NLP自然语言处理学习(一)——LSTM、GRU以及文本情感分类
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
-
- 1.循环神经网络(RNN)
- 1.1 文本的tokenization
-
- 1.1.1 中英文分词的方法
- 1.1.2 N-garm表示方法
- 1.1.3 向量化
- 1.2 文本情感分类
-
- 1.2.1 数据设置
- 1.2.2 文本序列化
- 1.3 循环神经网络
- 1.3.1 RNN的不同结构
- 1.3.2 LSTM(Long Short-Term Memory)
- 1.3.3 GRU(Gated Recurrent Unit)
- 1.3.4 双向LSTM
- 1.3.5 pytorch中的LSTM和GRU Api
前言
本文主要是记录了学习NLP相关的笔记,如有错误,还请不吝赐教。
1.循环神经网络(RNN)
1.1 文本的tokenization
tokenization 就是通常所说的分词,分出的每一词语我们把它称为token。
常见的分词工具:
1.jieba分词
2.清华大学的分词工具 THULAC
1.1.1 中英文分词的方法
1.把句子转化为词语
2.把句子转化为单个字
1.1.2 N-garm表示方法
前面我们说,句子可以由单个词来表示,但是由的时候,我们可以用2个、3个或者多个词来表示。
N-garm 一组一组的词,其中N表示能够被一起使用的词的数量。
例如:当N=2时
import jieba
test="我爱深度学习,我喜欢跑算法和代码!"
cuts=jieba.lcut(test)
result=[]
for i in range(len(cuts)-1):
result.append([cuts[i],cuts[i+1]])
print(result)
在传统机器学习中N-gram效果比单个单词更好,但是在RNN中自带N-gram效果。
1.1.3 向量化
因为文本不能直接被模型计算,所以需要将其转化为向量。
把文本转化为向量由以下两种方法:
1.one-hot 编码:使用稀疏的向量表示文本,占用空间多。
2.Word embedding:
token—>num—>vector
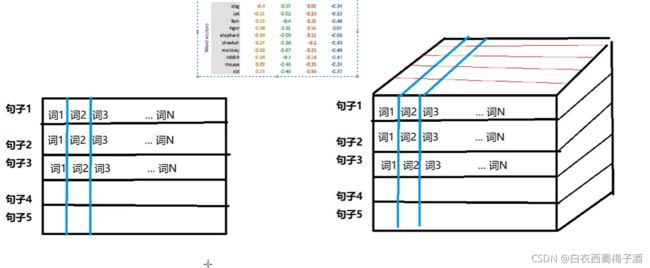
torch 中的Embedding API
torch.nn.Embedding(num_embeddings,embedding_dim);
num_embeddings :词典数量
embedding_dim :词典维度
embedding=torch.nn.Embedding(vocable_size,300)
input_embeded=embedding(input_x)
使用Embedding后,数据会增加一个维度,即Embedding_dim
1.2 文本情感分类
这里考虑使用IMDB数据来进行一个文本情感分析实践。
1.2.1 数据设置
import torch
from torch.utils.data import DataLoader,Dataset
import os
import re
data_base_path=r"..\data\aclImdb"
def tokenize(text):
filters=['!','"','#','$','%','&','\(','\)','\*','\+',',','-','\.','/',':',
';','<','>','=','\?','@','\[','\\','\]','^','_','~','\{','\}','\|',
'~','\t','\n','\x97','\x96','“','\0x93']
text=re.sub("<.*?>"," ",text,flags=re.S)
## 将 text 中的特殊符号改为空格 包括 filters中的和 类似
text=re.sub("|".join(filters)," ",text,flags=re.S)
return [i.strip().lower() for i in text.split()]
class ImdbDataset(Dataset):
def __init__(self,mode:str,use_binary:bool=False):
super(ImdbDataset,self).__init__()
self.use_binary=use_binary
if mode=='train':
text_path=[os.path.join(data_base_path,i) for i in ['train/neg',"train/pos"]]
else:
text_path=[os.path.join(data_base_path,i) for i in ["test/neg","test/pos"]]
self.total_file_path_list=[]
## 获取所有文件路径
for i in text_path:
self.total_file_path_list.extend([os.path.join(i,j) for j in os.listdir(i) if j.endswith(".txt")])
def __getitem__(self, idx):
cur_path=self.total_file_path_list[idx]
cur_filename=os.path.basename(cur_path)
label = int(cur_filename.split("_")[-1].split(".")[0])
text = tokenize(open(cur_path,encoding='utf-8').read().strip())
if self.use_binary:
label=1 if label>=5 else 0
return label,text
def __len__(self):
return len(self.total_file_path_list)
def collate_fn(batch):
# batch是一个列表,其中是一个一个的元组,每个元组是dataset中_getitem__的结果
batch = list(zip(*batch))
labels = torch.tensor(batch[0], dtype=torch.int32)
texts = batch[1]
del batch
return labels, texts
dataset=ImdbDataset(mode="train",use_binary=True)
dataloader=DataLoader(dataset=dataset,batch_size=2,shuffle=True,collate_fn=collate_fn)
if __name__=='__main__':
print(dataloader)
for idx ,datas in enumerate(dataloader):
print(datas)
1.2.2 文本序列化
文本序列化所需要考虑的问题:
1.对于新出现的词语在词典中没有出现怎么办?(特殊字符代理)
2.不同句子的长度不相同,每个batch的句子如何构造成相同的长度(可以对短句子进行填充,填充特殊字符)
3.对于高频词和低频次有时需要进行过滤
from typing import List
class Word2Sequence:
UNK_TAG="UNK"
PAD_TAG="PAG"
UNK=0
PAD=1
def __init__(self):
self.dict={
self.UNK_TAG:self.UNK,
self.PAD_TAG:self.PAD
}
self.count={
}
def fit(self,sentence):
for word in sentence:
self.count[word]=self.count.get(word,0)+1
def build_vocab(self,min:int=None,max:int=None,max_features:int=None):
"""
生成词典
:param min: 最小出现次数
:param max: 最大出现次数
:param max_features: 一共保留多少词语
:return:
"""
if min is not None:
self.count={
word:value for word,value in self.count if value>min}
if max is not None:
self.count={
word:value for word,value in self.count if value<max}
if max_features is not None:
## 由小到大排序
temp=sorted(self.count.items(),key=lambda x:x[-1],reverse=True)[:max_features]
self.count=dict(temp)
## 构造字典
for word in self.count:
self.dict[word]=len(self.dict)
## 得到反转的字典
self.inverse_dict=dict(zip(self.dict.values(),self.dict.keys()))
def transform(self,sentence:List[str],max_len:int=None):
cur_len=len(sentence)
if max_len is not None:
if max_len>cur_len:
sentence=sentence+[self.PAD_TAG]*(max_len-cur_len)
if max_len<cur_len:
sentence=sentence[:max_len]
return [self.dict.get(word,self.UNK) for word in sentence]
def inverse_transform(self,indices:List[int]):
return [self.inverse_dict.get(idx) for idx in indices]
def __len__(self):
return len(self.dict)
if __name__=="__main__":
ws=Word2Sequence()
ws.fit(["我","是","谁","啊"])
ws.fit(["我","爱","周陈静"])
ws.build_vocab()
ret=ws.transform(["我","爱","陈瑶瑶"])
print(ret)
pytorch 中的embedding层是服从0-1正态分布的随机取值,并不具备word2vec等的特性,但是可以通过神经网络来进行训练。
1.3 循环神经网络
为什么有了神经网络还需要由循环神经网络?
在普通的神经网络中,信息的传递是单向的,这种限制虽然使得网络变得更容易学习,但在一定程度上也减弱了神经网络模型的能力。特别是在很多现实任务中,网络的输出不仅和当前时刻的输入相关,也和其过去一段时间的输出相关。
此外,普通网络难以处理时序数据,比如视频、语音、文本等,时序数据的长度一般是不固定的,而前馈神经网络要求输入和输出的维度都是固定的,不能任意改变,因此,当处理这一类和时序相关的问题时,就需要一种能力更强的模型。
循环神经网络(Recurrent Neural Network,RNN)是一类具有短期记忆能力的神经网络。在循环神经网络中,神经元不但可以接受其他神经元的信息,也可以接受自身的信息,形成具有环路的网络结构。换句话说:神经元的输出可以在下一个时间步直接作用到自身(作为输入)

