的设置(提供默认设置,存放默认配置的包就是启动器),这样我们就可以简单的开始。多数Spring Boot应用只需要很少的Spring配置。
我们可以使用SpringBoot创建java应用,并使用java –jar 启动它,就能得到一个生产级别的web工程。
SpringBoot的特点
Spring Boot 主要目标是:
-
为所有 Spring 的开发者提供一个非常快速的、广泛接受的入门体验
-
开箱即用(启动器starter-其实就是SpringBoot提供的一个jar包),但通过自己设置参数(.properties),即可快速摆脱这种方式。
-
提供了一些大型项目中常见的非功能性特性,如内嵌服务器、安全、指标,健康检测、外部化配置等
-
绝对没有代码生成,也无需 XML 配置。
更多细节,大家可以到官网查看。
Springcloud和Dubbo的区别对比
-
背景
‘Dubbo微服务是有阿里开发的一套微服务治理的框架
SpringCould是由Spring社区开发的一个微服务框架
-
架构完整度
Dubbo只是实现了服务治理,而Spring Cloud下面有17个子项目(可能还会新增)分别覆盖了微服务架构下的方方面面,服务治理只是其中的一个方面,一定程度来说,Dubbo只是Spring Cloud Netflix中的一个子集。
具体的表现如下:
Dubbo Spring Cloud 服务注册中心 Zookeeper Spring Cloud Netflix Eureka 服务调用方式 RPC REST API 服务网关 无 Spring Cloud Netflix Zuul 断路器 不完善 Spring Cloud Netflix Hystrix 分布式配置 无 Spring Cloud Config 服务跟踪 无 Spring Cloud Sleuth 消息总线 无 Spring Cloud Bus 数据流 无 Spring Cloud Stream 批量任务 无 Spring Cloud Task …… …… ……
对比小结:Dubbo实现了服务治理的基础,但是要完成一个完备的微服务架构,还需要在各环节去扩展和完善以保证集群的健康,以减轻开发、测试以及运维各个环节上增加出来的压力,这样才能让各环节人员真正的专注于业务逻辑。而Spring Cloud依然发扬了Spring Source整合一切的作风,以标准化的姿态将一些微服务架构的成熟产品与框架揉为一体,并继承了Spring Boot简单配置、快速开发、轻松部署的特点,让原本复杂的架构工作变得相对容易上手一些(如果您读过我之前关于Spring Cloud的一些核心组件使用的文章,应该能体会这些让人兴奋而激动的特性,传送门)。所以,如果选择Dubbo请务必在各个环节做好整套解决方案的准备,不然很可能随着服务数量的增长,整个团队都将疲于应付各种架构上不足引起的困难。而如果选择Spring Cloud,相对来说每个环节都已经有了对应的组件支持,可能有些也不一定能满足你所有的需求,但是其活跃的社区与高速的迭代进度也会是你可以依靠的强大后盾。
Dubbo简介与学习:
Dubbox 是一个分布式服务框架,其前身是阿里巴巴开源项目Dubbo ,被国内电商及互联网项目中使用,后期阿里巴巴停止了该项目的维护,当当网便在Dubbo基础上进行优化,并继续维护,为了与原有的Dubbo区分,故将其命名为Dubbox。
Dubbox 致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案。简单的说,dubbox就是个服务框架,如果没有分布式的需求,其实是不需要用的,只有在分布式的时候,才有dubbox这样的分布式服务框架的需求,并且本质上是个服务调用的东东,说白了就是个远程服务调用的分布式框架。
Dubbo具体运行原理图如下所示:
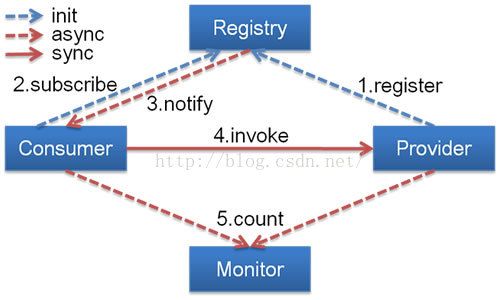
节点角色说明:
Provider: 暴露服务的服务提供方。 Consumer: 调用远程服务的服务消费方。 Registry: 服务注册与发现的注册中心。 Monitor: 统计服务的调用次调和调用时间的监控中心。 Container: 服务运行容器。
调用关系说明: 0.服务容器负责启动,加载,运行服务提供者。 1.服务提供者在启动时,向注册中心注册自己提供的服务。 2.服务消费者在启动时,向注册中心订阅自己所需的服务。 3.注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。 4.服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。 5.服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
微服务总线组件
跨服务间怎样保持事物的一致性
解决方案一:
使用中间表控制微服务之间的事物的一致性,即在A,B两个微服务中,是一个游戏买装备的业务流程,A微服务负责扣除用户的金币,B微服务负责生成相应的订单数据,在我们用户够买装备时,当A服务扣除金币成功时相应的B微服务有以下几处理结果态:①成功②失败③超时 当B微服务发生二或者是三中的一种时即事物不能保持一致性,此时我们可以采用中间表的机制实现微服务间事物的一致性。我们设计一个中间表用来存放用户够买装备的A,B两个微服务的状态,当我们A完成时状态为1B完成时状态为1,B失败时状态为0,我们设置一个定时的轮循查询该表数据,若A,B状态不一致则进行相应的事物控制,则可以实现微服务之间的事物的一致性。
解决方案二:
MQ(非事务消息)
通常情况下,在使用非事务消息支持的MQ产品时,我们很难将业务操作与对MQ的操作放在一个本地事务域中管理。通俗点描述,还是以上述提到的“跨行转账”为例,我们很难保证在扣款完成之后对MQ投递消息的操作就一定能成功。这样一致性似乎很难保证。
先从消息生产者这端来分析,请看伪代码:
根据上述代码及注释,我们来分析下可能的情况:
-
操作数据库成功,向MQ中投递消息也成功,皆大欢喜
-
操作数据库失败,不会向MQ中投递消息了
-
操作数据库成功,但是向MQ中投递消息时失败,向外抛出了异常,刚刚执行的更新数据库的操作将被回滚
从上面分析的几种情况来看,貌似问题都不大的。那么我们来分析下消费者端面临的问题:
-
消息出列后,消费者对应的业务操作要执行成功。如果业务执行失败,消息不能失效或者丢失。需要保证消息与业务操作一致
-
尽量避免消息重复消费。如果重复消费,也不能因此影响业务结果
如何保证消息与业务操作一致,不丢失?
主流的MQ产品都具有持久化消息的功能。如果消费者宕机或者消费失败,都可以执行重试机制的(有些MQ可以自定义重试次数)。
如何避免消息被重复消费造成的问题?
