软件设计师【软考中级】复习笔记 —— 第七章(数据结构与算法基础)
软件设计师【软考中级】复习笔记 —— 第七章(数据结构与算法基础)
- 7.1 数据结构与算法基础
-
- 7.1.1 课程内容提要
- 7.2 数组
- 7.3 稀疏矩阵
- 7.4 数据结构的定义
-
- 7.4.1 数据结构的概念:
- 7.4.2 数据逻辑结构
- 7.5 顺序表与链表
-
- 7.5.1 线性表的概念
- 7.5.2 线性表常见的两种存储结构
- 7.6 顺序存储与链式存储
- 7.7 队列与栈(每次基本都考)
-
- 7.7.1 例题
- 7.8 广义表
- 7.9 树与二叉树的基本概念
- 7.10 满二叉树与完全二叉树
- 7.11 二叉树遍历
-
- 7.11.1 层次遍历:
- 7.11.2 前序遍历:(根左右)
- 7.11.2 中序遍历:(左根右)
- 7.11.3 后序遍历:(左右根)
- 7.12 反向构造二叉树
- 7.13 树转二叉树
- 7.14 查找二叉树(排序二叉树)
- 7.15 最优二叉树(哈夫曼树)
- 7.16 线索二叉树
- 7.17 平衡二叉树
- 7.18 图的概念及存储
-
- 7.18.1 图的存储——邻接矩阵
- 7.18.2 图的存储——邻接表
- 7.19 图的遍历
- 7.20 拓朴排序
- 7.21 图的最小生成树(普里姆算法与克鲁斯卡尔算法)
-
- 7.21.1 图的最小生成树——普里姆算法
- 7.21.2 图的最小生成树——克鲁斯卡尔算法
- 7.22 算法的特性
- 7.23 算法的时间复杂度与空间复杂度
- 7.24 顺序查找与二分查找
-
- 7.24.1 查找-顺序查找
- 7.24.2 查找-二分查找
- 7.27.3 例题
- 7.25 散列表
- 7.26 排序(必考)
- 7.27 直接插入排序
- 7.28 希尔排序(属于插入排序的一种)
- 7.29 直接选择排序
- 7.30 堆排序
-
- 7.30.1 堆的概念
- 7.30.2 堆排序
- 7.31 冒泡排序
- 7.32 快速排序
- 7.33 归并排序
- 7.34 基数排序
- 7.35 排序算法的时间复杂度和空间复杂度及稳定性
该章节对于软件设计师来说非常重要,这部分内容除了在上午的综合部分考到,下午设计部分也会考到。且算法基础部分的下午题,属于整个下午考查最难的部分。
7.1 数据结构与算法基础
7.1.1 课程内容提要

线性表中栈和队列每次必考,树和二叉树必考
7.2 数组
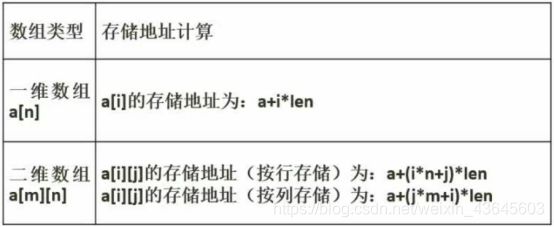
掌握:数组地址的计算;二维数组按行存储和按列存储的区别。
二维数组:按行按列存第一个元素都是a[0][0];
第二个元素:按行存是a[0][1],即第0行的第1个元素;
按列存是a[1][0],即第1列的第0个元素。
a[0][0]=a
二位数组是一张表结构,但是在计算机内存中是没有表结构的,都是线性存储。
二维数组在计算机中都是一维数组顺次存下来的。

解析:二位数组是一张表结构,但是在计算机内存中是没有表结构的,都是线性存储,所以,
a[2][3]表示的在表格当中的第二行的第三个数据,因为数组是5行5列,即该位置在线性表中是 25+3,即第13个位置,因为数组下标从0开始,所以,第13个位置,表示第14个数据,每个占得长度为2字节,所以为142=28。
7.3 稀疏矩阵
稀疏矩阵考试经常只考察一个点,计算稀疏矩阵当中某一个元素对应的一维数组的下标。
稀疏矩阵:二位数组中大量元素都为0 的话,就称为稀疏矩阵。
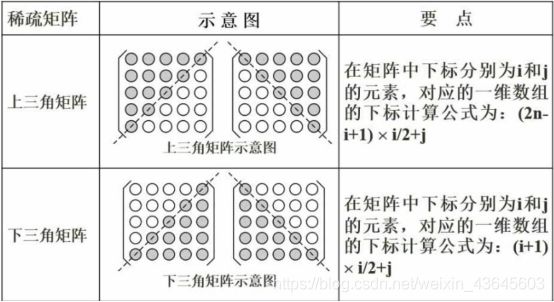

考试比较便捷的方法,代入法,因为公式肯定通用所有的可能,带入特殊值,不符合的排除,特殊值符合的有两个以上就在代入以特殊值试。依次排除。选A。
7.4 数据结构的定义
7.4.1 数据结构的概念:
数据结构即计算机存储即组织数据的方式。选择不同的数据结构,带来的运行效率差异很大。
7.4.2 数据逻辑结构
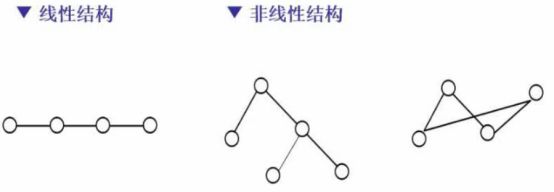
非线性结构可分为树形结构和图。
树形结构中没有环路,而图中有环路。
广义的图既包括树形结构,也包括线性结构。
广义的树包括了线性结构。
所以,主要的区别是从逻辑结构上来讲,分成这几种类型,便于我们进行分类的探讨与研究。
7.5 顺序表与链表
7.5.1 线性表的概念
7.5.2 线性表常见的两种存储结构
一种是顺序表的方式来存储,另一种是链表的方式来存储。