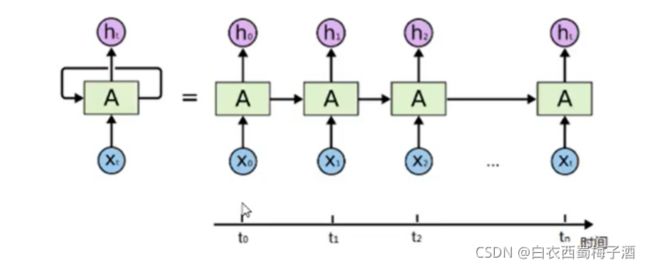

1.3.1 RNN的不同结构

- one to one: 图像分类
- one to many:图像描述
- many to one:文本分类,情感分析
- many to many(异步):文本翻译
- many to many:根据视频的每一帧来对视频进行分类
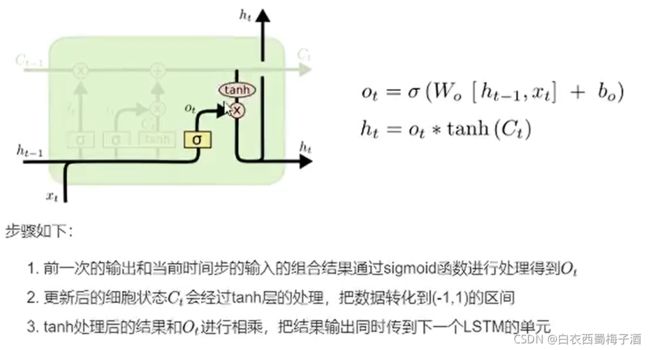
1.3.2 LSTM(Long Short-Term Memory)
主要是针对于RNN无法较好的保持长期记录的问题。

