堆(优先级队列)及TOPK问题详解
文章目录
-
- 1.二叉树的顺序存储
-
- 1.1存储方式
- 1.2下标关系
- 2.堆的应用:优先级队列(默认小根堆)
-
- 2.1概念
- 2.2Java中优先级队列的简单介绍
- 3.Topk问题
-
- 3.1求N个数中前k个最大/最小的元素
- 3.2求数组当中第K小的元素
1.二叉树的顺序存储
1.1存储方式
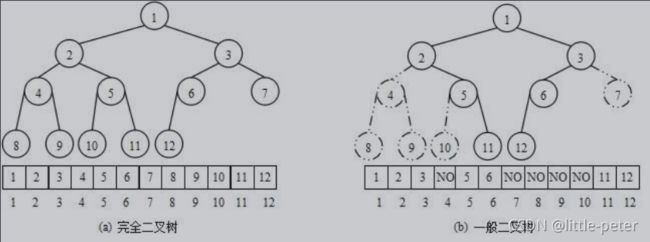
使用数组保存二叉树结构,方式即将二叉树用层序遍历方式放入数组中。
一般只适合表示完全二叉树,因为非完全二叉树会有空间的浪费。
这种方式的主要用法就是堆的表示。
1.2下标关系
已知双亲(parent)的下标,则:
左孩子(left)下标 = 2 * parent + 1;
右孩子(right)下标 = 2 * parent + 2;
已知孩子(不区分左右)(child)下标,则:
双亲(parent)下标 = (child - 1) / 2
##2. 堆(heap)
堆的概念:
1.堆结构上是一棵完全二叉树
2.堆物理上是保存在数组中
3. 满足任意结点的值都大于其子树中结点的值,叫做大堆,或者大根堆,或者最大堆
4. 反之,则是小堆,或者小根堆,或者最小堆
5. 堆的基本作用:快速找集合中的最值

建堆的时间复杂度从代码上来看是O(n*log(n)),实际上是o(n);
2.堆的应用:优先级队列(默认小根堆)
2.1概念
在很多应用中,我们通常需要按照优先级情况对待处理对象进行处理,比如首先处理优先级最高的对象,然后处理次高的对象。最简单的一个例子就是,在手机上玩游戏的时候,如果有来电,那么系统应该优先处理打进来的电话。在这种情况下,我们的数据结构应该提供两个最基本的操作,一个是返回最高优先级对象,一个是添加新的对象。这种数据结构就是优先级队列(Priority Queue)
出入列的操作我们都要保证操作完成之后其堆的状态还是与原来相同的。
2.2Java中优先级队列的简单介绍
虽然PriorityQueue它叫做优先级队列,但我们之前说过,其结构上是一棵完全二叉树,默认是小顶堆,在我们插入或删除元素时会自动将数据插入到合适的位置来保证是一个小顶堆。注意,队列中的数据不一定有序,但是每次弹出来的一定是最小(最大)的值
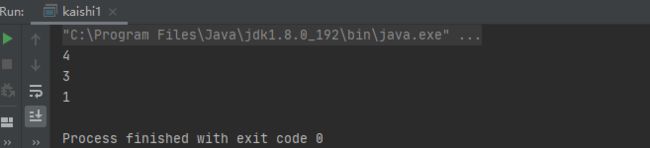
我们如何将默认的小堆改为大堆呢?如下:
import java.util.*;
public class kaishi1 {
public static void main(String[] args) {
//Comparator是一个接口,本身是不能new的,这里是匿名内部类的一种实现方式
PriorityQueue <Integer> priorityQueue=new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;//默认是小堆,比较时会调用compare方法,经过重写,在此我们就将其改成大堆的方式了
}
});
priorityQueue.offer(3);
priorityQueue.offer(1);
priorityQueue.offer(4);
System.out.println(priorityQueue.poll());
System.out.println(priorityQueue.poll());
System.out.println(priorityQueue.poll());
}
}
常用方法:
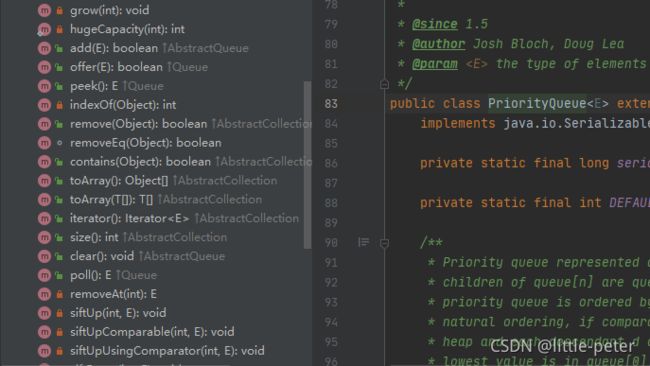
- add:插入队尾元素,不成功会抛出异常
- offer:插入队尾元素,不能被立即执行的情况下会返回true 或 false
- remove:删除队头元素,如果不成功会返回false。
- remove(Object o):删除其中一个元素o,如果o有多个则只删除一个。
- poll:删除队头元素,并返回删除的元素
- peek:查询队顶元素
- indexOf(Object o):查询对象o的索引
- contain(Object o):判断是否包含元素
3.Topk问题
3.1求N个数中前k个最大/最小的元素
注:如果N不大,我们就可以用快排解决
堆排序是通过维护大顶堆或者小顶堆来实现的。堆排序法来解决N个数中的TopK的思路是:先随机取出N个数中的K个数,将这N个数构造为小顶堆,那么堆顶的数肯定就是这K个数中最小的数了,然后再将剩下的N-K个数与堆顶进行比较,如果大于堆顶,那么说明该数有机会成为TopK,就更新堆顶为该数,此时由于小顶堆的性质可能被破坏,就还需要调整堆;
//求数组中前4个最大元素:用小堆
import java.util.*;
public class kaishi1 {
//优点:每次调整,只需要维护大小为k的堆
//求前k个最大的元素,用小堆,前k个最小的元素,用大堆
public static void topK(int []array,int k) {
//小堆
PriorityQueue<Integer> minHeap = new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1-o2;
}
});
//遍历数组
for (int i = 0; i <array.length;i++) {
if(minHeap.size()<k){
minHeap.offer(array[i]);
}else{
Integer top=minHeap.peek();
if(top!=null){
if(array[i]>top){
minHeap.poll();
minHeap.offer(array[i]);
}
}
}
}
for (int i = 0; i <k ; i++) {
System.out.println(minHeap.poll());
}
}
public static void main(String[] args) {
int []array={
1,23,34,54,65,767,876,32,21,2,56,76};
topK(array,4);
}
}