开辟了连续的空间,顺次的把表存进来,即一维数组的方式来存信息。
链表:每一个存储单元包含了存数据的部分和存指针的部分。因为这一部分空间是不连续的。
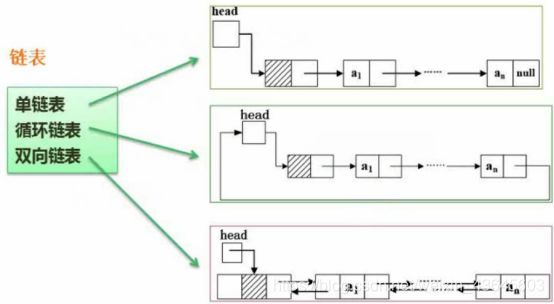
链表的基本操作
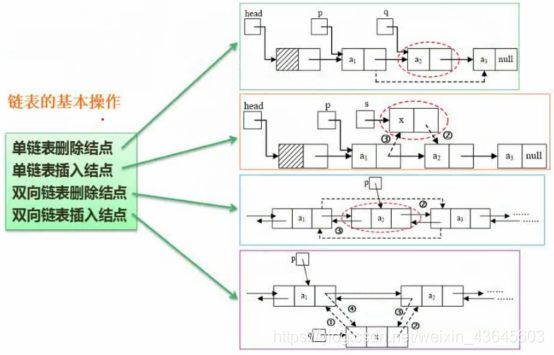
单链表删除节点:要删除a2节点,我们只需要让a1的next指向a3即可。
但是a3是没有直接指针指向的,所以需要辅助指针,q的next。
让p的next指向q的next。
单链表插入节点:要将x节点插入到a1和a2之间,要插入的节点用s指针指向它,辅助指针指向a1;
先将新节点的指针指向a2,即s的next指向p的next。再将p的next指向s。
双向链表删除和插入的原理和单向链表相同,只是操作复杂一点,因为涉及两套指针的修改。
单链表分有头节点的和没有头结点的。
有头节点的,单独有一个头结点,该节点不存任何信息,头结点的下一个元素才存信息,引入头节点有啥好处——引入头节点可以让所有节点的操作方式变成一致的。 如果头节点存了数据,那么头节点的处理往往要采取不同的处理方式。
7.6 顺序存储与链式存储
线性表-顺序存储与链式存储对比。
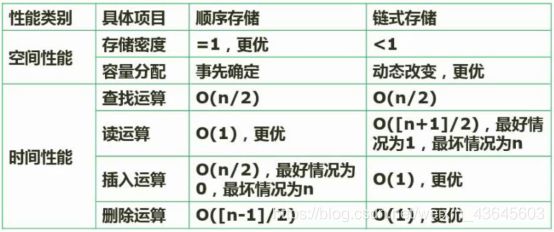
顺序存储存储密度为1,即100%;链式存储因为要存指针,所以存储密度小于100%。
给定下标读取时候,顺序存储更优。
7.7 队列与栈(每次基本都考)
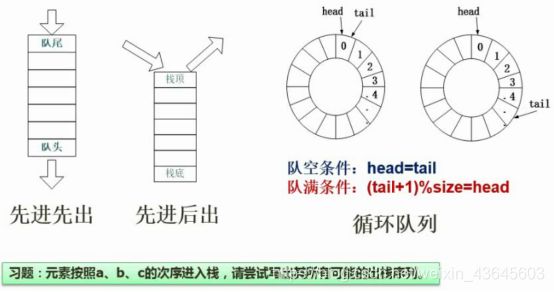
循环队列:对头和队尾连接起来,形成了一个圈。
对空条件:头和尾相等,指向同样的空间。
对满条件:也是头和尾相等。为了避免混淆,所以约定,少存一个元素,即队列的最大存储容量是(可以存的总数-1)。所以,队满的条件是:(队尾+1)% 可以存的总数 = 队头,即为队满。
习题解答:a、b、c依次入栈,则出栈顺序是c、b、a;
a先入栈,再a出栈;然后b入栈,b出栈;然后c入栈,c出栈。出栈顺序是a、b、c。
a、b先入栈,然后b先出栈,a在出栈,然后c入栈,出栈,出栈顺序是a、c。
7.7.1 例题
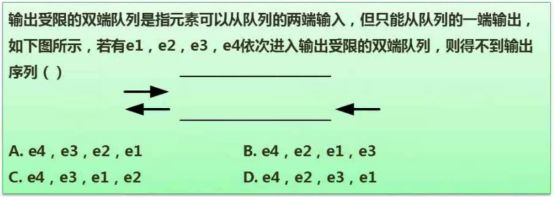
选D。分析:e4每个选项都有,必然是最先出来的,故排除e4,不去考虑。
A:只要从左端依次输入e1,e2,e3,e4即可。
B:左端放入e1,e2,右端放入e3,左端放入e4。
C:右端放入e1,e2,左端放入e3,e4。
7.8 广义表
广义表长度和深度的求法要求掌握

LS1中,第一个是表元素,第二,第三都是子表。
例1答案:长度为3,深度为2。
广义表中有两种操作:取表头head和取表尾tail。
表头:最外层的第一个表元素。
表尾:除了第一个元素以外的其他所有元素。
例2:只有取表头和取表尾,如何取出b元素。
head ( head ( tail ( LS1 ) ) ) 即可取出b字母。
7.9 树与二叉树的基本概念
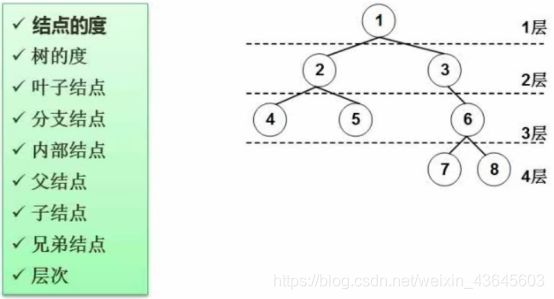
结点:即图中,1,2,3,4,5,6,7,8
结点的度:一个结点拥有的子结点数。1号结点拥有两个孩子结点,所以1号结点度为2。3号结点只有一个孩子结点,所以度为1。
7号结点是一个叶子结点,没有孩子结点,属于最末端的节点,度为0。
树的度:在一个树当中,所有结点度数最高的度就是树的度。上面的树所有结点度数最高的为2度,所以整个树的度为2。
叶子结点:类似4,5,7,8没有子结点的都属于叶子结点。
分支结点:类似2,3,6这种有分支的结点。
内部节点:即非叶子结点,也非根结点。(2,3,6这种夹在中间的结点)
父结点、子结点:相对概念,2,4之间,2是父结点,4是子结点,但是在1,2当中,1才是父节点,2是子结点。
兄弟结点:属于同一个父结点,平级的结点。
树的层次:树总共有几层。
7.10 满二叉树与完全二叉树
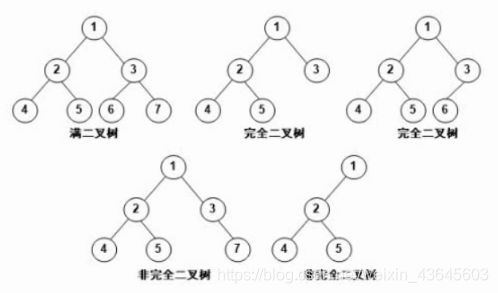