-
保证消费者调用业务的服务接口的幂等性
-
通过消费日志或者类似状态表来记录消费状态,便于判断(建议在业务上自行实现,而不依赖MQ产品提供该特性)
总结:这种方式比较常见,性能和吞吐量是优于使用关系型数据库消息表的方案。如果MQ自身和业务都具有高可用性,理论上是可以满足大部分的业务场景的。不过在没有充分测试的情况下,不建议在交易业务中直接使用。
解决方案三:
我们可以使用事物管理器进行事物的管理。所有的微服务都到事物管理器进行服务的注册,在实际微服务间调用时如果发生事物的异常,则我们事物管理器通知所有的微服务回滚事物,保持事物的一致性。
分布式事物解决方案:
(1):TCC分布式事物解决方案 (2):本地消息列表 (3):可靠消息最终一致解决方案 (4):最大努力tzh
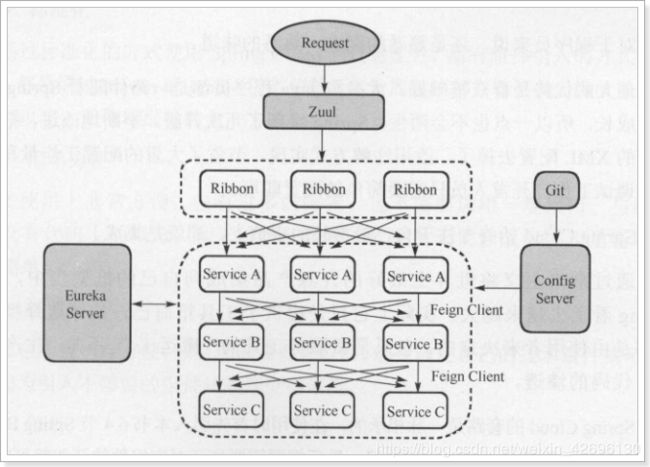
springcould常用的组件
SpringCloud作为Spring家族中的一员,它将现在非常流行的一些技术整合到一起,实现了微服务中诸如:配置管理,服务发现,智能路由,负载均衡,熔断器,控制总线,集群状态等等功能。其主要涉及的组件包括:
1.Eureka:注册中心
2.Zuul:服务网关
3.Ribbon:负载均衡
4.Feign:服务调用
5.Hystix:熔断器
如下图所示为组件中的调用的关系图解:
![]()
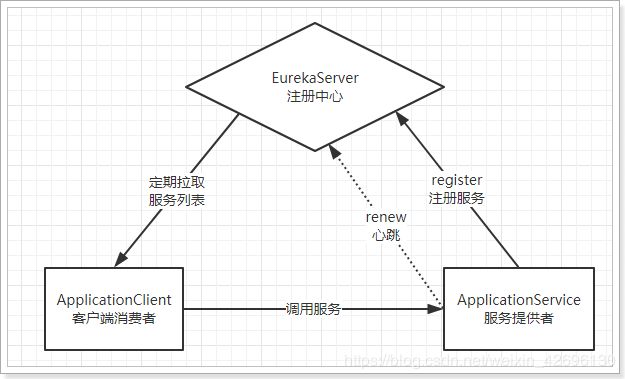
Eureka注册中心
简述:
Eureka就好比是一个公司的后台,负责管理、记录服务提供者的信息。我们只要将我们的微服务注册到Eureka中去,我们的服务调用者在调用微服务的时候,就无需自己寻找服务,而是把自己的需求告诉Eureka,然后Eureka会把符合你需求的服务告诉你,从而完成微服务的调用。
图解:
![]()
Eureka架构中的三个核心角色:
①服务注册中心
Eureka的服务端应用,提供服务注册和发现功能,就是刚刚我们建立的eureka-demo
②服务提供者
提供服务的应用,可以是SpringBoot应用,也可以是其它任意技术实现,只要对外提供的是Rest风格服务即可。
③服务消费者
消费应用从注册中心获取服务列表,从而得知每个服务方的信息,知道去哪里调用服务方。
具体的案例请看:SpringCloud--构建高可用Eureka注册中心
负载均衡Robbin
简述:
Robbin是我们SpringCould采用的一种负载均衡器,它的主要作用在于,当我们同一个功能的微服务开启了很多个时,当我们需要调用微服务时所遵循的一种微服务调用的规则,这样我们才能准确的调用响应的微服务。所以,只要我们为Robbin配置了提供服务者的同一类微服务的地址列表后,我们的Robbin就可以基于某种负载均衡的算法自动的帮助服务事物消费者去请求服务。Robbin默认的为我们提供了轮循,随机等负载均衡的算法,同时我们也可以自定义负载均衡的算法。
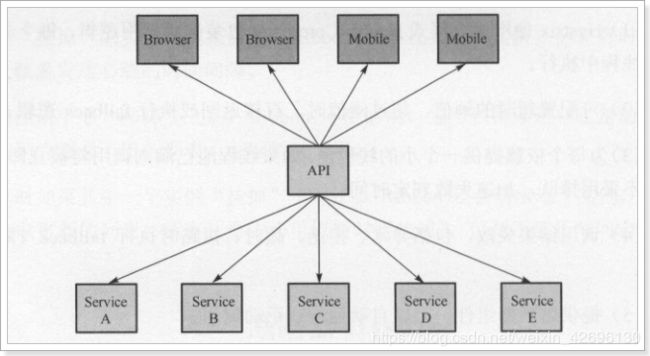
Hystrix熔断器
简述:
熔断器Hystrix是容错管理工具,作用是通过隔离、控制服务从而对延迟和故障提供更强大的容错能力,避免整个系统被拖垮。复杂分布式架构通常都具有很多依赖,当一个应用高度耦合其他服务时非常危险且容易导致失败,这种失败很容易伤害服务的调用者,最后导致一一个接一个的连续错误,应用本身就处在被拖垮的风险中,最后失去控制,就像在一一个高流量的网站中,某个单一的后端一旦发生延迟,将会在数秒内导致所有应用资源被耗尽。如何处理这些问题是有关系统性能和效率的关键性问题。 当在系统高峰时期,大量对微服务的调用可能会堵塞远程服务器的线程池,如果这个线程池没有和主应用服务器的线程池隔离,就可能导致整个服务器挂机。 Hystrix使用自己的线程池,这样和主应用服务器线程池隔离,如果调用花费很长时间,会停止调用,不同的命令或命令组能够被配置使用它们各自的线程池,可以隔离不同的服务。
图解:
正常工作的情况下,客户端请求调用服务API接口:
![]()
当有服务出现异常时,直接进行失败回滚,服务降级处理:
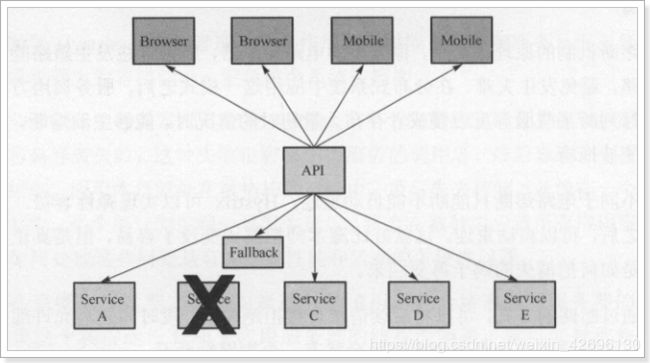
![]()
Hystrix熔断器主要的作用就是当我们的服务繁忙时,如果服务出现异常,不是粗暴的直接报错,而是返回一个友好的提示,虽然拒绝了用户的访问,但是会返回一个结果。这就好比去买鱼,平常超市买鱼会额外赠送杀鱼的服务。等到逢年过节,超时繁忙时,可能就不提供杀鱼服务了,这就是服务的降级。系统特别繁忙时,一些次要服务暂时中断,优先保证主要服务的畅通,一切资源优先让给主要服务来使用,在双十一、618时,京东天猫都会采用这样的策略。
具体的案例请看:Hystrix熔断器的使用
Feign服务的远程调用
微服务架构中,微服务间调用的一个组件。Feign是一个声明式的伪Http客户端,通过Feign可以实现服务间的相互调用,比如服务A调用服务B暴露的一些接口;同时Feign整合了Ribbon,所以Feign也可以实现服务的负载均衡调用。想要使用Feign也比较简单,定义一个通过注解@FeignClient()指定需要调用的服务的接口,启动类加上@EnableFeignClients开启Feign功能即可。
具体的案例请看:springcloud系列之feign服务间远程调用
Zuul网关
简述:
Zuul是Netfix开源的微服务网关,它可以和Eureka、Ribbon、Hystrix 等组件配合使用。Zuul的核心是一-系列的过滤器,这些过滤器可以完成以下功能。
●身份认证与安全:识别每个资源的验证要求,并拒绝那些与要求不符的请求。
●审查与监控:在边缘位置追踪有意义的数据和统计结果,从而带来精确的生产视图。
●动态路由:动态地将请求路由到不同的后端集群。
●压力测试:逐渐增加指向集群的流量,以了解性能。
●负载分配:为每一~种负载类型分配对应容量,并弃用超出限定值的请求。
●静态响应处理:在边缘位置直接建立部分响应,从而避免其转发到内部集群。
●多区域弹性:跨越AWS Region进行请求路由,旨在实现ELB ( Elastic Load Balancing )使用的多样化,以及让系统的边缘更贴近系统的使用者。
图解:
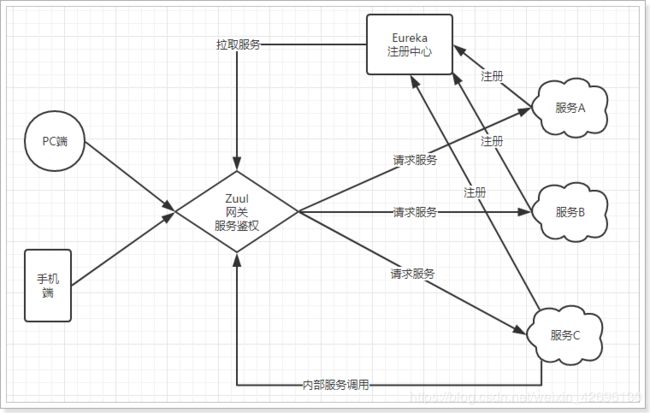
![]()
不管是来自于客户端(PC或移动端)的请求,还是服务内部调用。一切对服务的请求都会经过Zuul这个网关,然后再由网关来实现 鉴权、动态路由等等操作。Zuul就是我们服务的统一入口,即,我们可以通过Zuul网关实现微服务的统一调用。
具体的案例实现讲解:关于微服务Zuul网关的详细案例讲解
微服务消息总配置中心
在微服务架构体系中配置中心是比较重要的组件之一,Spring Cloud官方自身提供了Spring Cloud Config分布式配置中心,由它来提供集中化的外部配置支持,它分为客户端和服务端两个部分。其中服务端称作配置中心,是一个独立的微服务应用,用来连接仓库(如Git、Svn)并未客户端提供获取配置的接口;而客户端是各微服务应用,通过指定配置中心地址从远端获取配置内容,启动时加载配置信息到应用上下文中。因Spring Cloud Config实现的配置中心默认采用了Git来存储配置信息,所以版本控制管理也是基于Git仓库本身的特性来支持的 。 对该组件调研后,主要采用基于消息总线的架构方式,架构图如下所示: 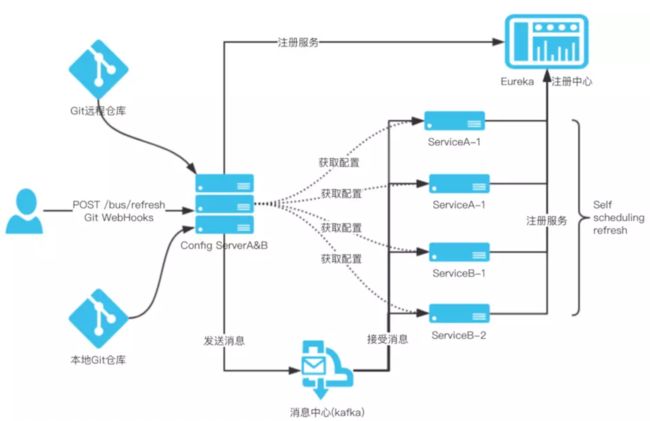
基于消息总线的配置中心架构中需要依赖外部的MQ组件,如Rabbit、Kafka 实现远程环境事件变更通知,客户端实时配置变更可以基于Git Hook功能实现。
JAVA技术部分:
为什么使用微服务架构
技术为业务而生,架构也为业务而出现。随着业务的发展、用户量的增长,系统数量增多,调用依赖关系也变得复杂,为了确保系统高可用、高并发的要求,系统的架构也从单体时代慢慢迁移至服务SOA时代,根据不同服务对系统资源的要求不同,我们可以更合理的配置系统资源,使系统资源利用率最大化。
Rpc远程调用的原理
RPC,即 Remote Procedure Call(远程过程调用),是一个计算机通信协议。 该协议允许运行于一台计算机的程序调用另一台计算机的子程序,而程序员无需额外地为这个交互作用编程。说得通俗一点就是:A计算机提供一个服务,B计算机可以像调用自己的本地服务那样调用A计算机的服务。
通过上面的概念,我们可以知道,实现RPC主要是做到两点:
-
实现远程调用其他计算机的服务
-
要实现远程调用,肯定是通过网络传输数据。A程序提供服务,B程序通过网络将请求参数传递给A,A本地执行后得到结果,再将结果返回给B程序。这里需要关注的有两点:
-
1)采用何种网络通讯协议?
