爬取ICCV2019信息 并用gephi可视化作者关系网与热词联系
爬取ICCV2019信息 并使用Gephi可视化作者关系网与热词联系
- 1.爬虫数据爬取
- 2. 分词保存
-
- 对于作者的信息来说
- 对标题的信息来说
- 3. 生成词云
- 4. 生成作者关系矩阵与Gephi所需的两个CSV文件
- 5. 在Gephi调整出关系网
- 6. Gephi的一个BUG 预览空白 没有反应
- 7. 总结
1.爬虫数据爬取
目标网站ICCV2019
网页的样式如下:

爬虫还是使用万能的request库写的
最后保存在HTML文件内
import requests
def main():
# 爬取网页
baseurl = "http://openaccess.thecvf.com/ICCV2019.py"
html = requests.get(baseurl)
print(html.encoding)
f = open("ICCV.Html", "w",encoding="ISO-8859-1")
for i in html.text:
#将数据写入文件
f.write(i)
#关闭文件
f.close()
if __name__ =='__main__':
main()
获取的HTML内部内容,到这一步爬取就完成了,下一步需要对HTML中的内容进行提取

2. 分词保存
可以在上面的HTML中发现,如果想要提取作者名字与论文标题,最方便的还是直接从引用信息进行提取。这里分别给出生成EXCEL文件和TXT文件的两种方式。
其中,TXT文件我用在了词云的生成。
EXCEL文件,我用来生成Gephi了(可能绕远了)。
这里主要使用了bs库
对于作者的信息来说
- 首先用使用“ and ”(空格+and+空格)分割作者
- 对于每个作者,将“, ”(逗号+空格)替换为“ ”(空格)
- 对于每个作者,将“ ”用“_”代替,为了连接一个名字,要不然词云全部都是姓氏
对作者的提取代码如下(EXCEL):
from bs4 import BeautifulSoup
file = open("./ICCV.Html","rb")
html = file.read()
bs = BeautifulSoup(html,"html.parser")
import xlwt
# 创建一个workbook 设置编码
workbook = xlwt.Workbook(encoding = 'utf-8')
# 创建一个worksheet
author_excel = workbook.add_sheet('My Worksheet')
numx=-1
for item in bs.find_all('div', class_="bibref"):#从引用提取信息
#print(item.text)
numx+=1
item = str(item.text)
i = item.find('author')
i2 = item.find('title')
i3 = item.find('booktitle')
author = item[i+10:i2-4]#作者信息划片
author = author.split(" and ") #首先使用and分离
for ii in range(len(author)):
author[ii] = author[ii].replace(", "," ")#将逗号用空格分离
author[ii] = author[ii].replace(" ","_")#将空格用_连接
for i in range(len(author)):
author_excel.write(numx,i,author[i])
print(author)