满二叉树:整棵树没有缺失的结点,所有结点的及子结点都是完整的。
完全二叉树:除了最底下一层,上面的层次都是满的树。而底下一层的结点是从左到右排列的。左边的结点都是满的,缺的只是右边的结点。编号依次排列,没有缺失。
非完全二叉树:编号有缺失,跳跃。
7.11 二叉树遍历
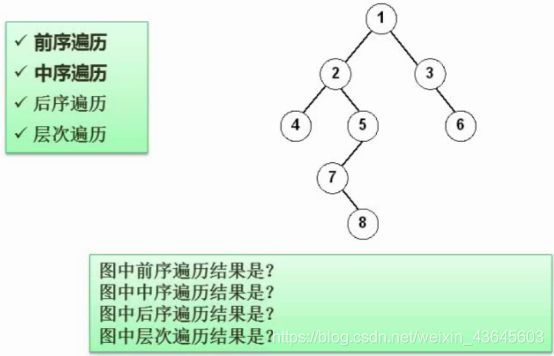
7.11.1 层次遍历:
一层一层的来,先把第一层的结点从左到右访问完,再来第二层,依次类推,遍历完所有层次的结点。
上面层次遍历的结果是:1、2、3、4、5、6、7、8
前序、中序、后序区别就是根结点什么时候访问。
7.11.2 前序遍历:(根左右)
先访问根结点,再访问左子树和右子树结点。
前序遍历结果:1、2、4、5、7、8、3、6
7.11.2 中序遍历:(左根右)
先访问左子树结点,再访问根结点,再访问右子树结点。
中序遍历的结果:4、2、7、8、5、1、3、6
7.11.3 后序遍历:(左右根)
先访问左子树结点,在访问右子树结点,最后访问根结点。
后序遍历的结果:4、8、7、5、2、6、3、1
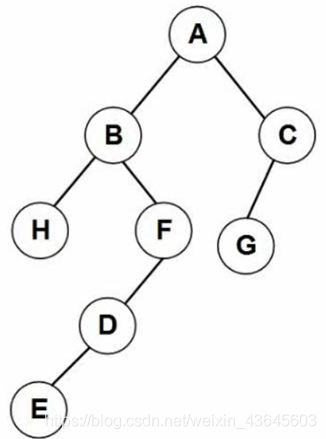
7.12 反向构造二叉树
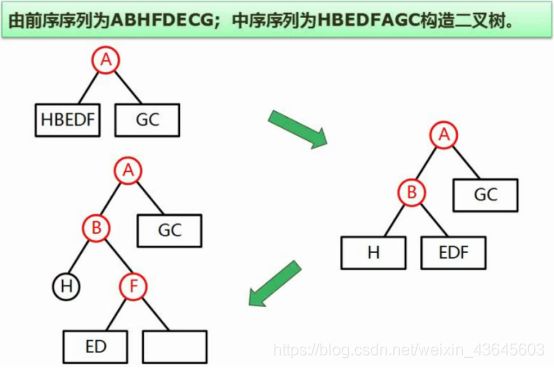
如果有前序和中序,或者中序和后序,都能够将一棵二叉树还原出来,但是仅仅有前序和后序是办不到的。
考查题型一般是给我们两种序列,让我们构造出相应的二叉树。或者给我们两种序列,问第三种。
分析例题:前序遍历的顺序是“根左右”,所以由前序遍历我们可以得到第一个是根结点,然后将根结点A这个结论代入到中序遍历中,找到A的位置,中序遍历的顺序是“左根右”,我们将根结点标识出来,就把左子树结点和右子树结点的分界点找到了。
BHFDE为左子树结点,CG为右子树结点。
左子树结点的字母当中,前序遍历第一个访问到的是B结点。同理,确定B为左子树的根结点。在中序序列中找到B,标识出来,确定H是B的左子树,EDF是B的 右子树。EDF三个结点中判断哪一个是根结点,回到前序遍历中,前序遍历中,这三个字母的顺序是FDE,则可以确定F是根结点。标注出来之后,发现D和E都是左子树结点。进一步分析可以得出D是D和E中的根结点,E在D的左边,所以E是左子树结点。
同理,完成C和G的分析,我们就可以构造出一棵完整的二叉树。
答案如下:
如果有前序和中序,或者中序和后序,都能够将一棵二叉树还原出来,但是仅仅有前序和后序是办不到的。
考查题型一般是给我们两种序列,让我们构造出相应的二叉树。或者给我们两种序列,问第三种。
分析例题:前序遍历的顺序是“根左右”,所以由前序遍历我们可以得到第一个是根结点,然后将根结点A这个结论代入到中序遍历中,找到A的位置,中序遍历的顺序是“左根右”,我们将根结点标识出来,就把左子树结点和右子树结点的分界点找到了。
BHFDE为左子树结点,CG为右子树结点。
左子树结点的字母当中,前序遍历第一个访问到的是B结点。同理,确定B为左子树的根结点。在中序序列中找到B,标识出来,确定H是B的左子树,EDF是B的 右子树。EDF三个结点中判断哪一个是根结点,回到前序遍历中,前序遍历中,这三个字母的顺序是FDE,则可以确定F是根结点。标注出来之后,发现D和E都是左子树结点。进一步分析可以得出D是D和E中的根结点,E在D的左边,所以E是左子树结点。
同理,完成C和G的分析,我们就可以构造出一棵完整的二叉树。
答案如下:
7.13 树转二叉树
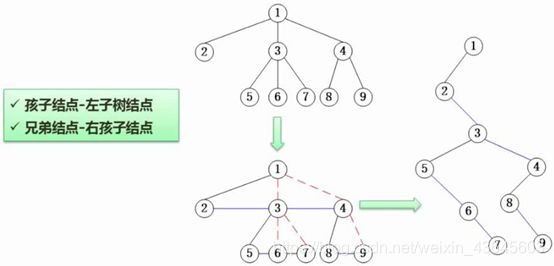
树方面的内容基本是围绕二叉树展开的。
一般对于普通的树没人做研究,所以一般会将普通的树转为二叉树进行分析,讨论。
如何将树转成二叉树,有一个基本原则:
在树当中一个结点的孩子结点都会成为这个孩子的左子树结点,兄弟结点都会成为这个树的右子树结点。
例题分析:根结点为1,之下的2、3、4都是它的孩子结点,而没有兄弟结点。所以我们会将2、3、4作为左子树结点来处理。那么会有3个,但是在构造二叉树的时候,某个树的左子树结点只能有一个,于是便指定,所有孩子结点中,最左边一个作为左子树的根结点,此时,对于2而言是有兄弟结点的,3和4都是它的兄弟结点,3和4会被当成2的右子树结点,此时又有两个,只能取一个3,对于3而言,有5、6、7三个孩子,三个孩子当中,5会成为左子树结点的根结点,6由于是5的兄弟结点,成为它的右孩子结点,7是6的兄弟,所以6的右3孩子,同理来处理4、8、9,就得到了一棵二叉树。
如果要简单的去转化二叉树,还有一个方法:连线法。对于兄弟结点我们把它连线,对于有多个孩子的,只保留第一个孩子的那一条线,兄弟结点直接平连起来,在把树做一下旋转,就能得到二叉树,如上图所示。
7.14 查找二叉树(排序二叉树)

