大数据开发基础入门与项目实战(三)Hadoop核心及生态圈技术栈之2.HDFS分布式文件系统
文章目录
- 前言
- 1.HDFS特点
- 2.命令行和API操作HDFS
-
- (1)Shell命令行客户端
- (2)API客户端连接HDFS的两种方式
- (3)API客户端上传下载文件
- (4)API客户端文件详情及文件类型判断
- (5)API客户端IO流操作
- (6)API客户端IO流的seek读取
- 3.HDFS读写机制解析
- 4.HDFS元数据管理机制
-
- (1)Namenode、Fsimage及Edits编辑日志
- (2)2NN及CheckPoint检查点
- (3)Fsimage及Edits文件解析
- (4)CheckPoint周期和NameNode故障处理
- 5.Hadoop限额、归档及集群安全模式
- 6.日志采集案例
-
- (1)需求分析
- (2)调度功能实现
- (3)采集上传功能实现
- (4)程序调优
前言
本文主要介绍了HDFS分布式文件系统,包括HDFS特点、命令行和API操作HDFS、HDFS读写机制解析、HDFS元数据管理机制、Hadoop限额、归档及集群安全模式和日志采集案例。
1.HDFS特点
HDFS(全称Hadoop Distribute File System,Hadoop分布式文件系统)是 Hadoop 核心组成,是分布式存储服务。
分布式文件系统横跨多台计算机,在大数据时代有着广泛的应用前景,它们为存储和处理超大规模数据提供所需的扩展能力。
HDFS是分布式文件系统中的一种。
HDFS 通过统一的命名空间目录树来定位文件; 另外,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色(分布式本质是拆分,各司其职)。
HDFS的常见特点如下:
- 典型的 Master/Slave(主从) 架构
HDFS 的架构是典型的 Master/Slave 结构。
NameNode是集群的主节点,DataNode是集群的从节点,共同协作来完成分布式数据存储任务。
HDFS集群往往是由一个NameNode(其中HA架构和联邦机制除外,HA架构有两个NameNode,联邦机制有多个NameNode)+多个DataNode组成。
- 分块存储(block机制)
HDFS 中的文件在物理上是分块存储(block)的,块的大小可以通过配置参数来规定;
Hadoop2.x版本中默认的block大小是128M,当文件大于128block大小时,由HDFS进行自动切分,分块对我们来说是无感的。
- 命名空间(NameSpace)
HDFS 支持传统的层次型文件组织结构,用户或者应用程序可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名文件。
Namenode 负责维护文件系统的名字空间,任何对文件系统名字空间或属性的修改都将被Namenode 记录下来。
即HDFS提供给客户一个单独的(类似于Linux的)抽象目录树,访问形式是hdfs://NameNode的hostname:port/目录,例如hdfs://node01:9000/test/input。
- NameNode元数据管理
把目录结构及文件分块位置信息叫做元数据。
NameNode的元数据记录每一个文件所对应的block信息(block的id以及所在的DataNode节点的信息)。
- DataNode数据存储
文件的各个 block 的具体存储管理由 DataNode 节点承担。
一个block会有多个DataNode来存储,DataNode会定时向NameNode来汇报 自己持有的block信息,以便NameNode及时掌控集群的状态信息,来保证数据的安全性和任务执行的及时性。
- 副本机制
为了容错,文件的所有 block 都会有副本。每个文件的 block 大小和副本系数都是可配置的。应用程序可以指定某个文件的副本数目。副本系数可以在文件创建的时候指定,也可以在之后改变。
副本数量默认是3个(包含原始block)。
- 一次写入,多次读出
HDFS 是设计成适应一次写入、多次读出的场景,且不支持文件的随机修改 。 (支持追加写入,不只支持随机更新)。
正因为如此,HDFS 适合用来做大数据分析的底层存储服务,并不适合用来做网盘等应用(修改不方便,延迟大,网络开销大,成本太高)。
HDFS架构如下:

各个角色的作用如下:
(1)NameNode(nn)——HDFS集群的管理者,Master
-
维护管理HDFS的名称空间(NameSpace)
-
维护副本策略
出现问题后,会从不同的机架读取副本数据。
-
记录文件块(Block)的映射信息
-
负责处理客户端读写请求
(2)DataNode——NameNode下达命令,DataNode执行实际操作,Slave节点
-
保存实际的数据块
-
负责数据块的读写
(3)Client——客户端
-
上传文件到HDFS的时候,Client负责将文件切分成Block,然后进行上传
-
请求NameNode交互,主要是为了获取文件block的位置信息
-
取或写入文件,与DataNode交互
-
Client可以使用一些命令来管理HDFS或者访问HDFS
2.命令行和API操作HDFS
(1)Shell命令行客户端
HDFS客户端操作有两种方式:Shell命令行和Java API。
先使用Shell命令行操作HDFS。
基本语法格式为:
hadoop fs -具体命令 / hdfs dfs -具体命令
查看命令大全如下:
[root@node01 ~]$ hadoop fs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-x] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {
-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{
-b|-k} {
-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {
-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
Generic options supported are:
-conf <configuration file> specify an application configuration file
-D <property=value> define a value for a given property
-fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations.
-jt <local|resourcemanager:port> specify a ResourceManager
-files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster
-libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath
-archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines
The general command line syntax is:
command [genericOptions] [commandOptions]
可以看到,HDFS的很多命令都和Linux中相似,只是需要在命令前面加-作为HDFS命令的选项,同时有很多可选参数进行选择;
还有一些支持的通用选项,例如-conf可以指定副本数量,-D以key-value的形式指定配置项,-fs指定文件系统等等;
hdfs dfs命令和hadoop fs是一样的效果,但是推荐使用前者。
现在使用HDFS命令如下:
(1)-help:输出命令参数的帮助信息
[root@node01 ~]$ hdfs dfs -help mv
-mv <src> ... <dst> :
Move files that match the specified file pattern <src> to a destination <dst>.
When moving multiple files, the destination must be a directory.
(2)-ls:显示目录信息
[root@node01 ~]$ hdfs dfs -ls /
Found 4 items
drwxr-xr-x - root supergroup 0 2021-08-25 20:23 /test
drwx------ - root supergroup 0 2021-08-26 00:36 /tmp
drwxr-xr-x - root supergroup 0 2021-08-25 22:33 /wcinput
drwxr-xr-x - root supergroup 0 2021-08-26 00:37 /wcoutput
[root@node01 ~]$ ls
anaconda-ks.cfg lxDemo test.txt wc.txt
可以看到,hdfs dfs -ls /是操作HDFS的文件系统,ls是操作Linux本地的操作系统,两者是不同的,同时HDFS中的ls命令相当于Linux中的ll命令或ls -l。
(3)-mkdir:在HDFS上创建目录
[root@node01 ~]$ hdfs dfs -mkdir -p /cl/bigdata
[root@node01 ~]$ hdfs dfs -ls /
Found 5 items
drwxr-xr-x - root supergroup 0 2021-08-26 19:22 /cl
drwxr-xr-x - root supergroup 0 2021-08-25 20:23 /test
drwx------ - root supergroup 0 2021-08-26 00:36 /tmp
drwxr-xr-x - root supergroup 0 2021-08-25 22:33 /wcinput
drwxr-xr-x - root supergroup 0 2021-08-26 00:37 /wcoutput
[root@node01 ~]$ hdfs dfs -ls /cl/
Found 1 items
drwxr-xr-x - root supergroup 0 2021-08-26 19:22 /cl/bigdata
(4)-moveFromLocal:从本地剪切粘贴到HDFS
[root@node01 ~]$ vim hadoop.txt
# 输入内容为:
# hadoop new file
[root@node01 ~]$ ll
总用量 20
-rw-------. 1 root root 1259 8月 19 03:28 anaconda-ks.cfg
-rw-r--r-- 1 root root 16 8月 26 19:37 hadoop.txt
drwxr-xr-x. 3 root root 4096 8月 24 21:07 lxDemo
-rw-r--r-- 1 root root 12 8月 25 20:26 test.txt
-rw-r--r-- 1 root root 967 8月 25 22:26 wc.txt
[root@node01 ~]$ hdfs dfs -moveFromLocal hadoop.txt /cl/bigdata
[root@node01 ~]$ ll
总用量 16
-rw-------. 1 root root 1259 8月 19 03:28 anaconda-ks.cfg
drwxr-xr-x. 3 root root 4096 8月 24 21:07 lxDemo
-rw-r--r-- 1 root root 12 8月 25 20:26 test.txt
-rw-r--r-- 1 root root 967 8月 25 22:26 wc.txt
[root@node01 ~]$ hdfs dfs -ls /cl/bigdata
Found 1 items
-rw-r--r-- 3 root supergroup 16 2021-08-26 19:37 /cl/bigdata/hadoop.txt
可以看到, 在操作后,本地文件被移动到HDFS文件系统中。
(5)-cat:显示文件内容
[root@node01 ~]$ hdfs dfs -cat /cl/bigdata/hadoop.txt
hadoop new file
(6)-appendToFile:追加一个文件到已经存在的文件末尾
[root@node01 ~]$ vim hdfs.txt
[root@node01 ~]$ hdfs dfs -appendToFile hdfs.txt /cl/bigdata/hadoop.txt
[root@node01 ~]$ hdfs dfs -cat /cl/bigdata/hadoop.txt
hadoop new file
namenode datanode block replication
[root@node01 ~]$ ll
总用量 20
-rw-------. 1 root root 1259 8月 19 03:28 anaconda-ks.cfg
-rw-r--r-- 1 root root 36 8月 26 19:41 hdfs.txt
drwxr-xr-x. 3 root root 4096 8月 24 21:07 lxDemo
-rw-r--r-- 1 root root 12 8月 25 20:26 test.txt
-rw-r--r-- 1 root root 967 8月 25 22:26 wc.txt
可以看到,将本地文件的内容追加到了HDFS中的文件末尾,同时本地文件也没有被删除。
(7)-chgrp 、-chmod、-chown:修改文件所属权限,用法和Linux文件系统中一样
[root@node01 ~]$ hdfs dfs -ls /cl/bigdata/
Found 1 items
-rw-r--r-- 3 root supergroup 52 2021-08-26 19:41 /cl/bigdata/hadoop.txt
[root@node01 ~]$ hdfs dfs -chmod 777 /cl/bigdata/hadoop.txt
[root@node01 ~]$ hdfs dfs -ls /cl/bigdata/
Found 1 items
-rwxrwxrwx 3 root supergroup 52 2021-08-26 19:41 /cl/bigdata/hadoop.txt
[root@node01 ~]$ hdfs dfs -chown root:root /cl/bigdata/hadoop.txt
[root@node01 ~]$ hdfs dfs -ls /cl/bigdata/
Found 1 items
-rwxrwxrwx 3 root root 52 2021-08-26 19:41 /cl/bigdata/hadoop.txt
(8)-copyFromLocal:从本地文件系统中拷贝文件到HDFS路径
[root@node01 ~]$ ll
总用量 20
-rw-------. 1 root root 1259 8月 19 03:28 anaconda-ks.cfg
-rw-r--r-- 1 root root 36 8月 26 19:41 hdfs.txt
drwxr-xr-x. 3 root root 4096 8月 24 21:07 lxDemo
-rw-r--r-- 1 root root 12 8月 25 20:26 test.txt
-rw-r--r-- 1 root root 967 8月 25 22:26 wc.txt
[root@node01 ~]$ cat test.txt
hello, hdfs
[root@node01 ~]$ hdfs dfs -copyFromLocal test.txt /cl/bigdata
[root@node01 ~]$ ll
总用量 20
-rw-------. 1 root root 1259 8月 19 03:28 anaconda-ks.cfg
-rw-r--r-- 1 root root 36 8月 26 19:41 hdfs.txt
drwxr-xr-x. 3 root root 4096 8月 24 21:07 lxDemo
-rw-r--r-- 1 root root 12 8月 25 20:26 test.txt
-rw-r--r-- 1 root root 967 8月 25 22:26 wc.txt
[root@node01 ~]$ hdfs dfs -ls /cl/bigdata
Found 2 items
-rwxrwxrwx 3 root root 52 2021-08-26 19:41 /cl/bigdata/hadoop.txt
-rw-r--r-- 3 root supergroup 12 2021-08-26 19:56 /cl/bigdata/test.txt
[root@node01 ~]$ hdfs dfs -cat /cl/bigdata/test.txt
hello, hdfs
可以看到,-copyFromLocal方式会保留原数据文件。
(9)-copyToLocal:从HDFS拷贝到本地
[root@node01 ~]$ ll
总用量 20
-rw-------. 1 root root 1259 8月 19 03:28 anaconda-ks.cfg
-rw-r--r-- 1 root root 36 8月 26 19:41 hdfs.txt
drwxr-xr-x. 3 root root 4096 8月 24 21:07 lxDemo
-rw-r--r-- 1 root root 12 8月 25 20:26 test.txt
-rw-r--r-- 1 root root 967 8月 25 22:26 wc.txt
[root@node01 ~]$ hdfs dfs -copyToLocal /cl/bigdata/hadoop.txt .