遗忘门:
通过sigmoid函数来决定哪些信息会被遗忘

输入门
tanh会创造新的信息,而输入门则决定那些信息会被更新

输出门
决定那些信息会被输出
1.3.3 GRU(Gated Recurrent Unit)
它将遗忘门和输入门组合成一个更新门,合并了单元状态和隐藏状态。

1.3.4 双向LSTM
单向的RNN,是根据前面的信息去推出后面的,但有时候只看前面的词是不够的,也需要后面的信息,此时就需要一种机制,能够让模型不仅能够从前往后的具有记忆,还需要从后往前需要记忆。此时就引出了双向LSTM

由于是双向LSTM,所以每个方向的LSTM都会有一个输出,最终的输出会有两部分,所以往往需要concat操作。
1.3.5 pytorch中的LSTM和GRU Api
torch.nn.LSTM(input_size,hidden_size,num_layers,batch_first,dropout,bidirectional)
1.input_size: 输入数据的形状即embedding_dim
2.hidden_szie: 隐藏状态的特征数
3.num_layer:即RNN中的LSTM单元层数
4.batch_first:默认为False
5.dropout:随机失活比例,当num_layer>1才能使用
6.bidirectional:是否使用双向LSTM,默认为False
import torch.nn as nn
import torch
vocab_size=100
embedding_dim=30
hidden_size=20
batch_size=10
seq_len=20
input=torch.randint(low=0,high=100,size=[batch_size,seq_len])
embedding=nn.Embedding(vocab_size,embedding_dim)
input_embedded=embedding(input)
input_embedded=torch.transpose(input_embedded,0,1)
lstm=nn.LSTM(embedding_dim,hidden_size,num_layers=2)
output,(h_t,c_t)=lstm(input_embedded)
last_output=output[-1,:,:]
print(last_output==h_t[-1,:,:])
h 倒数第一个位后向,倒数第二个为前向
output则为前向第一个和后向的最后一个在最后一个维度上的拼接。
GRU也是类似与LSTM
文本情感分类代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
from lib import ws
from dataset import *
from torch import Tensor
import numpy as np
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
self.hidden_size=128
self.embedding_dim=200
self.num_layer=2
self.dropout=0.4
self.bi_num=2
self.max_len=200
self.embedding=nn.Embedding(len(ws),200)
self.lstm=nn.LSTM(self.embedding_dim,self.hidden_size,num_layers=self.num_layer,bidirectional=True,dropout=self.dropout)
# self.lstm2=nn.LSTM(self.hidden_size,self.hidden_size)
self.dropout=nn.Dropout(0.5)
self.fc1=nn.Linear(self.hidden_size*2,64)
self.relu1=nn.ReLU(inplace=True)
self.bn1 = nn.BatchNorm1d(64)
self.fc2=nn.Linear(64,2)
def forward(self,inputs:Tensor)->Tensor:
## [batch_size,seq_len,embdding_dim]
input_embedded=self.embedding(inputs)
input_embedded=torch.transpose(input_embedded,0,1)
output,(h_t,c_t)=self.lstm(input_embedded)
output=torch.concat([h_t[-2,:,:],h_t[-1,:,:]],dim=-1)
output=self.dropout(output)
out=self.fc1(output)
out=self.relu1(out)
out = self.bn1(out)
out=self.dropout(out)
out=self.fc2(out)
return out
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model=Model()
model.to(device)
batch_size=32
optimizer=torch.optim.Adam(model.parameters(),lr=0.001)
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8])
dataset = ImdbDataset(mode="train", use_binary=True)
dataloader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, collate_fn=collate_fn,num_workers=nw)
eval_dataset = ImdbDataset(use_binary=True)
eval_dataloader=DataLoader(dataset=eval_dataset,batch_size=32,shuffle=True,collate_fn=collate_fn,num_workers=nw)
def train():
loss_func=nn.CrossEntropyLoss()
for idx,(target,input) in enumerate(dataloader):
input=torch.tensor(input,dtype=torch.int32)
optimizer.zero_grad()
output=model(input.to(device))
loss=loss_func(output,target.to(device))
loss.backward()
optimizer.step()
if idx%256==0:
print(loss.item())
torch.save(model.state_dict(),"./models/model.pth")
def eval():
acc_list=[]
loss_list=[]
acc_num=0
all_num=len(eval_dataset)
for idx,(target,input) in enumerate(eval_dataloader):
with torch.no_grad():
input = torch.tensor(input, dtype=torch.int32)
output=model(input.to(device))
cur_loss=F.cross_entropy(output,target.to(device))
loss_list.append(cur_loss.item())
pred=output.max(dim=-1)[-1]
cur_acc=pred.eq(target.to(device)).float().mean()
acc_list.append(cur_acc.item())
print("total loss,acc:",np.mean(loss_list),np.mean(acc_list))
if __name__=="__main__":
for i in range(8):
train()
eval()