左小右大
查找二叉树是一种比较特殊的二叉树,特殊之处在于:
查找二叉树的根结点的左子树结点都比根结点的值要小,右子树结点的树都比根的值要大。对于每一级子树也满足这个条件;
对于所有左子树小于根结点,右子树大于根结点的树,称为查找二叉树,或者称为排序二叉树。
这种树构造出来的价值和意义何在?
能够极大的提高查询的速度,效率。
查找二叉树进行插入节点和删除节点要进行怎样的操作?
插入结点:不允许有两个结点的值相等。
删除节点:
掌握查找二叉树的基本特性,插入和删除是拔高阶段要掌握的。
7.15 最优二叉树(哈夫曼树)
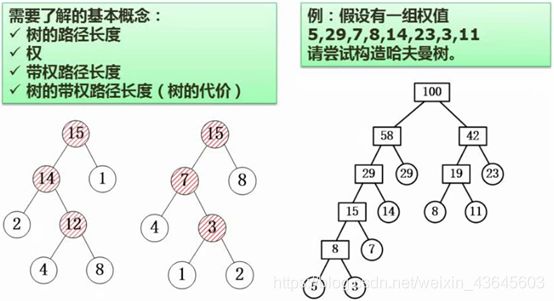
最优二叉树又称为哈夫曼树,这种树是一种工具。用于哈夫曼编码:哈夫曼编码是一种压缩编码方式,能够让原始信息的编码长度变得更短,从而节省存储空间和传输带宽。这种编码在多媒体领域的压缩技术当中经常使用到,属于无损(压缩之后可以还原,不会有信息的损失)压缩的方式。
考查: 1:了解哈夫曼树的基本概念;
2:会计算树的带权路径长度。(计算哈夫曼树的方式,构造哈夫曼树的过程)。
树的路径长度:树当中的路径,一段一段累加起来有多长。
权:某个叶子结点他有一个数值,这个数值代表了某一字符出现的频度。
带权路径长度:将路径的长度求出来,再乘以权值;
2号结点,从根结点到2号结点,路径长度为2,该结点的权值为2,所以带权长度为4;
4号结点,从根结点到4号结点,路径长度为3,权值为4,所以带权长度为12;
8号结点权值为24。
树的带权路径长度:将所有的带权路径长度累加起来,就是树的带权路径长度。
构造一棵哈夫曼树,要达到的效果是:让一个棵树的带权路径长度是最短的情况。
同样是1、2、4、8组成的哈夫曼树,第一种方式组成的树的带权路径长度有41,第二种只有25,所以,第二种树的带权路径长度总得来讲要短一些,我们的目标就是构造最短的带权路径长度的树。
例题分析:在整个树列当中选出两个权值最小的构成一棵小的子树,即3和5,这个小树的权就是8,然后在原来的树列中将5和3删除,将8加入树列;
然后在该树列中找出两个权值最小的7和8,构成一棵树;将7和8在原树列中删掉,将15加入新树列;
选出最小的两个8和11,8和11构成的结点,权值19;
接下来最小的就是14和15了,14和15构成的29,以此类推,一层层垒上去,就得到这棵哈夫曼树。
求整棵哈夫曼树的带权路径长度。将每个叶子结点的带权路径长度求出来,再累加。
为什么求树的带权路径长度,只要求叶子结点,而不要求分支结点?
因为只有叶子结点是初始的权值,所有的中间结点都是我们构造出来的中间结点,在原始数据中,没有这些结点,所以只要将叶子结点的带权路径长度累加起来即可。
7.16 线索二叉树
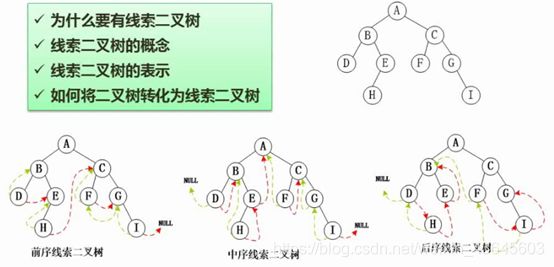
在二叉树的基础之上,会有虚线的渐线,把很多结点串起来。
为什么提出线索二叉树?
因为我们发现在二叉树当中,很多节点是属于空闲状态,有很多指针都是空的,没有利用起来。我们可以将这些空闲的资源利用起来,主要就是为了方便遍历。由于方便遍历,所以提出了前序、中序、后序线索二叉树。
前序线索的箭头是按前序序列来生成的。
中序线索的箭头是按中序遍历时的顺序来生成的。
后序线索就按后序遍历的顺序来生成。
其中左子树结点的指针指向当前结点遍历当中的前序结点。
右子树结点的指针指向该种遍历的后序结点。
如图,前序线索二叉树,前序遍历结果是ABDEHCFGI,左子树结点D的的指针指向当前结点遍历当中的前序结点B。右子树结点的指针指向前序遍历的后序结点E。
7.17 平衡二叉树
同样的一个序列,排序二叉树可能有多棵,形态不一样。
上图,最左边和最右边的排序二叉树都是同一个树列生成的,但是最右边的查找效率更好,更平衡。
一棵排序二叉树越平衡,它的查找效率越高。
平衡二叉树的定义:任意结点左右子树的深度相差不超过1,也就是每个结点的平衡度只能为-1,0或1。
平衡度如何求:对于所有的叶子结点而言,他们的平衡度都是0,因为左子树深度为0,右子树深度也为0,相减也为0。

