普林斯顿大学&英伟达&Facebook提出基于深度神经网络的全动态推理,助力轻量级网络!...
关注公众号,发现CV技术之美
▊ 写在前面
深层神经网络是一种功能强大、应用广泛的模型,能够多级抽象提取任务相关信息。然而,这种成功通常是以计算成本、高内存带宽和长推理延迟为代价的,这使得它们无法部署在资源受限和时间敏感的场景中 ,如边缘推理和自动驾驶汽车。
虽然最近的高效深层神经网络方法通过减小模型体积,使其在现实世界中的部署更加可行,但它们并没有在每个实例的基础上充分利用输入属性,以最大限度地提高计算效率和任务精度。
特别是,大多数现有方法通常使用“一刀切”的方法,以相同的方式处理所有输入 。基于不同的图像需要不同的特征才能准确分类的事实,在本文中,作者提出了一种完全动态的模式,能够赋予深度卷积神经网络 动态 分层推理的能力 。
▊ 1. 论文和代码地址

Fully Dynamic Inference with Deep Neural Networks
论文地址:https://arxiv.org/abs/2007.15151
代码地址:未开源
▊ 2. Motivation
近几年来,深度神经网络(DNN)极大地加速了人工智能领域的发展。它们通过越来越抽象的特征表示层来表示数据的能力在许多应用领域中被证明是有效的,例如图像分类、语音识别、疾病诊断和神经机器翻译。
通过增加对强大计算资源和大量标记训练数据的访问(例如,ImageNet拥有来自1000个不同类别的128万张图像),DNN可以在各种任务上实现超过人类的性能。
增加DNN表达能力和准确性的一种策略依赖于添加更多层和卷积滤波器。通过这种方式,尽管精度有所提高,但这些笨重的模型不适用于边缘端推理,边缘端推理通常面临严格的延迟和显存限制。
为了解决现代DNN的部署限制,增加模型的紧致性的研究正在兴起 。一种方法是学习紧凑的结构 。例如,神经架构搜索(NAS),模型压缩方法,如剪枝。另一种方法侧重于通过权重量化减少计算开销 ,可以在不影响精度的情况下降低比特精度。
这些方法的一个共同特点是同一个模型处理不同的输入实例。鉴于不同的实例具有独特的视觉特征,自然会产生一个问题:是否每个实例都需要所有级别的嵌入和同一组特征映射才能准确分类?
直观地说,对于易于分类的图像,可能不需要更深的嵌入。因此,为了最大限度地提高计算效率,应仅为困难的输入实例保留与深层相关的额外计算。此外,由于卷积通道/滤波器捕获特定于类的特征,因此在推理过程中跳过不相关的通道可以避免不必要的计算。
动态推理是一种新兴的方法,它利用输入属性有选择地执行精确分类所需的显著计算子集。与永久移除神经元以提高模型效率的静态方法不同,动态方法仅根据输入实例暂时抑制计算。因此,动态方法可以最大限度地提高效率并保持模型的表达能力。然而,到目前为止,这些方法不能完全适应每个实例的计算需求。此外,这些方法通常使用强化学习来做出选择决策,这是计算密集型的。
在这项工作中,作者提出了一个基于每个实例的全动态推理框架。本文方法的核心是设计与主干网络平行的预测控制网络。具体地说,作者提出了两种新的辅助网络,层网络(Layer-Net,L-Net) 和通道网络(Channel-Net,C-Net) ,它们分别辅助动态层和通道的跳跃和缩放。
由两个控制网(称为LC Net)组成的联合拓扑,通过(1)确定在推理时执行哪些通道和块 (2)使用显著性分数缩放保留通道和块以最大化精度,以及(3)实现完全动态推理 ,从而在不中断推理流或产生延迟开销的情况下动态预测显著计算,同时提高推理效率和准确性。
▊ 3. 方法
CNN中的特征和层的重要性因输入实例而不同。这种输入依赖性可用于为计算受限的场景设计高效网络,因为原则上可以忽略不相关的特征映射,而不会牺牲准确性。在本文中,作者提出了一种分层动态的方法,以实现动态选择性执行CNN,从而实现高效推理 。
