用爬虫分析上热榜涨的600粉,竟发现。。。(含代码和详解)
目录
前言
下面我就分享一下这次经历!
1、编程环境及相关库的安装
1.1、编程环境:
1.2、第三方库:
1.3库的安装方法:
1.3.1、Windows的shell命令安装
1.3.2、在编程环境内安装
2、如何通过爬虫获取粉丝数据
2.1、获取自己待爬的URI
2.1.1、到这个界面,然后右键检查
2.1.2、红色圈住的便是待爬的URL
2.1.3、记录下"请求URL"和"User-agent"在两个重要的待爬信息
2.2、采用requests获取粉丝数据
2.3粉丝数据的组成
2.3.1粉丝数据标签的解释
2.3.2重点要分析的数据
3、如何合理的分析这些数据
3.1、把各个分页的数据合并
3.2、数据预处理,数据信息查看
3.3、数据的清洗和预处理等步骤
3.4、数据提取和筛选
3.5数据处理
3.6数据存储
4、分析粉丝数据得到的结论
前言
最近参加了新星计划,在各位老哥们的帮助下成功上了一次热榜。一夜之间涨了600多的粉。但是这些粉丝全部都是通过用户推荐界面加我的。我就特别好奇我现有粉丝的用户画像(数据分析名词),于是就打算通过python爬一下我这600多粉丝的码龄和用户名以及是不是VIP这三项信息。最后竟然发现了。。。好奇就好好学一下吧。下图是博主近7天内的粉丝数据。关注一下我吧,拜托了,看在我这次这么有诚意的份上。。
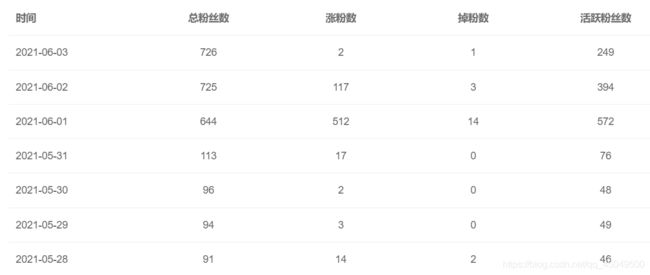 博主近七天内的粉丝数据
博主近七天内的粉丝数据
下面我就分享一下这次经历!

1、编程环境及相关库的安装
1.1、编程环境:
1.2、第三方库:
(1)requests:爬虫爬数据需要用到的库,其他库也可以实现,如Urllib3、urllib等等
(2)numpy:爬虫得到的数据是一个元组,使用numpy来处理数据比较方便
(3)matplotlib:数据可视化需要用到的库
(4)os:读取和保存过程中产生的数据需要用到的库
(5)pandas: Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
1.3库的安装方法:
我个人推荐第二种方法
1.3.1、Windows的shell命令安装
(1)打开命令窗口
(2)输入该命令,并按下enter ,pip install -i https://pypi.tuna.tsinghua.edu.cn/simple patsy[注:simple后面加需要安装的库]
1.3.2、在编程环境内安装
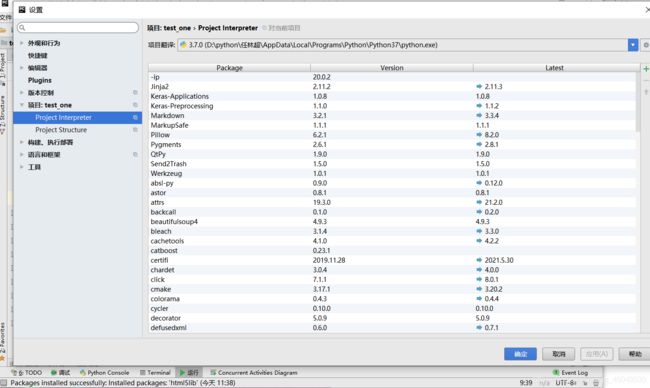
(1)文件--》设置--》项目--》Project Interpreter,如下图所示:
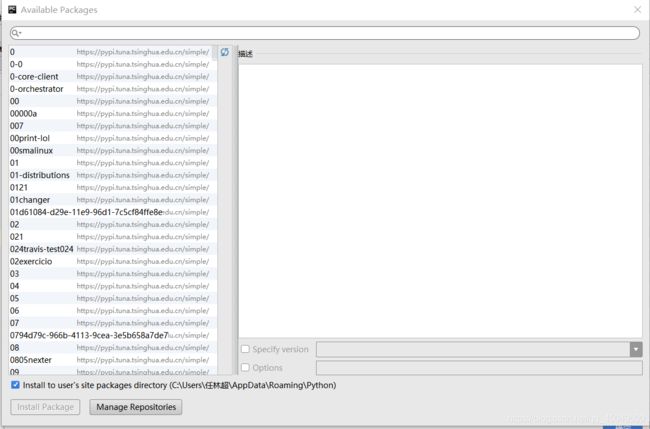
(2)点击+号,跳出下面这个窗口,在搜索栏直接搜索就行了,如果出现”Error updating package list: Status: 404“的错误提示,看第四步,如果没有错误看第三步。
(3)以requests库为例子,搜索可得requests的信息,然后直接点击Install Package进行下载安装即可。
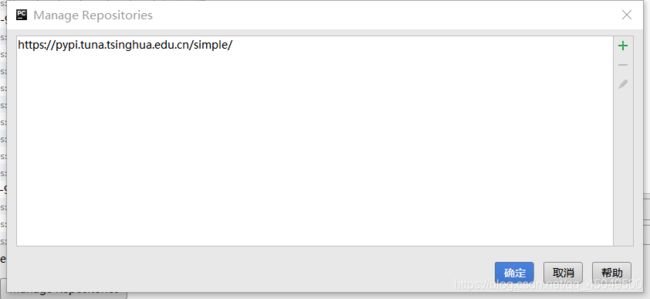
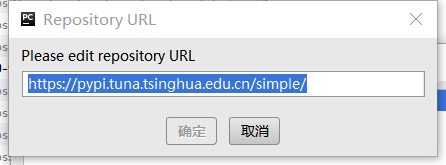
(4)点击第二步图里面的Manage Repositories按钮,出现如下界面,点击加号输入https://pypi.tuna.tsinghua.edu.cn/simple/,然后点击确认即可,之后在按照第三步安装所需的库。

2、如何通过爬虫获取粉丝数据
2.1、获取自己待爬的URI
2.1.1、到这个界面,然后右键检查
2.1.2、红色圈住的便是待爬的URL
2.1.3、记录下"请求URL"和"User-agent"在两个重要的待爬信息
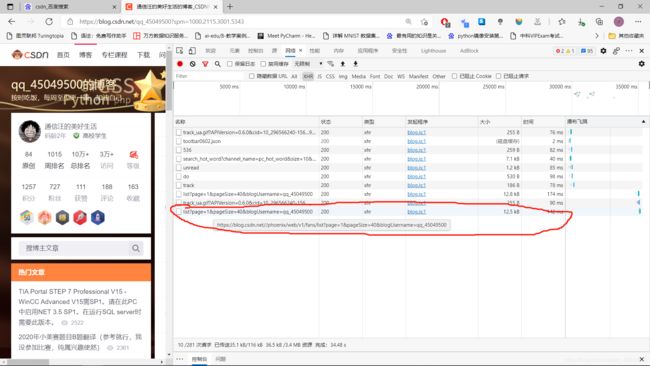
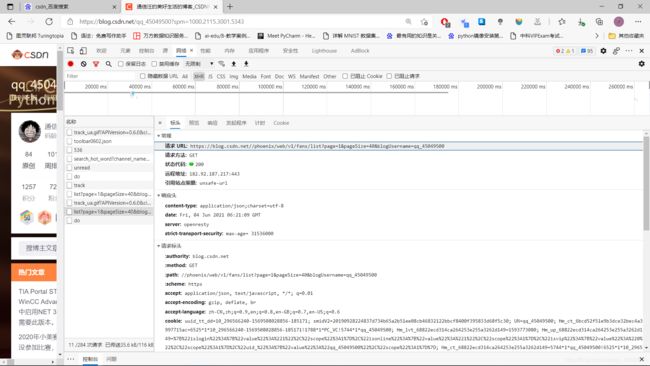

我们上面得到的待爬URL为:https://blog.csdn.net//phoenix/web/v1/fans/list?page=1&pageSize=40&blogUsername=qq_45049500,注意这只是我粉丝数据的第一页,不是索引的粉丝数据,比如粉丝数据一共有500页,那么待爬的URL便有500个。这里放一下爬虫的流程有兴趣的可以看一下。
2.2、采用requests获取粉丝数据
这是一个简单的爬虫代码,获取了10页粉丝数据,我下面分析一下粉丝数据的组成。
import requests url=["https://blog.csdn.net//phoenix/web/v1/fans/list?page=1&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=2&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=3&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=4&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=5&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=6&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=7&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=8&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=9&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=10&pageSize=40&blogUsername=qq_45049500", ] headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.37' } for