-
现在比较流行的RPC框架,都会采用TCP作为底层传输协议
-
-
2)数据传输的格式怎样?
-
两个程序进行通讯,必须约定好数据传输格式。就好比两个人聊天,要用同一种语言,否则无法沟通。所以,我们必须定义好请求和响应的格式。另外,数据在网路中传输需要进行序列化,所以还需要约定统一的序列化的方式。
-
-
-
-
像调用本地服务一样调用远程服务
-
如果仅仅是远程调用,还不算是RPC,因为RPC强调的是过程调用,调用的过程对用户而言是应该是透明的,用户不应该关心调用的细节,可以像调用本地服务一样调用远程服务。所以RPC一定要对调用的过程进行封装
-
面对海量级别的数据我们怎样在后端的代码中提高查询的效率
一、数据库设计方面
-
1、对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引;
-
2、应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num is null 可以在num上设置默认值0,确保表中num列没有null值,然后这样查询: select id from t where num = 0;
-
3、并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,查询可能不会去利用索引,如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用;
-
4、索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要;
-
5、应尽可能的避免更新索引数据列,因为索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新索引数据列,那么需要考虑是否应将该索引建为索引;
-
6、尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了;
-
7、尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些;
-
8、尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引);
-
9、避免频繁创建和删除临时表,以减少系统表资源的消耗;
-
10、临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使用导出表;
-
11、在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert;
-
12、如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
二、SQL语句方面
-
1、应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描;
-
2、应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num=10 or num=20 可以这样查询: select id from t where num=10 union all select id from t where num=20;
-
3、in 和 not in 也要慎用,否则会导致全表扫描,如: select id from t where num in(1,2,3) 对于连续的数值,能用 between 就不要用 in 了: select id from t where num between 1 and 3;
-
4、下面的查询也将导致全表扫描: select id from t where name like ‘%abc%’
-
5、如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描: select id from t where num=@num 可以改为强制查询使用索引: select id from t with(index(索引名)) where num=@num;
-
6、应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如: select id from t where num/2=100 应改为: select id from t where num=100*2;
-
7、应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如: select id from t where substring(name,1,3)=’abc’–name以abc开头的id,select id from t where datediff(day,createdate,’2005-11-30′)=0–‘2005-11-30’生成的id 应改为: select id from t where name like ‘abc%’ select id from t where createdate>=’2005-11-30′ and createdate<’2005-12-1′
-
8、不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
-
9、不要写一些没有意义的查询,如需要生成一个空表结构: select col1,col2 into #t from t where 1=0 这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样: create table #t(…)
-
10、很多时候用 exists 代替 in 是一个好的选择: select num from a where num in(select num from b) 用下面的语句替换: select num from a where exists(select 1 from b where num=a.num)
-
11、任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
-
12、尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
-
13、尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
-
14、尽量避免大事务操作,提高系统并发能力。
三、Java方面
-
1、尽可能的少造对象;
-
2、合理摆正系统设计的位置。大量数据操作,和少量数据操作一定是分开的。大量的数据操作,肯定不是ORM框架搞定的;
-
3、使用JDBC链接数据库操作数据;
-
4、控制好内存,让数据流起来,而不是全部读到内存再处理,而是边读取边处理;
-
5、合理利用内存,有的数据要缓存
解决高并发的方法:
前端: 1:使用页面的静态化的技术,Thymeleaf减少前端的压力。 2:权限控制,例如会员,普通用户,并发时会员优先。 3:使用ngnix反向代理技术,进行分流。 后端: 1.使用readis缓存。 2.使用tomcat集群,分压。 3.使用fasdfs图片服务器进行静态资源的分压,不将图片,视频静态资源存储到数据库中。 4.使用mysql的主从复制的机制。 5.使用mysql的集群机制。 6.使用微服务架构,对相应的业务模块进行拆分,重构。
消息队列RabbitMQ的5种模式
1.点对点的队列
功能:一个生产者P发送消息到队列Q,一个消费者C接收
生产者实现思路:
-
创建连接工厂ConnectionFactory,设置服务地址127.0.0.1,端口号5672,设置用户名、密码、virtual host,从连接工厂中获取连接connection,使用连接创建通道channel,使用通道channel创建队列queue,使用通道channel向队列中发送消息,关闭通道和连接。
-
消费者实现思路
-
创建连接工厂ConnectionFactory,设置服务地址127.0.0.1,端口号5672,设置用户名、密码、virtual host,从连接工厂中获取连接connection,使用连接创建通道channel,使用通道channel创建队列queue, 创建消费者并监听队列,从队列中读取消息。
2 工作队列模式Work Queue
-
功能描述:一个生产者发送消息到队列中,有多个消费者共享一个队列,每个消费者获取的消息是唯一的。
-
为了保证服务器同一时刻只发送一条消息给消费者,保证资源的合理利用。channal.basicQos(1);这样是为了保证多个消费者接收的消息数量不一样,能者多劳,如果不设置,那么消费者是平均分配消息(例如10条消息,每个消费者接收5条)
3 发布/订阅模式Publish/Subscribe
-
这个可能是消息队列中最重要的队列了,其他的都是在它的基础上进行了扩展。
-
功能实现:一个生产者发送消息,多个消费者获取消息(同样的消息),包括一个生产者,一个交换机,多个队列,多个消费者。
-
思路解读(重点理解):
-
(1)一个生产者,多个消费者
-
(2)每一个消费者都有自己的一个队列
-
(3)生产者没有直接发消息到队列中,而是发送到交换机
-
(4)每个消费者的队列都绑定到交换机上
-
(5)消息通过交换机到达每个消费者的队列
-
注意:交换机没有存储消息功能,如果消息发送到没有绑定消费队列的交换机,消息则丢失。
4 路由模式Routing
-
功能:生产者发送消息到交换机并指定一个路由key,消费者队列绑定到交换机时要制定路由key(key匹配就能接受消息,key不匹配就不能接受消息),例如:我们可以把路由key设置为insert ,那么消费者队列key指定包含insert才可以接收消息,消费者队列key定义为update或者delete就不能接收消息。很好的控制了更新,插入和删除的操作。
5 通配符模式Topics
-
说明:此模式实在路由key模式的基础上,使用了通配符来管理消费者接收消息。生产者P发送消息到交换机X,type=topic,交换机根据绑定队列的routing key的值进行通配符匹配;
-
符号#:匹配一个或者多个词lazy.# 可以匹配lazy.irs或者lazy.irs.cor
-
符号:只能匹配一个词lazy. 可以匹配lazy.irs或者lazy.cor
接口的自动测试机制
frammark常见的用法
导出静态页面
导出word文档
导出excel文档
消息队列消息丢失怎么办
reids 的list可以作为消息队列来使用。当消费者从list中取出消息时redis就已经将消息删除,此时如果消费者消费失败,或者因为异常、不可抗拒因素(宕机等)时,可能会导致消息丢失的情况。
ZooKeeper原理与总结
zookeeper概述: 分布式的、开源的分布式应用程序协调服务,原本是Hadoop、HBase的一个重要组件。它为分布式应用提供一致性服务的软件,包括:配置维护、域名服务、分布式同步、组服务等。 应用场景 : Zookeeper的功能很强大,应用场景很多,结合我实际工作中使用Dubbo框架的情况,Zookeeper主要是做注册中心用。基于Dubbo框架开发的提供者、消费者都向Zookeeper注册自己的URL,消费者还能拿到并订阅提供者的注册URL,以便在后续程序的执行中去调用提供者。而提供者发生了变动,也会通过Zookeeper向订阅的消费者发送通知。
nginx服务器的配置学习
1、反向代理 2、负载均衡 3、HTTP服务器(包含动静分离)
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
#反向代理 直接访问 http://localhost
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://localhost:1001;
proxy_set_header Host $host:$server_port;
}
}
#负载均衡 使用weight指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况
upstream test {
#一个请求来的时候请求可能分发到另外一个服务器,当我们的程序不是无状态的时候(采用了session保存数据),这时候就有一个很大的很问题了,比如把登录信#息保存到了session中,那么跳转到另外一台服务器的时候就需要重新登录了,所以很多时候我们需要一个客户只访问一个服务器,那么就需要用iphash了,iphash的每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。
#ip_hash;
server localhost:1001 weight=2;
server localhost:1002 weight=2;
server localhost:1003 weight=6;
}
# 多次访问http://localhost:10011端口观察响应可以实现负载均衡
server {
listen 10011;
server_name localhost;
client_max_body_size 1024M;
location / {
proxy_pass http://test;
proxy_set_header Host $host:$server_port;
}
}
#静态资源服务器 访问路径 http://localhost:10012/xxx.jpg 可以获取相应的图片资源
server {
listen 10012;
server_name localhost;