workbook.save("author_info.xls")
提取效果(使用引用提取的名字正好是中国人的姓+名形式):
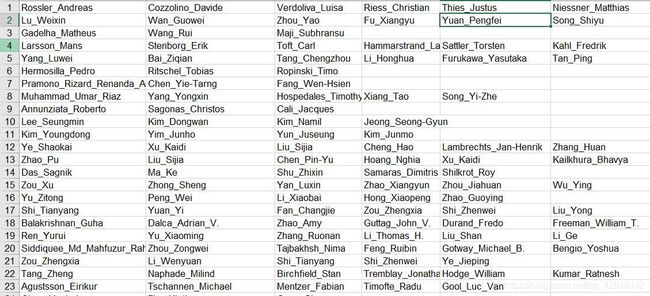
对作者的提取代码如下(TXT):
from bs4 import BeautifulSoup
fil = open("./ICCV.Html","rb")
html = fil.read()
bs = BeautifulSoup(html,"html.parser")
txt = 'author_full_name.txt'
numx=-1
with open(txt,'w') as file:
for item in bs.find_all('div', class_="bibref"):
numx+=1
item = str(item.text)
i = item.find('author')
i2 = item.find('title')
i3 = item.find('booktitle')
author = item[i+10:i2-4]#作者信息
author = author.split(" and ") #首先使用and分离
for ii in range(len(author)):
author[ii] = author[ii].replace(", ","_")#将逗号用空格分离
author[ii] = author[ii].replace(" ","_")#将逗号用空格分离
for i in range(len(author)):
print(author[i])
file.write(author[i]+',')
提取效果:

对标题的信息来说
- 使用“ ”(空格)分割标题
- 将每个标题词汇中的“,”(逗号)与“:”(冒号)替换为“”(空)
对于标题的提取代码如下(EXCEL):
from bs4 import BeautifulSoup
file = open("./ICCV.Html","rb")
html = file.read()
bs = BeautifulSoup(html,"html.parser")
import xlwt
# 创建一个workbook 设置编码
workbook = xlwt.Workbook(encoding = 'utf-8')
# 创建一个worksheet
title_excel = workbook.add_sheet('My Worksheet')
numx=-1
for item in bs.find_all('div', class_="bibref"):
#print(item.text)
numx+=1
item = str(item.text)
i = item.find('author')
i2 = item.find('title')
i3 = item.find('booktitle')
title = item[i2+9:i3-4]#标题信息
title = title.split(" ")
for i in range(len(title)):
title[i] =title[i].replace(":","")
title[i] =title[i].replace(",","")
title_excel.write(numx,i,title[i])
print(title)
workbook.save("title_info.xls")
提取效果如下:
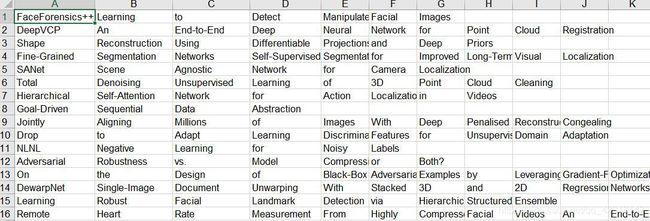
对于标题的提取代码如下(TXT):
from bs4 import BeautifulSoup
fil = open("./ICCV.Html","rb")