在粗粒度级别,在推断时仅保留用于图像识别的显著层,而跳过其他层。在更细的粒度级别上,仅保留与保留层相关的显著特征图/通道。这种多级方法利用了层和通道的稀疏性,在保持高分类精度的同时显著降低了计算成本
3.1 L-Net: Dynamic Layer Skipping for Depth Flexibility
并非所有输入实例都需要所有层的计算来达到正确分类的目的,在现代DNN中,通常采用重复的块相互叠加以微调特征细节。复杂的样本可能需要较深的嵌入才能准确分类,而较容易的样本可能只需要较浅的嵌入。换句话说,较浅的推断适用于较简单的样本,而较难的情况则需要较深的推断层来保持性能 。
因此,作者提出了一个深度跳跃框架(depth-wise skipping framework) ,动态选择高分类性能所需的显著层。在ResNet取得显著成功后,大多数现代DNN都采用了基于block的残差设计,解决DNN精度下降的问题。因此,作者构建的方法通常适用于目前DNN中使用的任意块。
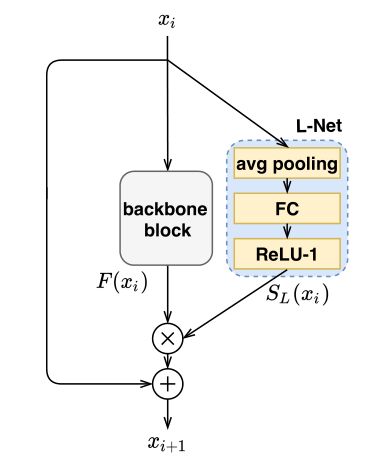
为了支持动态的块跳跃,作者在具有残差的任意块中添加一个称为L-Net 的小型网络。L-Net结构如上图所示。L-Net包含三个部分:全局平均池化层、全连接层和ReLU-1激活函数 。作者将L-Net设计为小而浅,以确保与原始主干神经网络相比,额外引入的计算和参数可以忽略不计。
第i个block的输入表示为,输出表示为,当前block的函数可以表示为:。带残差的整个block可以表示为:
其中F包含一个或多个卷积层,占网络计算的大部分。为了动态跳过不必要的块,从而降低计算成本,作者在每个块上并行添加一个L-Net。在L-Net中,首先通过一个全局平均池化层,将空间大小减少到1。接下来,输出向量被传递到一个全连接层FC,随后被一个ReLU-1激活,该激活输出一个块显著性分数,用表示,介于0和1之间。与原始block的输出相乘,如果显著性得分为零,则跳过该块。将L-Net控制块建模如下:
3.2 C-Net: Dynamic Channel Selection for Width Flexibility
DNN的大部分计算成本发生在卷积层。在这些层中,单个通道的贡献高度依赖于输入。例如,汽车的特征图对于马的分类没有用处,因为这些特征图通常在ReLU后不会被激活。
因此,可以避免这些不相关的特征映射,而不会降低分类精度。虽然L-Net通过block-level skipping提高了计算效率,但通过利用块内通道级的图像相关显著性差异 ,可以进一步降低总体计算成本。
为此,作者提出了一种L-Net的补充方法,称为C-Net ,它以输入驱动的方式动态修剪不重要的通道。
DNN的第l层卷积网络可以表示为:。C-Net的目标是预测信道显著性,并在所有卷积中仅执行重要卷积的子集。
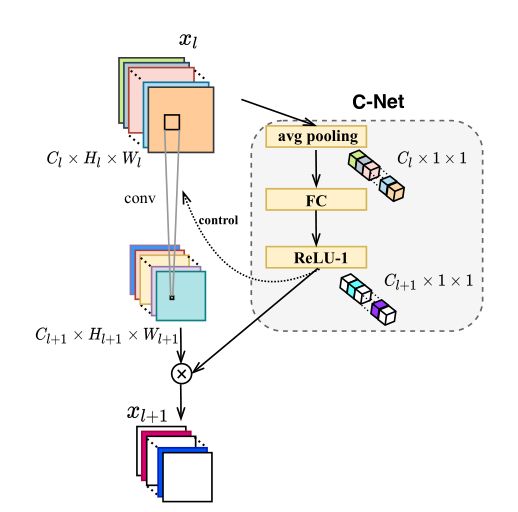
C-Net的示意图如上图所示。与L-Net一样,C-Net是一个紧凑的网络,包含一个全局平均池化层、一个全连接层和一个ReLU-1激活函数。全连接层有个unit,以匹配输出的通道数。C-Net和第l个block共享输入。
在C-Net中,全局平均池化层处理输入并生成长度为的向量,接下来,该向量经过全连接层和ReLU-1激活函数,以产生大小为的通道显著性得分,记为。具有通道选择的动态层可以表示为:
是第k个通道的显著性得分,然后乘以第k个通道的所有元素。在推理过程中,如果相关通道的显著性得分为0,则不会执行卷积。计算具有非零分数的通道,并根据其相应的分数缩放其生成的特征图。
3.3 Joint Design: LC-Net

