python实现基于物品的协同过滤算法
文章目录
- 一、算法思想
- 二、实现思路
- 三、源代码
- 四、代码运行结果
一、算法思想
在上篇文章中简单实现了基于用户的协同过滤算法(userCF),该算法存在一些缺点:
- 随着用户数量的增加,计算用户相似度矩阵的时间和空间复杂度增长接近 O ( N 2 ) O(N^2) O(N2);
- 相比基于物品的协同过滤算法,基于用户的协同过滤算法可解释性稍弱(很难让用户相信:给用户推荐某个商品,原因是有个和该用户兴趣很相似的用户也买了这个商品。用户可能会有疑问:你凭什么说他和我的兴趣很相似)
基于物品的协同过滤算法(itemCF)的思想是给用户推荐 和用户喜欢的商品相似的商品,这就涉及到如何计算两个商品的相似度了。itemCF 中并不是利用物品本身的内容属性来计算相似度(这是基于内容的推荐),而是通过分析用户行为记录(评分、购买、点击、浏览等行为)来计算两个物品的相似度,同时喜欢物品A和物品B的用户数越多,就认为物品A和物品B越相似。下面介绍该算法的实现过程。
二、实现思路
- 数据集
本实现使用的数据集也是 MovieLens 提供的数据:

下载地址:MovieLens数据集
加载解压后为:

我们使用 ml-latest-small 文件夹下的 ratings.csv 文件:
该数据集中的数据格式为:
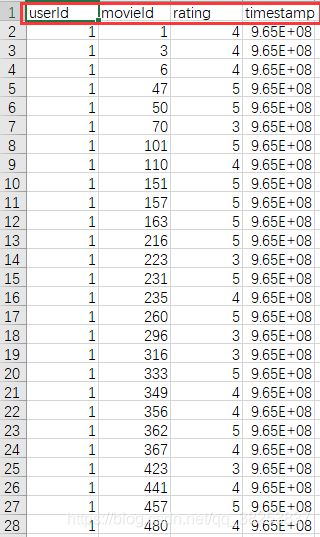
userId : 用户 ID
movieId : 用户看过的电影 ID
rating : 用户对所看电影的评分
timestap : 用户看电影的时间戳
- 定义变量
N : 记录电影被多少用户看过,如: N[“1”] = 10 表示有10个用户看过ID 为 “1”的电影;
W : 相似矩阵,存储两个用户的相似度,如:W[“1”][“2”] = 0.66 表示ID 为 “1” 的电影和 ID 为 “2” 的电影相似度为 0.66 ;
train : 用户记录数据集中的数据, 格式为: train= { user : [[item1, rating1], [item2, rating2], …], …… }
k : 使用最相似的 k 个电影
n : 为用户推荐 n 部电影
- 加载数据
从数据集中读出数据,将数据以 { user : [[item1, rating1], [item2, rating2], …],……} 的形式存入 train 中。 - 计算物品相似矩阵
本实现中物品相似度的计算公式为:
W i j = N ( i ) ⋂ N ( j ) N ( i ) ∗ N ( j ) W_{ij}=\frac{N(i)\bigcap N(j)}{\sqrt{N(i)*N(j)}} Wij=N(i)∗N(j)N(i)⋂N(j)
其中 N ( i ) N(i) N(i)表示电影 i 被看过的次数, N ( i ) ⋂ N ( j ) N(i)\bigcap N(j) N(i)⋂N(j)表示同时看过电影 i 和电影 j 的用户数。
具体计算如下(可以结合下面的源代码看):
首先遍历 train 变量 { user : [[item1, rating1], [item2, rating2], …],……} ,取出用户看过的电影列表,使用变量 i 遍历该用户看过的电影 ,对看过该电影的用户数(即变量 N(i) )加一,同时使用变量 j 遍历该用户看过的电影,如果 i 和 j 不同,则 W[i][j] 加一(此时W[i][j]记录的是同时看过电影 i 和电影 j 的用户数)。
遍历 W 矩阵,对 W 中的每一个元素进行如下计算:
W [ i ] [ j ] = W [ i ] [ j ] N ( i ) ∗ N ( j ) W[i][j] = \frac{W[i][j]}{\sqrt{N(i) * N(j)}} W[i][j]=N(i)∗N(j)W[i][j]
得到的 W 矩阵就是物品之间的相似度矩阵。
5. 推荐
首先获得用户已经看过的电影列表,遍历该电影列表,对于用户看过的电影 i ,找出与电影 i 最相似的前 k 个电影(对 W[i] 按照相似度排序),计算这 k 个电影各自的加权评分(rank):
r a n k j = ∑ i ( 用 户 对 电 影 i 的 评 分 ∗ 电 影 i 和 电 影 j 的 相 似 度 ) rank_{j}=\sum_i(用户对电影 i 的评分 * 电影 i 和电影 j 的相似度) rankj=i∑(用户对电影i的评分∗电影i和电影j的相似度)
对rank按照评分倒序排序,取前 n 个推荐给用户即可。
三、源代码
"""
@description: a demo for item_based collaborative filtering
@author: Chengcheng Zhao
@date: 2020-11-11 21:19:00
"""
import random
import operator
class ItemBasedCF:
def __init__(self):
self.N = {
} # number of item user have interacted
self.W = {
} # similarity matrix to store similarity of item i and item j
self.train = {
}
# recommend n items from the k most similar to the items user have interacted
self.k = 30
