tensorboard ckpt pb 模型的输出节点_Tensorboard 详解(上篇)

作者:花间提壶华小厨
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习、深度学习的知识!也可以搜索号:磐创AI,关注我们的文章。
1. Tensorboard简介
对大部分人而言,深度神经网络就像一个黑盒子,其内部的组织、结构、以及其训练过程很难理清楚,这给深度神经网络原理的理解和工程化带来了很大的挑战。为了解决这个问题,tensorboard应运而生。Tensorboard是tensorflow内置的一个可视化工具,它通过将tensorflow程序输出的日志文件的信息可视化使得tensorflow程序的理解、调试和优化更加简单高效。Tensorboard的可视化依赖于tensorflow程序运行输出的日志文件,因而tensorboard和tensorflow程序在不同的进程中运行。
那如何启动tensorboard呢?下面代码定义了一个简单的用于实现向量加法的计算图。
1. import tensorflow as tf
2. # 定义一个计算图,实现两个向量的减法操作
3. # 定义两个输入,a为常量,b为变量
4. a=tf.constant([10.0, 20.0, 40.0], name='a')
5. b=tf.Variable(tf.random_uniform([3]), name='b')
6. output=tf.add_n([a,b], name='add')
7. # 生成一个具有写权限的日志文件操作对象,将当前命名空间的计算图写进日志中
8. writer=tf.summary.FileWriter('/path/to/logs', tf.get_default_graph())
9. writer.close()在上面程序的8、9行中,创建一个writer,将tensorboard summary写入文件夹/path/to/logs,然后运行上面的程序,在程序定义的日志文件夹/path/to/logs目录下,生成了一个新的日志文件events.out.tfevents.1524711020.bdi-172,如下图1所示。当然,这里的日志文件夹也可以由读者自行指定,但是要确保文件夹存在。如果使用的tensorboard版本比较低,那么直接运行上面的代码可能会报错,此时,可以尝试将第8行代码改为file_writer=tf.train.SummaryWriter('/path/to/logs', sess.graph)
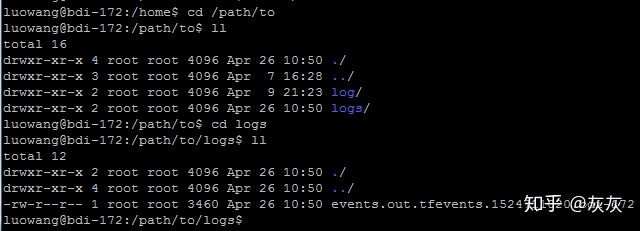
接着运行如图2所示命令tensorboard –logdir /path/to/logs来启动服务。
注意,当系统报错,找不到tensorboard命令时,则需要使用绝对路径调用tensorboard,例如下面的命令形式:
python tensorflow/tensorboard/tensorboard.py --logdir=path/to/log-directory 
启动tensorboard服务后,在本地浏览器中输入http://188.88.88.88:6006,会看到如上图3所示的界面。注意,由于本节程序是在Linux服务器上运行的,所以需要输入该服务器完整的IP地址(http://188.88.88.88:6006指本实验所使用的服务器IP地址,实际操作时需要修改成实际使用的服务器IP),若tensorflow程序是在本机上运行,则需将上述IP地址http://188.88.88.88:6006替换成localhost。
根据上述内容描述,tensorboard的启动过程可以概括为以下几步:
1.创建writer,写日志文件
writer=tf.summary.FileWriter('/path/to/logs', tf.get_default_graph())
2.保存日志文件
writer.close()
3.运行可视化命令,启动服务
tensorboard –logdir /path/to/logs
4.打开可视化界面
通过浏览器打开服务器访问端口http://xxx.xxx.xxx.xxx:6006注意:tensorboard兼容Google浏览器或Firefox浏览器,对其他浏览器的兼容性较差,可能会提示bug或出现其他性能上的问题。
在这里使用tensorboard1.4.1,较以往版本有很多不同。首先从界面上,此版本的tensorboard导航栏中只显示有内容的栏目,如GRAPHS,其他没有相关数据的子栏目都隐藏在INACTIVE栏目中,点击这些子栏目则会显示一条如图4所示的提示信息,指示使用者如何序列化相关数据。除此之外,在栏目的数量上也有增加,新增了DISTRIBUTIONS、PROJECTOR、TEXT、PR CURVES、PROFILE五个栏目。
Tensorboard的可视化功能很丰富。SCALARS栏目展示各标量在训练过程中的变化趋势,如accuracy、cross entropy、learning_rate、网络各层的bias和weights等标量。如果输入数据中存在图片、视频,那么在IMAGES栏目和AUDIO栏目下可以看到对应格式的输入数据。在GRAPHS栏目中可以看到整个模型计算图结构。在HISTOGRAM栏目中可以看到各变量(如:activations、gradients,weights 等变量)随着训练轮数的数值分布,横轴上越靠前就是越新的轮数的结果。DISTRIBUTIONS和HISTOGRAM是两种不同形式的直方图,通过这些直方图可以看到数据整体的状况。PROJECTOR栏目中默认使用PCA分析方法,将高维数据投影到3D空间,从而显示数据之间的关系。
2. Tensorflow数据流图
从tensorboard中我们可以获取更多,远远不止图3所展示的。这一小节将从计算图结构和结点信息两方面详细介绍如何理解tensorboard中的计算图,以及从计算图中我们能获取哪些信息。
2.1 Tensorflow的计算图结构
如上图3展示的是一个简单的计算图,图结构中主要包含了以下几种元素:

