
一、背景
随着大数据、云计算等技术的发展,数据隐私安全问题受到越来越多的重视,各国都在加强数据安全和隐私保护。中国在2017年实施的《中华人民共和国网络安全法》要求网络运营者不得泄露、篡改、毁坏收集的个人信息,并且在于第三方进行数据交易时需要确保合同明确约定拟交易数据的范围和数据保护义务。欧盟也在2018年实施了法案《通用数据保护条例》(General Data Protection Regulation, GDPR)。这些法规的实施要求我们在使用和交换数据的时候更加谨慎,数据源之间彼此成为独立的“数据孤岛”,而人工智能的“魔力”来源于数据,特别是在一些实际应用场景中,有效数据都是“小数据”,需要不同数据源之间协作使用。
比如构建金融领域反洗钱模型,但每家金融机构只有少量反洗钱案例;在医疗图像研究中,对于特定病例的有标注图像数据是非常少的;少样本增加了建模的难度甚至无法支撑建模。
除了这些“小数据”场景,有很多应用场景需要整合多维度的数据来刻画目标。比如金融领域的风控场景,需要综合考虑借贷人的人口属性,信用表现,多头表现,消费行为等,而几乎没有一家数据公司能同时拥有这么多维度的数据。
在车险定价领域,除了车辆本身的情况外,车辆的使用情况,行车区域的环境也是影响保期内赔付风险的重要因素,对车险定价影响至关重要,特别是新客的表现数据很少,各方数据无法有效连接,难以精准定价。
但是数据隐私安全法规出台之后,不同机构之间的数据聚合使用更加困难,这些业务场景急需一项技术来实现数据源之间的安全聚合和建模。 联邦学习(FederatedLearning)概念的初衷就是为了解决数据孤岛问题,该技术能够让数据在不出库的情况下实现建模任务。下面是维基百科中对联邦学习的定义:
Federated learning (also known as collaborative learning) is a machine learning technique that trains an algorithm across multiple decentralized edge devices or servers holding local data samples, without exchanging them. This approach stands in contrast to traditional centralized machine learning techniques where all the local datasets are uploaded to one server, as well as to more classical decentralized approaches which often assume that local data samples are identically distributed.
这段定义中有两个关键部分:
- machine learning technique:联邦学习本质也是一种机器学习技术
- holding local data samples, without exchanging them: 与将所有数据上传到一个服务器的传统机器学习以及将所有数据上传到一个集群的传统分布式机器学习相比,联邦学习的最大特点是所有数据源方将自己的数据保留在自己的本地,在建模过程中,也不会通过网络直接交换原始数据。
FATE 是微众银行推出的一款联邦学习开源框架,它实现了从数据预处理,特征筛选,建模,模型评估,模型上线整个流程了基本功能,目前也是业界最认可的联邦学习工程化实践,目前在金融信贷管理、零售、智慧城市、智慧安防等应用场景下都取得了成功。本文将对FATE框架进行初步的理论和应用探索。
二、FATE介绍
2.1 机器学习背景介绍
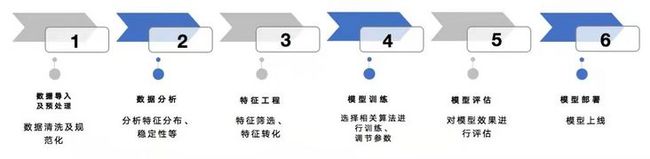
图1:机器学习一般流程
在启动一个机器学习模型项目后,一般会经历以下6个步骤:
- 导入数据对数据进行预处理: 这一步主要对数据进行清洗,去除异常样本,规范数据格式等
- 对数据进行分析:了解数据含义,分析变量分布,做特征变量衍生等
- 特征工程:筛选特征,比如计算变量IV, 特征转换,比如归一化、转换为woe等
- 训练模型:选定模型,模型调参
- 评估模型:根据项目选定模型评估指标, 常见指标有AUC, KS, Precision, Recall 等
- 模型上线:线上部署,供业务方调用