self.n = 10
def get_data(self, file_path):
"""
@description: load data from file
@param file_path: path of file
"""
print('start loading data from ', file_path)
with open(file_path, "r") as f:
for i, line in enumerate(f, 0):
if i != 0: # remove the first line that is title
line = line.strip('\r')
user, item, rating, timestamp = line.split(',')
self.train.setdefault(user, [])
self.train[user].append([item, rating])
print('loading data successfully')
def similarity(self):
"""
@description: caculate similarity between item i and item j
"""
print('start caculating similarity matrix ...')
for user, item_ratings in self.train.items():
items = [x[0] for x in item_ratings] # items that user have interacted
for i in items:
self.N.setdefault(i, 0)
self.N[i] += 1 # number of users who have interacted item i
for j in items:
if i != j:
self.W.setdefault(i, {
})
self.W[i].setdefault(j, 0)
self.W[i][j] += 1 # number of users who have interacted item i and item j
for i, j_cnt in self.W.items():
for j, cnt in j_cnt.items():
self.W[i][j] = self.W[i][j] / (self.N[i] * self.N[j]) ** 0.5 # similarity between item i and item j
print('caculating similarity matrix successfully')
def recommendation(self, user):
"""
@description: recommend n item for user
@param user: recommended user
@return items recommended for user
"""
print('start recommending items for user whose userId is ', user)
rank = {
}
watched_items = [x[0] for x in self.train[user]]
for i in watched_items:
for j, similarity in sorted(self.W[i].items(), key=operator.itemgetter(1), reverse=True)[0:self.k]:
if j not in watched_items:
rank.setdefault(j, 0.)
rank[j] += float(self.train[user][watched_items.index(i)][1]) * similarity # rating that user rate for item i * similarity between item i and item j
return sorted(rank.items(), key=operator.itemgetter(1), reverse=True)[0:self.n]
if __name__ == "__main__":
file_path = "C:\\Users\\DELL\\Desktop\\code\\python\\dataset\\ml-latest-small\\ratings.csv"
itemBasedCF = ItemBasedCF()
itemBasedCF.get_data(file_path)
itemBasedCF.similarity()
user = random.sample(list(itemBasedCF.train), 1)
rec = itemBasedCF.recommendation(user[0])
print('\nitems recommeded for user whose userId is', user[0], ':')
print(rec)
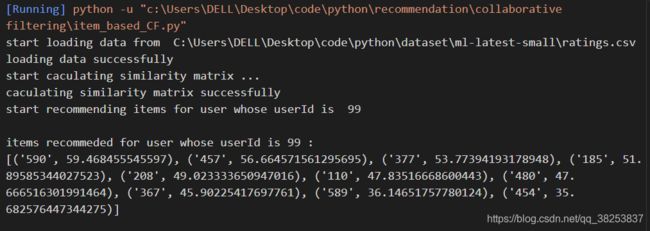
四、代码运行结果
源代码地址:基于物品的协同过滤算法
参考资料:《推荐系统实践》—— 项亮