[root@node01 ~]$ hdfs dfs -ls /cl/bigdata
Found 2 items
-rwxrwxrwx 3 root root 52 2021-08-26 19:41 /cl/bigdata/hadoop.txt
-rw-r--r-- 3 root supergroup 12 2021-08-26 19:56 /cl/bigdata/test.txt
[root@node01 ~]$ ll
总用量 24
-rw-------. 1 root root 1259 8月 19 03:28 anaconda-ks.cfg
-rw-r--r-- 1 root root 52 8月 26 20:01 hadoop.txt
-rw-r--r-- 1 root root 36 8月 26 19:41 hdfs.txt
drwxr-xr-x. 3 root root 4096 8月 24 21:07 lxDemo
-rw-r--r-- 1 root root 12 8月 25 20:26 test.txt
-rw-r--r-- 1 root root 967 8月 25 22:26 wc.txt
[root@node01 ~]$ cat hadoop.txt
hadoop new file
namenode datanode block replication
可以看到, HDF是中的数据文件保留,同时本地也得到了拷贝的文件。
(10)-cp:从HDFS的一个路径拷贝到HDFS的另一个路径
[root@node01 ~]$ hdfs dfs -ls /
Found 5 items
drwxr-xr-x - root supergroup 0 2021-08-26 19:22 /cl
drwxr-xr-x - root supergroup 0 2021-08-25 20:23 /test
drwx------ - root supergroup 0 2021-08-26 00:36 /tmp
drwxr-xr-x - root supergroup 0 2021-08-25 22:33 /wcinput
drwxr-xr-x - root supergroup 0 2021-08-26 00:37 /wcoutput
[root@node01 ~]$ hdfs dfs -cp /cl/bigdata/hadoop.txt /
[root@node01 ~]$ hdfs dfs -ls /
Found 6 items
drwxr-xr-x - root supergroup 0 2021-08-26 19:22 /cl
-rw-r--r-- 3 root supergroup 52 2021-08-26 20:07 /hadoop.txt
drwxr-xr-x - root supergroup 0 2021-08-25 20:23 /test
drwx------ - root supergroup 0 2021-08-26 00:36 /tmp
drwxr-xr-x - root supergroup 0 2021-08-25 22:33 /wcinput
drwxr-xr-x - root supergroup 0 2021-08-26 00:37 /wcoutput
(11)-mv:在HDFS目录中移动文件
[root@node01 ~]$ hdfs dfs -ls /test
Found 1 items
drwxr-xr-x - root supergroup 0 2021-08-25 20:24 /test/input
[root@node01 ~]$ hdfs dfs -mv /hadoop.txt /test
[root@node01 ~]$ hdfs dfs -ls /test
Found 2 items
-rw-r--r-- 3 root supergroup 52 2021-08-26 20:07 /test/hadoop.txt
drwxr-xr-x - root supergroup 0 2021-08-25 20:24 /test/input
(12)-get:等同于copyToLocal,就是从HDFS下载文件到本地
[root@node01 ~]$ ll
总用量 24
-rw-------. 1 root root 1259 8月 19 03:28 anaconda-ks.cfg
-rw-r--r-- 1 root root 52 8月 26 20:14 hadoop.txt
-rw-r--r-- 1 root root 36 8月 26 19:41 hdfs.txt
drwxr-xr-x. 3 root root 4096 8月 24 21:07 lxDemo
-rw-r--r-- 1 root root 12 8月 25 20:26 test.txt
-rw-r--r-- 1 root root 967 8月 25 22:26 wc.txt
[root@node01 ~]$ rm -f hadoop.txt
[root@node01 ~]$ ll
总用量 20
-rw-------. 1 root root 1259 8月 19 03:28 anaconda-ks.cfg
-rw-r--r-- 1 root root 36 8月 26 19:41 hdfs.txt
drwxr-xr-x. 3 root root 4096 8月 24 21:07 lxDemo
-rw-r--r-- 1 root root 12 8月 25 20:26 test.txt
-rw-r--r-- 1 root root 967 8月 25 22:26 wc.txt
[root@node01 ~]$ hdfs dfs -get /cl/bigdata/hadoop.txt .
[root@node01 ~]$ ll
总用量 24
-rw-------. 1 root root 1259 8月 19 03:28 anaconda-ks.cfg
-rw-r--r-- 1 root root 52 8月 26 20:15 hadoop.txt
-rw-r--r-- 1 root root 36 8月 26 19:41 hdfs.txt
drwxr-xr-x. 3 root root 4096 8月 24 21:07 lxDemo
-rw-r--r-- 1 root root 12 8月 25 20:26 test.txt
-rw-r--r-- 1 root root 967 8月 25 22:26 wc.txt
[root@node01 ~]$ cat hadoop.txt
hadoop new file
namenode datanode block replication
(13)-put:等同于copyFromLocal,将文件从本地上传到HDFS中
[root@node01 ~]$ vim yarn.txt
[root@node01 ~]$ hdfs dfs -mkdir -p /user/root/test/
[root@node01 ~]$ ll
总用量 28
-rw-------. 1 root root 1259 8月 19 03:28 anaconda-ks.cfg
-rw-r--r-- 1 root root 52 8月 26 20:15 hadoop.txt
-rw-r--r-- 1 root root 36 8月 26 19:41 hdfs.txt
drwxr-xr-x. 3 root root 4096 8月 24 21:07 lxDemo
-rw-r--r-- 1 root root 12 8月 25 20:26 test.txt
-rw-r--r-- 1 root root 967 8月 25 22:26 wc.txt
-rw-r--r-- 1 root root 28 8月 26 20:18 yarn.txt
[root@node01 ~]$ hdfs dfs -put yarn.txt /user/root/test/
[root@node01 ~]$ hdfs dfs -ls /user/root/test/
Found 1 items
-rw-r--r-- 3 root supergroup 28 2021-08-26 20:21 /user/root/test/yarn.txt
(14)-tail:显示一个文件的末尾
[root@node01 ~]$ hdfs dfs -tail /user/root/test/yarn.txt
resourcemanager nodemanager
(15)-rm:删除文件或文件夹
[root@node01 ~]$ hdfs dfs -rm /user/root/test/yarn.txt
Deleted /user/root/test/yarn.txt
[root@node01 ~]$ hdfs dfs -ls /user/root/test/
可以看到,此时可以不用提示,直接删除。
(16)-rmdir:删除空目录
[root@node01 ~]$ hdfs dfs -rmdir /user/root/test/
[root@node01 ~]$ hdfs dfs -ls /user/root/
(17)-du统计文件夹的大小信息
[root@node01 ~]$ hdfs dfs -put wc.txt /test/input/
[root@node01 ~]$ hdfs dfs -du /test/
52 /test/hadoop.txt
979 /test/input
[root@node01 ~]$ hdfs dfs -du -s -h /test/
1.0 K /test
[root@node01 ~]$ hdfs dfs -du -h /test/
52 /test/hadoop.txt
979 /test/input
其中,hdfs dfs -du -s -h /test/是统计指定目录下文件夹的大小,并以人性化的形式展示;
hdfs dfs -du -h /test/统计指定目录下所有内容的大小,并以人性化的形式展示。
(18)-setrep:设置HDFS中文件的副本数量
设置/test/hadoop.txt的副本之前,默认的副本数为3,如下:

现在进行设置:
[root@node01 ~]$ hdfs dfs -setrep 5 /test/hadoop.txt
Replication 5 set: /test/hadoop.txt
现在重新查看,如下:
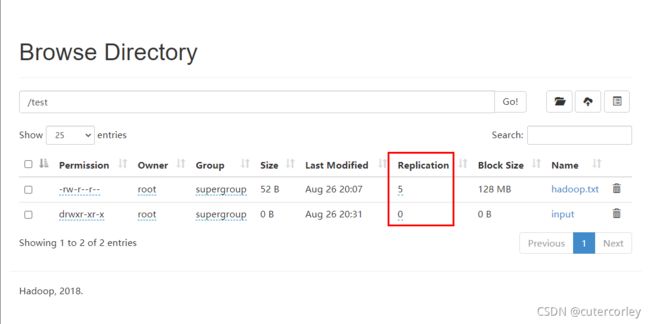
可以看到,副本数已经设置为5;
但是副本的数量大于节点数,是没有意义的,因为副本数了大于节点数时,说明至少有一个节点有多个副本,因为副本的作用是容错,即在某个节点出现错误的时候可以使用其他节点的副本,所以出错的这个节点有再多的节点都是没有区别的;
文件的真正副本数量取决于DataNode的数量,目前只有3台设备,最多也就3个副本,只有节点数的增加到5台时,副本数才能达到5。
(2)API客户端连接HDFS的两种方式
现在使用API操作HDFS。
在使用之前,需要先准备客户端环境:
(1)将Hadoop-2.9.2安装包解压到非中文路径
将之前上传到虚拟机上的Hadoop安装包解压到本地,需要选择非中文路径,再解压。
(2)配置环境变量
先配置HADOOP_HOME环境变量,即配置Hadoop解压包的路径,例如E:\Java\hadoop-2.9.2,配置如下:

再配置Path环境变量,如下:

(3)创建一个Maven工程ClientDemo
在IDEA中新建Maven Project,如下:
输入Project Name等信息:
点击完成创建。
(4)导入相应的依赖坐标和日志配置文件
Maven工程中关于Hadoop的配置项有hadoop-common、hadoop-client、hadoop-hdfs三项,具体配置可以在https://www.mvnrepository.com/中进行查询。
配置pom.xml下:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.bigdata.hdfsgroupId>
<artifactId>HDFSClientDemoartifactId>
<version>1.0-SNAPSHOTversion>
<dependencies>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.13.2version>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-coreartifactId>
<version>2.8.2version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>2.9.2version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.9.2version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>2.9.2version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.13.1version>
<scope>compilescope>
dependency>
dependencies>
<properties>
<maven.compiler.source>11maven.compiler.source>
<maven.compiler.target>11maven.compiler.target>
properties>
project>
因为是第一次使用,所以编辑好之后需要下载依赖,如下:
选择IDEA右下角Import Changes即可下载依赖,或者点击同步Maven依赖,下载可能需要较长的时间,需要等待下载并解决相关依赖;
同时,为了后面统计和验证代码方便,还需要引如junit测试和log4j控制日志打印输出级别。
为了便于控制程序运行打印的日志数量,需要在项目的src/main/resources目录下,新建一个文件,命名为log4j.properties,文件内容如下:
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
可以根据日志的输出情况修改log4j.rootLogger的值。
(5)创建包和客户端类
在项目的src/main/java目录下创建com.cl.hdfs包;
在包下创建HdfsClientDemo类,如下:
package com.bigdata.hdfs;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test;
import org.apache.hadoop.conf.Configuration;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* @author Corley
* @date 2021/8/29 19:02
* @description HDFSClientDemo-com.bigdata.hdfs
*/
public class HdfsClientDemo {
@Test
public void testMkdirs() throws URISyntaxException, IOException, InterruptedException {
// 1.获取Hadoop集群的Configuration对象
Configuration configuration = new Configuration();
// 2.根据Configuration对象获取FileSystem对象
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:9000"), configuration, "root");
// 3.使用FileSystem对象创建测试目录
fileSystem.mkdirs(new Path("/api_test"));
// 4.释放FileSystem对象
fileSystem.close();
}
}
执行后,查看文件系统:
[root@node01 ~]$ hdfs dfs -ls /
Found 7 items
drwxr-xr-x - root supergroup 0 2021-09-01 17:59 /api_test
drwxr-xr-x - root supergroup 0 2021-08-26 19:22 /cl
drwxr-xr-x - root supergroup 0 2021-08-26 20:11 /test
drwx------ - root supergroup 0 2021-08-26 00:36 /tmp
drwxr-xr-x - root supergroup 0 2021-08-26 20:19 /user
drwxr-xr-x - root supergroup 0 2021-08-25 22:33 /wcinput
drwxr-xr-x - root supergroup 0 2021-08-26 00:37 /wcoutput
可以看到,已经在根目录下创建了api_test目录。
需要注意:
Windows解压安装Hadoop后,在调用相关API操作HDFS集群时可能会报错,如下图:

这是由于Hadoop安装缺少Windows操作系统相关文件所致,Windows作为客户端读取Linux的文件,但是客户端没有Hadoop的环境 ,所以需要重新在Windows上面编译Hadoop,编译出Windows版本的客户端。
解决办法是将winutils.exe拷贝放到Windows系统Hadoop安装目录的bin目录下即可;
同时还需要hadoop.dll,也需要拷贝到相同目录下。
如需要winutils.exe和hadoop.dll文件,可点击下方进行下载:
Windows安装Hadoop的bin所需文件.zip
如果遇到HADOOP_HOME and hadoop.home.dir are unset问题,可以参考https://www.136.la/nginx/show-147746.html进行解决。
前面是调用FileSystem类的public static FileSystem get(final URI uri, final Configuration conf, String user)方法生成FileSystem对象的。
还可以通过另一种方式生成FileSystem对象,如下:
package com.bigdata.hdfs;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test;
import org.apache.hadoop.conf.Configuration;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* @author Corley
* @date 2021/8/29 19:02
* @description HDFSClientDemo-com.bigdata.hdfs
*/
public class HdfsClientDemo {
@Test
public void testMkdirs() throws URISyntaxException, IOException, InterruptedException {
// 1.获取Hadoop集群的Configuration对象
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://node01:9000");
// 2.根据Configuration对象获取FileSystem对象
// FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:9000"), configuration, "root");
FileSystem fileSystem = FileSystem.get(configuration);
// 3.使用FileSystem对象创建测试目录
fileSystem.mkdirs(new Path("/api_test1"));
// 4.释放FileSystem对象
fileSystem.close();
}
}
执行时,不能成功,会报错:
org.apache.hadoop.security.AccessControlException: Permission denied: user=cuter¿ÆÀ, access=WRITE, inode="/":root:supergroup:drwxr-xr-x
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:350)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:251)
...
