Centos7 最小系统安装hadoop——大数据实验
文章目录
-
- 1. 安装JDK
-
- 1.1 下载 JDK1.8
- 1.2 安装 JDK1.8
- 2. 安装hadoop
-
- 2.1 新建用户并进行相关配置
- 2.2 正式安装
- 2.3 Hadoop单机配置(非分布式)
- 2.4 Hadoop分布式配置
- 参考文章
特别注意:这里使用的操作系统是最小化安装的Centos7操作系统,具体的系统安装请参照这里
1. 安装JDK
1.1 下载 JDK1.8
到官网去下载即可,可以下载跟我一样的jdk版本,到这里往下找找,就能找到下图的下载链接了。
一般来说,下载的时候会提醒你登录,登录一下就行,没有账号的就注册一下,免费的。
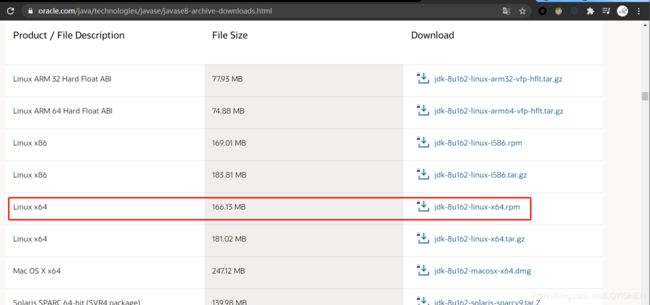
下载下来之后上传到虚拟机即可。
1.2 安装 JDK1.8
把下载的JDK解压出来就可以了:
mkdir /usr/lib/jvm # 新建一个文件夹用来存储JDK
tar -zxf jdk-8u*.tar.gz -C /usr/lib/jvm # 把压缩包解压出来,压缩包名字应该要对应到你的压缩包名字,这里我使用了 * 以免你只知道复制粘贴而导致无法执行
cd /usr/lib/jvm
mv * jdk1.8 # 改一下文件夹的名字,这里的 * 与上面的相同
接下来,需要配置JDK的环境,所以需要写入到终端的配置文件。你可以只写入到具体用户的用户目录下的.bashrc文件最后。当然,为了以后我每个用户都可以使用JDK,这里我写到全局的终端配置文件/etc/bashrc里:
vim /etc/bashrc
然后在最后加入以下几行:
export JAVA_HOME=/usr/lib/jvm/jdk1.8
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
写入后,可以重新开终端,也可以在本终端使用:
source /etc/bashrc
刷新终端的执行环境。
可以执行以下命令看下能不能正常使用java:
java -version
假如输出是类似这样的:

那就证明没什么问题了。
2. 安装hadoop
2.1 新建用户并进行相关配置
注:以下操作请在root权限下进行
- 新建一个用户
hadoop:
adduser -m hadoop -s /bin/bash # 新建用户
echo 123456 | passwd --stdin hadoop # 设置hadoop密码为123456
- 添加
hadoop用户到 sudoers 列表内
cd /etc
chmod u+w sudoers # 添加写权限
然后使用文本编辑软件编辑该文本,这里我使用的是vim
vim sudoers
我这里是在第100行找到的 root 用户的设置,在下面添加一行,用户名写成 hadoop ,其它的跟 root 用户的相同即可,如下图:
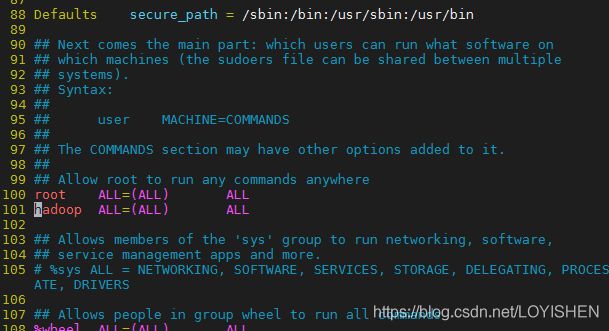
修改完请保存(要是不能保存,那说明你没有执行上面的 chmod 命令)。
保存后要重新设置 sudoers 文件为只读状态:
chmod u-w sudoers
- 配置 ssh 无密码登录
su - hadoop # 登录到 hadoop 用户
ssh-keygen -t rsa # 生成秘钥
cd ~/.ssh/ # 进入 hadoop 用户的 ssh 配置目录
cat id_rsa.pub >> authorized_keys # 添加自己到自己的免登录列表
chmod 600 authorized_keys # 修改权限,这一步必须的,要不然不能免登录到自己
然后可以在hadoop用户下使用 ssh 连接一下自己,看能不能免登录(第一次连接可能有是否需要保存秘钥的选项,选择yes即可),如下:
ssh localhost # 或者 ssh hadoop@localhost
能够在hadoop用户下免密码登录到hadoop用户即可。
2.2 正式安装
- 下载hadoop安装文件,可以到官网这里下载。
- 解压hadoop安装文件到目标文件夹:
tar -zxf hadoop*.tar.gz -C /usr/local # 解压文件到目标文件夹
cd /usr/local
mv hadoop* hadoop # 更改文件夹的名字
chown -R hadoop:hadoop hadoop # 修改 hadoop 文件夹的所属用户和所属组
- 查看 hadoop 是否可用:
cd hadoop/
bin/hadoop version
假如能看到类似下面的输出,那就证明没什么问题了:

2.3 Hadoop单机配置(非分布式)
hadoop默认是本地模式运行的,运行即可。
su - hadoop # 切换到 hadoop 用户
cd /usr/local/hadoop
mkdir input
cp etc/hadoop/*.xml input # 添加一些测试文件
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep input output 'dfs[a-z.]+'
cat ./output/* # 查看结果
运行hadoop那一条命令的时候,会需要比较长的时间,且会输出比较多的调试信息,都不用管。
执行最后一条命令后,假如能看到类似下面的内容,证明没什么问题了:
![]()
要注意的是,hadoop默认不能覆盖文件,所以要重复执行的时候,删掉output目录之后再执行。
2.4 Hadoop分布式配置
Hadoop可并不是用来本地运行的,它就是为了分布式运行而生的。
这里配置一下就可以使用分布式配置了。先到目录:
cd /usr/local/hadoop/etc/hadoop/
中,接下来需要编辑core-site.xml和hdfs-site.xml文件。
修改core-site.xml文件的configuration的配置为:
<configuration>
<property>
<name>hadoop.tmp.dirname>
<value>file:/usr/local/hadoop/tmpvalue>
<description>Abase for other temporary directories.description>
property>
<property>
<name>fs.defaultFSname>
<value>hdfs://localhost:9000value>
property>
configuration>
修改hdfs-site.xml文件的configuration的配置为:
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/usr/local/hadoop/tmp/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/usr/local/hadoop/tmp/dfs/datavalue>
property>
configuration>
第一次配置完成时,需要执行NameNode的格式化:
cd /usr/local/hadoop
bin/hdfs namenode -format
运行时间会比较长。
最后假如能够看到类似下图的结果,则格式化完成:
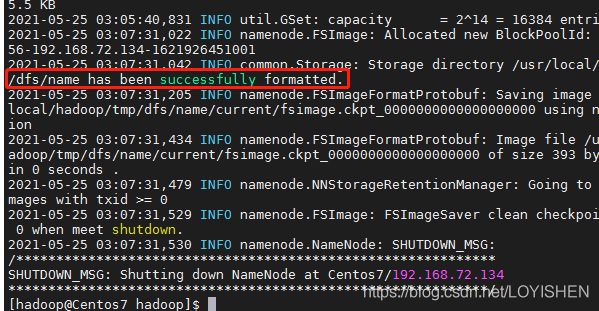
假如出现
Error: JAVA_HOME is not set and could not be found.错误时:
- 使用文本编辑文件打开
/usr/local/hadoop/etc/hadoop/hadoop-env.sh文件- 找到
export JAVA_HOME=${JAVA_HOME}这一行- 把它修改成
export JAVA_HOME=/usr/lib/jvm/default-java即可。
打开NameNode和DataNode守护进程:
cd /usr/local/hadoop
sbin/start-dfs.sh
启动时出现
Could not resolve hostname警告
解决办法:
- 忽略,不用管它
- 可以添加两个环境变量:
export HADOOP_HOME=/usr/local/hadoop export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
此时可以运行jps命令查看是否启动成功,假如看到类似下面的结果,则表明启动成功:
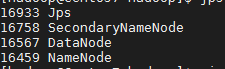
- 假如
SecondaryNameNode没有启动,需要先执行sbin/stop-dfs.sh停止,然后重新启动一下。假如这样还不行,可以为/etc/hosts添加一条记录,指向自己的主机名,我的主机名是centos7,所以添加记录之后如下:
- 假如没有NameNode或者DataNode,则配置不成功,检查一下配置有没有问题,或者看一下日志解决。

启动成果之后,可以登录到服务器的9870端口查看hadoop的web页面(请对应到自己的虚拟机的ip):
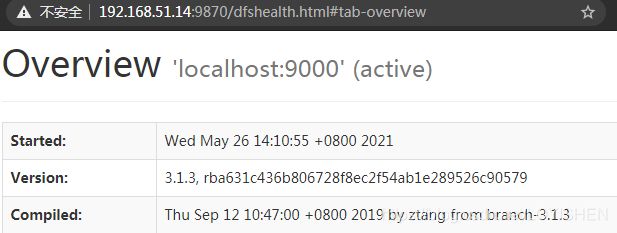
因为使用的是centos7的最小化安装系统,这里会发现
不能打开网页。原因是防火墙ban掉了端口,这里可以暂时地删除所有防火墙规则,也可以永久关闭防火墙:iptables -F # 清除所有防火墙规则 systemctl stop firewalld # 关闭防火墙 systemctl disable firewalld # 开机不启动防火墙
接下来就可以执行hdfs的操作了。
为了能够不用每次都进入hadoop目录和敲出一大串命令才能执行hadoop相关的命令,这里就把hadoop的环境加到PATH环境变量中,我写到了hadoop家目录下的.bashrc文件了:
echo "export PATH=/usr/local/hadoop/bin:/usr/local/hadoop/sbin:\$PATH" >> ~/.bashrc # 添加环境
source ~/.bashrc # 更新当前环境
至此,hadoop的安装就结束了。
参考文章
- Hadoop3.1.3安装教程_单机/伪分布式配置_Hadoop3.1.3/Ubuntu18.04(16.04)