i in range(0,10): response=requests.get(url[i],headers=headers) #print(response.content) print(response.text)2.3粉丝数据的组成
{"code": 200, "message": "success", "data": {"total": 727, "list": [ {"username": "daoyin1", "nickname": "daoyin1", "userAvatar": "https://profile.csdnimg.cn/A/8/2/3_daoyin1", "loginUserNameIsFollow": false, "blogUrl": "https://blog.csdn.net/daoyin1", "years": "0", "vip": false, "vipIcon": "", "companyExpert": false, "companyExpertIcon": "", "expert": false, "expertIcon": ""}, {"username": "m0_50546016", "nickname": "lucifer\xe4\xb8\x89\xe6\x80\x9d\xe5\x90\x8e\xe8\xa1\x8c", "userAvatar": "https://profile.csdnimg.cn/4/D/6/3_m0_50546016", "loginUserNameIsFollow": false, "blogUrl": "https://blog.csdn.net/m0_50546016", "years": "1", "vip": false, "vipIcon": "", "companyExpert": false, "companyExpertIcon": "", "expert": false, "expertIcon": ""}, {"username": "qq_27489007", "nickname": "\xe8\x8a\x9d\xe9\xba\xbb\xe7\xb2\x92\xe5\x84\xbf", "userAvatar": "https://profile.csdnimg.cn/F/3/1/3_qq_27489007", "loginUserNameIsFollow": false, "blogUrl": "https://blog.csdn.net/qq_27489007", "years": "6", "vip": false, "vipIcon": "", "companyExpert": false, "companyExpertIcon": "", "expert": false, "expertIcon": ""}]}}2.3.1粉丝数据标签的解释
一共12个类别:
username用户名 nickname用户昵称 userAvatar用户头像 loginUserNameIsFollow不清楚,感觉没啥用 blogUrl该粉丝的博客网址 years用户年限,小于1年为零 vip是不是VIP vipIconVIP图标 companyExpert是不是企业专家 companyExpertIcon企业专家图标 expert是不是专家 expertIcon专家图标 2.3.2重点要分析的数据
上面红颜色的那几个标签
3、如何合理的分析这些数据
我写了很多数据处理的库函数现象就不都展示出来了,不然太多了,只放个可视化的吧
3.1、把各个分页的数据合并
使用requesys爬虫获取数据并把数据然后使用pandas和join把各个分页的数据合并到一起,即"XXX.csv"类型的文件方便我们处理.csdn粉丝数据一个网页里面有40个粉丝数据,我目前一共726个粉,所以待爬的URL一共有不满20页,按照20页来计算了。
分页数据的合并我使用了pandas自带的concat()函数,我这里就不在科普了。
具体如下:df1=pd.concat([df1,df],ignore_index="ture")