显然, 此时是访问控制出现了问题。
因为HDFS文件系统有文件访问控制,属主和数组是root和supergroup,但是第二种方式没有指定操作HDFS集群的用户信息,默认获取当前操作系统的用户信息,这里使用的是Windows的登录用户,出现权限被拒绝的问题。
HDFS文件系统权限问题:
HDFS的文件权限机制与Linux系统的文件权限机制类似,都是r:read、w:write、x:execute ,其中,权限x对于文件表示忽略,对于文件夹表示是否有权限访问其内容。
如果Linux系统用户Corley使用HDFS命令创建一个文件,那么这个文件在HDFS当中的owner就是Corley,HDFS文件权限的目的是防止好人做错事,而不是阻止坏人做坏事,HDFS相信“你告诉我你是谁,你就是谁”,所以权限访问没有较高的约束力和安全性,生产中不能直接使用。
此时有3种解决方案:
- 指定用户信息获取FileSystem对象
前面第一种生成FileSystem对象的方式即为本方式。
- 关闭HDFS集群权限校验
编辑hdfs-site.xml,添加如下属性:
<property>
<name>dfs.permissionsname>
<value>truevalue>
property>
修改完成之后要分发到其他节点,并重启HDFS集群。
- 放弃HDFS的权限校验
基于HDFS权限本身比较鸡肋的特点,可以彻底放弃HDFS的权限校验,生产环境中可以考虑借助Kerberos以及Sentry等安全框架来管理大数据集群安全。
具体方式是直接修改HDFS的根目录权限为777,即执行hdfs dfs -chmod -R 777 /。
现在使用第三种方式解决如下:
[root@node01 ~]$ hdfs dfs -chmod -R 777 /
[root@node01 ~]$ hdfs dfs -ls /
Found 7 items
drwxrwxrwx - root supergroup 0 2021-09-01 17:59 /api_test
drwxrwxrwx - root supergroup 0 2021-08-26 19:22 /cl
drwxrwxrwx - root supergroup 0 2021-08-26 20:11 /test
drwxrwxrwx - root supergroup 0 2021-08-26 00:36 /tmp
drwxrwxrwx - root supergroup 0 2021-08-26 20:19 /user
drwxrwxrwx - root supergroup 0 2021-08-25 22:33 /wcinput
drwxrwxrwx - root supergroup 0 2021-08-26 00:37 /wcoutput
可以看到,已经全部改为可执行权限。
此时再执行之前的代码,没有报错,再查看如下:
[root@node01 ~]$ hdfs dfs -ls /
Found 8 items
drwxrwxrwx - root supergroup 0 2021-09-01 17:59 /api_test
drwxr-xr-x - cuter¿ÆÀ supergroup 0 2021-09-01 19:43 /api_test1
drwxrwxrwx - root supergroup 0 2021-08-26 19:22 /cl
drwxrwxrwx - root supergroup 0 2021-08-26 20:11 /test
drwxrwxrwx - root supergroup 0 2021-08-26 00:36 /tmp
drwxrwxrwx - root supergroup 0 2021-08-26 20:19 /user
drwxrwxrwx - root supergroup 0 2021-08-25 22:33 /wcinput
drwxrwxrwx - root supergroup 0 2021-08-26 00:37 /wcoutput
此时成功创建api_test1目录,但是用户是Windows系统的登录用户。
综上,为了保证HDFS文件系统中的用户都是root用户,还是建议采用第一种方式指定用户。
(3)API客户端上传下载文件
先优化之前的代码,如下:
package com.bigdata.hdfs;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import org.apache.hadoop.conf.Configuration;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* @author Corley
* @date 2021/8/29 19:02
* @description HDFSClientDemo-com.bigdata.hdfs
*/
public class HdfsClientDemo {
FileSystem fileSystem = null;
Configuration configuration = null;
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
// 1.获取Hadoop集群的Configuration对象
configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://node01:9000");
// 2.根据Configuration对象获取FileSystem对象
fileSystem = FileSystem.get(new URI("hdfs://node01:9000"), configuration, "root");
}
@After
public void destroy() throws IOException {
// 释放FileSystem对象
fileSystem.close();
}
@Test
public void testMkdirs() throws URISyntaxException, IOException, InterruptedException {
// 使用FileSystem对象创建测试目录
fileSystem.mkdirs(new Path("/api_test2"));
}
}
使用junit的Before和After提取公共代码。
执行后,查看HDFS,如下:
[root@node01 ~]$ hdfs dfs -ls /
Found 9 items
drwxrwxrwx - root supergroup 0 2021-09-01 17:59 /api_test
drwxr-xr-x - cuter¿ÆÀ supergroup 0 2021-09-01 19:43 /api_test1
drwxr-xr-x - root supergroup 0 2021-09-01 22:06 /api_test2
drwxrwxrwx - root supergroup 0 2021-08-26 19:22 /cl
drwxrwxrwx - root supergroup 0 2021-08-26 20:11 /test
drwxrwxrwx - root supergroup 0 2021-08-26 00:36 /tmp
drwxrwxrwx - root supergroup 0 2021-08-26 20:19 /user
drwxrwxrwx - root supergroup 0 2021-08-25 22:33 /wcinput
drwxrwxrwx - root supergroup 0 2021-08-26 00:37 /wcoutput
可以看到,目录api_test2创建成功,说明代码优化成功。
现在测试客户端上传文件,如下:
package com.bigdata.hdfs;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import org.apache.hadoop.conf.Configuration;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* @author Corley
* @date 2021/8/29 19:02
* @description HDFSClientDemo-com.bigdata.hdfs
*/
public class HdfsClientDemo {
FileSystem fileSystem = null;
Configuration configuration = null;
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
// 1.获取Hadoop集群的Configuration对象
configuration = new Configuration();
// 2.根据Configuration对象获取FileSystem对象
fileSystem = FileSystem.get(new URI("hdfs://node01:9000"), configuration, "root");
}
@After
public void destroy() throws IOException {
// 释放FileSystem对象
fileSystem.close();
}
@Test
public void testMkdirs() throws URISyntaxException, IOException, InterruptedException {
// 使用FileSystem对象创建测试目录
fileSystem.mkdirs(new Path("/api_test2"));
}
@Test
public void testCopyFromLocalToHdfs() throws URISyntaxException, IOException, InterruptedException {
// 上传文件
// void copyFromLocalFile(Path src, Path dst)
fileSystem.copyFromLocalFile(new Path("E:/Test/tmp.txt"), new Path("/tmp.txt"));
}
}
其中,copyFromLocalFile(Path src, Path dst)方法的src参数代表源文件目录,即本地路径,dstc桉树代表目标文件目录,即HDFS路径。
运行后,查看HDFS,如下:
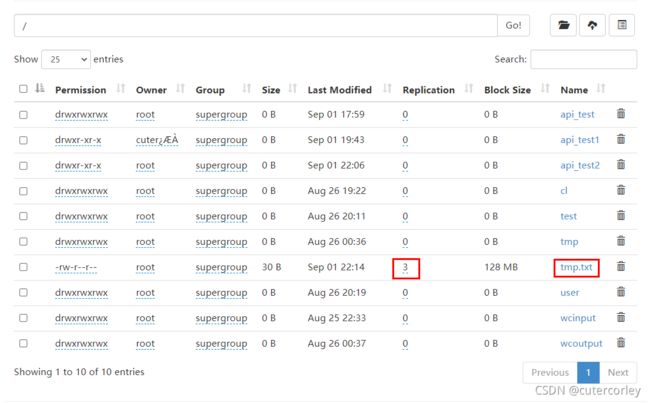
可以看到,通过这种方式上传文件到HDFS时,默认副本数量为3。
要想改变副本数量,有两种方式:
(1)通过Configuration对象设置
可以在Configuration对象中指定副本数量,如下:
package com.bigdata.hdfs;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import org.apache.hadoop.conf.Configuration;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* @author Corley
* @date 2021/8/29 19:02
* @description HDFSClientDemo-com.bigdata.hdfs
*/
public class HdfsClientDemo {
FileSystem fileSystem = null;
Configuration configuration = null;
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
// 1.获取Hadoop集群的Configuration对象
configuration = new Configuration();
configuration.set("dfs.replication", "2");
// 2.根据Configuration对象获取FileSystem对象
fileSystem = FileSystem.get(new URI("hdfs://node01:9000"), configuration, "root");
}
@After
public void destroy() throws IOException {
// 释放FileSystem对象
fileSystem.close();
}
@Test
public void testMkdirs() throws IOException {
// 使用FileSystem对象创建测试目录
fileSystem.mkdirs(new Path("/api_test2"));
}
@Test
public void testCopyFromLocalToHdfs() throws IOException {
// 上传文件
// void copyFromLocalFile(Path src, Path dst)
fileSystem.copyFromLocalFile(new Path("E:/Test/tmp.txt"), new Path("/tmp.txt"));
}
}
显示:

修改成功。
(2)通过新建XML配置文件设置
在resources目录下创建hdfs-site.xml文件,如下:
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
configuration>
代码中注释掉Configuration对象设置副本数量,如下:
package com.bigdata.hdfs;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import org.apache.hadoop.conf.Configuration;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* @author Corley
* @date 2021/8/29 19:02
* @description HDFSClientDemo-com.bigdata.hdfs
*/
public class HdfsClientDemo {
FileSystem fileSystem = null;
Configuration configuration = null;
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
// 1.获取Hadoop集群的Configuration对象
configuration = new Configuration();
// configuration.set("dfs.replication", "2");
// 2.根据Configuration对象获取FileSystem对象
fileSystem = FileSystem.get(new URI("hdfs://node01:9000"), configuration, "root");
}
@After
public void destroy() throws IOException {
// 释放FileSystem对象
fileSystem.close();
}
@Test
public void testMkdirs() throws IOException {
// 使用FileSystem对象创建测试目录
fileSystem.mkdirs(new Path("/api_test2"));
}
@Test
public void testCopyFromLocalToHdfs() throws IOException {
// 上传文件
// void copyFromLocalFile(Path src, Path dst)
fileSystem.copyFromLocalFile(new Path("E:/Test/tmp.txt"), new Path("/tmp.txt"));
}
}
执行后,查看:
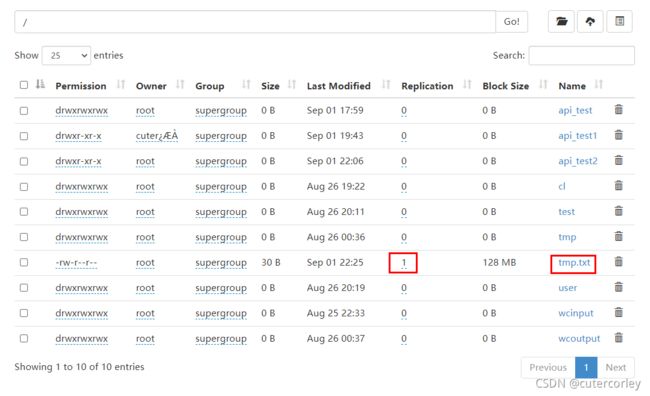
可以看到,此时也设置成功。
还可以查看,HDFS服务器的默认值,文件为XXX\org\apache\hadoop\hadoop-hdfs\2.9.2\hadoop-hdfs-2.9.2.jar!\hdfs-default.xml,如下:
<property>
<name>dfs.replicationname>
<value>3value>
<description>Default block replication.
The actual number of replications can be specified when the file is created.