在介绍联邦学习之前,先以逻辑斯特回归模型(Logistic Regression, 以下简称LR)为例,介绍机器学习中的一些概念。分类和回归问题是机器学习中最常见的两类问题,常见的分类问题可以简化为如下的一个数学问题:Y={y1, y2 ,...,yn}表示分类问题的类别总和, n为不同类别数,X={x1,x2,...,xm}为所有特征的集合, m为特征总量。分类问题的本质是学习一个函数映射f(X;w) =Y, w为模型的参数。我们假设X和Y之间存在线性关系,即Y∝ wX,wX∈(-∞ ,∞), 分类问题中yi 为离散型数据,比如二分类问题,yi ={-1, 1}, 所以会在wX上添加一个sigmoid函数,该函数可以将(-∞ ,∞)之间的数字“压缩”到(0, 1)之间,而这个压缩值可以看做是模型的置信度。
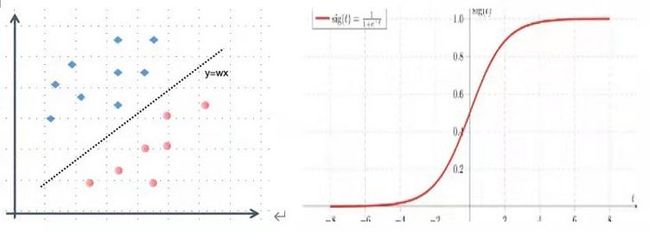
图2: LR示意图及sigmoid 函数
以上的一个计算方式f(X,w)=sigmoid(wX) 就是逻辑斯特回归模型, LR模型针对每个样本会输出样本对应的置信度,一般地,如果f(xi,Θ)>=0.5, yi =1 , 反之yi = -1。
那么,模型的参数w如何获取呢?参数Θ的学习可以转化为优化问题,在LR 模型中,损失函数为:![]()
逻辑斯特回归模型常见的参数求解方法为随机梯度下降。随机梯度下降法求参的步骤如下:
- 给定一个优化目标函数f(X, w)、迭代次数T以及学习率lr, 随机初始化参数w0;
- 设定初始迭代次数t=0
- for t = 0, 1, 2, ..., T:
- 计算g=fw’(X,w)
- 更新w : wt+1 = wt - lr *g
梯度为:![]()
2.2 联邦学习概述
在微众发布的《联邦学习白皮书v2.0》中,对联邦学习的目的,联邦学习要达到的效果做了进一步阐述:
- 各方数据都保留在本地,不泄露隐私也不违反法规;
- 多个参与者联合数据建立虚拟的共有模型,并且共同获益的体系;
- 在联邦学习的体系下,各个参与者的身份和地位平等;
- 联邦学习的建模效果和将整个数据集放在一处建模的效果相同,或相差不大(在各个数据的用户对齐(user alignment)或特征对齐(feature alignment)对齐的条件下);
- 迁移学习是在用户或者特征不对齐的情况下,也可以在数据间通过交换加密参数达到知识迁移的效果。
联邦学习根据各个数据持有方(数据持有方可以大于等于两方,以下为了简化以两方联邦建模为例)之间用户和特征的分布情况,将联邦学习分为三种:
图3:联邦学习分类示意图
横向联邦学习:联合建模的双方用户重叠较少,用户特征X重叠较多的情况;
纵向联邦学习:联合建模的双方用户重叠较多,用户特征X重叠较少的情况;
联邦迁移学习:联合建模的双方用户以及用户X的重叠都较少。
2.3 FATE框架
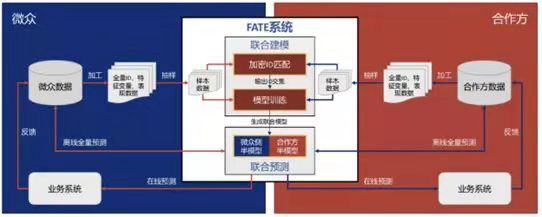
图4: FATA双方联合建模系统框架
图4展示了一个完整的FATE双方联合建模的系统框架,微众和合作方分别部署了一个FATE集群,双方集群共同组成了一个FATE生态系统,双方分别从各自的数据库中抽样全量ID, 对ID进行加密求交集,目的是找出双方共同拥有的用户S,提取共同用户集的特征变量XA, XB以及表现数据Y, 进入FATE 的联邦学习阶段, 模型训练完成后会生成一个联合模型,联合模型分别在AB方保存半个模型。联合建模双方可以共同使用模型对全量样本进行离线预测以及在线打分。
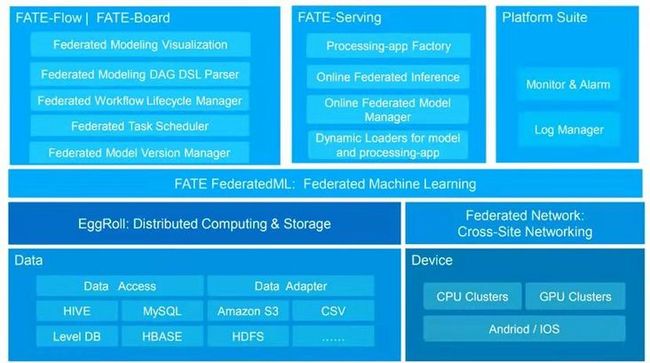
图5 : FATE技术架构总览
图5为FATE系统总体架构,从下往上比较重要的功能模块:
- Federated Network: 实现FATE合作方之间的跨站点通信功能;
- EggRoll: 数据的分布式存储和计算模块;
- Fate Federated ML: 联邦学习算法功能组件,组件内实现了机器学习常用算法;
- Fate-Flow: 联邦学习建模pipeline, 模型计算调用入口;
- Fate-Board: 联邦学习建模看板,展现模型的pipeline, 部分中间结果,模型进度以及模型日志;
- Fate-Serving: 支持联邦学习联合模型部署和在线预测。
在FATE系统中,最核心的部分之一就是Fate Federated ML,这一部分功能组件实现了机器学习建模过程中的大部分功能:
- 联邦学习样本对齐:private set intersect(PSI), 用于纵向样本对齐,包括基于RSA+哈希等对齐方式
- 联邦特征工程:包括联邦采样,联邦特征分箱,联邦特征选择,联邦相关性,联邦统计等