client_max_body_size 1024M;
location / {
root H:\static;
}
}
#实现网站的动静分离代理
server {
listen 10013;
server_name localhost;
location / {
root H:\image;
index index.html;
}
# 所有静态请求都由nginx处理,存放目录为image
location ~ \.(gif|jpg|jpeg|png|bmp|swf|css|js)$ {
root H:\image;
}
# 所有动态请求都转发给tomcat处理
location ~ \.(jsp|do)$ {
proxy_pass http://test;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root e:\wwwroot;
}
}
}
#user nobody;
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
gzip on;
server {
listen 80;
server_name manage.answer.com;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Server $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
location / {
proxy_pass http://127.0.0.1:9001;
proxy_connect_timeout 600;
proxy_read_timeout 600;
}
}
server {
listen 80;
server_name api.answer.com;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Server $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# 上传路径的映射
location /api/upload {
proxy_pass http://127.0.0.1:8082;
proxy_connect_timeout 600;
proxy_read_timeout 600;
rewrite "^/api/(.*)$" /$1 break;
}
location / {
proxy_pass http://127.0.0.1:10010;
proxy_connect_timeout 600;
proxy_read_timeout 600;
}
}
# server {
#listen 80;
#server_name image.answer.com;
# proxy_set_header X-Forwarded-Host $host;
# proxy_set_header X-Forwarded-Server $host;
# proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
#location / {
# root D:\\answer\\upload;
# }
# }
}
数据库部分:
数据库事务的级别
一、首先什么是事务?
事务是应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所作的所有更改都会被撤消。也就是事务具有原子性,一个事务中的一系列的操作要么全部成功,要么一个都不做。
事务的结束有两种,当事务中的所以步骤全部成功执行时,事务提交。如果其中一个步骤失败,将发生回滚操作,撤消撤消之前到事务开始时的所以操作。
二、事务的 ACID
读未提交 读已提交 可重复读 可串行化
事务具有四个特征:原子性( Atomicity )、一致性( Consistency )、隔离性( Isolation )和持续性( Durability )。这四个特性简称为 ACID 特性。
1 、原子性。事务是数据库的逻辑工作单位,事务中包含的各操作要么都做,要么都不做
2 、一致性。事 务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。因此当数据库只包含成功事务提交的结果时,就说数据库处于一致性状态。如果数据库系统运行中发生故障,有些事务尚未完成就被迫中断,这些未完成事务对数据库所做的修改有一部分已写入物理数据库,这时数据库就处于一种不正确的状态,或者说是 不一致的状态。
3 、隔离性。一个事务的执行不能其它事务干扰。即一个事务内部的操作及使用的数据对其它并发事务是隔离的,并发执行的各个事务之间不能互相干扰。
4 、持续性。也称永久性,指一个事务一旦提交,它对数据库中的数据的改变就应该是永久性的。接下来的其它操作或故障不应该对其执行结果有任何影响。
三、Mysql的四种隔离级别
SQL标准定义了4类隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的。低级别的隔离级一般支持更高的并发处理,并拥有更低的系统开销。
Read Uncommitted(读取未提交内容)
在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
Read Committed(读取提交内容)
这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这种隔离级别 也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select可能返回不同结果。
Repeatable Read(可重读)
这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。
Serializable(可串行化)
这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
这四种隔离级别采取不同的锁类型来实现,若读取的是同一个数据的话,就容易发生问题。例如:
脏读(Drity Read):某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。
不可重复读(Non-repeatable read):在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。
幻读(Phantom Read):在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的。
传统的数据库有什么优势
1.灵活性,经得起考验,适用范围广 开发者与关系型的数据库编程之间的接口是灵活和友好的,我们可以无差别的使用sql语言在一个产品上获取另一个产品的信息。我们目前java与数据库交互的方式有原始的JDBC编程,Hibernate框架,Mybatis框架,SpringData框架等等诸多的交互方式都可以实现数据交互。阿里,谷歌,腾讯,脸书等等一些大公司都在使用Mysql传统数据库。
2.支持事物 传统的Mysql数据库可以支持事物,而redis不支持事物
3.易于维护:丰富的完整性(实体完整性、参照完整性和用户定义的完整性)大大减低了数据冗余和数据不一致的概率。而大部分的非关系型数据则没有如此丰富的完整性。
Mysql数据库练习
-- 笛卡尔积
select * from a,b where a.id = b.id;-- 隐式内连接
-- 内连接: select * from 表名a inner join 表b on 条件
select * from a INNER JOIN b on a.id = b.id
select * from a inner join b on a.id = b.id;-- 显示内连接
-- 外连接
-- 1. 左外连接: select * from 表a left outer join 表b on 条件
-- 需求 : 列出所有的水果的信息和价格
select * from b left outer join a on a.id = b.id;
SELECT * from a left join b on a.id = b.id;
-- 2. 右外连接: select * from 表a right outer join 表b on 条件
-- 需求 : 列出所有的价格信息和水果
select * from a right outer join b on a.id = b.id;
select * from b left outer join a on a.id = b.id;
-- 3. 全外连接 select * from 表a full outer join 表b on 条件
-- 需求 : 查询所有的水果的信息,和价格的信息
select * from a full outer join b on a.id = b.id;-- mysql不支持这种写法而已
-- mysql的全外连接如何实现
-- 左外连接联合右外连接
select * from a left outer join b on a.id = b.id
union -- union只显示不重复的数据,union all,将所有的数据都展示
select * from a right outer join b on a.id = b.id;
# 关联子查询
-- 需求 : 查询年龄最大的学生信息
-- 查询出最大的年龄
SELECT * from student
where age IN(SELECT max(age) from student)
select max(age) from student;-- 25
-- 查询年龄为25岁的学生的信息
select * from student where age = 25;
SELECT * from student where age in(25);
select * from student
where age = (select max(age) from student);
-- -- in 的用法 :
-- 需求:查询分数不及格的所有的学生信息
SELECT * FROM student where student.id in(select student_id from student_course where score < 60)
-- 从中间表中,查询出不及格的学生的id
select student_id FROM student_course WHERE score<60;
select student_id from student_course where score < 60;
-- 从学生表中,查询对应id的学生信息
-- in:当查询条件是多个,或者不确定时,要使用in
select * from student
where id in (select student_id from student_course where score < 60);
-- all 的用法 :
-- 需求 : 查询年龄最大的学生的信息
SELECT * from student where age in(SELECT max(age) from student)
SELECT * from student where id in(SELECT id from student where age in(SELECT MAX(age) from student ) )
SELECT * from student where age >=all(SELECT age from student)
-- 先查询出所有的学生的年龄
select age from student
-- 只要>=所有年龄就是要找最大年龄
select * from student where age >= all(select age from student);
-- all()中只能放sql语句不能直接放值
select * from student where age >= all(18,22,25);-- 错误
-- any 和 some 的用法 :
-- 查询成绩是90的学生的信息
SELECT * from student where id in(SELECT student_course.student_id from student_course where student_course.score=90)
SELECT * from student where id = SOME(SELECT student_course.student_id from student_course where student_course.score=90)
SELECT * from student where id = ANY(SELECT student_course.student_id from student_course where student_course.score=90)
-- 从中间表中查询90分的学生id
select student_id from student_course where score = 90;
-- 从学生表中查询信息
select * from student
where id in (select student_id from student_course where score = 90);
-- 如果查询结果是多个或不确定时,但是我就想用= 怎么办??