The default is used if replication is not specified in create time.
description>
property>
可以看到,默认值为3。
可以得到,参数优先级如下:
代 码 中 设 置 的 值 > 用 户 自 定 义 配 置 文 件 > 服 务 器 的 默 认 配 置 代码中设置的值 >用户自定义配置文件 >服务器的默认配置 代码中设置的值>用户自定义配置文件>服务器的默认配置
再测试下载文件,如下:
package com.bigdata.hdfs;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import org.apache.hadoop.conf.Configuration;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* @author Corley
* @date 2021/8/29 19:02
* @description HDFSClientDemo-com.bigdata.hdfs
*/
public class HdfsClientDemo {
FileSystem fileSystem = null;
Configuration configuration = null;
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
// 1.获取Hadoop集群的Configuration对象
configuration = new Configuration();
// configuration.set("dfs.replication", "2");
// 2.根据Configuration对象获取FileSystem对象
fileSystem = FileSystem.get(new URI("hdfs://node01:9000"), configuration, "root");
}
@After
public void destroy() throws IOException {
// 释放FileSystem对象
fileSystem.close();
}
@Test
public void testMkdirs() throws IOException {
// 使用FileSystem对象创建测试目录
fileSystem.mkdirs(new Path("/api_test2"));
}
@Test
public void testCopyFromLocalToHdfs() throws IOException {
// 上传文件
// void copyFromLocalFile(Path src, Path dst)
fileSystem.copyFromLocalFile(new Path("E:/Test/tmp.txt"), new Path("/tmp.txt"));
}
@Test
public void testCopyFromHdfsToLocal() throws IOException {
// 下载文件
fileSystem.copyToLocalFile(true, new Path("/tmp.txt"), new Path("E:/Test/tmp-2.txt"));
}
}
其中,void copyToLocalFile(boolean delSrc, Path src, Path dst)方法的第一个参数表示是否删除源文件,这里为true表示删除。
执行后,查看HDFS,如下:
[root@node01 ~]$ hdfs dfs -ls /
Found 9 items
drwxrwxrwx - root supergroup 0 2021-09-01 17:59 /api_test
drwxr-xr-x - cuter¿ÆÀ supergroup 0 2021-09-01 19:43 /api_test1
drwxr-xr-x - root supergroup 0 2021-09-01 22:06 /api_test2
drwxrwxrwx - root supergroup 0 2021-08-26 19:22 /cl
drwxrwxrwx - root supergroup 0 2021-08-26 20:11 /test
drwxrwxrwx - root supergroup 0 2021-08-26 00:36 /tmp
drwxrwxrwx - root supergroup 0 2021-08-26 20:19 /user
drwxrwxrwx - root supergroup 0 2021-08-25 22:33 /wcinput
drwxrwxrwx - root supergroup 0 2021-08-26 00:37 /wcoutput
可以看到,源文件消失。
在查看本地,如下:
λ ls -a | grep tmp-2
.tmp-2.txt.crc
tmp-2.txt
可以看到,文件复制到了本地。
(4)API客户端文件详情及文件类型判断
先实现删除文件,如下:
@Test
public void testDeleteFile() throws IOException {
// 删除文件或文件夹
fileSystem.delete(new Path("/api_test1"), true);
}
执行后,查看HDFS:
[root@node01 ~]$ hdfs dfs -ls /
Found 8 items
drwxrwxrwx - root supergroup 0 2021-09-01 17:59 /api_test
drwxr-xr-x - root supergroup 0 2021-09-01 22:06 /api_test2
drwxrwxrwx - root supergroup 0 2021-08-26 19:22 /cl
drwxrwxrwx - root supergroup 0 2021-08-26 20:11 /test
drwxrwxrwx - root supergroup 0 2021-08-26 00:36 /tmp
drwxrwxrwx - root supergroup 0 2021-08-26 20:19 /user
drwxrwxrwx - root supergroup 0 2021-08-25 22:33 /wcinput
drwxrwxrwx - root supergroup 0 2021-08-26 00:37 /wcoutput
可以看到,删除成功。
再实现查看文件名称、权限、长度、块信息,如下:
@Test
public void testListFiles() throws IOException {
// 遍历HDFS根目录,获取文件及文件夹的信息(名称、权限和长度等)
// 获取迭代器
RemoteIterator<LocatedFileStatus> remoteIterator = fileSystem.listFiles(new Path("/"), true);
// 遍历迭代器
while (remoteIterator.hasNext()) {
LocatedFileStatus fileStatus = remoteIterator.next();
String name = fileStatus.getPath().getName(); // 文件名
long len = fileStatus.getLen(); // 文件长度
FsPermission permission = fileStatus.getPermission(); // 权限
String owner = fileStatus.getOwner(); // 用户
String group = fileStatus.getGroup(); // 分组
BlockLocation[] blockLocations = fileStatus.getBlockLocations(); // 块信息
System.out.println(name + "\t" + len + "\t" + permission + "\t" + owner + "\t" + group);
for (BlockLocation blockLocation : blockLocations) {
String[] hosts = blockLocation.getHosts(); // 块所在的主机信息
for (String host : hosts) {
System.out.println("主机名称:" + host);
}
}
}
}
输出:
hadoop.txt 52 rwxrwxrwx root root
主机名称:node01
主机名称:node03
主机名称:node02
test.txt 12 rwxrwxrwx root supergroup
主机名称:node02
主机名称:node03
主机名称:node01
hadoop.txt 52 rwxrwxrwx root supergroup
主机名称:node03
主机名称:node02
主机名称:node01
test.txt 12 rwxrwxrwx root supergroup
主机名称:node02
主机名称:node01
主机名称:node03
wc.txt 967 rwxrwxrwx root supergroup
主机名称:node02
主机名称:node03
主机名称:node01
job_1629895298908_0001-1629902194007-root-word+count-1629902239441-1-1-SUCCEEDED-default-1629902211805.jhist 33621 rwxrwxrwx root supergroup
主机名称:node01
主机名称:node03
主机名称:node02
job_1629895298908_0001_conf.xml 196008 rwxrwxrwx root supergroup
主机名称:node01
主机名称:node03
主机名称:node02
job_1629908848730_0001-1629909395692-root-word+count-1629909435182-1-1-SUCCEEDED-default-1629909411945.jhist 33635 rwxrwxrwx root supergroup
主机名称:node01
主机名称:node03
主机名称:node02
job_1629908848730_0001_conf.xml 196175 rwxrwxrwx root supergroup
主机名称:node01
主机名称:node02
主机名称:node03
node02_39947 103139 rwxrwxrwx root root
主机名称:node01
主机名称:node03
主机名称:node02
wc.txt 967 rwxrwxrwx root supergroup
主机名称:node02
主机名称:node01
主机名称:node03
_SUCCESS 0 rwxrwxrwx root supergroup
part-r-00000 624 rwxrwxrwx root supergroup
主机名称:node03
主机名称:node02
主机名称:node01
其中,public RemoteIterator方法的返回值类型是迭代器,包含了指定目录下的所有文件(夹)信息。
再实现判断文件或文件夹,如下:
@Test
public void testIsFile() throws IOException {
// 判断文件或文件夹
FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/"));
for (FileStatus fileStatus : fileStatuses) {
boolean flag = fileStatus.isFile();
if (flag) {
System.out.println("File: " + fileStatus.getPath().getName());
} else {
System.out.println("Dir: " + fileStatus.getPath().getName());
}
}
}
输出:
Dir: api_test
Dir: api_test2
Dir: cl
Dir: test
Dir: tmp
Dir: user
Dir: wcinput
Dir: wcoutput
可以看到,FileStatus[] listStatus(Path var1)方法只能获取到当前路径下的所有文件(夹)信息;
FileStatus[] listStatus(Path var1)方法和RemoteIterator方法存在一定的区别,前者只支持遍历当前目录,不支持递归当前目录下的所有内容,同时返回值为数组,后者支持递归遍历目录下的所有内容,并且返回值为迭代器。
(5)API客户端IO流操作
前面使用的API操作都是HDFS系统框架封装好的,也可以采用IO流的方式实现文件的上传和下载。
先实现上传文件,如下:
@Test
public void testUploadFileIO() throws IOException {
// 使用IO流操作HDFS——上传文件
// 1.输入流读取本地文件
FileInputStream inputStream = new FileInputStream("E:/Test/tmp.txt");
// 2.输出流写数据到HDFS
FSDataOutputStream outputStream = fileSystem.create(new Path("/tmp.txt"));
// 3.输入流数据拷贝到输出流
IOUtils.copyBytes(inputStream, outputStream, configuration);
// 4.关闭流对象
IOUtils.closeStream(outputStream);
IOUtils.closeStream(inputStream);
}
使用IO流操作HDFS的过程为,使用输入流读取本地文件,再使用HDFS的输出流写数据到HDFS文件系统;
其中,使用IOUtils工具类的void copyBytes(InputStream in, OutputStream out, Configuration conf)方法实现文件上传,调用了copyBytes(in, out, conf.getInt("io.file.buffer.size", 4096), true)方法,设置了默认的缓冲区大小为4096,同时关闭了流对象,所以第4步关闭流对象的步骤可以省略。
执行后,查看:
[root@node01 ~]$ hdfs dfs -ls /
Found 9 items
drwxrwxrwx - root supergroup 0 2021-09-01 17:59 /api_test
drwxr-xr-x - root supergroup 0 2021-09-01 22:06 /api_test2
drwxrwxrwx - root supergroup 0 2021-08-26 19:22 /cl
drwxrwxrwx - root supergroup 0 2021-08-26 20:11 /test
drwxrwxrwx - root supergroup 0 2021-08-26 00:36 /tmp
-rw-r--r-- 1 root supergroup 30 2021-09-02 10:59 /tmp.txt
drwxrwxrwx - root supergroup 0 2021-08-26 20:19 /user
drwxrwxrwx - root supergroup 0 2021-08-25 22:33 /wcinput
drwxrwxrwx - root supergroup 0 2021-08-26 00:37 /wcoutput
可以看到,文件上传成功。
再实现下载文件,如下:
@Test
public void testDownloadFileIO() throws IOException {
// 使用IO流操作HDFS——下载文件
// 1.输入流读取HDFS文件
FSDataInputStream inputStream = fileSystem.open(new Path("/tmp.txt"));
// 2.输出流保存到本地
FileOutputStream outputStream = new FileOutputStream("E:/Test/tmp-3.txt");
// 3.输入流数据拷贝到输出流
IOUtils.copyBytes(inputStream, outputStream, configuration);
}
执行后,查看:
λ ls -a | grep tmp
.tmp-2.txt.crc
tmp/
tmp.txt
tmp1/
tmp-2.txt
tmp-3.txt
可以看到,tmp-3.txt拷贝到本地;
显然,通过IO流的方式具有更大的灵活性。
(6)API客户端IO流的seek读取
可以通过seek 定位读取,即从某个偏移量开始读取文件。
现在实现将HDFS上的tmp.txt的内容在控制台输出两次,如下:
@Test
public void testSeekReadfile() throws IOException {
// 使用IO流seek定位读取HDFS指定文件,并将内容输出2次
// 1.创建输入流,用于读取HDFS文件
FSDataInputStream inputStream = fileSystem.open(new Path("/tmp.txt"));
// 2.控制台输出,实现流拷贝,输入流 → 控制台输出
// IOUtils.copyBytes(inputStream, System.out, configuration);
IOUtils.copyBytes(inputStream, System.out, 4096, false);
System.out.println("\n---------------------------------------");
// 3.再此读取文件
// 定位为0,即从文件头部再次读取
inputStream.seek(0);
IOUtils.copyBytes(inputStream, System.out, 4096, false);
// 4.关闭流对象
IOUtils.closeStream(inputStream);
}
输出:
hadoop
hdfs
seek
---------------------------------------
hadoop
hdfs
seek
可以看到,读取了两次内容;
其中,IOUtils.copyBytes(inputStream, System.out, 4096, false)表示将HDFS输入流的内容传递到控制台输出中,即打印出来,同时不关闭流对象;
seek定位读取与MapReduce分块读取数据有一定的关联,可以实现逻辑上的块划分。
3.HDFS读写机制解析
以下载文件为例说明HDFS读数据流程,如下:

- 客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址,返回给客户端目标文件的快信息和块所在节点的信息。
数据块较多时,不是一次性返回,而是分批获取并返回。
- 挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
根据网络距离采取就近原则选择数据块副本的DataNode服务器。
-
DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet 为单位来做校验)。
-
客户端以Packet为单位接收,先在本地缓存,然后写入目标文件,最后将所有数据块进行拼接得到完整的数据块。
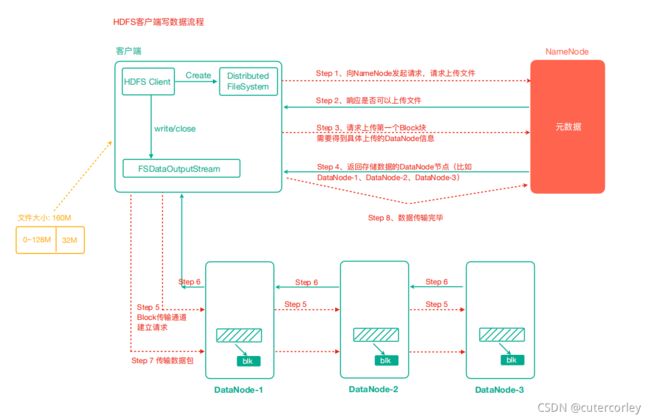
以上传文件说明HDFS写数据流程,如下:
-
客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
-
NameNode返回是否可以上传。
切块在客户端完成,并且是每个文件单独处理并切块,而不是所有文件累加在一起再切块。
-
客户端请求第一个 Block上传到哪几个DataNode服务器上。
-
NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
-