对于不平衡的二叉树,要进行调整,调整思路:把相应的树折过来。
平衡二叉树平衡度的计算及左右子树的深度相差不查过1。
不能忽视,有些地方的一些子树比较特殊,要一层一层让每一棵树都达到相关的要求。
这棵树才能是平衡二叉树。
7.18 图的概念及存储
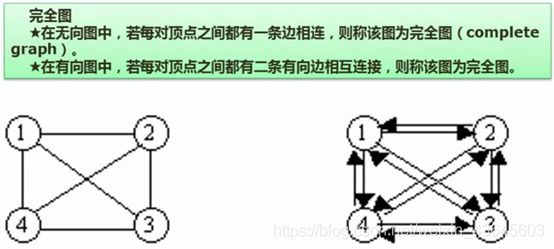
无向图:左边的图,指两个结点之间的连线是不带箭头的,这种线代表1和2之间既可以从1到2,也可以从2到1,没有方向性
有向图:右边的图,有向图的所有的边都是有方向性的,从1到2的边是从1到2引入的箭头,箭头指向代表只能够从1到2,带方向性,反过来会有一条从2到1的箭头代表2也能够到1,假设只有从1到2的箭头,代表从2到1是走不通的。
完全图:无论无向图还是有向图,都有完全图的概念,所谓完全图就是该链边的地方都连好了,连全了,连满了;
在无向图中,四个结点最多只能连6条边。
7.18.1 图的存储——邻接矩阵
图中存储方式主要有两种:
第一种就是邻接矩阵,用一个矩阵来存图的关系。
第二种就是邻接表。
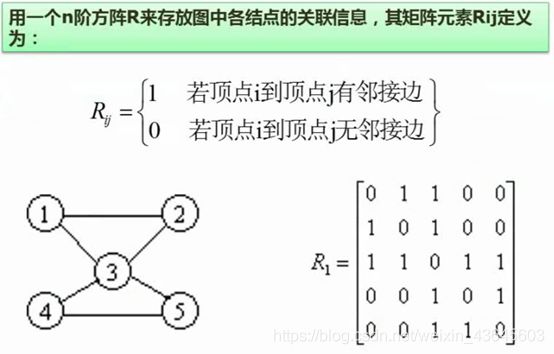
邻接矩阵:矩阵的大小取决于点的数量,上面总共有5个点,所以邻接矩阵是个5X5的二维表,1到1,就是自己到自己,没有连线,所以坐标(0,0)位置用0表示,代表1和1之间没有边;
1和2之间有一条边,所以(1,2)坐标对应1;
1到3有边,所以(1,3)坐标位置对应的也是1;
2到1·有边,所以(2,1)坐标位置对应1,以此类推。
对于无向图而言,邻接矩阵,按左上到右下的对角线有对称性,所以,如果想节省存储空间,可以只存上三角或下三角矩阵。
7.18.2 图的存储——邻接表
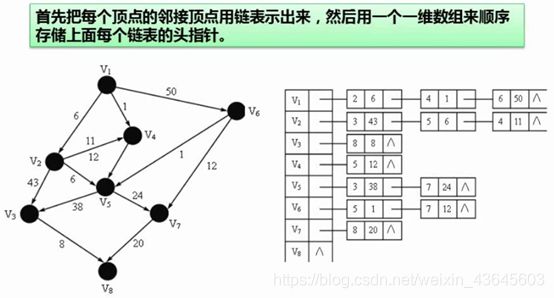
利用邻接表如何来存一个图:
邻接表首先会有一个表记录了所有的结点,每个结点能够到那个结点,用链表的方式存起来;
对于V1结点,跟他相邻的结点有V2、V4、V6,到V2距离是6,到V4距离是1,到V6距离是50;所以邻接表中记录到V2记录6,到V4记录1,到V6记录50;
同理,从V2可以到V3,V5,V4,以此类推。就是邻接表的方式来存储一个图的基本信息。
会用一个数组来记录图的结点,再用链表来记录每个结点可以到的顶点情况。
7.19 图的遍历
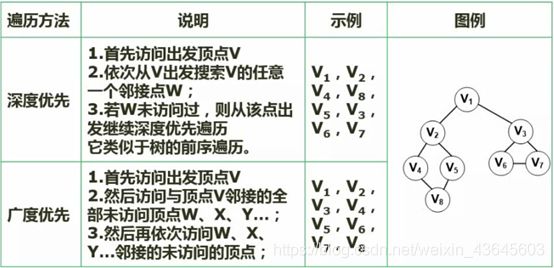
深度优先:根据线索一层一层深入到底,只有无法继续深入,才退回来进入下一个分支。
广度优先:把一个结点所相邻的所有结点全部访问完,在继续下一个层次。
这种示意不是很严谨,因为我们不知道它存储的结构如何。
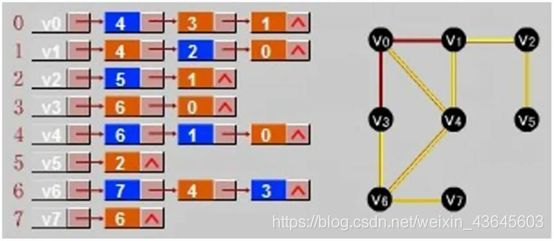
从V0作为起点进行相应的遍历:
按广度优先遍历,会先访问V4,V3,V1,因为这是V0所邻接的一系列结点,把这个链表李的所有结点全部访问完,然后再访问到V4,V4邻接的结点V6,(V4、V0已经访问过了,不管它),这是广度优先的走法。访问完V4邻接的,就访问V3邻接的V6,V6刚已经访问过,不再访问,V0也是,再就是V1所邻接的,V4访问过了,V2没有访问, 在通过V2线索访问到V5,访问完V5,在回溯到V4邻接的V6,V6邻接的有V7,是按邻接的顺序去走。
深度优先:V0到V4,在访问V4邻接的V6,再访问V6所邻接的V7,到V7,深度的一条线已经走到底了,回退到。
深度就是试探到底,不能深入了,回退一步,在往下,在回退一步,在往下。
7.20 拓朴排序
拓扑排序:用一个序列来表达一个图当中哪些事件可以先执行,哪些事件可以后执行。
因为在项目当中会有多个活动需要完成的任务,这些任务之间可能存在着一定的约束的关系,必须要先完成哪一个工作,才能开始下一个工作。有这样的先后关系,我们可以把先后顺序排列下来。看可以用什么样的顺序来完成该任务。
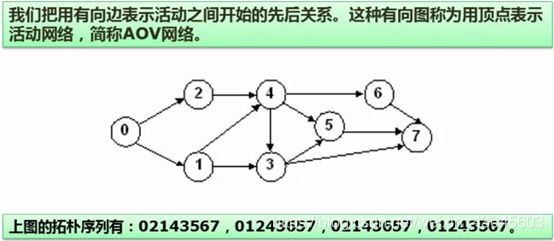
拓扑序列如何求解?
在上图中,可以执行的第一个任务是0,其他的所有任务都不可以排在一个进行,因为0是没有任何约束的(没有任务箭头指向它,代表了没有任务可以约束到0),一开始就可以执行。0执行完之后,1和2不受约束了,可以执行1,也可以执行2,并且只有当1和2都执行完,才能执行3和4,先执行4,在执行3,然后可以执行5或者6,3、5、6都执行完,最后才能执行7。
所以,拓扑排序可能产生多个不同的序列。
7.21 图的最小生成树(普里姆算法与克鲁斯卡尔算法)
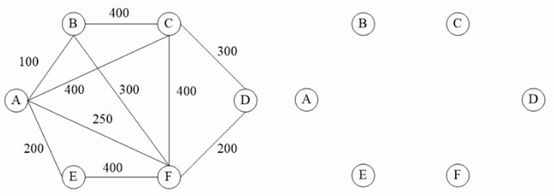
图的最小生成树:把这个图当中很多的线、边去掉,只留下若干条边把所有节点连贯起来,留下来的边都是权值比较小,从而使得整个留下来的部分它的权值加起来是最小的状态。
留下来的这部分被称为生成树,说明已经是一种树结构了。
树和图的区别:最大区别是树没有环路,图是有环路的。
如果一棵树的结点树是n,那么它的边的条数最多就是n-1,如果边也是n的话,就说明已经是图了,已经构成了环路。
图生成树,根据图的结点选出边来,上面有6个结点,应该选出5条边,这5条边加起来的长度是属于最短的情况,就是最小生成树。
求最小生成树:常用算法有两种,一种是普里姆算法,另一种是克鲁斯卡尔算法。
7.21.1 图的最小生成树——普里姆算法
普里姆算法:从任意一个结点出发,比如选A结点,将A定义为红点集,其他结点定义为蓝点集,A进入红点集之后,整个红点集只有A一个结点,然后找出从红点集到蓝点集合里面最短的距离,A能到B距离100,能到C距离400,能到F距离250,能到E距离200,选最短的100,将树中的A和B连起来,然后将和A连起来的结点自然就纳入到了红点集,纳入到红点集之后,再看从红点集到蓝点集最短的距离,最短距离是红点集中的A到E距离200,所以,将树中的A和E连起来,E进入红点集,E进入红点集之后,红点集到蓝点集最短距离是A到F距离250,将A和F连起来,此时,F进入红点集,再从红点集出发到蓝点集,最短的是F到D距离200,将F和D连起来,将D纳入进红点集,然后最短距离是D到C距离300。
这样就形成了最小生成树,这些线的总长度,会是图当中选出5条线最短的情况;另外,我们选的这些边要注意一个原则:不能够形成环。一旦形成环,就不满足要求了。
7.21.2 图的最小生成树——克鲁斯卡尔算法
克鲁斯卡尔算法:首先确定要选5条边,从最短的边选起,最短的边是A到B之间的100的一条边,接下来剩下的可选的是A到E之间的200的第二条边,F到D之间200的第三条边,接下来就是A到F250的第四条边,接下来不能选B和F之间的300,因为会形成环,只能选C和D之间的300的第五条边。
7.22 算法的特性