除此之外,还有Unconnected series、Connected series、Summary等元素。这些元素构成的计算图能够让我们对输入数据的流向,各个操作之间的关系等有一个清晰的认识。

如上图5,是一个简单的两层全连接神经网络的计算图。仅仅从图5,我们很难快速了解该神经网络的主体数据流关系,因为太多的细节信息堆积在了一起。这还只是一个两层的简单神经网络,如果是多层的深度神经网络,其标量的声明,常量、变量的初始化都会产生新的计算结点,这么多的结点在一个页面上,那其对应的计算图的复杂性,排列的混乱性难以想象。所以我们需要对计算图进行整理,避免主要的计算节点淹没在大量的信息量较小的节点中,让我们能够更好的快速抓住主要信息。通过定义子命名空间,可以达到整理节点、让可视化效果更加清晰的目的。

如上图6,就是通过定义子命名空间整理结点后的效果。该计算图只显示了最顶层的各命名空间之间的数据流关系,其细节信息被隐藏起来了,这样便于把握主要信息。
图7为加入子命名空间后的部分代码截图。代码中,将输入数据都放在了input命名空间中,还使用了perdition、moving_averages、loss、train等命名空间去整理对应的操作过程。

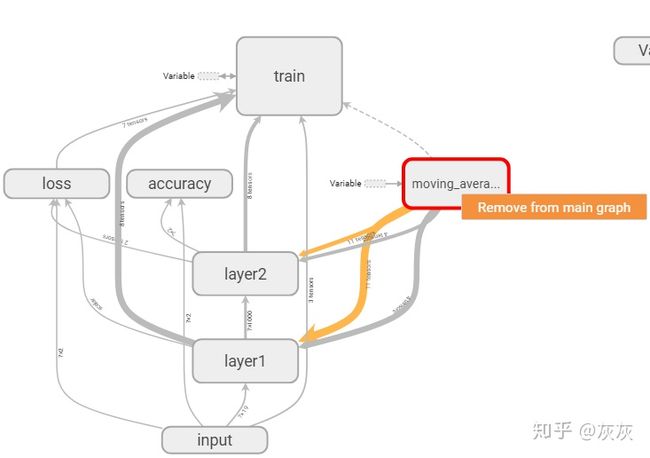
除此之外,我们还可以通过手动将不重要的节点从主图中移除来简化计算图,如上图8,右键点击想要移除的节点,会出现“Remove from main graph”按钮,点击该按钮,就可以移除对应节点了。
2.2 结点的信息
Tensorboard除了可以展示整体的计算图结构之外,还可以展示很多细节信息,如结点的基本信息、运行时间、运行时消耗的内存、各结点的运行设备(GPU或者CPU)等。
2.2.1 基本信息
前面的部分介绍了如何将计算图的细节信息隐藏起来,但是有的时候,我们需要查看部分重要命名空间下的节点信息,那这些细节信息如何查看呢?对于节点信息,双击图8中的任意一个命名空间,就会展开对应命名空间的细节图(再次双击就可以收起细节图)。