客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
-
dn1、dn2、dn3逐级应答客户端。
-
客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个确认队列等待确认。
-
当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器,重复执行3-7步。
可以看到,在写入数据时,就直接对所有数据块创建副本并分发,而不是在传输数据完成后再生成副本。
现在验证Packet,如下:
@Test
public void testUploadPacket() throws IOException {
// 从本地文件系统上传文件到HDFS
// 1.输入流读取本地文件
FileInputStream inputStream = new FileInputStream("E:/Test/packet.txt");
// 2.输出流写入数据到HDFS
FSDataOutputStream outputStream = fileSystem.create(new Path("/packet.txt"), new Progressable() {
int i = 0;
@Override
public void progress() {
System.out.println("Packet " + i++);
}
});
// 3.拷贝输入流内容到输出流
IOUtils.copyBytes(inputStream, outputStream, configuration);
}
输出:
Packet 0
Packet 1
Packet 2
Packet 3
Packet 4
Packet 5
其中,public FSDataOutputStream create(Path f, Progressable progress)方法的第三个参数Progressable属于接口类型,因此这里通过匿名内部类的方式获取实现类,其中的void progress()方法每传输64KB(1个Packet大小)就会执行一次,所以可以监控每个Packet的传输;
在要传输的文件大小不为0时需要建立传输通道,就会执行一次void progress()方法,同时文件大小为275KB,275/64=4.3共有5个Packet,所以需要传输5次,加建立传输通道1次,共6次。
4.HDFS元数据管理机制
(1)Namenode、Fsimage及Edits编辑日志
NameNode管理和存储元数据分析:
计算机中存储数据有两种方式,即内存或者是磁盘:
如果元数据存储磁盘,存储磁盘无法面对客户端对元数据信息的任意的快速低延迟的响应,但是安全性高;
如果元数据存储内存,元数据存放内存,可以高效的查询以及快速响应客户端的查询请求,数据保存在内存,如果断点,内存中的数据全部丢失。
所以HDFS采取的方式是内存+磁盘 ,即NameNode内存+FsImage的文件(磁盘,类似于虚拟机的快照)。
此时需要考虑磁盘和内存中元数据的划分:
- 内存和磁盘中的数据一模一样
client如果对元数据进行增删改操作,需要保证两个数据的一致性;
并且,FsImage文件操作效率不高。
- 内存和磁盘中的数据合并到一起组成完整的数据
两个合并之后形成完整数据,NameNode引入了一个edits文件。
edits文件是普通的日志文件,同时只能追加写入。
edits文件记录了client的增删改操作,不再让NameNode把数据dump出来形成FsImage文件,因为这种操作比较消耗资源。
HDFS也选择了第二种方式。
元数据管理流程图如下:

第一阶段:NameNode启动
-
第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
-
客户端对元数据进行增删改的请求。
-
NameNode记录操作日志,更新滚动日志。
-
NameNode在内存中对数据进行增删改。
NameNode启动后,edits文件会逐渐积累、越来越大,存在生成快、恢复慢的特点;
fsimage文件从内存中dump到磁盘时,存在生成慢、恢复快的特点。
要想利用好edits和fsimage文件的生成块和恢复快的优点,同时克服缺点,就需要使用Secondary NameNode。
(2)2NN及CheckPoint检查点
第二阶段:Secondary NameNode工作
-
Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否执行检查点操作结果。
-
Secondary NameNode请求执行CheckPoint。
-
NameNode滚动正在写的Edits日志。
-
将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
-
Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
-
生成新的镜像文件fsimage.chkpoint。
-
拷贝fsimage.chkpoint到NameNode。
-
NameNode将fsimage.chkpoint重新命名成fsimage。
(3)Fsimage及Edits文件解析
NameNode在执行格式化之后,会在/data/tmp/dfs/name/current目录下产生FsImage和edits文件,查看虚拟机生成的文件如下:
[root@node01 ~]$ ll /opt/software/hadoop-2.9.2/data/tmp/dfs/name/current/
总用量 3224
-rw-r--r-- 1 root root 1048576 8月 25 11:47 edits_0000000000000000001-0000000000000000001
-rw-r--r-- 1 root root 42 8月 25 20:01 edits_0000000000000000002-0000000000000000003
-rw-r--r-- 1 root root 1048576 8月 25 20:24 edits_0000000000000000004-0000000000000000012
-rw-r--r-- 1 root root 42 8月 25 20:42 edits_0000000000000000013-0000000000000000014
-rw-r--r-- 1 root root 42 8月 25 21:56 edits_0000000000000000015-0000000000000000016
...
-rw-r--r-- 1 root root 42 9月 2 12:41 edits_0000000000000000417-0000000000000000418
-rw-r--r-- 1 root root 1048576 9月 2 12:43 edits_inprogress_0000000000000000419
-rw-r--r-- 1 root root 3253 9月 2 11:41 fsimage_0000000000000000416
-rw-r--r-- 1 root root 62 9月 2 11:41 fsimage_0000000000000000416.md5
-rw-r--r-- 1 root root 3253 9月 2 12:41 fsimage_0000000000000000418
-rw-r--r-- 1 root root 62 9月 2 12:41 fsimage_0000000000000000418.md5
-rw-r--r-- 1 root root 4 9月 2 12:41 seen_txid
-rw-r--r-- 1 root root 219 8月 25 19:59 VERSION
其中,各个文件的含义如下:
- Fsimage文件
是NameNode中关于元数据的镜像,是内存dump出来的数据,一般称为检查点。
包含了HDFS文件系统所有目录以及文件相关信息(Block数量,副本数量,权限等信息)。
但是fsimage文件数据与内存中的数据存在一定的区别。
其中,.md5文件用于Secondary NameNode与NameNode进行文件传输fsimage文件时进行校验。
- Edits文件
存储了客户端对HDFS文件系统所有的更新操作记录 ,Client对HDFS文件系统所有的更新操作(增删改操作,不包括查询操作)都会被记录到Edits文件中。
- seen_txid
该文件保存了一个数字,记录当前NamNode中最后一个Edits文件名的末尾数字,主要是为了NameNode管理edits文件、校验元数据是否丢失。
- VERSION
该文件记录namenode的一些版本号信息,包括ClusterId(集群编号)、namespaceID(命名空间编号)、blockpoolID(块池编号)等。
查看内容如下:
[root@node01 current]$ cat VERSION
#Wed Aug 25 19:59:59 CST 2021
namespaceID=1128684891
clusterID=CID-22adc4b2-cf44-4b8a-abd8-2e48b5bb9a05
cTime=1629862615839
storageType=NAME_NODE
blockpoolID=BP-1336715332-192.168.31.155-1629862615839
layoutVersion=-63
其中,ClusterId是当前集群唯一编号,在格式化后生成,用于区分DataNode属于哪一个集群。
因为Fsimage和Edits文件属于二进制文件,不能直接查看,此时可以借助HDFS提供的命令来查看,可以参考https://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-hdfs/HdfsImageViewer.html。
使用oiv和oev命令来查看文件内容,含义如下:
| 命令 | 完整表达 | 含义 |
|---|---|---|
| oiv | Offline Image Viewer | 使用指定的处理器查看Hadoop fsimage文件,并将结果保存在输出文件中 |
| oev | Offline edits viewer | 解析Hadoopedits日志文件输入文件并将结果保存在输出文件中 |
查看fsimage文件的语法格式为:
hdfs oiv -p 文件类型(xml) -i 镜像文件 -o 转换后文件输出路径
使用如下:
[root@node01 current]$ hdfs oiv -p XML -i fsimage_0000000000000000427 -o /root/img0427.xml
21/09/02 14:11:37 INFO offlineImageViewer.FSImageHandler: Loading 4 strings
执行完抽,将生成的img0427.xml下载到本地,再将文件内容粘贴到在线XML格式化网站中格式化,便于查看,如下:

其中,INodeSection节点保存了主要的文件信息,包括文件(夹)名称、创建时间、权限、文件大小、副本数量等,与HDFS文件系统中保持一致;
同时,信息中包含了块信息,但是没有节点信息,即Fsimage中没有记录块所对应的DataNode。其实,在内存元数据中是有记录块所对应的dn信息,但是fsimage中剔除了这个信息,这是因为:
HDFS集群在启动的时候会加载image以及edits文件,block对应的dn信息都没有记录,集群启动时会以安全模式(safemode)来启动,安全模式就是为了让dn汇报自己当前所持有的block信息给nn来补全元数据,并且后续每隔一段时间dn都要汇报自己持有的block信息。之所以这样设计,是因为有可能在集群停止期间,某些节点出现异常宕机,这样即使这些节点被记录、而再次启动集群时这些节点不能启动、也没有任何意义,反之,选择不记录节点信息,而是让节点主动汇报自己节点的block信息,这样能保证所获取到的节点信息也是最有效的。
查看edits文件的语法格式为:
hdfs oev -p 文件类型 -i edits日志 -o 转换后文件输出路径
使用如下:
[root@node01 current]$ hdfs oev -p XML -i edits_0000000000000000419-0000000000000000427 -o /root/edits0427.xml
使用之前的方式处理生成的文件,如下:
<EDITS>
<EDITS_VERSION>-63EDITS_VERSION>
<RECORD>
<OPCODE>OP_START_LOG_SEGMENTOPCODE>
<DATA>
<TXID>419TXID>
DATA>
RECORD>
<RECORD>
<OPCODE>OP_ADDOPCODE>
<DATA>
<TXID>420TXID>
<LENGTH>0LENGTH>
<INODEID>16478INODEID>
<PATH>/packet.txtPATH>
<REPLICATION>1REPLICATION>
<MTIME>1630557817304MTIME>
<ATIME>1630557817304ATIME>
<BLOCKSIZE>134217728BLOCKSIZE>
<CLIENT_NAME>DFSClient_NONMAPREDUCE_-638007174_1CLIENT_NAME>
<CLIENT_MACHINE>192.168.31.1CLIENT_MACHINE>
<OVERWRITE>trueOVERWRITE>
<PERMISSION_STATUS>
<USERNAME>rootUSERNAME>
<GROUPNAME>supergroupGROUPNAME>
<MODE>420MODE>
PERMISSION_STATUS>
<RPC_CLIENTID>658555cc-4d7d-4920-8ab2-00ff3c26abdeRPC_CLIENTID>
<RPC_CALLID>0RPC_CALLID>
DATA>
RECORD>
<RECORD>
<OPCODE>OP_ALLOCATE_BLOCK_IDOPCODE>
<DATA>
<TXID>421TXID>
<BLOCK_ID>1073741860BLOCK_ID>
DATA>
RECORD>
<RECORD>
<OPCODE>OP_SET_GENSTAMP_V2OPCODE>
<DATA>
<TXID>422TXID>
<GENSTAMPV2>1037GENSTAMPV2>
DATA>
RECORD>
<RECORD>
<OPCODE>OP_ADD_BLOCKOPCODE>
<DATA>
<TXID>423TXID>
<PATH>/packet.txtPATH>
<BLOCK>
<BLOCK_ID>1073741860BLOCK_ID>
<NUM_BYTES>0NUM_BYTES>
<GENSTAMP>1037GENSTAMP>
BLOCK>
<RPC_CLIENTID>RPC_CLIENTID>
<RPC_CALLID>-2RPC_CALLID>
DATA>
RECORD>
<RECORD>
<OPCODE>OP_CLOSEOPCODE>
<DATA>
<TXID>424TXID>
<LENGTH>0LENGTH>
<INODEID>0INODEID>
<PATH>/packet.txtPATH>
<REPLICATION>1REPLICATION>
<MTIME>1630557817462MTIME>
<ATIME>1630557817304ATIME>
<BLOCKSIZE>134217728BLOCKSIZE>
<CLIENT_NAME>CLIENT_NAME>
<CLIENT_MACHINE>CLIENT_MACHINE>
<OVERWRITE>falseOVERWRITE>
<BLOCK>
<BLOCK_ID>1073741860BLOCK_ID>
<NUM_BYTES>281214NUM_BYTES>
<GENSTAMP>1037GENSTAMP>
BLOCK>
<PERMISSION_STATUS>
<USERNAME>rootUSERNAME>
<GROUPNAME>supergroupGROUPNAME>
<MODE>420MODE>
PERMISSION_STATUS>
DATA>
RECORD>
<RECORD>
<OPCODE>OP_DELETEOPCODE>
<DATA>
<TXID>425TXID>
<LENGTH>0LENGTH>
<PATH>/testPATH>
<TIMESTAMP>1630560908262TIMESTAMP>
<RPC_CLIENTID>RPC_CLIENTID>
<RPC_CALLID>-2RPC_CALLID>
DATA>
RECORD>
<RECORD>
<OPCODE>OP_DELETEOPCODE>
<DATA>
<TXID>426TXID>
<LENGTH>0LENGTH>
<PATH>/api_test2PATH>
<TIMESTAMP>1630560908267TIMESTAMP>
<RPC_CLIENTID>RPC_CLIENTID>
<RPC_CALLID>-2RPC_CALLID>
DATA>
RECORD>
<RECORD>
<OPCODE>OP_END_LOG_SEGMENTOPCODE>
<DATA>
<TXID>427TXID>
DATA>
RECORD>
EDITS>
可以看到,文件中记录了ADD、DELETE等操作的信息;
Edits中只记录了更新相关的操作,查询或者下载文件并不会记录在内。
NameNode启动时不会加载所有edits文件,同时Secondary NameNode已经合并了前面的大部分数据,确定需要加载Edits文件的方式如下:
nn启动时需要加载fsimage文件以及那些没有被2nn进行合并的edits文件,nn可以通过fsimage文件自身的编号来确定哪些edits已经被合并。
举例如下:

(4)CheckPoint周期和NameNode故障处理
HDFS有2种默认的处理方式:
-
定时1小时
-
一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次
这是通过hdfs-default.xml文件设置的,如下:
<property>
<name>dfs.namenode.checkpoint.periodname>
<value>3600value>
property>
<property>
<name>dfs.namenode.checkpoint.txnsname>
<value>1000000value>
<description>操作动作次数description>
property>
<property>
<name>dfs.namenode.checkpoint.check.periodname>
<value>60value>
<description>1分钟检查一次操作次数description>
property>
也可以根据自己的需要进行修改。
NameNode故障后,HDFS集群就无法正常工作,因为HDFS文件系统的元数据需要由NameNode来管理维护并与Client交互,如果元数据出现损坏和丢失同样会导致NameNode无法正常工作进而HDFS文件系统无法正常对外提供服务。
如果元数据出现丢失损坏,恢复的方式有2种:
- 将2NN的元数据拷贝到NN的节点下
此种方式会存在元数据的丢失,丢失的数据为上次CheckPoint之后还未合并的edits。
- 搭建HDFS的HA(高可用)集群,解决NN的单点故障问题
借助Zookeeper实现HA(High Availability),包括一个Active的NameNode和一个Standby的NameNode,后者作为备份NameNode,主要负责与Active NameNode的元数据和失败切换。
5.Hadoop限额、归档及集群安全模式
HDFS文件的限额配置允许以文件大小或者文件个数来限制在某个目录下上传的文件数量或者文件内容总量,以便达到类似网盘等应用限制每个用户允许上传的最大的文件的量。
数量限额命令如下:
# 给directory目录设置目录限额
hdfs dfsadmin -setQuota count directory
# 给directory目录取消目录限额
hdfs dfsadmin -clrQuota directory
进行限额需要使用HDFS的dfsadmin命令,如下:
[root@node01 ~]$ hdfs dfsadmin -help
hdfs dfsadmin performs DFS administrative commands.