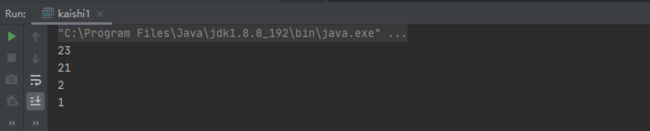
思路:求前n个最小的数 先建立最大堆 把海量数据向最大堆添加n个数,然后堆的内部会调整 ,然后我们往大堆进行插入操作 ,大堆的特点就是堆顶元素最大 若插入元素大于堆顶元素 则它大于堆中任何一个元素 所以摒弃该元素 遍历下一个元素 若插入元素小于堆顶元素则进行插入 插入后堆内自动调整 堆顶元素又成为该堆的最大元素 原堆顶元素出堆 持续遍历完 得到的就是所有元素中最小的前n个数
import java.util.*;
public class kaishi1 {
//求数组中前4个最小元素:用大堆
//优点:每次调整,只需要维护大小为k的堆
//求前k个最大的元素,用小堆,前k个最小的元素,用大堆
public static void topK(int []array,int k) {
//小堆
PriorityQueue<Integer> minHeap = new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
});
//遍历数组
for (int i = 0; i <array.length;i++) {
if(minHeap.size()<k){
minHeap.offer(array[i]);
}else{
Integer top=minHeap.peek();
if(top!=null){
if(array[i]<top){
minHeap.poll();
minHeap.offer(array[i]);
}
}
}
}
for (int i = 0; i <k ; i++) {
System.out.println(minHeap.poll());
}
}
public static void main(String[] args) {
int []array={
1,23,34,54,65,767,876,32,21,2,56,76};
topK(array,4);
}
}
根据堆排序的复杂度,不难得出,在该方法中,首先需要对K个元素进行建堆,建堆的复杂度我们上面说过,时间复杂度为O(K);然后对剩下的N-K个数对堆顶进行比较及更新,最好情况下当然是都不需要调整了,那么时间复杂度就只是遍历这N-K个数的O(N-K),这样总体的时间复杂度就是O(N),而在最坏情况下,N-K个数都需要更新堆顶,每次调整堆的时间复杂度为logK,因此此时时间复杂度就是NlogK了,总的时间复杂度就是O(K)+O(NlogK)≈O(NlogK)。空间复杂度是O(1)。值得注意的是,堆排序法提前只需读入K个数据即可,可以实现来一个数据更新一次,能够很好的实现数据动态读入并找出TopK
3.2求数组当中第K小的元素
思路:建立大小为k的大堆,当数组元素遍历完成后,堆顶元素就是第k小得元素,求前k小或第k大思路类似,在此不赘述。
import java.util.*;
public class kaishi1 {
//优点:每次调整,只需要维护大小为k的堆
//求前k个最大的元素,用小堆,前k个最小的元素,用大堆
public static void topK(int []array,int k) {
//小堆
PriorityQueue<Integer> minHeap = new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
});
//遍历数组
for (int i = 0; i <array.length;i++) {
if (minHeap.size() < k) {
minHeap.offer(array[i]);
} else {
Integer top = minHeap.peek();
if (top != null) {
if (array[i] < top) {
minHeap.poll();
minHeap.offer(array[i]);
}
}
}
}
System.out.println(minHeap.poll());
}
public static void main(String[] args) {
//Comparator是一个接口,本身是不能new的,这里是匿名内部类的一种实现方式
int []array={
1,23,34,54,65,767,876,32,21,2,56,76};
topK(array,3);
}
}

老铁们声明一下,此堆非彼堆,jvm中有堆、栈等,属于存储结构,我们这里讨论的堆为数据结构。