select * from student
where id = some(select student_id from student_course where score = 90);
select * from student
where id = any(select student_id from student_course where score = 90);
-- as 定义 `临时表`
-- 需求 : 查询不及格的学生信息和不及格分数
select student.*,score from student,(SELECT * from student_course WHERE student_course.score<60) as temp where student.id = temp.student_id;
select student.*,temp.* from student,(SELECT * from student_course WHERE student_course.score<60) as temp where student.id = temp.student_id;
SELECT * FROM student,(SELECT student_course.student_id,student_course.score from student_course where student_course.score <60) as temp where student.id = temp.student_id;
-- 从中间表中查询不及格的学生的id和分数
select student_id,score from student_course where score < 60;
-- 将上面的子查询认作是一张临时表as
select student.*,score from student,
(select student_id,score from student_course where score < 60) as temp
where temp.student_id = student.id;
-- 子查询练习
-- 需求 : 查询数学成绩比语文成绩高的所有学生信息
select * from student_course where course_id in (SELECT id from course where `name` ='语文')
select * from student_course where course_id in (SELECT id from course where `name` ='数学')
SELECT * FROM student where id in(
SELECT temp_chinese.student_id
from
(select * from student_course where course_id in (SELECT id from course where `name` ='语文')) as temp_chinese,
(select * from student_course where course_id in (SELECT id from course where `name` ='数学')) as temp_maths
where temp_chinese.student_id = temp_maths.student_id AND temp_maths.score>temp_chinese.score);
-- 1.1从课程表中查询出数学的id
select id from course where name = '数学';
-- 1.2从课程表中查询出语文的id
select id from course where name = '语文';
-- 2.1 从中间表中查询数学成绩
select student_id,score from student_course
where course_id = (select id from course where name = '数学');
-- 2.2 从中间表中查询语文成绩
select student_id,score from student_course
where course_id = (select id from course where name = '语文');
-- 3.从2个临时表中进行内连接查询获取学生的id
select temp_math.student_id from
(
select student_id,score from student_course
where course_id = (select id from course where name = '数学')
) as temp_math,
(
select student_id,score from student_course
where course_id = (select id from course where name = '语文')
) as temp_chinese
where temp_math.student_id = temp_chinese.student_id
and temp_math.score > temp_chinese.score;
-- 4.从学生表中查询出(1,5,6)的学生信息
select * from student
where id in(
select temp_math.student_id from
(
select student_id,score from student_course
where course_id = (select id from course where name = '数学')
) as temp_math,
(
select student_id,score from student_course
where course_id = (select id from course where name = '语文')
) as temp_chinese
where temp_math.student_id = temp_chinese.student_id
and temp_math.score > temp_chinese.score
);
-- mysql 自带函数 (知道即可)
-- 加密方法 *23AE809DDACAF96AF0FD78ED04B6A265E05AA257
select password('123');
select password("1111")
-- 字符方法
select ucase('itheima');
select lcase('ITHEIMA');
-- java 0基 sql 1基
select substring('王思聪',2,2);
-- 数字方法
select abs(-5);
select ceil(3.14);
select floor(3.14);
-- 日期方法
select now();
select current_date();
select current_time();
# sql 强化练习
-- 1 查询平均成绩大于70分的同学的学号和平均成绩
SELECT student_id,AVG(score) as `平均成绩`
FROM student_course
GROUP BY student_id
HAVING AVG(score)>70;
select student_id,avg(score) as 平均成绩 from student_course
group by student_id
having avg(score) > 70;
-- 2 查询所有同学的学号、姓名、选课数、总成绩
SELECT student.id as '学号' ,student.`name` as '姓名', temp.选课数,temp.总成绩
from student ,(
SELECT student_id,sum(score) as '总成绩',COUNT(score) as '选课数'
FROM student_course
GROUP BY student_id) as temp
where student.id = temp.student_id;
-- 2.1 从中间表中按学号分组查询出学号、选课数、总成绩
select student_id,count(*),sum(score)
from student_course group by student_id;
-- 2.2 临时表和学生表内连接查询
-- 子查询中的聚合函数不能直接使用!!!必须通过别名来使用
select student.id,student.name,temp.选课数,temp.总成绩 from student,
(
select student_id,count(*) as 选课数,sum(score) as 总成绩
from student_course group by student_id
) as temp
where temp.student_id = student.id;
-- 3 查询学过赵云老师所教课的同学的学号、姓名
SELECT * from student where student.id in
(SELECT student_id FROM student_course where student_course.course_id in(
SELECT id from course where course.teacher_id in
(SELECT id from teacher where teacher.name='赵云')));
SELECT * from student_course where
-- 3.1 查询赵云的id
select id from teacher where name = '赵云';
-- 3.2 从课程表中查询赵云所教的课程id
select id from course
where teacher_id = (select id from teacher where name = '赵云');
-- 3.3 从中间表查询学过赵云老师课程的学生id
select student_id from student_course
where course_id in (
select id from course
where teacher_id = (select id from teacher where name = '赵云')
);
-- 3.4从学生表中查询上面的学号的姓名即可
select * from student where id in (
select student_id from student_course
where course_id in (
select id from course
where teacher_id = (select id from teacher where name = '赵云')
)
);
-- 4 查询没学过关羽老师课的同学的学号、姓名
SELECT * from student where student.id not in(
SELECT DISTINCT(student_id) FROM student_course where course_id in(
SELECT id from course where teacher_id =(
select id from teacher where name ="关羽")));
-- 4.1 查询出学过关羽老师课的同学的学号、姓名
-- 4.2 取反
select * from student where not id in (
select student_id from student_course
where course_id in (
select id from course
where teacher_id = (select id from teacher where name = '关羽')
)
);
-- 5 查询学三门课以下的同学的学号、姓名
select id as '学号' ,name as '姓名' from student where id in
(SELECT student_id from student_course GROUP BY student_id
HAVING COUNT(course_id)>3 ORDER BY student_id ASC);
-- 5.1 从中间表按学号分组查询 学号和选课数,条件:三门以下
select student_id ,count(*) from student_course
group by student_id having count(*) < 3;
-- 5.2 多表查询内连接
select student.id,student.name from student,
(
select student_id ,count(*) from student_course
group by student_id having count(*) < 3
) as temp
where temp.student_id = student.id;
-- 6 查询各科成绩最高和最低的分
SELECT course_id,MAX(score),MIN(score)
FROM
student_course GROUP BY course_id;
select course_id,max(score),min(score)
from
student_course group by course_id;
-- 7 查询各个城市的学生数量
SELECT city , COUNT(*) FROM student GROUP BY city;
select city , count(*) from student group by city;
-- 8 查询不及格的学生信息和课程信息
SELECT student.*,course.* from student,course ,