Note: Administrative commands can only be run with superuser permission.
The full syntax is:
hdfs dfsadmin
[-report [-live] [-dead] [-decommissioning] [-enteringmaintenance] [-inmaintenance]]
[-safemode <enter | leave | get | wait>]
[-saveNamespace]
[-rollEdits]
[-restoreFailedStorage true|false|check]
[-refreshNodes]
[-setQuota <quota> <dirname>...<dirname>]
[-clrQuota <dirname>...<dirname>]
[-setSpaceQuota <quota> [-storageType <storagetype>] <dirname>...<dirname>]
[-clrSpaceQuota [-storageType <storagetype>] <dirname>...<dirname>]
[-finalizeUpgrade]
[-rollingUpgrade [<query|prepare|finalize>]]
[-refreshServiceAcl]
[-refreshUserToGroupsMappings]
[-refreshSuperUserGroupsConfiguration]
[-refreshCallQueue]
[-refresh <host:ipc_port> <key> [arg1..argn]
[-reconfig <namenode|datanode> <host:ipc_port> <start|status|properties>]
[-printTopology]
[-refreshNamenodes datanode_host:ipc_port]
[-getVolumeReport datanode_host:ipc_port]
[-deleteBlockPool datanode_host:ipc_port blockpoolId [force]]
[-setBalancerBandwidth <bandwidth in bytes per second>]
[-getBalancerBandwidth <datanode_host:ipc_port>]
[-fetchImage <local directory>]
[-allowSnapshot <snapshotDir>]
[-disallowSnapshot <snapshotDir>]
[-shutdownDatanode <datanode_host:ipc_port> [upgrade]]
[-evictWriters <datanode_host:ipc_port>]
[-getDatanodeInfo <datanode_host:ipc_port>]
[-metasave filename]
[-triggerBlockReport [-incremental] <datanode_host:ipc_port>]
[-listOpenFiles]
[-help [cmd]]
-report [-live] [-dead] [-decommissioning] [-enteringmaintenance] [-inmaintenance]:
Reports basic filesystem information and statistics.
The dfs usage can be different from "du" usage, because it
measures raw space used by replication, checksums, snapshots
and etc. on all the DNs.
Optional flags may be used to filter the list of displayed DNs.
-safemode <enter|leave|get|wait|forceExit>: Safe mode maintenance command.
Safe mode is a Namenode state in which it
1. does not accept changes to the name space (read-only)
2. does not replicate or delete blocks.
Safe mode is entered automatically at Namenode startup, and
leaves safe mode automatically when the configured minimum
percentage of blocks satisfies the minimum replication
condition. Safe mode can also be entered manually, but then
it can only be turned off manually as well.
-saveNamespace: Save current namespace into storage directories and reset edits log.
Requires safe mode.
-rollEdits: Rolls the edit log.
-restoreFailedStorage: Set/Unset/Check flag to attempt restore of failed storage replicas if they become available.
-refreshNodes: Updates the namenode with the set of datanodes allowed to connect to the namenode.
Namenode re-reads datanode hostnames from the file defined by
dfs.hosts, dfs.hosts.exclude configuration parameters.
Hosts defined in dfs.hosts are the datanodes that are part of
the cluster. If there are entries in dfs.hosts, only the hosts
in it are allowed to register with the namenode.
Entries in dfs.hosts.exclude are datanodes that need to be
decommissioned. Datanodes complete decommissioning when
all the replicas from them are replicated to other datanodes.
Decommissioned nodes are not automatically shutdown and
are not chosen for writing new replicas.
-finalizeUpgrade: Finalize upgrade of HDFS.
Datanodes delete their previous version working directories,
followed by Namenode doing the same.
This completes the upgrade process.
-rollingUpgrade [<query|prepare|finalize>]:
query: query the current rolling upgrade status.
prepare: prepare a new rolling upgrade.
finalize: finalize the current rolling upgrade.
-metasave <filename>: Save Namenode's primary data structures
to in the directory specified by hadoop.log.dir property.
is overwritten if it exists.
will contain one line for each of the following
1. Datanodes heart beating with Namenode
2. Blocks waiting to be replicated
3. Blocks currrently being replicated
4. Blocks waiting to be deleted
-setQuota ...: Set the quota for each directory .
The directory quota is a long integer that puts a hard limit
on the number of names in the directory tree
For each directory, attempt to set the quota. An error will be reported if
1. quota is not a positive integer, or
2. User is not an administrator, or
3. The directory does not exist or is a file.
Note: A quota of 1 would force the directory to remain empty.
-clrQuota ...: Clear the quota for each directory .
For each directory, attempt to clear the quota. An error will be reported if
1. the directory does not exist or is a file, or
2. user is not an administrator.
It does not fault if the directory has no quota.
-setSpaceQuota [-storageType ] ...: Set the space quota for each directory .
The space quota is a long integer that puts a hard limit
on the total size of all the files under the directory tree.
The extra space required for replication is also counted. E.g.
a 1GB file with replication of 3 consumes 3GB of the quota.
Quota can also be specified with a binary prefix for terabytes,
petabytes etc (e.g. 50t is 50TB, 5m is 5MB, 3p is 3PB).
For each directory, attempt to set the quota. An error will be reported if
1. quota is not a positive integer or zero, or
2. user is not an administrator, or
3. the directory does not exist or is a file.
The storage type specific quota is set when -storageType option is specified.
Available storageTypes are
- RAM_DISK
- DISK
- SSD
- ARCHIVE
-clrSpaceQuota [-storageType ] ...: Clear the space quota for each directory .
For each directory, attempt to clear the quota. An error will be reported if
1. the directory does not exist or is a file, or
2. user is not an administrator.
It does not fault if the directory has no quota.
The storage type specific quota is cleared when -storageType option is specified.
Available storageTypes are
- RAM_DISK
- DISK
- SSD
- ARCHIVE
-refreshServiceAcl: Reload the service-level authorization policy file
Namenode will reload the authorization policy file.
-refreshUserToGroupsMappings: Refresh user-to-groups mappings
-refreshSuperUserGroupsConfiguration: Refresh superuser proxy groups mappings
-refreshCallQueue: Reload the call queue from config
-refresh: Arguments are [arg1..argn]
Triggers a runtime-refresh of the resource specified by on .
All other args after are sent to the host.
The ipc_port is determined by ' dfs.datanode.ipc.address',default is DFS_DATANODE_IPC_DEFAULT_PORT.
-reconfig :
Starts or gets the status of a reconfiguration operation,
or gets a list of reconfigurable properties.
The second parameter specifies the node type
-printTopology: Print a tree of the racks and their
nodes as reported by the Namenode
-refreshNamenodes: Takes a datanodehost:ipc_port as argument,For the given datanode
reloads the configuration files,stops serving the removed
block-pools and starts serving new block-pools.
The ipc_port is determined by ' dfs.datanode.ipc.address',default is DFS_DATANODE_IPC_DEFAULT_PORT.
-deleteBlockPool: Arguments are datanodehost:ipc_port, blockpool id and an optional argument
"force". If force is passed,block pool directory for
the given blockpool id on the given datanode is deleted
along with its contents,otherwise the directory is deleted
only if it is empty.The command will fail if datanode is
still serving the block pool.Refer to refreshNamenodes to
shutdown a block pool service on a datanode.
The ipc_port is determined by 'dfs.datanode.ipc.address',default is DFS_DATANODE_IPC_DEFAULT_PORT.
-setBalancerBandwidth :
Changes the network bandwidth used by each datanode during
HDFS block balancing.
is the maximum number of bytes per second
that will be used by each datanode. This value overrides
the dfs.balance.bandwidthPerSec parameter.
--- NOTE: The new value is not persistent on the DataNode.---
-getBalancerBandwidth :
Get the network bandwidth for the given datanode.
This is the maximum network bandwidth used by the datanode
during HDFS block balancing.
--- NOTE: This value is not persistent on the DataNode.---
-fetchImage :
Downloads the most recent fsimage from the Name Node and saves it in the specified local directory.
-allowSnapshot :
Allow snapshots to be taken on a directory.
-disallowSnapshot :
Do not allow snapshots to be taken on a directory any more.
-shutdownDatanode [upgrade]
Submit a shutdown request for the given datanode. If an optional
"upgrade" argument is specified, clients accessing the datanode
will be advised to wait for it to restart and the fast start-up
mode will be enabled. When the restart does not happen in time,
clients will timeout and ignore the datanode. In such case, the
fast start-up mode will also be disabled.
-evictWriters
Make the datanode evict all clients that are writing a block.
This is useful if decommissioning is hung due to slow writers.
-getDatanodeInfo
Get the information about the given datanode. This command can
be used for checking if a datanode is alive.
-triggerBlockReport [-incremental]
Trigger a block report for the datanode.
If ' incremental' is specified, it will be an incremental
block report; otherwise, it will be a full block report.
-listOpenFiles
List all open files currently managed by the NameNode along
with client name and client machine accessing them.
-help [cmd]: Displays help for the given command or all commands if none
is specified.
Generic options supported are:
-conf specify an application configuration file
-D define a value for a given property
-fs specify default filesystem URL to use, overrides ' fs.defaultFS' property from configurations.