html = fil.read()
bs = BeautifulSoup(html,"html.parser")
txt = 'title.txt'
numx=-1
with open(txt,'w') as file:
for item in bs.find_all('div', class_="bibref"):
numx+=1
item = str(item.text)
i = item.find('author')
i2 = item.find('title')
i3 = item.find('booktitle')
title = item[i2+9:i3-4]#标题信息
title = title.split(" ")
for i in range(len(title)):
title[i] =title[i].replace(":","")
title[i] =title[i].replace(",","")
for i in range(len(title)):
print(title[i])
file.write(title[i]+',')
图片略,和上面的TXT几乎一个样
3. 生成词云
词云主要是通过统计词汇出现频率,继而根据频率的大小,设置词汇的大小,最终填充某一区域。主要使用的是wordcloud库
代码如下:
import matplotlib.pyplot as plt
from wordcloud import WordCloud
# 1.读入txt文本数据
file = open(u'此处放入第二节生成的TXT文件','r',encoding='utf-8').read()
word_cloud = WordCloud(
background_color='white',
width=800,
height=600,
max_font_size=80, )
word_cloud.generate(file)
word_cloud.to_file(r"生成的词云文件.png")
# 以图片的形式显示词云
plt.imshow(word_cloud)
# 关闭图像坐标系
plt.axis("off")
plt.show()
作者词云如下:

论文标题词云如下(没去处介词,可以去除一下):

4. 生成作者关系矩阵与Gephi所需的两个CSV文件
在Gephi中,需要两个CSV文件用来生成节点与边
- 节点CSV文件,存在三个属性,“Label”,“ID”,“Weight”
- 边CSV文件,也存在三个属性,“Source”,“Target”,“Weight”
所以,本次分析中,我们构建这两个CSV文件的原则如下:
- 每一个作者为一个节点,代表发布了论文。
- 如果在同一篇论文中,有着不同的作者,则不同的作者两两之间存在一条边, 权重为 1
- 若一个作者撰写了多篇论文,则作者节点的权重增加。
- 若在多篇论文中,有着相同的两个或以上的作者,则两个或以上作者之间的边权重增加
根据以上原则,我们可以开始构建关系矩阵与CSV文件了,我写的不算很明白,具体看代码吧。
其次,其实关系矩阵并不是很好的可视化方法,因为稍微动脑子想想,就知道这种矩阵肯定是非常稀疏的矩阵,但是就展示出来看一下吧。代码如下:
mport pandas as pd
import xlrd
import numpy as np
import csv
import matplotlib.pyplot as plt
#使用pandas读取excel文件
xls_file = xlrd.open_workbook('之前生成的EXCEL文件.xls')
name_list = []
name_count=[]