- 联邦机器学习:联邦Logistic Regression, LinearRegression, PossionRegression, PossionRegression, 联邦SecureBoost, 联邦DNN, 联邦迁移学习等
- 多方安全计算协议:提供多种安全协议,包括同态加密,SecretShare, RSA, DiffieHellman等
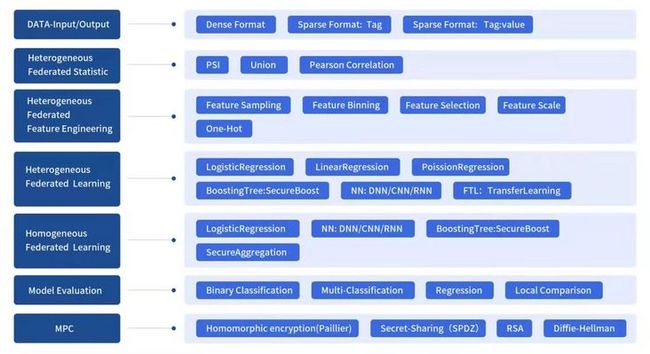
图6:FATE算法列表
2.4 FATE算法框架
机器学习算法联邦化的底层关键技术是MPC(Secure multi-party computation) 。MPC是姚期智先生提出的为解决一组互不信任的参与方之间在保护隐私信息以及没有可信第三方的前提下进行协同计算理论框架。多方安全计算能够同时确保输入的隐私性和计算的正确性,在无可信第三方的前提下通过数学理论保证参与计算的各方成员输入信息不暴露,且同时能够获得准确的运算结果。MPC有多组算法和理论组成,在FATE模型算法中主要使用了同态加密算法。
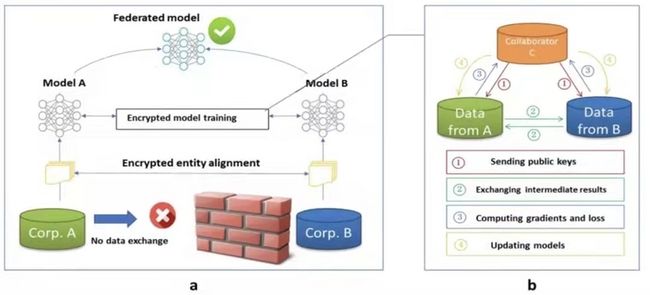
图7 :FATE纵向联邦学习基于梯度优化算法的通用框架
在图7展示了纵向联邦学习基于梯度优化算法的通用框架,假设企业A和企业B共同训练一个模型,A方有自己的数据X, B方有X和Y, 由于隐私保护原因,AB不能直接交换数据。为了保证训练过程数据的保密性,加入了可信第三方C, 整个建模流程如下:
- 由可信第三方C创建秘钥对,并将公共秘钥发送给A和B;
- A方和B方对中间结果进行加密和交换。中间结果用来帮助计算梯度和损失值;
- A方和B方计算加密梯度并分别加入附加掩码。B方还需计算加密损失。A方和B方将加密的结果发送给C方;
- C方对梯度和损失信息进行解密,并将结果返回A方和B方。A方和B方解除梯度信息上的掩码,并根据这些梯度信息来更新模型参数。
重复2-4步直到停止(比如C可以根据损失函数值不再变化就停止)。
模型训练完成后,企业A 和企业B分别拥有独立的半模型,在预测时,AB双方需要共同合作来完成模型的预测。
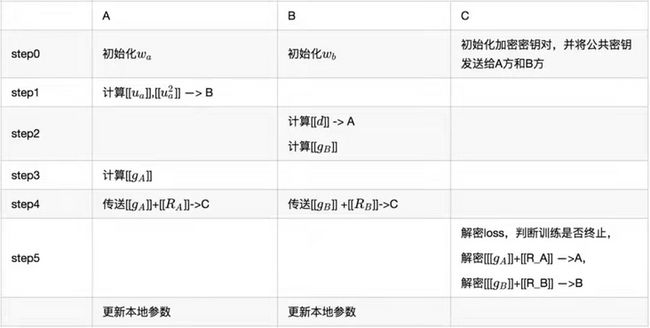
下面以LR算法为例,详细阐述数据在各方之间的流转。
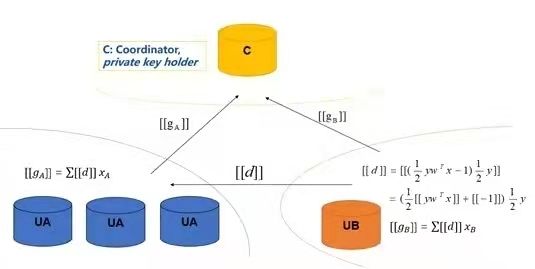
图8: 多方联邦LR计算模型计算框架
图中[[*]]表明对数据进行了同态加密,同态加密技术对明文进行的加法和乘法运算再加密,与加密后对密文进行相应的运算,结果是等价的。目前只能实现加减乘除的同态加密,由2.1的介绍可知,在LR模型的优化过程中,需要进行exp指数操作,为了避免这个操作,在联邦中对LR的损失函数进行了泰勒展开,损失函数和梯度转换为:
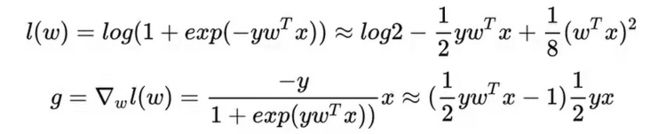
模型的各个参与方数据计算和流转步骤如下:
2.5 FATE联合建模实践
FATE github 官方网站 https://github.com/FederatedA... 上有详细的安装指导,有兴趣的朋友可以按照指导进行FATE部署和安装。
FATE 通过fateflow模块启动建模任务,fateflow 以fate-dsl语言定义模型的pipeline, 整个模型的pipeline定义分为两个配置文件,dsl.json配置文件定义模型的流程,conf.json 配置文件制定模型各个模块的参数设定。新版FATE发布后,可以支持类似于sklearn 编程风格的模型pipeline进行模型设计,熟悉python的建模分析师可以更快的上手使用FATE构建隐私安全模型。下面为FATE LR模型的pipeline代码。
FATE Pipeline:
import argparse
from pipeline.backend.pipeline import PipeLine
from pipeline.component import DataIO
from pipeline.component import Evaluation
from pipeline.component import HeteroLR
from pipeline.component import Intersection
from pipeline.component import Reader
from pipeline.interface import Data
from pipeline.utils.tools import load_job_config