(SELECT * from student_course where score<60) as temp
where student.id = temp.student_id
and temp.course_id = course.id ;
-- 8.1 从中间表查询不及格的学生id,课程id
select student_id , course_id from student_course
where score < 60;
-- 8.2 3表联查
select student.*,course.* from student,course,
(
select student_id , course_id from student_course
where score < 60
) as temp
where temp.student_id = student.id
and temp.course_id = course.id;
-- 9 统计每门课程的学生选修人数(超过四人的进行统计)
SELECT course_id as '课程的编号', count(*) as '选修的人数' from student_course GROUP BY course_id HAVING count(*)>4;
select course_id,count(*) as 选修人数 from student_course
group by course_id having 选修人数 > 4;
-- 3. 列出所有员工的姓名及其直接上级的姓名。
-- 如果所要的数据都来自同一张表,那么就将当前表临时作为2张不同的表
select temp1.ename,temp2.ename from
(select * from emp) as temp1,
emp as temp2
where temp1.mgr = temp2.empno
SELECT user_type,is_admin ,SUM(id) FROM saut_m_user
WHERE id > 100
GROUP BY user_type,is_admin
HAVING SUM(status) < 500
ORDER BY is_admin ASCmysql支持的行级锁和表集锁
数据库的主从复制
原理:读写分离 可以解决高并发。 https://baijiahao.baidu.com/s?id=1609045850176316928&wfr=spider&for=pc
主重复值时,我们可以创建一个主数据库A一个从的数据库B,主库A负责相应的数据的(增删改)同步操作,B负责数据的查询操作,我们将A中的数据操作产生的日志存进一个A的日志中,然后通过网络发送给B,B将A传输过来的日志写入本地的日志中,然后一条条的将数据库事件在数据库中完成。那么,MYSQL-A的变化,MYSQL-B也会变化,这样就是所谓的MYSQL的复制,即MYSQL replication。
数据库中的锁的机制 悲观锁,乐观锁
何谓悲观锁与乐观锁
乐观锁对应于生活中乐观的人总是想着事情往好的方向发展,悲观锁对应于生活中悲观的人总是想着事情往坏的方向发展。这两种人各有优缺点,不能不以场景而定说一种人好于另外一种人。
悲观锁
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
乐观锁
总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
两种锁的使用场景
从上面对两种锁的介绍,我们知道两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写比较少的情况下(多读场景),即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果是多写的情况,一般会经常产生冲突,这就会导致上层应用会不断的进行retry,这样反倒是降低了性能,所以一般多写的场景下用悲观锁就比较合适。
乐观锁常见的两种实现方式
乐观锁一般会使用版本号机制或CAS算法实现。
-
版本号机制
一般是在数据表中加上一个数据版本号version字段,表示数据被修改的次数,当数据被修改时,version值会加一。当线程A要更新数据值时,在读取数据的同时也会读取version值,在提交更新时,若刚才读取到的version值为当前数据库中的version值相等时才更新,否则重试更新操作,直到更新成功。
举一个简单的例子: 假设数据库中帐户信息表中有一个 version 字段,当前值为 1 ;而当前帐户余额字段( balance )为 $100 。
-
操作员 A 此时将其读出( version=1 ),并从其帐户余额中扣除 (100-$50 )。
-
在操作员 A 操作的过程中,操作员B 也读入此用户信息( version=1 ),并从其帐户余额中扣除 (100-$20 )。
-
操作员 A 完成了修改工作,将数据版本号加一( version=2 ),连同帐户扣除后余额( balance=$50 ),提交至数据库更新,此时由于提交数据版本大于数据库记录当前版本,数据被更新,数据库记录 version 更新为 2 。
-
操作员 B 完成了操作,也将版本号加一( version=2 )试图向数据库提交数据( balance=$80 ),但此时比对数据库记录版本时发现,操作员 B 提交的数据版本号为 2 ,数据库记录当前版本也为 2 ,不满足 “ 提交版本必须大于记录当前版本才能执行更新 “ 的乐观锁策略,因此,操作员 B 的提交被驳回。
这样,就避免了操作员 B 用基于 version=1 的旧数据修改的结果覆盖操作员A 的操作结果的可能。
-
CAS算法
即compare and swap(比较与交换),是一种有名的无锁算法。无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking Synchronization)。CAS算法涉及到三个操作数
-
需要读写的内存值 V
-
进行比较的值 A
-
拟写入的新值 B
当且仅当 V 的值等于 A时,CAS通过原子方式用新值B来更新V的值,否则不会执行任何操作(比较和替换是一个原子操作)。一般情况下是一个自旋操作,即不断的重试。
乐观锁的缺点
ABA 问题是乐观锁一个常见的问题
1 ABA 问题
如果一个变量V初次读取的时候是A值,并且在准备赋值的时候检查到它仍然是A值,那我们就能说明它的值没有被其他线程修改过了吗?很明显是不能的,因为在这段时间它的值可能被改为其他值,然后又改回A,那CAS操作就会误认为它从来没有被修改过。这个问题被称为CAS操作的 "ABA"问题。
JDK 1.5 以后的 AtomicStampedReference 类就提供了此种能力,其中的 compareAndSet 方法就是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
2 循环时间长开销大
自旋CAS(也就是不成功就一直循环执行直到成功)如果长时间不成功,会给CPU带来非常大的执行开销。 如果JVM能支持处理器提供的pause指令那么效率会有一定的提升,pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。
3 只能保证一个共享变量的原子操作
CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS 无效。但是从 JDK 1.5开始,提供了AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作.所以我们可以使用锁或者利用AtomicReference类把多个共享变量合并成一个共享变量来操作。
CAS与synchronized的使用情景
简单的来说CAS适用于写比较少的情况下(多读场景,冲突一般较少),synchronized适用于写比较多的情况下(多写场景,冲突一般较多)
-
对于资源竞争较少(线程冲突较轻)的情况,使用synchronized同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗cpu资源;而CAS基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。
-
对于资源竞争严重(线程冲突严重)的情况,CAS自旋的概率会比较大,从而浪费更多的CPU资源,效率低于synchronized。
补充: Java并发编程这个领域中synchronized关键字一直都是元老级的角色,很久之前很多人都会称它为 “重量级锁” 。但是,在JavaSE 1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的 偏向锁 和 轻量级锁 以及其它各种优化之后变得在某些情况下并不是那么重了。synchronized的底层实现主要依靠 Lock-Free 的队列,基本思路是 自旋后阻塞,竞争切换后继续竞争锁,稍微牺牲了公平性,但获得了高吞吐量。在线程冲突较少的情况下,可以获得和CAS类似的性能;而线程冲突严重的情况下,性能远高于CAS。
redis的概述
redis: 概述: c语言编写 安装redis: redis数据结构: key value value: String : 512M hash : list set sorted-set redis: redis数据结构: jedis: java操作redis的方式 redis的特性: redis持久化: RDB: 默认 存储的数最终的数据信息 可能会导致数据丢失 AOF: 存储的是每次执行的命令 不会导致数据丢失
redis的特点
-
读写性能高,支持并发性高(读110000/s,写81000/s)
-
灵活的数据类型
redis支持的数据类型
-
string(字符串)
-
hash(哈希)
-
list(列表)
-
set(集合)
-
zset(sorted set:有序集合)。
redis的应用的场景
-
缓存——活跃的数据(String)
-
计数器—网站的访问量统计
-
public class HomeController : Controller { private readonly static string keyPerfix = "Test_ClickTotal_"; // GET: Home public async TaskIndex(int Id = 0) { using (ConnectionMultiplexer redis = ConnectionMultiplexer.Connect("localhost:6379")) { IDatabase db = redis.GetDatabase(4); //Redis默认有15个数据库,GetDatabase()中参数代表将数据存入那个数据中 if (await db.KeyExistsAsync(keyPerfix + Request.UserHostAddress + Id) == false) //keyPerfix+访问者的IP地址+Id为 key,记录这个IP是否点击过 { //说明没有找到 await db.StringIncrementAsync(keyPerfix + Id, 1); //使用StringIncrementAsync来进行计数,效率很高 //这里就增加一条已经访问过的记录,key值要上面判断格式一致,value值随意,第三个参数表示一天后这条记录就失效 await db.StringSetAsync(keyPerfix + Request.UserHostAddress + Id, "true", TimeSpan.FromDays(1)); string total = await db.StringGetAsync(keyPerfix + Id); //增加之后在读取出来 ClickTotalModel totalModel = new ClickTotalModel { Total = Convert.ToInt32(total) }; return View(totalModel); } else { //直接读出来 string total = await db.StringGetAsync(keyPerfix + Id); ClickTotalModel totalModel = new ClickTotalModel { Total = Convert.ToInt32(total) }; return View(totalModel); } } } } -
搜索排行榜(sorted set)
-
任务队列
-
数据的过期处理
-
分布式集群架构中的session的分离
redis常用命令
String : 512M set key value / set name Jack 设置数据值 get key / get name 获取数据值 getset key value incr key / incr number number值加一 decr key / decr number number值减一 incrby key 数值 /incrby number 100 number值加100 decrby key 数值 /decrby number 100 number值减100 append key 字符串 / append number 1 number后面拼接一个1 del key/del name 删除name键值对 flushall/flushadb 删除所有/当前redis数据库中的key值 keys * 查看所有的所有的键值 select DB_index /select 1 切换redis数据库 move key DB_index/move name 1 将当前数据库中的name键值移动到数据库1中 quit 退出连接 info 获取服务器的信息和统计
hash : hset key filed value hmset key filed1 value1 filed2 value2 ... hget key filed hmget filed1 filed2 hgetall key hkeys key hvals key hdel key filed1 ...