correlation =[0 for i in range(len(name_list))]
print(correlation)
correlation = correlation*(len(name_list))
print(correlation)
sheet =xls_file.sheet_by_index(0) # 读sheet,这里取第一个
rows = sheet.nrows # 获得行数
data = [[] for i in range(rows)] # 去掉表头,从第二行读数据
for i in range(1, rows+1):
data[i-1] = sheet.row_values(i-1)[0:16] #
#for var in data:
#print(var)
# print(len(data))
# print(len(data[0]))
# print(data[0])
for hang in range(len(data)):
for lie in range(len(data[0])):
name = data[hang][lie]
if(name not in name_list and name != ""):
name_list.append(name)
name_count.append(0)
if(name in name_list):
index = name_list.index(name)
name_count[index]+=1
#开始构建二维矩阵,统计交互
correlation = [([0]*(len(name_list))) for i in range(len(name_list))]
actual_length =0
for hang in range(len(data)):
actual_length =0
one_paper_author = data[hang]
for ii in range(len(one_paper_author)):
if(one_paper_author[ii]==""):
actual_length = ii
break
for num in range(actual_length-1):
for num2 in range(num+1,actual_length):
name1 = one_paper_author[num]
name2 =one_paper_author[num2]
index1 = name_list.index(name1)
index2 = name_list.index(name2)
correlation[index1][index2]+=1
correlation[index2][index1]+=1
np_co = np.array(correlation)
print(np_co.shape)
x_size,y_size = np_co.shape
plt.matshow(np_co)
plt.show()#记得把图像窗口关了才能继续运行
f = open('author_weights.csv','w',encoding='utf-8')
csv_writer = csv.writer(f)
csv_writer.writerow(["Source","Target","Weight"])
for i in range(x_size):
for j in range(i,y_size):
if(np_co[i][j] != 0):
csv_writer.writerow([name_list[i],name_list[j],np_co[i][j]])
f.close()
fff = open('author_counts.csv','w',encoding='utf-8')