确定性:同样的数据输入进去,只能够得到相同的数。
输入:0个或0个以上的输入。
输出:最少有一个输出,没有任何输出的算法是没意义的。
有效性要注意和有穷性区别,有穷性是步骤的数量,有效性是每个步骤都能得到有效的结果。
比如:除法运算中,除数为零就违反了有效性原则。
7.23 算法的时间复杂度与空间复杂度
算法负责度分为时间复杂度和空间复杂度两个维度:
考的比较多的是时间复杂度,下午的设计题中出现关于时间复杂度的提问。
让你来分析咱们的程序代码说涉及到的算法的时间复杂度情况如何。

O(1)代表时间复杂度是常数级。比如执行:i = 0 这样赋初值的语句,这样的语句时间复杂度就是O(1)。如果还有两条 j = 0,k = 1,3条,时间复杂度可以记为O(3),当然,更多的时候是将O(3)写成O(1)的形式,因为如果确定只有3条,或者说可以用常数表达的条数,那就认为都是常数级的时间复杂度,所有常数级的时间复杂度都用O(1)来代表。
比如有一个循环,循环次数为n,时间复杂度记为O(n),代表整个算法要执行消耗的时间,它的规模和n的大小是正相关的。
假设有一个嵌套循环,外层循环和内层循环的循环变量都是1~n,那么该嵌套循环的时间复杂度就是O(n)2,三重循环就是O(n)3。
在对树的处理中,经常用到O(log 2n),假设有一棵平衡度很高的排序二叉树,我们要去查找排序二叉树中的一个键值,此时的时间复杂度和二叉树的层数有关,二叉树有多少层,我们最多就比多少次,次数就是 log2n,n就是结点的数量。

7.24 顺序查找与二分查找
7.24.1 查找-顺序查找


顺序查找平均比较次数为 n+1 / 2 ,1代表第一个比对就找到了 ,n就是将n个数据都比对了一次。
顺序查找的时间复杂度为O(n),因为n+1 / 2,当n很大时,1可以忽略不计,相对于是n/2,
n / 2就是O(n)数量级的。
顺序查找常见,简单,但是整体效率不高
7.24.2 查找-二分查找

不是所有序列都能用二分查找法,二分查找到前题是该序列是有序排列的。
7.27.3 例题
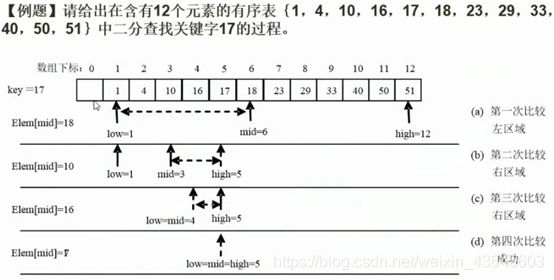
二分查找注意事项:
中间位置确定是向下取整,比如上图1+12/2=6.5,取整中间位置为6,下一次比较时候,6号位置不参与比较,只比1——5号,因为6号已经比较过了。
二分查找法整个的时间复杂度:
![]()
log2n 向下取整+1,效率高,查找数据越多,优势越明显。
![]()
7.25 散列表
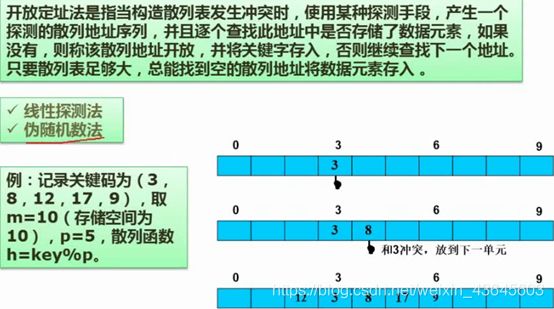
散列表跟之前讲过的按内容存储比较接近,散列表本身就是按内容存储的。
存储之前就定好规则,存储到相应的空间中。取和查就很方便。
线性探测法:当两个数的存储空间冲突时,当前空间已有数字,将第二个数顺次放到该空间的下一个空间。例如:当前3号空间被占了,就将该数装到3号空间的下一个空间,即4号空间。如12存在2号位置,17也存在2号位置,但是2号位置已经被12占了,只能放到下一个空间,下一个再被占,就在下一个,依次规则,往后顺次移动就是。
散列表要做好,就要精心设计,让冲突的可能性尽可能的小。效率才会高。
可以将整体空间设计大一些,冲突概率就降低了。
伪随机数法:二次散列。即当存储空间冲突时,可以再设计一个散列函数,进行二次散列,得到新的空间。
7.26 排序(必考)
排序在整个数据结构与算法部分是非常重要的部分,每次考试必考排序。
有时仅在上午题中考,有时上午下午都考。