redis的持久化策略
-
概述:由于redis是将数据保存在内存中的,为了是redis重启之后仍然能够保证数据的同步,则需要将数据从磁盘 读取到内存中,这一步就是数据的持久化。
-
RDB:redis默认的持久化策略,该机制是在指定的时间间隔内将内存中的数据集快照写入磁盘。
优点:每隔一段时间备份的策略,当我们需要记录每一天的数据或者是每一个月记录一次数据,通过此策略机制如果在某个时间段redis数据生了灾难性的问题我们很容易将数据还原到某个时间点,同时我们还可以很容易的将我们的备份文件传输到其他的存储介质上去,同时对于redis的服务进程来讲我们的RDB在开始持久化时会先会分叉处子进程,然后由这些子进程共同完成持久化的工作,持久化的效率比较高。
缺点:由于它是在每一段时间间隔内进行数据持久化的,所有如果在某一个时间间隔内数据还没有持久化服务器宕机,此时在此间隔内的数据会丢失,同时由于RDB的持久化是通过分子进程来完成,所以当我们的数据量达到一定的级别,持久化的过程可能会导致服务器在某一段时间内停止服务。
-
AOF: 该机制是以日记的方式去记录服务器所处理的每一个写的操作,在redis服务器启动之初会读取该文件来重新构建redis数据库。
优点:AOF机制对日志文件的写入采用的是append模式,因此在写入的过程中出现宕机现象也不会破坏日志系统中已存在的内容,就算写入了不完整的命令,我们也可以通过redis-check-aof工具来进行修复。如果日志量过大,aof机制还会对日志文件进行重写,重写后的文件包含了恢复当前redis数据的最小的命令的集合。
缺点:相同的数据,aof的文件通常会大于RDB文件,根据同步策略的不同,AOF在运行的效率上会低于RDB.
java中的redis的使用
1.链接redis的服务 redis: host: 192.168.44.132 2.配置相应的jar包 从Spring的Beans中获取@Autowiredprivate RedisTemplate redisTemplate; 3.操作redis中的数据
RedisTemplate中定义了对5种数据结构操作
redisTemplate.opsForValue();//操作字符串String
redisTemplate.opsForHash();//操作hash
redisTemplate.opsForList();//操作list
redisTemplate.opsForSet();//操作set
redisTemplate.opsForZSet();//操作有序set获取数据:redisTemplate.opsForValue().get("ARTICLE" + id); 删除数据:redisTemplate.delete("ARTICLE" + id); 添加数据:redisTemplate.opsForValue().set("ARTICLE_" + id, article);
redis怎样实现持久化
-
概述:由于redis是将数据保存在内存中的,为了是redis重启之后仍然能够保证数据的同步,则需要将数据从磁盘 读取到内存中,这一步就是数据的持久化。
-
RDB:redis默认的持久化策略,该机制是在指定的时间间隔内将内存中的数据集快照写入磁盘。
优点:每隔一段时间备份的策略,当我们需要记录每一天的数据或者是每一个月记录一次数据,通过此策略机制如果在某个时间段redis数据生了灾难性的问题我们很容易将数据还原到某个时间点,同时我们还可以很容易的将我们的备份文件传输到其他的存储介质上去,同时对于redis的服务进程来讲我们的RDB在开始持久化时会先会分叉处子进程,然后由这些子进程共同完成持久化的工作,持久化的效率比较高。
缺点:由于它是在每一段时间间隔内进行数据持久化的,所有如果在某一个时间间隔内数据还没有持久化服务器宕机,此时在此间隔内的数据会丢失,同时由于RDB的持久化是通过分子进程来完成,所以当我们的数据量达到一定的级别,持久化的过程可能会导致服务器在某一段时间内停止服务。
-
AOF: 该机制是以日记的方式去记录服务器所处理的每一个写的操作,在redis服务器启动之初会读取该文件来重新构建redis数据库。
优点:AOF机制对日志文件的写入采用的是append模式,因此在写入的过程中出现宕机现象也不会破坏日志系统中已存在的内容,就算写入了不完整的命令,我们也可以通过redis-check-aof工具来进行修复。如果日志量过大,aof机制还会对日志文件进行重写,重写后的文件包含了恢复当前redis数据的最小的命令的集合。
缺点:相同的数据,aof的文件通常会大于RDB文件,根据同步策略的不同,AOF在运行的效率上会低于RDB.
***redis的集群
MongoDB概述讲解
-
简介:MongoDB 是一个跨平台的,面向文档的数据库,是当前 NoSQL 数据库产品中最热门的一种。它介于关系数据库和非关系数据库之间,是非关系数据库当中功能最丰富,最像关系数据库的产品。它支持的数据结构非常松散,是类似 JSON 的 BSON 格式,因此可以存储比较复杂的数据类型。
-
具体特点总结如下: (1)面向集合存储,易于存储对象类型的数据 (2)模式自由 (3)支持动态查询 (4)支持完全索引,包含内部对象 (5)支持复制和故障恢复 (6)使用高效的二进制数据存储,包括大型对象(如视频等) (7)自动处理碎片,以支持云计算层次的扩展性 (8)支持 Python,PHP,Ruby,Java,C,C#,Javascript,Perl 及 C++语言的驱动程序,社区中也提供了对 Erlang 及.NET 等平台的驱动程序 (9) 文件存储格式为 BSON(一种 JSON 的扩展)
-
MongoDB体系结构
MongoDB 的逻辑结构是一种层次结构。主要由: 文档(document)、集合(collection)、数据库(database)这三部分组成的。逻辑结构是面向用户的,用户使用 MongoDB 开发应用程序使用的就是逻辑结构。 (1)MongoDB 的文档(document),相当于关系数据库中的一行记录。 (2)多个文档组成一个集合(collection),相当于关系数据库的表。 (3)多个集合(collection),逻辑上组织在一起,就是数据库(database)。 (4)一个 MongoDB 实例支持多个数据库(database)。 文档(document)、集合(collection)、数据库(database)的层次结构如下图:
下表是MongoDB与MySQL数据库逻辑结构概念的对比:
MongoDB 关系型数据库Mysql 数据库(databases) 数据库(databases) 集合(collections) 表(table) 文档(document) 行(row) Bson数据类型
-
null:用于表示空值或者不存在的字段,{“x”:null}
-
布尔型:布尔类型有两个值true和false,{“x”:true}
-
数值:shell默认使用64位浮点型数值。{“x”:3.14}或{“x”:3}。对于整型值,可以使用NumberInt(4字节符号整数)或NumberLong(8字节符号整数),{“x”:NumberInt(“3”)}{“x”:NumberLong(“3”)}
-
字符串:UTF-8字符串都可以表示为字符串类型的数据,{“x”:“呵呵”}
-
日期:日期被存储为自新纪元依赖经过的毫秒数,不存储时区,{“x”:new Date()}
-
正则表达式:查询时,使用正则表达式作为限定条件,语法与JavaScript的正则表达式相同,{“x”:/[abc]/}
-
数组:数据列表或数据集可以表示为数组,{“x”: [“a“,“b”,”c”]}
-
内嵌文档:文档可以嵌套其他文档,被嵌套的文档作为值来处理,{“x”:{“y”:3 }}
-
对象Id:对象id是一个12字节的字符串,是文档的唯一标识,{“x”: objectId() }
-
二进制数据:二进制数据是一个任意字节的字符串。它不能直接在shell中使用。如果要将非utf-字符保存到数据库中,二进制数据是唯一的方式。
-
代码:查询和文档中可以包括任何JavaScript代码,{“x”:function(){/…/}}
-
与mysql数据库比较:
-
SQL术语/概念 MongoDB术语/概念 解释/说明 database database 数据库 table collection 数据库表/集合 row document 数据记录行/文档 column field 数据字段/域 index index 索引 table joins 表连接,MongoDB不支持 primary key primary key 主键,MongoDB自动将_id字段设置为主键
MonGodb常用的命令:
选择数据库(如果没有数据库则自动的创建):use spitdb 插入数据:db.spit.insert({bson数据}) 查询所有数据:db.spit.find(); 条件查询数据:db.spit.find({条件}) 查询符合条件的第一条记录:db.spit.findOne({条件}) 查询符合条件的前几条记录:db.spit.find({条件}).limit(条数) 查询符合条件的跳过的记录:db.spit.find({条件}).skip(条数) 修改数据:db.spit.update({条件},{要修改的数据}) 或db.spit.update({条件},{$set:{要修改部分的字段:数据}) 修改数据并自增某字段值:db.spit.update({条件},{$inc:{自增的字段:步进值}}) 删除数据:db.spit.remove({条件}) 统计查询:db.spit.count({条件}) 模糊查询:db.spit.find({字段名:/正则表达式/}) 条件比较运算:db.spit.find({字段名:{$gt:值}}) 包含查询:db.spit.find({字段名:{$in:[值1,值2]}})选择数据库(如果没有数据库则自动的创建):use spitdb 条件连接查询:db.spit.find({$and:[{条件1},{条件2}]})或db.spit.find({$or:[{条件1},{条件2}]}) 显示所有的数据库:show databases
mongodb和redis的区别
-
MongoDB更类似Mysql,支持字段索引、游标操作,其优势在于查询功能比较强大,擅长查询JSON数据,能存储海量数据,但是不支持事务。