csv_writer = csv.writer(fff)
csv_writer.writerow(["ID","Label","Weight"])
for i in range(len(name_list)):
csv_writer.writerow([name_list[i],name_list[i],name_count[i]])
fff.close()
下面为生成的3500多位作者的关系矩阵,估计都看不清。。。。

放大一点就好些了
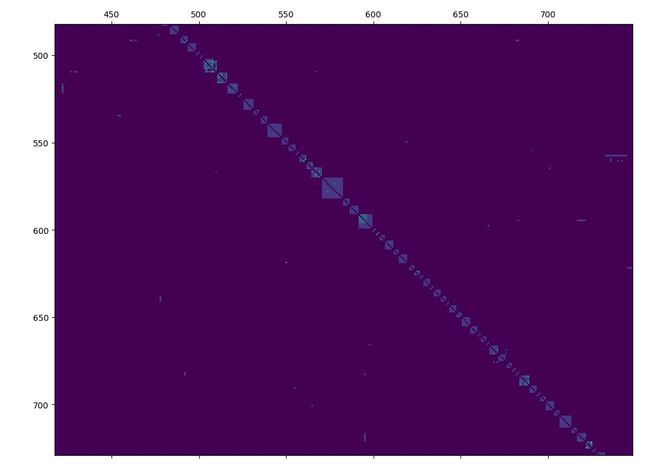
然后就可以生成CSV文件了,以作者的为例:
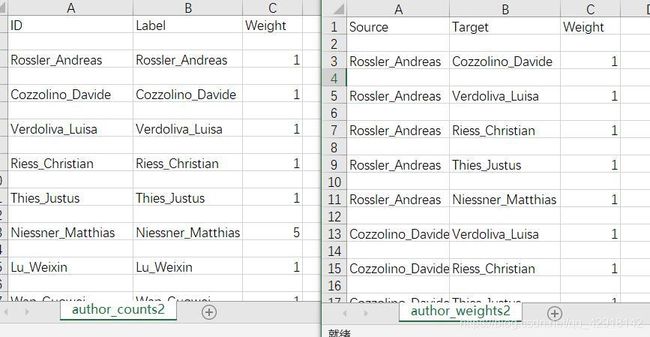
5. 在Gephi调整出关系网
Gephi主要用来分析复杂关系网,在本次中,我主要用来分析作者之间的关系与论文标题热词之间的关系。
Gephi是免费的,安装也很简单,上他的官网下载就可以。
- 第一步,选择新建工程

- 第二步,点击左上角的数据资料,依次选择节点和边,输入电子表格
输入节点的电子表格,如下:
点击下一步,点击完成,之后选择Append to existing workspace
对于边的添加也同理,但是注意,需要调整边为有向边还是无向边(本次为无向边)

可以看到,已经全部导入进去了
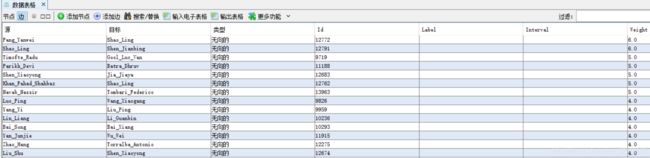
-
第三步,回到左上角,点击概览可以进行调整
开始是一坨黑糊糊
可调的有如下几个部分(括号内指可选项)(我利用过的):
-
节点颜色(固定,手动设定,按照权重自动设定,按度自动设定)
-
节点大小(固定,按照权重/度自动设定)
-
节点标签颜色(固定,手动设定,按照权重自动设定,按度自动设定)
-
节点标签大小(固定,按照权重/度自动设定)
-
边的颜色(固定,手动设定,按照权重自动设定)
-
边的标签尺寸(固定,按照权重自动设定)
-
边的标签大小(固定,按照权重自动设定)
具体的大家自己去发掘吧,***标签需要点击界面下方黑色的T生成
对于外观,可以根据喜好去设置,存在动态和静态的
简单随意生成了一下,可见还是过于稀疏,所以必须删除部分
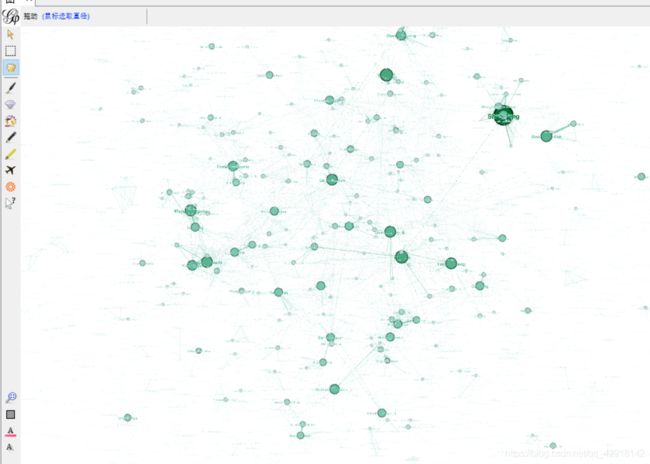
删除了部分作者,在本次,我只保留了发表论文数大于等于4的大牛
下面这张图张图是根据节点的权重调整节点的大小的,就是说,作者发表的论文越多,节点越大
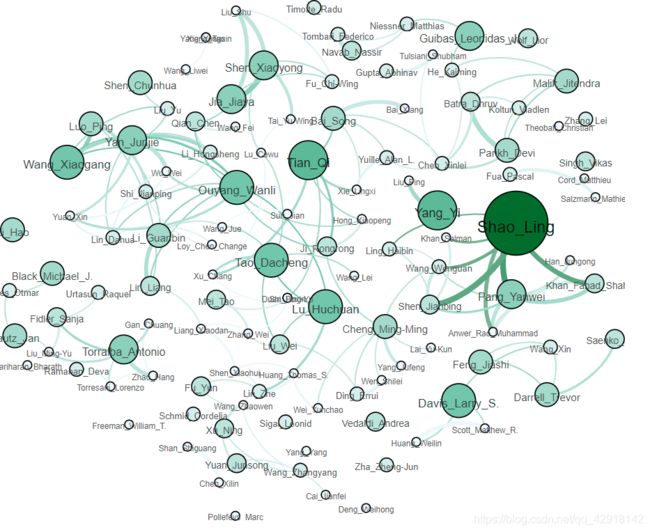
这一张是根据节点的度决定节点的大小的,节点越大,说明与这位作者合作发表的人越多
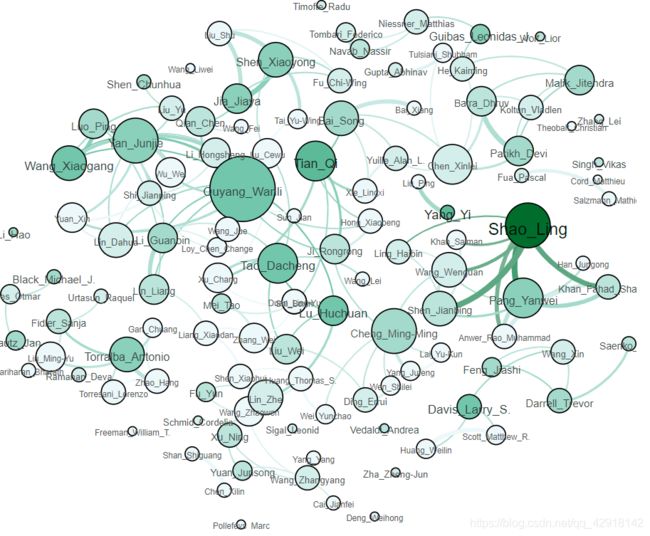
下面这张是关于论文标题的热词关系的
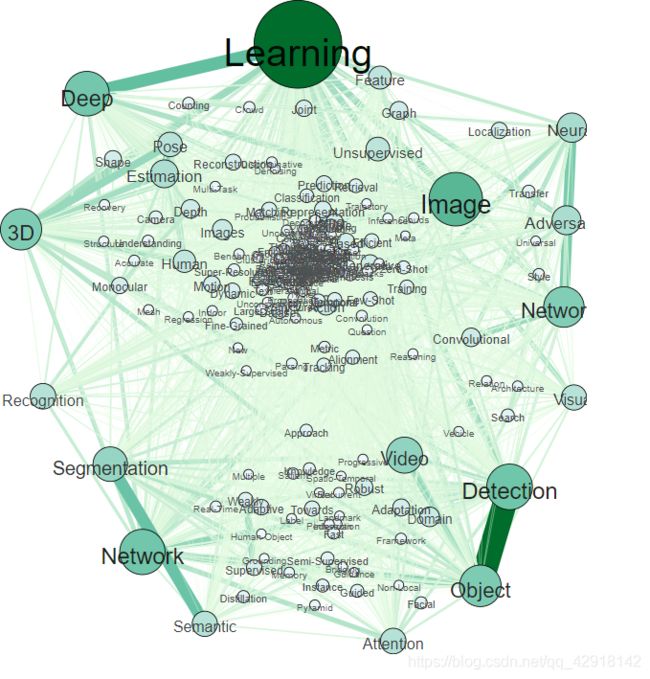
-第四步, 那么,如何导出图片呢,不能从概览里面导出,应该从预览里面导出
在概览处点击刷新,就能够产生更直观的关系网了,在左侧还可以继续调整参数,这里就不多讲了。点击左下角的部分,就可以进行矢量图导出。
6. Gephi的一个BUG 预览空白 没有反应
可能存在点击预览中的刷新没有反应的情况,这时候参考下面一片博客的做法就可以了
至少我的可以。。。
Gephi绘图时,预览不显示图形的解决办法
7. 总结
CUG的数据可视化作业,感觉海星,具体的数据分析内容就免了,可以自己走一遍去试试
因为Gephi的BUG或我的BUG,存在几个作者的标签重叠,于是删掉了
如果有空会上传全部图像/代码到gayhub,这刚刚结课,先休息几天。
我的代码水平和CSDN写博客水平稀烂,稀烂,轻喷,轻喷。。。。