稳定与不稳定排序:以上树列中,存在红色和黑色两个21,未排序之前黑色21在红色21之前;那么稳定排序之后,黑色21依旧在红色21之前,即键值相同等的数的顺序不会因为排序而发生改变;而不稳定排序之后,无法保证键值相等的数的顺序的原始顺序。
内排序和外排序:内排序是指在内存中进行的排序;而外排序会涉及到外部的存储空间。
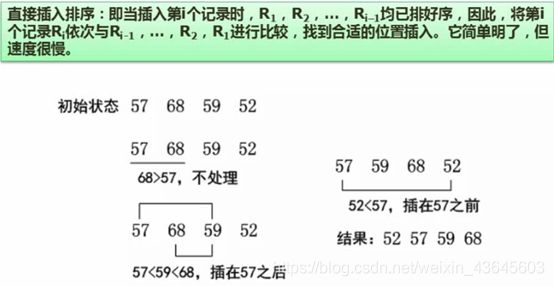
直接插入排序小效率简单,操作容易,但是效率没有希尔排序高。
快速排序较冒泡排序效率比较高,但过程相对复杂。
堆排序的效率很高,但是整个处理过程复杂。堆排序建堆的过程和操作排序二叉树类似,涉及到把堆建立起来之后,要删除一个结点,应该如何调整这棵树仍然是一个堆的基本形态。
正是因为快速排序,堆排序这种比较复杂,不容易实现的排序算法,考试考程序会考的多一些。简单的算法,考程序基本很少考。
归并排序和基数排序了解基本思路。考查概率相对较小。
7.27 直接插入排序
7.28 希尔排序(属于插入排序的一种)
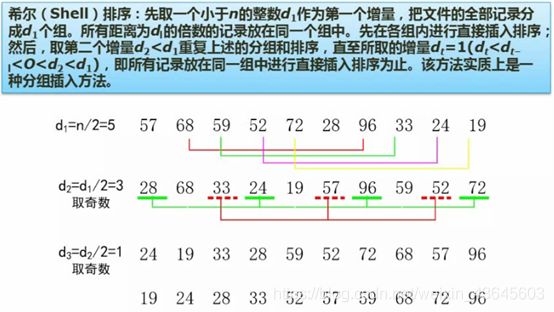
n代表将要排序序列数字个数。
分析排序过程:首先取到的d1是5,也就是每隔5个元素分成一个组,如:第一个57和隔5个后的第六个元素28为一组,以此原则分组。然后组内进行直接插入排序,如:将57和28进行比较,57>28,将57和28进行交换,以此原则将每一个组内完成相应的排序。
排序之后将新的序列分组值d2进一步缩小调整,调整到3,没相隔3个元素是一组,如第一、四、七、十位置的数28、24、96、72为一组,一次原则完成所有分组。再用直接插入排序给每一组进行排序,每一组排序完成后,得到新的序列。
对新的序列进一步取距离值为1,即所有数都是一个组,再进行直接插入排序。
这样操作的优势:经过前面两轮的初步排序之后,整个的序列变得基本有序了,然后在用直接插入排序,那么元素的挪动位置次数就大大的减少(经过两次分组排序后,偏小的数都在前部空间,偏大一点的数都在后部空间),直接插入排序进行插入的时候不需要比较很多次(在统计学上做过分析和研究),所以希尔排序整个的效率要比直接插入排序高。尤其当问题空间比较大时,效果更加明星。
希尔排序借助的理论基础:当排序的数列比较小时,直接插入排序效率还是可以的,当数据越多,直接插入排序效率下降明显。通过分组的方式将解决问题的规模缩小,先将序列大体理好,然后再一轮彻底排好。
7.29 直接选择排序
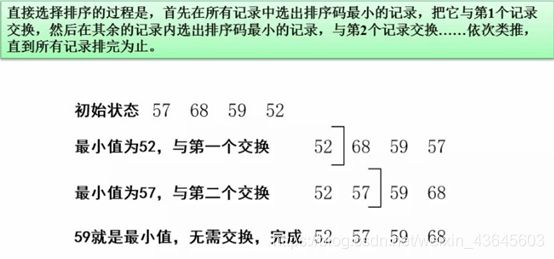
7.30 堆排序
7.30.1 堆的概念
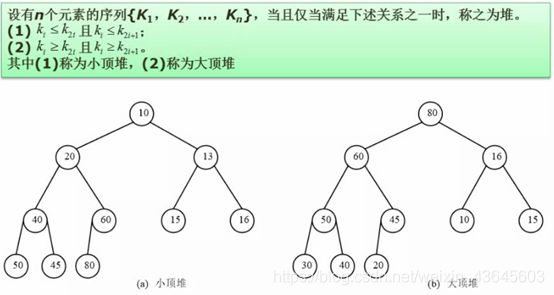
堆结构和完全二叉树结构相同。
所有孩子结点都小于根结点属于大顶堆。
所有孩子结点都大于根结点属于小顶堆。
7.30.2 堆排序