-
Mysql在大数据量时效率显著下降,MongoDB更多时候作为关系数据库的一种替代。
内存管理机制
-
Redis数据全部存在内存,定期写入磁盘,当内存不够时,可以选择指定的LRU算法删除数据。
-
MongoDB数据存在内存,由linux系统mmap实现,当内存不够时,只将热点数据放入内存,其他数据存在磁盘。
支持的数据结构
-
Redis支持的数据结构丰富,包括String、hash、sortSet、set、list等。
-
MongoDB支持丰富的数据表达,索引,最类似关系型数据库,支持的查询语言非常丰富。
性能
-
二者性能都比较高,应该说都不会是瓶颈。
可靠性
-
二者均支持持久化。
不适用场景
-
Ø 需要使用复杂sql的操作
-
Ø 事务性系统
mysql和redis的区别
从数据存储的角度:
mysql:数据库是一种传统的关系型数据库,数据以二维表的形式进行存储。 redis:是一种非关系型数据库,也是缓存数据库,即将数据存储在缓存中,缓存的读取速度快,能够大大的提高运行效率,以key-value形式进行数据的存储,支持丰富的数据了类型list、set、String、hash、zset。 mondb:它是一个内存数据库,由linux系统mmap实现,理论上数据都是放在内存里面的、对数据的操作大部分都在内存中,但mongodb并不是单纯的内存数据库。当内存不够时,只将热点数据放入内存,其他数据存在磁盘。
读取性能: redis读写性能测试redis官网测试读写能到10w/s左右 mysql读能力5K/s、写能力为3K/s
事物支持角度: mysql支持各种事物的操作。 Redis 事务支持比较弱,只能保证事务中的每个操作连续执行 。 mongodb不支持事物的操作。
虚拟机部分:
linux怎样去查看日志
第一种:查看实时变化的日志(比较吃内存)
最常用的:
tail -f filename (默认最后10行,相当于增加参数 -n 10)
Ctrl+c 是退出tail命令
其他情况:
tail -n 20 filename (显示filename最后20行)
tail -n +5 filename (从第5行开始显示文件
第二种:搜索关键字附近的日志
最常用的:
cat -n filename |grep "关键字
其他情况:
cat filename | grep -C 5 '关键字' (显示日志里匹配字串那行以及前后5行)
cat filename | grep -B 5 '关键字' (显示匹配字串及前5行)
cat filename | grep -A 5 '关键字' (显示匹配字串及后5行)
第三种:进入编辑查找:vi(vim)
1、进入vim编辑模式:vim filename
2、输入“/关键字”,按enter键查找
3、查找下一个,按“n”即可
退出:按ESC键后,接着再输入:号时,vi会在屏幕的最下方等待我们输入命令
wq 保存退出;
q! 不保存退出;
怎样在linux中清空一个文件
1、> /var/log/asterisk/messages 或者 :> /var/log/asterisk/messages (文件大小被截为0字节) 2、cat /dev/null > /var/log/asterisk/messages (文件大小被截为0字节)
3、echo "" > /var/log/asterisk/messages(文件大小被截为1字节)
怎样定位到linux中的最一行
输入大G,或者shitf+g
Linux中常用的指令
-
ls: 列出文件的列表
-
mkdir 目录名称: 创建目录
-
rmdir 目录名称: 删除目录
-
tail 文件名: 显示文件最后几行
-
tar -xvf 文件目录: 打包
-
tar -zcvf 压缩包名: 打包并压缩
-
grep 字符串名: 查找字符串
-
pwd: 显示所在的目录
-
touch 文件夹名称: 创建空文件夹
-
vim 文件名称:编辑文件
-
cp /etc/passwd ./passwd1: //拷贝,cp 拷贝对象 目标路径/更改文件名,点表示当前路径
-
mv /mnt/shadow /opt: //移动,mv 原文件 目标路径
-
rm 文件/文件夹名称: //删除
-
yum -y install 软件名...: //安装软件
-
poweroff: 关机
-
reboot : //重启
docker技术
docker技术是一个容器和虚拟机具有相似的资源隔离和分配优势,但功能有所不同,虚拟机虚拟化的是硬件,而容器虚拟化的是操作系统,因此容器更容易移植,效率也更高。
docker技术的特点:
(1)上手快
用户只需要几分钟,就可以把自己的程序“Docker化”。Docker依赖于“写时复制”(copy-on-write)模型,使修改应用程序也非常迅速,可以说达到“随心所致,代码即改”的境界。
随后,就可以创建容器来运行应用程序了。大多数Docker容器只需要不到1秒中即可启动。由于去除了管理程序的开销,Docker容器拥有很高的性能,同时同一台宿主机中也可以运行更多的容器,使用户尽可能的充分利用系统资源。
(2)职责的逻辑分类
使用Docker,开发人员只需要关心容器中运行的应用程序,而运维人员只需要关心如何管理容器。Docker设计的目的就是要加强开发人员写代码的开发环境与应用程序要部署的生产环境一致性。从而降低那种“开发时一切正常,肯定是运维的问题(测试环境都是正常的,上线后出了问题就归结为肯定是运维的问题)”
(3)快速高效的开发生命周期
Docker的目标之一就是缩短代码从开发、测试到部署、上线运行的周期,让你的应用程序具备可移植性,易于构建,并易于协作。(通俗一点说,Docker就像一个盒子,里面可以装很多物件,如果需要这些物件的可以直接将该大盒子拿走,而不需要从该盒子中一件件的取。)
(4)鼓励使用面向服务的架构
Docker还鼓励面向服务的体系结构和微服务架构。Docker推荐单个容器只运行一个应用程序或进程,这样就形成了一个分布式的应用程序模型,在这种模型下,应用程序或者服务都可以表示为一系列内部互联的容器,从而使分布式部署应用程序,扩展或调试应用程序都变得非常简单,同时也提高了程序的内省性。(当然,可以在一个容器中运行多个应用程序)
39.docekr的常用的指令
操作docker容器集合的指令:
-
l 启动docker:systemctl start docker
-
l 停止docker:systemctl stop docker
-
l 重启docker:systemctl restart docker
-
l 查看docker状态:systemctl status docker
-
l 开机启动:systemctl enable docker
操作docker中的镜像的常用的操作的命令:
-
l 查看本地的镜像:docker images
-
l 查询搜索注册中心中的镜像:docker search 镜像名称
-
l 镜像的拉取与下载:docker pull 镜像的名字
-
l 删除指定的镜像:docker rmi 镜像编号(image id)/镜像名字:版本标记
-
l 删除所有的镜像:docker rmi
docker images -q
Container容器的常用的操作:
-
l 查看正在运行的容器:docker ps
-
l 查看所有的容器(包括运行和关闭的):docker ps -a
-
l 查看最后一次运行的容器信息:docker ps -l
-
l 查看停止了的容器列表:docker ps -f status=exited
-
l 停止一个正在运行的容器(守护式容器):docker stop $CONTAINER_NAME(容器的名称)/ID(编号)
-
| 启动一个已经运行过的容器: docker start $CONTAINER_NAME(容器的名称)/ID(编号)
-
| 重启一个容器:docker restart $CONTAINER_NAME(容器的名称)/ID(编号)
-
| 删除一个容器:docker rm 容器的ID
l 创建一个交互式的容器:docker run -it --name=mycentos centos:7.5.1804 /bin/bash
交互式容器的优点:
创建完容器后,自动运行容器,并可以直接进入到子容器系统中操作了。
缺点:
当退出子容器后,该容器会自动停止运行。
| 创建一个守护式的容器: docker run -id --name=mycentos2 centos:7.5.1804 或 docker run -id --name mycentos2 centos:7.5.1804
l 登录守护式容器的方法:docker exec -it container_name (或者 container_id) /bin/bash(exit退出时,容器不会停止)
守护式容器的优点:
从守护式容器中退出,并不影响容器的运行。
缺点:
必须的手动命令进入到容器。
前端部分:
跨域解决的方式:
crous:微服务项目中使用的跨域中的技术。 原理: CORS是一个W3C标准,全称是"跨域资源共享",它允许浏览器跨域进行数据的请求,从而克服了ajax只能同源使用的限制。浏览器一旦发现AJAX请求跨源,就会自动添加一些附加的头信息,有时还会多出一次附加的请求,但用户不会有感觉。因此,实现CORS通信的关键是服务器。只要服务器实现了CORS接口,就可以跨源通信。https://www.cnblogs.com/cityspace/p/6858969.html
什么是CORS?
CORS是一个W3C标准,全称是"跨域资源共享"(Cross-origin resource sharing)。
它允许浏览器向跨源服务器,发出XMLHttpRequest请求,从而克服了AJAX只能同源使用的限制。
CORS需要浏览器和服务器同时支持。目前,所有浏览器都支持该功能,IE浏览器不能低于IE10。
-
浏览器端:
目前,所有浏览器都支持该功能(IE10以下不行)。整个CORS通信过程,都是浏览器自动完成,不需要用户参与。
-
服务端:
CORS通信与AJAX没有任何差别,因此你不需要改变以前的业务逻辑。只不过,浏览器会在请求中携带一些头信息,我们需要以此判断是否允许其跨域,然后在响应头中加入一些信息即可。这一般通过过滤器完成即可。
jsonp: 原理: jsonp的最基本的原理是:动态添加一个