上图9是input命名空间的展开图,展开图中包含了两个操作节点(x_input和y_input)。除了了解具体包含的操作节点以及其他元素外,我们还可以获取粒度更小的信息。
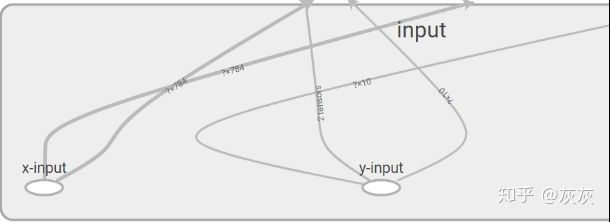
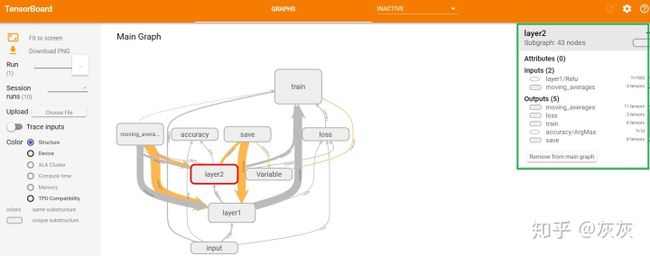

上图10所示为图9中input命名空间展开图的放大图。观察图10,我们可以了解到输入数据x、y的维度,图中x的向量维度为784维,y为10维,?表示样本数量。本节演示中使用的是mnist数据集,mnist数据集是一个针对图片的10分类任务,输入向量维度是784,这说明可以通过计算图上这些信息,来校验输入数据是否正确。通过左键单击命名空间或者操作节点,屏幕的右上角会显示对应的具体信息。
如上图11中,右上角绿色框标注的部分为命名空间layer2的具体信息。如上图12中,右上角绿色框标注的部分为节点x_input的具体信息。
2.2.2 其他信息
除了节点的基本信息之外,tensorboard还可以展示每个节点运行时消耗的时间、空间、运行的机器(GPU或者CPU)等信息。本小节将详细讲解如何使用tensorboard展示这些信息。这些信息有助于快速获取时间、空间复杂度较大的节点,从而指导后面的程序优化。将2.1节中图7所展示的代码的session部分改成如下所示的程序,就可以将程序运行过程中不同迭代轮数中tensorflow各节点消耗的时间和空间等信息写入日志文件中,然后通过读取日志文件将这些信息用tensorboard展示出来。
1 #创建writer对象
2 writer=tf.summary.FileWriter("/path/to/metadata_logs",
3 tf.get_default_graph())
4 with tf.Session() as sess:
5 tf.global_variables_initializer().run()
6 for i in range(TRAINING_STEPS):
7 x_batch, y_batch=mnist.train.next_batch(BATCH_SIZE)
8 if i%1000==0:
9 #这里通过trace_level参数配置运行时需要记录的信息,
10 # tf.RunOptions.FULL_TRACE代表所有的信息
11 run_options = tf.RunOptions(
12 trace_level=tf.RunOptions.FULL_TRACE)
13 #运行时记录运行信息的proto,pb是用来序列化数据的
14 run_metadata = tf.RunMetadata()
15 #将配置信息和记录运行信息的proto传入运行的过程,从而记录运行时每一个节点的时间、空间开销信息
16 _, loss_value, step = sess.run(
17 [train_op, loss, global_step],
18 feed_dict={x: x_batch, y_: y_batch},
19 options=run_options, run_metadata=run_metadata)
20 #将节点在运行时的信息写入日志文件
21 writer.add_run_metadata(run_metadata, 'step %03d' % i)
22 else:
23 _, loss_value, step = sess.run(
24 [train_op, loss, global_step],
25 feed_dict={x: xs, y_: ys})
26 writer.close()
运行上面的程序,生成日志文件存储在/path/to/metadata_logs/目录下,启动tensorboard服务,读取日志文件信息,将每一个节点在不同迭代轮数消耗的时间、空间等信息展示出来。