堆排序首先要建立堆,然后逐步的将堆顶元素取走,排成的序列就是有序序列;
如果要从小到大的去排列一个序列,建立一个小顶堆,第一个元素就要是最小的。
首先建立一个堆,然后 取走堆顶,然后再将堆进行重建,重建堆之后再取走堆顶,以此类推,直达把堆中的所有元素全部取走,完成排序。
其中最重要的步骤就是初建堆。
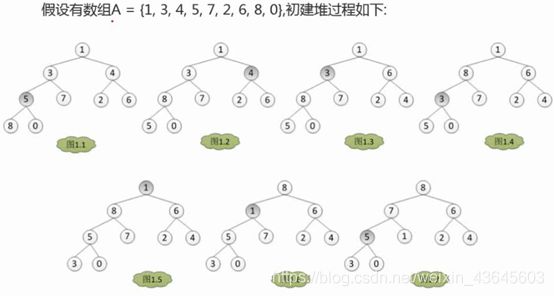
建堆按完全二叉树的方式来建,将数组中的元素顺次的排下来,构成的是一棵完全二叉树。如图1-1。
此时只是排列,并不属于堆,不满足大顶堆和小顶堆的特性。还需要调整,从最后一个非叶子结点开始调整(非叶子结点在图1-1中有1、3、4、5结点)。最后一个是5结点。从5结点开始调,看5是否大于它的两个子结点,因为我们要建一个大顶堆,5如果都大于两个孩子,不变动;但是目前5小于其中一个孩子结点,将5和孩子中的最大值和根结点5进行交换进行交换,交换之后如图1-2所示(局部的小调整)。 调整完之后,就开始调整倒数第二个叶子结点,调整原则如上,交换完之后如图1-3所示。
接下来调整3结点,3结点涉及多级调整;
首先3和8进行交换(图1-4),交换3到了下面一层之后打破了堆的规则,所以该局部要进行进一步调整,将3和5进行交换(图1-5)。最后调到根结点,将根结点的1和8进行交换(图1-6),交换之后1要进一步往地下调,将1和7进行交换(图1-7)。
此时便构建了一个大顶堆,
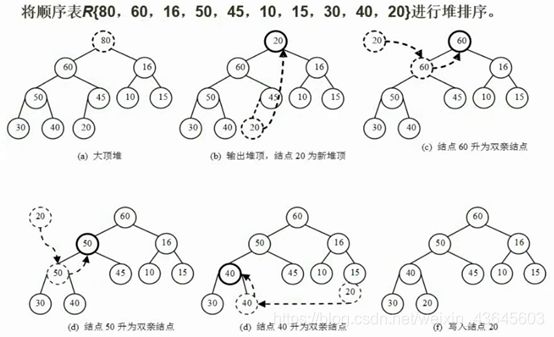
分析过程:将大顶堆的堆顶取走之后,将这棵完全二叉树的最后一个结点(20),放到堆顶上去,然后进行堆的调整,将20和它的两个孩子进行对比,然后将20和最大的孩子进行交换,交换之后,再将20继续和它的孩子结点做对比,将20和最大的孩子50进行交换,往底下调,然后再和下面的孩子30和40做比较,继续和最大的孩子记性交换。
将20调整到完全二叉树的9号位置之后,如图f所示。
至此就完成了堆的重建调整。再将堆顶元素60取出去,在按上面的规则调整。以此类推,最后就能完成排序操作。
堆排序因为利用到了树的数据结构,效率比直接排序要高很多,同时,堆排序应用在n多个元素,不需要堆所有元素进行排序,只要对一部分极值名求出来,这种方式堆排序最合适,因为每次只选出一个来。
7.31 冒泡排序
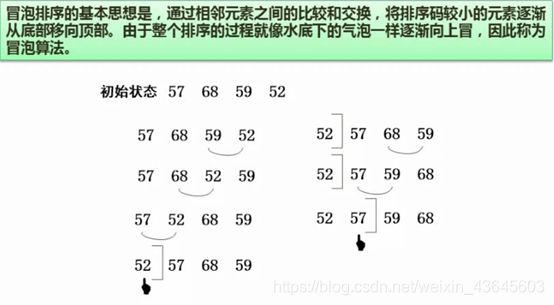
7.32 快速排序

非常具有代表性的排序算法。
快速排序基本思想采用分治法,就是把一个问题分成若干个规模更小的问题来解决。
并且排序过程采用递归的方式来进行。
具体过程分析:对要排序序列定个基准,基准没有什么特殊的要求。如:在上面序列,定第一元素57为基准,基准此时在头部,尾部还有一个指针指向最末端的元素,将最末端的元素和基准进行对比,发现比基准小,将最后一个元素和基准做交换。基准处于最后面位置。
记下来指针指向第二个元素,第二个元素再和基准对比,发现比基准大,所以又交换,将基准换到第二个位置,如果该位置数比基准小,就不用交换,只有当比较元素在前,基准在后,而前面元素比基准还要大时,就要交换到后面,交换过去之后,又从倒数第二位开始,将24和基准比较,小于基准,对调,24放前面,通过这种类踢皮球的方式。
大于基准的都往后面放,小于基准的都往前放,经过一轮后发现,基准在中间,前面的序列都小于基准,后面的序列都大于基准,然后将两个小的序列进行完排序,整个序列就有序了。
通过基准元素及一系列的操作,将原来比较大的数列拆成两个小的数列,而每个小的数列,又可以用递归的方式用刚才同样的流程进行排序。这就是快速排序法,该方法整体比较高效。
7.33 归并排序
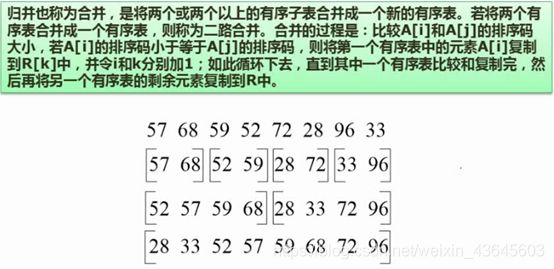
分析:假设对这8个元素进行排序,会将他们两两分组,每两个一组进行相应的排序,这个排序非常简单,然后前两组做归并,后两组做归并;第一次归并后的结果,57和52做比较,然后将较小的复制到R数组当中第k个单元,然后k+1,即数组的下一个单元,i+1即指向下一个元素,在比较i和j哪个小,即比较59和57,由于57更小,将57复制到k+1个单元,再讲值标指向68,(即将被取出组的值标下移一个单位继续比较)。
对于有序表进行合并,比无序表合并要比较的次数要少很多,所以这样的归并看起来元素比较多,但是归并速率是很块的,经过多伦归并,最终得到完整的有序表。
从之前学过的多种排序算法,都可以开出一种共同的思想,排序算法在很多地方动的脑筋都是把排序规模分块缩小。因为当问题规模扩大时候,所消耗的时间不一定是按线性增长的,可能是几何倍数增长的,所以一定要想办法将问题拆的更小一点。这样,虽然看上去要解决的问题变多了,但是每个问题的规模都很小,所以总体来讲,耗时反而会短一些。
7.34 基数排序
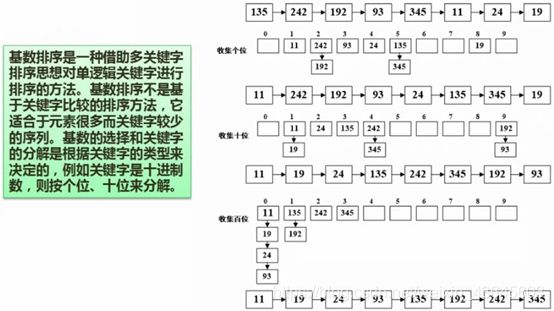
排序过程:将初始序列想按各位进行排序,如:135个位是5,放到5的位置,242个位是2放到2的位置,192个位也是2,链到242后面,以此原则,将个位收集起来进行排序,将按个位排序的结果序列按个位排序规则,进行十位排序;将十位排序的结果序列继续按照个位排序的规则进行百位排序,然后即可得到排序序列。
7.35 排序算法的时间复杂度和空间复杂度及稳定性
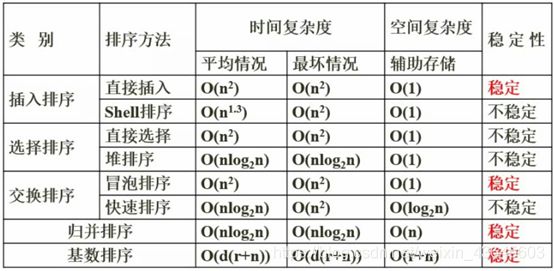
对于不同的排序算法,它的基本状况也是要求掌握的,考不同排序算法参数的,会涉及到哪些方面的参数:1。时间复杂度;2,空间复杂度;3.算法本身的稳定性(即同样关键字会不会改变顺序决定了它的稳定性)。