import requests import numpy as np import pandas as pd import json df1=[]; #待爬的粉丝界面URL url=["https://blog.csdn.net//phoenix/web/v1/fans/list?page=1&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=2&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=3&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=4&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=5&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=6&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=7&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=8&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=9&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=10&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=11&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=12&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=13&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=14&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=15&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=16&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=17&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=18&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=19&pageSize=40&blogUsername=qq_45049500", "https://blog.csdn.net//phoenix/web/v1/fans/list?page=20&pageSize=40&blogUsername=qq_45049500" ] #待爬界面的User-Agent headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.37' } for i in range(0,19): response=requests.get(url[i],headers=headers) content = json.loads(response.text) #print(content) stp1=content.get("data") stp2=stp1.get("list") df=pd.DataFrame(stp2) if i<1: df1=df else: df1=pd.concat([df1,df],ignore_index="ture") print(df1)3.2、数据预处理,数据信息查看
目的:了解数据的概况,例如整个数据表的大小、所占空间、数据格式、是否有空值和重复项,为后面的清洗和预处理做准备。上面的df1里面已经包含了所有我们所需的数据,接下来就开始具体处理数据了。
df1.info()#整体信息 df1.shape#维度 df1.columns() #列名 df1.dtypes#数据类型 df1.isnull#查看空值 df1.vaules#查看数据表值 df1.head(5)#查看5行数据 df1.tail(5)#查看后五行数据3.3、数据的清洗和预处理等步骤
对清洗完的数据进行预处理整理以便后期的统计和分析工作。
df1.dropna(how="any",inplace=True)#空值处理 df1.fillna(0)#空值处理填充 df1["Name"]=df["name"].map(str.strip)#空格处理 df1["Embarked"].str.lower()#大小写转换 df1["years"].astype('int')#更改数据类型 df1.rename(columns={'years':'码龄'})#更改列名称
3.4、数据提取和筛选
数据提取:使用loc和iloc配合相关函数。
筛选:使用与,或,非三个条件配合大于,小于和等于对数据进行筛选
df.loc[:2,'years']#按标签提取数据 df1.iloc[:2,3]#按位置提取 df1["years"].isin(["vip"])#配合isin函数使用,按条件对数据进行提取 df1.loc[(df1['years']>2)|(df1_inner["vip"]==ture)].head()#筛选数据
3.5数据处理
3.6数据存储
df1.to_excel('tantic.xlsx,sheet_name="a')#存到Excel里面 df1.to_csv("my_fans.csv")#存到csv
4、分析粉丝数据得到的结论
我的粉丝大多都是属于新用户,并且码零不超过两年,基本应该属于小白那种,但是我们都要有一个从零到一的一个过程,希望关注我可以给你带来一定的帮助。终于等到你了,一起加油,未来属于我们这些努力提升自己的人!!!还是关注我的时候自动回复的那句话:终于等到你了,一起加油,未来属于我们这些努力提升自己的人!!!我不会让你白关注我的,一起加油。