如上图13所示,在浏览器中打开可视化界面,进入GRAPHS子栏目,点击Session runs选框,会出现一个下拉菜单,这个菜单中展示了所有日志文件中记录的运行数据所对应的迭代轮数。任意选择一个迭代轮数,页面右边的区域会显示对应的运行数据。
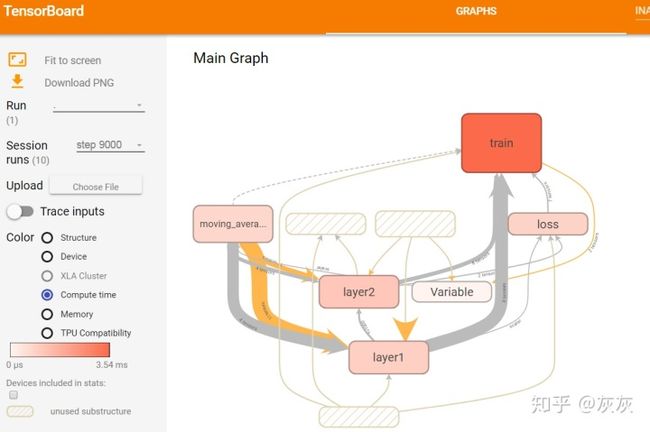

如上图14所示,选择了第9000轮的运行数据,然后选择Color栏目下的Compute time选项,GRAPHS栏目下就会显示tensorflow程序每个计算节点的运行时间。图中使用颜色的深浅来表示运行时间的长短,颜色深浅对应的具体运行时间可以从页面左侧的颜色条看出。由图14可知,train命名空间运行时所消耗的时间最长,Variable命名空间所消耗的时间比较短,无色表示不消耗时间。
如上图15展示了tensorflow各个节点所占用的空间大小。与衡量运行时所消耗的时间方法类似,使用颜色的深浅来标识所占用内存的大小。颜色条上的数字说明,占用的最大空间为677MB,最小空间为0B。train命名空间占用的存储空间最大。
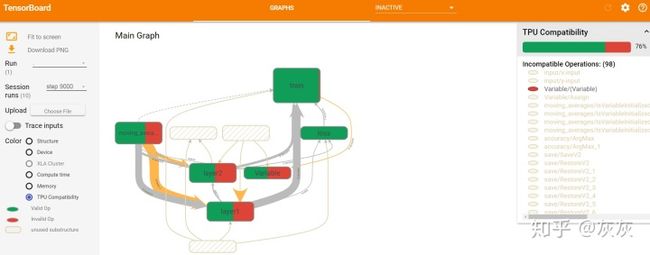
除了时间和空间指标,tensorboard还可以展示各节点的运行设备(GPU还是CPU)、XLA Cluster、TPU Compatibility等,这些全部都在Color栏目下作为选项供选择。这些指标都是将节点染色,通过不同颜色以及颜色深浅来标识结果的。如下图16,是TPU Compatibility展示图。
下一篇将讲述“Tensorflow监控指标可视化”与Tensorboard总述。敬请期待。
最后,对深度学习感兴趣,热爱Tensorflow的小伙伴,欢迎关注我们的网站!http://www.tensorflownews.com。我们的号:磐创AI。