-jt <local|resourcemanager:port> specify a ResourceManager
-files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster
-libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath
-archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines
The general command line syntax is:
command [genericOptions] [commandOptions]
包含了完整的管理命令。
使用如下:
# 创建HDFS文件夹
[root@node01 ~]$ hdfs dfs -mkdir /test
# 给该文件夹下面设置最多上传两个文件
[root@node01 ~]$ hdfs dfsadmin -setQuota 2 /test
[root@node01 ~]$ hdfs dfs -put test.txt /test
# 上传文件,只能上传一个文件
[root@node01 ~]$ hdfs dfs -put test.txt /test/test-2.txt
put: The NameSpace quota (directories and files) of directory /test is exceeded: quota=2 file count=3
# 清除文件数量限制
[root@node01 ~]$ hdfs dfsadmin -clrQuota /test
[root@node01 ~]$ hdfs dfs -put test.txt /test/test-2.txt
可以看到,设置了数量限额为2,所以最多能上传1个文件,清除数量限制后,可以上传多个文件。
设置空间大小限额的命令如下:
# 给目录directory设置空间限额大小为size
hdfs dfsadmin -setSpaceQuota size directory
# 清除空间限额
hdfs dfsadmin -clrSpaceQuota directory
# 查看文件限额数量
hdfs dfs -count -q -h directory
使用如下:
# 限制空间大小为30KB
[root@node01 ~]$ hdfs dfsadmin -setSpaceQuota 30k /test
# 上传超过30KB大小的文件会提示文件超过限额
[root@node01 ~]$ hdfs dfs -put img0427.xml /test
put: The DiskSpace quota of /test is exceeded: quota = 30720 B = 30 KB but diskspace consumed = 402653256 B = 384.00 MB
# 查看hdfs文件限额数量
[root@node01 ~]$ hdfs dfs -count -q -h /test
none inf 30 K 29.9 K 1 2 24 /test
# 清除空间限额
[root@node01 ~]$ hdfs dfsadmin -clrSpaceQuota /test
[root@node01 ~]$ hdfs dfs -put test.txt /test/test-3.txt
[root@node01 ~]$ hdfs dfs -ls /
Found 9 items
drwxrwxrwx - root supergroup 0 2021-09-01 17:59 /api_test
drwxrwxrwx - root supergroup 0 2021-08-26 19:22 /cl
-rw-r--r-- 1 root supergroup 281214 2021-09-02 12:43 /packet.txt
drwxr-xr-x - root supergroup 0 2021-09-02 17:34 /test
drwxrwxrwx - root supergroup 0 2021-08-26 00:36 /tmp
-rw-r--r-- 1 root supergroup 18 2021-09-02 11:12 /tmp.txt
drwxrwxrwx - root supergroup 0 2021-08-26 20:19 /user
drwxrwxrwx - root supergroup 0 2021-08-25 22:33 /wcinput
drwxrwxrwx - root supergroup 0 2021-08-26 00:37 /wcoutput
[root@node01 ~]$ hdfs dfs -ls /test
Found 3 items
-rw-r--r-- 3 root supergroup 12 2021-09-02 17:15 /test/test-2.txt
-rw-r--r-- 3 root supergroup 12 2021-09-02 17:34 /test/test-3.txt
-rw-r--r-- 3 root supergroup 12 2021-09-02 17:13 /test/test.txt
[root@node01 ~]$
可以看到,在设置空间限额后,不能成功上传文件,取消空间限额之后,就能上传文件。
HDFS集群启动时需要加载Fsimage以及edits文件,而这两个文件都没有记录block对应的datanode节点信息,所以如果此时Client请求上传文件,集群是不能工作的。这时候就需要用到安全模式。
安全模式是HDFS所处的一种特殊状态,属于HDFS自我保护的模式,在这种状态下,文件系统只接受读数据请求,而不接受删除、修改等变更请求。在NameNode主节点启动时,HDFS首先进入安全模式,DataNode在启动的时候会向NameNode汇报可用的block等状态,当整个系统达到安全标准时,HDFS自动离开安全模式。如果HDFS处于安全模式下,则文件block不能进行任何的副本复制操作,因此达到最小的副本数量要求是基于DataNode启动时的状态来判定的,启动时不会再做任何复制(从而达到最小副本数量要求),HDFS集群刚启动的时候,默认30S钟的时间是出于安全期的,只有过了30S之后,集群脱离了安全期,然后才可以对集群进行操作。
与安全模式相关的命令如下:
hdfs dfs -safemode <enter|leave|get|wait|forceExit>
使用如下:
[root@node01 ~]$ hdfs dfsadmin -safemode enter
Safe mode is ON
[root@node01 ~]$ hdfs dfs -get /tmp.txt
[root@node01 ~]$ hdfs dfs -put hadoop.txt /test
put: Cannot create file/test/hadoop.txt._COPYING_. Name node is in safe mode.
[root@node01 ~]$ hdfs dfsadmin -safemode leave
Safe mode is OFF
[root@node01 ~]$ hdfs dfs -put hadoop.txt /test
[root@node01 ~]$ hdfs dfs -ls /test
Found 4 items
-rw-r--r-- 3 root supergroup 52 2021-09-02 18:14 /test/hadoop.txt
-rw-r--r-- 3 root supergroup 12 2021-09-02 17:15 /test/test-2.txt
-rw-r--r-- 3 root supergroup 12 2021-09-02 17:34 /test/test-3.txt
-rw-r--r-- 3 root supergroup 12 2021-09-02 17:13 /test/test.txt
可以看到,在进入安全模式后,只允许读文件、不允许写文件,在关闭安全模式后才能写文件。
Hadoop归档技术主要是为了解决HDFS集群存在大量小文件的问题。
由于大量小文件会占用NameNode的内存,因此对于HDFS来说存储大量小文件造成NameNode内存资源的浪费。
Hadoop存档文件HAR文件,是一个更高效的文件存档工具,HAR文件是由一组文件通过archive工具创建而来,多个文件只需要1条元数据来存储,在减少了NameNode的内存使用的同时,可以对文件进行透明的访问,通俗来说,就是HAR文件对NameNode来说是一个文件减少了内存的浪费,对于实际操作处理文件依然是多个独立的文件。如下图:

现在测试归档:
(1)启动Yarn集群
因为归档需要用到计算任务,所以需要启动Yarn集群,如果Yarn集群未启动,需要先启动Yarn,执行start-yarn.sh命令即可。
(2)归档文件
把/test目录里面的所有文件归档成一个叫test.har的归档文件,并把归档后文件存储到/test路径下,如下:
[root@node01 ~]$ hadoop archive -help
usage: archive <-archiveName <NAME>.har> <-p <parent path>> [-r <replication factor>] <src>* <dest>
-archiveName <arg> Name of the Archive. This is mandatory option
-help Show the usage
-p <arg> Parent path of sources. This is mandatory option
-r <arg> Replication factor archive files
[root@node01 ~]$ hadoop archive -archiveName test.har -p /test /output
21/09/02 18:29:13 INFO client.RMProxy: Connecting to ResourceManager at node03/192.168.31.157:8032
21/09/02 18:29:14 INFO mapreduce.JobSubmissionFiles: Permissions on staging directory /tmp/hadoop-yarn/staging/root/.staging are incorrect: rwxrwxrwx. Fixing permissions to correct value rwx------
21/09/02 18:29:14 INFO client.RMProxy: Connecting to ResourceManager at node03/192.168.31.157:8032
21/09/02 18:29:14 INFO client.RMProxy: Connecting to ResourceManager at node03/192.168.31.157:8032
21/09/02 18:29:15 INFO mapreduce.JobSubmitter: number of splits:1
21/09/02 18:29:15 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
21/09/02 18:29:16 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1629908848730_0002
21/09/02 18:29:16 INFO impl.YarnClientImpl: Submitted application application_1629908848730_0002
21/09/02 18:29:16 INFO mapreduce.Job: The url to track the job: http://node03:8088/proxy/application_1629908848730_0002/
21/09/02 18:29:16 INFO mapreduce.Job: Running job: job_1629908848730_0002
21/09/02 18:29:27 INFO mapreduce.Job: Job job_1629908848730_0002 running in uber mode : false
21/09/02 18:29:27 INFO mapreduce.Job: map 0% reduce 0%
21/09/02 18:29:40 INFO mapreduce.Job: map 100% reduce 0%
21/09/02 18:29:54 INFO mapreduce.Job: map 100% reduce 100%
21/09/02 18:29:54 INFO mapreduce.Job: Job job_1629908848730_0002 completed successfully
21/09/02 18:29:54 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=390
FILE: Number of bytes written=401295
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=611
HDFS: Number of bytes written=465
HDFS: Number of read operations=18
HDFS: Number of large read operations=0
HDFS: Number of write operations=11
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=9066
Total time spent by all reduces in occupied slots (ms)=10903
Total time spent by all map tasks (ms)=9066
Total time spent by all reduce tasks (ms)=10903
Total vcore-milliseconds taken by all map tasks=9066
Total vcore-milliseconds taken by all reduce tasks=10903
Total megabyte-milliseconds taken by all map tasks=9283584
Total megabyte-milliseconds taken by all reduce tasks=11164672
Map-Reduce Framework
Map input records=5
Map output records=5
Map output bytes=374
Map output materialized bytes=390
Input split bytes=116
Combine input records=0
Combine output records=0
Reduce input groups=5
Reduce shuffle bytes=390
Reduce input records=5
Reduce output records=0
Spilled Records=10
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=269
CPU time spent (ms)=2460
Physical memory (bytes) snapshot=340410368
Virtual memory (bytes) snapshot=4169043968
Total committed heap usage (bytes)=140947456
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=407
File Output Format Counters
Bytes Written=0
[root@node01 ~]$ hdfs dfs -ls /output
Found 1 items
drwxr-xr-x - root supergroup 0 2021-09-02 18:29 /output/test.har
[root@node01 ~]$ hdfs dfs -ls /output/test.har
Found 4 items
-rw-r--r-- 3 root supergroup 0 2021-09-02 18:29 /output/test.har/_SUCCESS
-rw-r--r-- 3 root supergroup 354 2021-09-02 18:29 /output/test.har/_index
-rw-r--r-- 3 root supergroup 23 2021-09-02 18:29 /output/test.har/_masterindex
-rw-r--r-- 3 root supergroup 88 2021-09-02 18:29 /output/test.har/part-0
可以看到,生成了归档文件test.har目录,下包含4个文件:
_SUCCESS表示状态成功;
part-0保存了合并后的文件;
_index和_masterindex分别表示开始和结束的索引文件,记录了part-0文件中原文件的分布。
(3)查看归档文件
如下:
[root@node01 ~]$ hdfs dfs -ls -R /output/test.har
-rw-r--r-- 3 root supergroup 0 2021-09-02 18:29 /output/test.har/_SUCCESS
-rw-r--r-- 3 root supergroup 354 2021-09-02 18:29 /output/test.har/_index
-rw-r--r-- 3 root supergroup 23 2021-09-02 18:29 /output/test.har/_masterindex
-rw-r--r-- 3 root supergroup 88 2021-09-02 18:29 /output/test.har/part-0
[root@node01 ~]$ hdfs dfs -ls -R har:///output/test.har
-rw-r--r-- 3 root supergroup 52 2021-09-02 18:14 har:///output/test.har/hadoop.txt
-rw-r--r-- 3 root supergroup 12 2021-09-02 17:15 har:///output/test.har/test-2.txt
-rw-r--r-- 3 root supergroup 12 2021-09-02 17:34 har:///output/test.har/test-3.txt
-rw-r--r-- 3 root supergroup 12 2021-09-02 17:13 har:///output/test.har/test.txt
可以看到,要查看归档文件对应的源文件,需要用到HAR协议。
(4)解归档文件
解归档文件相当于将HAR文件拷贝出来。如下:
[root@node01 ~]$ hdfs dfs -cp har:///output/test.har/* /demo
[root@node01 ~]$ hdfs dfs -ls /demo
Found 4 items
-rw-r--r-- 3 root supergroup 52 2021-09-02 18:37 /demo/hadoop.txt
-rw-r--r-- 3 root supergroup 12 2021-09-02 18:37 /demo/test-2.txt
-rw-r--r-- 3 root supergroup 12 2021-09-02 18:37 /demo/test-3.txt
-rw-r--r-- 3 root supergroup 12 2021-09-02 18:37 /demo/test.txt
6.日志采集案例
(1)需求分析
公司的业务架构如下:
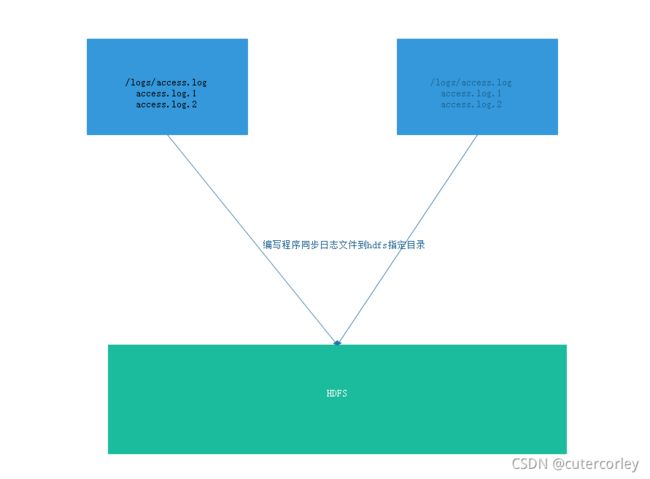
业务系统由多台服务器组成,每台服务器都有日志,随着时间的延长,日志会逐渐增加,此时需要滚动日志。每个服务器的日志都会滚动生成大量日志,存在少量的价值,但是又会占用大量磁盘空间,此时就可以使用HDFS来进行处理:
将已经滚动完成的日志写入HDFS文件系统中,同时为了区分已上传的日志和未上传的日志、避免影响业务系统,需要创建临时目录,并且创建backup目录用于保存最近一段时间内的日志,便于服务器查看最近的日志文件,而不需要从HDFS中读取。
所以需要实现的功能如下:
-
定时采集已滚动完毕日志文件
-
将待采集文件上传到临时目录
-
备份日志文件
(2)调度功能实现
新建一个项目LogCollector,pom.xml如下:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.bigdata.collectloggroupId>
<artifactId>collect_logartifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<maven.compiler.source>8maven.compiler.source>
<maven.compiler.target>8maven.compiler.target>
properties>
<dependencies>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.13.2version>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-coreartifactId>
<version>2.8.2version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>2.9.2version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.9.2version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>2.9.2version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.13.1version>
<scope>compilescope>