L-Net和C-Net是正交方法,分别支持深度和通道跳转和缩放,以实现高效的动态推理。因此,作者将这两种方法结合起来,以实现完全动态推理并最小化计算成本。以ResNet为例,作者构建了两个类型的block:基本块 和瓶颈块 。
基本块由两个3x3卷积层组成,“瓶颈”块由1x1、3x3和1x1卷积层序列组成。两种类型模块的联合设计结构如上图所示。L-Net和C-Net都是与任一构建块并行添加的,并采用相同的输入。
由于L-Net和C-Net都使用全局平均池化过程,可以通过在两者之间共享一个全局平均池化层来减少计算开销。除了共享池化层之外,作者还提出了两种设计,以鼓励训练收敛,并允许动态运行,同时将延迟开销降至最低。
3.3.1 ReLU-1
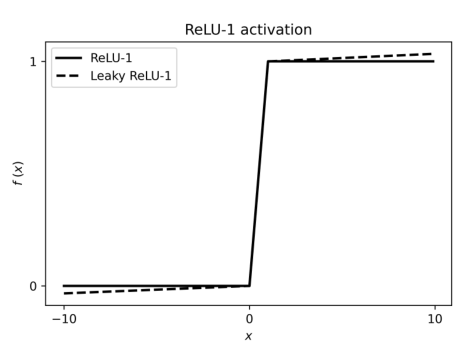
在L-Net和C-Net中,作者通过ReLU-1激活函数获得了介于0和1之间的显著性分数,如上图所示,公式如下:
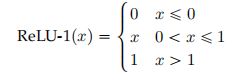
在训练过程中,作者选用了Leaky ReLU-1。与同样产生0到1之间结果的sigmoid激活函数不同,该ReLU-1激活函数在训练期间不会出现消失梯度,并且能够在推理时产生0到1之间的严格值范围。此外,与标准ReLU相比,Leaky ReLU-1不太容易发生正输入值的爆炸性的激活。由于ReLU-1函数是可微的,与基于强化学习的策略控制器不同,LC Net和主干模型可以以端到端的方式联合训练。这提高了训练效率。
3.3.2 Parallelism
作者将L-Net和C-Net设计为与构建块并行,以便控制网络和主干网络可以同时执行。与主构建块中的第一个卷积层相比,L-Net和C-Net的计算量更少。因此,这两个网络可以在第一个卷积层完成执行之前生成显著性分数。
▊ 4.实验
4.1 Main Results
4.1.1. CIFAR-10

上表结果展示了,在CIFAR-10上,本文的方法在精度和FLOPs方面优于所有现有技术。

上图展示了本文方法和其他方法的FLOPs和准确率的对比
4.1.2. ImageNet

上表展示了本文方法在ImageNet上的实验结果,可以看出,本文的方法对更大、更复杂的数据集(如ImageNet)的可扩展性。
4.2 Qualitative Analysis
4.2.1 Relationship between instance complexity and FLOPs

上图展示了高FLOPs和低FLOPs的图片。这两组之间的视觉差异很明显。一般来说,低FLOPs图像组中的对象很容易识别,但高FLOPs图像组中的图像更难分类。
4.2.2 Dynamic Selection

上图展示了ResNet-18主干网络上通道选择的可视化。每列显示了跨图像类的特定通道的百分比。图中位置(i,j)处的色块表示第i个类中激活第j个通道的图像实例的百分比。
▊ 5. 总结
在本文中,作者提出了一个新的端到端训练框架,该框架实现了基于实例的全动态推理,以自动优化DNN中的计算路径。两个浅层网络,L-Net和C-Net,分别有助于动态层和通道的跳跃和缩放。作者用CIFAR-10和ImageNet进行的实验表明,本文的选择性执行方法大大减少了FLOPs,并且比其他方法的动态推理方法具有更高的准确性。
▊ 作者简介
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。
知乎/公众号:FightingCV

END
欢迎加入「模型部署」交流群备注:部署