from pipeline.runtime.entity import JobParameters
def main(config="../../config.yaml", namespace=""):
# obtain config
if isinstance(config, str):
config = load_job_config(config)
parties = config.parties
guest = parties.guest[0]
host = parties.host[0]
arbiter = parties.arbiter[0]
backend = config.backend
work_mode = config.work_mode
guest_train_data = {"name": "breast_hetero_guest", "namespace": f"experiment{namespace}"}
host_train_data = {"name": "breast_hetero_host", "namespace": f"experiment{namespace}"}
pipeline = PipeLine().set_initiator(role='guest', party_id=guest).set_roles(guest=guest, host=host, arbiter=arbiter)
reader_0 = Reader(name="reader_0")
reader_0.get_party_instance(role='guest', party_id=guest).component_param(table=guest_train_data)
reader_0.get_party_instance(role='host', party_id=host).component_param(table=host_train_data)
dataio_0 = DataIO(name="dataio_0")
dataio_0.get_party_instance(role='guest', party_id=guest).component_param(with_label=True)
dataio_0.get_party_instance(role='host', party_id=host).component_param(with_label=False)
intersection_0 = Intersection(name="intersection_0")
hetero_lr_0 = HeteroLR(name="hetero_lr_0", early_stop="weight_diff", max_iter=10, penalty="L2", tol=0.0001, alpha=0.01,optimizer="rmsprop",batch_size=320,learning_rate=0.15)
evaluation_0 = Evaluation(name="evaluation_0", eval_type="binary")
pipeline.add_component(reader_0)
pipeline.add_component(dataio_0, data=Data(data=reader_0.output.data))
pipeline.add_component(intersection_0, data=Data(data=dataio_0.output.data))
pipeline.add_component(hetero_lr_0, data=Data(train_data=intersection_0.output.data))
pipeline.add_component(evaluation_0, data=Data(data=hetero_linr_0.output.data))
pipeline.compile()
job_parameters = JobParameters(backend=backend, work_mode=work_mode)
pipeline.fit(job_parameters)
# predict
# deploy required components
pipeline.deploy_component([dataio_0, intersection_0, hetero_lr_0])
predict_pipeline = PipeLine()