dependency>
dependencies>
project>
新建包com.bigdata.collectlog,collectlog下新建类如下:
package com.bigdata.collectlog;
import java.util.Timer;
/**
* @author Corley
* @date 2021/9/2 19:01
* @description LogCollector-com.bigdata.collectlog
* 定时采集已滚动完毕日志文件
* 将待采集文件上传到临时目录
* 备份日志文件
*/
public class LogCollector {
public static void main(String[] args) {
// 后台守护线程
Timer timer = new Timer();
// 定时采集任务调度
timer.schedule(new LogCollectorTask(), 0, 3600*1000);
}
}
其中,Timer类的public void schedule(TimerTask task, long delay, long period)方法用于实现定时采集任务的调度,3个参数分别表示采集的任务逻辑、延迟时间和周期时间,TimerTask类是抽象类、实现了Runnable接口,需要继承自TimerTask类、并将定时的业务逻辑在void run()方法中实现。
自定义的LogCollectorTask类框架如下:
package com.bigdata.collectlog;
import java.util.TimerTask;
/**
* @author Corley
* @date 2021/9/2 19:07
* @description LogCollector-com.bigdata.collectlog
*/
public class LogCollectorTask extends TimerTask {
@Override
public void run() {
// 采集的任务逻辑
// 1.扫描指定目录,找到待上传文件
// 2.将待上传文件转移到临时目录
// 3.使用HDFS API上传文件到指定目录
// 4.上传后的文件备份目录
}
}
(3)采集上传功能实现
LogCollectorTask类中完善方法如下:
package com.bigdata.collectlog;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.File;
import java.io.FilenameFilter;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.TimerTask;
/**
* @author Corley
* @date 2021/9/2 19:07
* @description LogCollector-com.bigdata.collectlog
*/
public class LogCollectorTask extends TimerTask {
@Override
public void run() {
// 采集的任务逻辑
// 1.扫描指定目录,找到待上传文件
File logDir = new File("E:/Test/logs");
File[] uploadFiles = logDir.listFiles(new FilenameFilter() {
@Override
public boolean accept(File dir, String name) {
return name.startsWith("access.log.");
}
});
// 2.将待上传文件转移到临时目录
// 判断并创建临时目录
File tmpFile = new File("E:/Test/tmp");
if (!tmpFile.exists()) {
tmpFile.mkdirs();
}
assert uploadFiles != null;
for (File file : uploadFiles) {
file.renameTo(new File(tmpFile.getPath() + "/" + file.getName()));
}
// 3.使用HDFS API上传文件到指定目录
Configuration configuration = new Configuration();
FileSystem fileSystem = null;
// 格式化日期
DateTimeFormatter timeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd");
LocalDateTime dateTime = LocalDateTime.now();
String timeString = dateTime.format(timeFormatter);
// 判断备份目录是否存在并创建
File logBakDir = new File("E:/Test/log_bak/" + timeString);
if (!logBakDir.exists()) {
logBakDir.mkdirs();
}
// 判断HDFS路径是否存在并创建
Path logPath = new Path("/collect_log/" + timeString);
try {
fileSystem = FileSystem.get(new URI("hdfs://node01:9000"), configuration, "root");
if (!fileSystem.exists(logPath)) {
fileSystem.mkdirs(logPath);
}
File[] files = tmpFile.listFiles();
for (File file : files) {
// 按照日期分类存放
fileSystem.copyFromLocalFile(new Path(file.getPath()),
new Path(logPath.getParent() + "/" + logPath.getName() + "/" + file.getName()));
// 4.上传后的文件备份目录
file.renameTo(new File(logBakDir.getPath() + "/" + file.getName()));
}
} catch (IOException | URISyntaxException | InterruptedException e) {
try {
if (null != fileSystem) {
fileSystem.close();
}
} catch (IOException ioException) {
ioException.printStackTrace();
}
e.printStackTrace();
}
}
}
为了测试,准备日志文件,如下:
λ ls logs\
access.log access.log.1 access.log.2 access.log.3 access.log.4 access.log.5 access.log.6
如有需要,可点击下方下载:
logs.zip
现在进行测试,执行LogCollector类中的main方法,如下:
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
因为程序是定时任务,所以会处于阻塞状态;
先查看logs目录:
λ ls logs\
access.log
可以看到,只剩下access.log;
查看tmp目录:
λ ls tmp/
tmp目录为空;
再查看log_bak目录,如下:
λ tree /f log_bak\
Folder PATH listing for volume 文档
Volume serial number is C0000100 10EF:7240
E:\TEST\LOG_BAK
└───2021-09-02
access.log.1
access.log.2
access.log.3
access.log.4
access.log.5
access.log.6
可以看到,已经滚动的日志保存到了log-bak目录下。
最后查看HDFS文件系统,如下:
[root@node01 ~]$ hdfs dfs -ls /
Found 12 items
drwxrwxrwx - root supergroup 0 2021-09-01 17:59 /api_test
drwxrwxrwx - root supergroup 0 2021-08-26 19:22 /cl
drwxr-xr-x - root supergroup 0 2021-09-02 22:01 /collect_log
drwxr-xr-x - root supergroup 0 2021-09-02 18:37 /demo
drwxr-xr-x - root supergroup 0 2021-09-02 18:29 /output
-rw-r--r-- 1 root supergroup 281214 2021-09-02 12:43 /packet.txt
drwxr-xr-x - root supergroup 0 2021-09-02 18:14 /test
drwxrwxrwx - root supergroup 0 2021-08-26 00:36 /tmp
-rw-r--r-- 1 root supergroup 18 2021-09-02 11:12 /tmp.txt
drwxrwxrwx - root supergroup 0 2021-09-02 21:06 /user
drwxrwxrwx - root supergroup 0 2021-08-25 22:33 /wcinput
drwxrwxrwx - root supergroup 0 2021-08-26 00:37 /wcoutput
[root@node01 ~]$ hdfs dfs -ls /collect_log
Found 1 items
drwxr-xr-x - root supergroup 0 2021-09-02 22:03 /collect_log/2021-09-02
[root@node01 ~]$ hdfs dfs -ls /collect_log/2021-09-02
Found 6 items
-rw-r--r-- 3 root supergroup 179822 2021-09-02 22:03 /collect_log/2021-09-02/access.log.1
-rw-r--r-- 3 root supergroup 251115 2021-09-02 22:03 /collect_log/2021-09-02/access.log.2
-rw-r--r-- 3 root supergroup 6037 2021-09-02 22:03 /collect_log/2021-09-02/access.log.3
-rw-r--r-- 3 root supergroup 149080 2021-09-02 22:03 /collect_log/2021-09-02/access.log.4
-rw-r--r-- 3 root supergroup 314855 2021-09-02 22:03 /collect_log/2021-09-02/access.log.5
-rw-r--r-- 3 root supergroup 1571 2021-09-02 22:03 /collect_log/2021-09-02/access.log.6
可以看到,日志文件上传到了HDFS中。
(4)程序调优
程序有很多可以优化的地方:
(1)LogCollectorTask类中有很多参数,例如各个路径,都是直接写在代码中的,显然,可扩展性不强,可以将其抽取到配置文件中;
(2)任务启动后,每次执行多线程,但是配置文件只需要加载一次,所以可以使用单例设计模式,来获取Properties对象
src/main/resources下新建配置文件collector.properties如下:
LOG.DIR=E:/Test/logs
LOG.PREFIX=access.log.
LOG.TMP.FILE=E:/Test/tmp
HDFS.TARGET.DIR=/collect_log/
LOG.BAK.DIR=E:/Test/log_bak/
新建包com.bigdata.common,common包下新建常量类Constant类如下:
package com.bigdata.common;
/**
* @author Corley
* @date 2021/9/2 22:16
* @description LogCollector-com.bigdata.common
*/
public class Constant {
public static final String LOG_DIR = "LOG.DIR";
public static final String LOG_PREFIX = "LOG.PREFIX";
public static final String LOG_TMP_FILE = "LOG.TMP.FILE";
public static final String LOG_TARGET_DIR = "HDFS.TARGET.DIR";
public static final String LOG_BAK_DIR = "LOG.BAK.DIR";
}
新建包com.bigdata.singleton,singleton包下创建单例类,单例模式有饿汉式和懒汉式。
饿汉式如下:
package com.bigdata.singleton;
import com.bigdata.collectlog.LogCollectorTask;
import java.io.IOException;
import java.util.Properties;
/**
* @author Corley
* @date 2021/9/3 10:34
* @description LogCollector-com.bigdata.singleton
* 饿汉式单例模式
*/
public class HungryPropertiesTool {
private static Properties properties = null;
// 类加载时初始化执行一次即可
static {
properties = new Properties();
try {
properties.load(LogCollectorTask.class.getClassLoader().getResourceAsStream("collector.properties"));
} catch (IOException e) {
e.printStackTrace();
}
}
private static Properties getProperties() {
return properties;
}
}
懒汉式如下:
package com.bigdata.singleton;
import com.bigdata.collectlog.LogCollectorTask;
import java.io.IOException;
import java.util.Properties;
/**
* @author Corley
* @date 2021/9/3 10:46
* @description LogCollector-com.bigdata.singleton
* 懒汉式单例模式
*/
public class LazyPropertiesTool {
private static volatile Properties properties = null;
public static Properties getProperties() throws IOException {
if (null == properties) {
synchronized ("Lock") {
if (null == properties) {
properties = new Properties();
properties.load(LogCollectorTask.class.getClassLoader().getResourceAsStream("collector.properties"));
}
}
}
return properties;
}
}
其中,volatile关键字是Java中禁止指令重排序的关键字,多线程中会出现指令重排序,volatile关键字可以保证有序性和可见性。
日志收集任务类如下:
package com.bigdata.collectlog;
import com.bigdata.common.Constant;
import com.bigdata.singleton.LazyPropertiesTool;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.File;
import java.io.FilenameFilter;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.Properties;
import java.util.TimerTask;
/**
* @author Corley
* @date 2021/9/2 19:07
* @description LogCollector-com.bigdata.collectlog
*/
public class LogCollectorTask extends TimerTask {
@Override
public void run() {
// Properties properties = new Properties();
// try {
// properties.load(LogCollectorTask.class.getClassLoader().getResourceAsStream("collector.properties"));
// } catch (IOException e) {
// e.printStackTrace();
// }
Properties properties = null;
try {
properties = LazyPropertiesTool.getProperties();
} catch (IOException e) {
e.printStackTrace();
}
// 采集的任务逻辑
// 1.扫描指定目录,找到待上传文件
File logDir = new File(properties.getProperty(Constant.LOG_DIR));
Properties finalProperties = properties;
File[] uploadFiles = logDir.listFiles(new FilenameFilter() {
@Override
public boolean accept(File dir, String name) {
return name.startsWith(finalProperties.getProperty(Constant.LOG_PREFIX));
}
});
// 2.将待上传文件转移到临时目录
// 判断并创建临时目录
File tmpFile = new File(properties.getProperty(Constant.LOG_TMP_FILE));
if (!tmpFile.exists()) {
tmpFile.mkdirs();
}
assert uploadFiles != null;
for (File file : uploadFiles) {
file.renameTo(new File(tmpFile.getPath() + "/" + file.getName()));
}
// 3.使用HDFS API上传文件到指定目录
Configuration configuration = new Configuration();
FileSystem fileSystem = null;
// 格式化日期
DateTimeFormatter timeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd");
LocalDateTime dateTime = LocalDateTime.now();
String timeString = dateTime.format(timeFormatter);
// 判断备份目录是否存在并创建
File logBakDir = new File(properties.getProperty(Constant.LOG_BAK_DIR) + timeString);
if (!logBakDir.exists()) {
logBakDir.mkdirs();
}
// 判断HDFS路径是否存在并创建
Path logPath = new Path(properties.getProperty(Constant.LOG_TARGET_DIR) + timeString);
try {
fileSystem = FileSystem.get(new URI("hdfs://node01:9000"), configuration, "root");
if (!fileSystem.exists(logPath)) {
fileSystem.mkdirs(logPath);
}
File[] files = tmpFile.listFiles();
for (File file : files) {
// 按照日期分类存放
fileSystem.copyFromLocalFile(new Path(file.getPath()),
new Path(logPath.getParent() + "/" + logPath.getName() + "/" + file.getName()));
// 4.上传后的文件备份目录
file.renameTo(new File(logBakDir.getPath() + "/" + file.getName()));
}
} catch (IOException | URISyntaxException | InterruptedException e) {
try {
if (null != fileSystem) {
fileSystem.close();
}
} catch (IOException ioException) {
ioException.printStackTrace();
}
e.printStackTrace();
}
}
}
运行后,可以达到与之前相同的效果,但是性能上进行了优化。