# add data reader onto predict pipeline
predict_pipeline.add_component(reader_0)
# add selected components from train pipeline onto predict pipeline
# specify data source
predict_pipeline.add_component(pipeline,
data=Data(predict_input={pipeline.dataio_0.input.data: reader_0.output.data}))
# run predict model
predict_pipeline.predict(job_parameters)
pipeline.dump("pipeline_saved.pkl")
if name == "__main__":
parser = argparse.ArgumentParser("PIPELINE DEMO")
parser.add_argument("-config", type=str,
help="config file")
args = parser.parse_args()
if args.config is not None:
main(args.config)
else:
main()
以上代码实现了一个简单的LR模型,下面对代码进行简单解读:
• 代码的18-23行:初始化FATE建模的相关配置,里面涉及到FATE中常见的几个概念
party_id: 它是一个Int型数字,用来唯一标识一个单边FATE物理集群
role: 参与建模的多方在建模任务重担任的角色,一共有三种角色:
guest 为数据应用方,是拥有数据标签y值的一方,在一个建模任务中只有一个guest方;
host 为数据提供方,只提供建模特征x, 在一个建模任务中可以有大于等于一个的host方参与;
arbiter 为仲裁方,作为可信第三方参与建模过程中的聚合平均等操作,在FATE中中仲裁方可以有guest方来担任;
backend :指定分布式计算存储引擎,backend=0,使用eggroll 作为分布式计算和存储工具,backend=1使用spark以及rabbitmq作为消息队列,backend=2 使用spark和pulsar的组合;
work_mode:work_mode=0 为standalone, work_mode=1 为cluster;
• 代码25-26行:声明guest方和host方的文件名称,在这段代码中使用了eggroll进行分布式计算和存储 ,在eggroll中命名空间namespace和表名name共同指定一个数据文件;
• 代码28行:初始化模型pipeline, 指定任务发起方以及guest方和host方对应的party_id;
• 代码30-32行: 定义reader, 指定guest方和host方的使用数据;
• 代码34-36行:初始化dataIO, 对双方样本进行初步解析,指定样本中是否包含y值, 这一步也支持数据进行缺失值填充;
• 代码38行:初始化intersect隐私求交组件,该组件用来计算多个数据源中的用户id交集,并且不泄露除交集外的任何用户id, FATE中支持两种隐私求交方式:RAW和RSA, RSA求交方式的安全性高于RAW, 但是计算和通信代价要高于RAW方式;
• 代码39行:定义LR模型组件,同时指定LR模型参数, 纵向联邦LR模型的参数基本和传统机器学习LR的一致;
• 代码40行:定义一个模型评估器,评估的模型类型为二分类模型;
• 代码42-46行:按照建模流程顺序,依次将以上功能组件加入到pipeline中;
• 代码48-50行:编译pipeline;初始化建模任务参数,设定work_node以及backend; 训练pipeline;
• 代码54行:指定pipeline上线部署时需要的功能组件;
• 代码56-62行: 定义模型预测的pipeline, 并添加相应组件, 与模型训练的pipeline相比,主要区别在数据读取器;
• 代码64行:使用模型预测;
• 代码65行:保存模型。
参考文献:
- 《联邦学习白皮书v2.0》
- A Quasi-Newton Method Based Vertical Federated Learning Framework for Logistic Regression
- 《联邦学习的研究与应用》
- 中国工信出版集团《联邦学习Federated Learning》