网络爬虫基础总结
网络爬虫基础总结
- 网络爬虫
-
- 1. 爬虫简介
-
- 网页结构
- 2.BeatufulSoup 解析网页
-
- 0.BeatufulSoup的介绍
- 1.安装
- 2.1 简单使用
- 2.2 BeautifulSoup 解析网页: CSS
-
- 2.2.1 什么是 CSS
- 2.2.1 CSS 的 Class
- 2.2.2 按 Class 匹配
- 2.3 BeautifulSoup 解析网页: 正则表达
-
- 2.3.1 正则表达式
- 2.3.2 正则匹配
- 3.更多请求/下载方式
-
- 3.1 多功能的requests
-
- 3.1.1 获取网页的方式
- 3.1.2 安装requests
- 3.1.3 requests get 请求
- 3.1.4 requests post 请求
- 3.1.5 上传图片
- 3.1.6 登录
- 3.1.7 使用Session登录
- 3.2 下载文件
- 3.3 小练习:下载美图
- 4.加速你的爬虫
- 5.高级爬虫
- 6 Scrapy项目
这篇文章是对莫烦pyhton爬虫基础课进行一个总结,详细教程大家可以参考学习官网: https://morvanzhou.github.io/tutorials/data-manipulation/scraping/
网络爬虫
对于网络爬虫,我个人理解就是从网页爬取数据。那么要学习网络爬虫,你得弄清楚以下几个问题:(1)网页是什么?(2)数据在网页中怎么存储的?(3)如何爬取数据?让我们一起带着问题去开启爬虫学习之旅吧。
本课程的教学流程如下图所示,不过这些都是些基础知识。有了基础之后,你才能更加深入自学。
1. 爬虫简介
爬虫的产物产物无处不在, 比如说搜索引擎 (Google, 百度), 他们能为你提供这么多搜索结果, 也都是因为它们爬了很多信息, 然后展示给你. 再来说一些商业爬虫, 比如爬爬淘宝的同类商品的价格信息, 好为自己的商品挑选合适的价格. 爬虫的用途很多很多, 如果你搞机器学习, 爬虫就是你获取数据的一种途径, 网上的信息成百上千, 只要你懂爬虫, 你都能轻松获取。
- why? ,爬虫就是为了爬取所需数据为我所用;
- 知其然,也要知其所以然,我们必须了解网页结构。
网页结构
学习爬虫, 首先要懂的是网页. 支撑起各种光鲜亮丽的网页的不是别的, 全都是一些代码. 这种代码我们称之为 HTML, HTML 是一种浏览器(Chrome, Safari, IE, Firefox等)看得懂的语言, 浏览器能将这种语言转换成我们用肉眼看到的网页. 所以 HTML 里面必定存在着很多规律, 我们的爬虫就能按照这样的规律来爬取你需要的信息.其实除了 HTML, 一同构建多彩/多功能网页的组件还有 CSS 和 JavaScript.
网页的基本组成部分
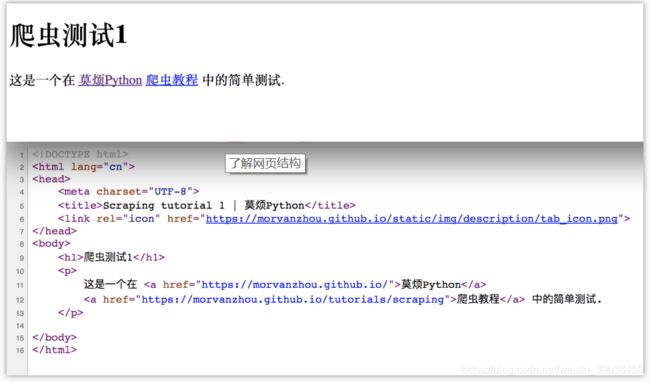
在 HTML 中, 基本上所有的实体内容, 都会有个 tag 来框住它. 而这个被 tag 住的内容, 就可以被展示成不同的形式, 或有不同的功能. 主体的 tag 分成两部分, header 和 body. 在 header 中, 存放这一些网页的网页的元信息, 比如说 title, 这些信息是不会被显示到你看到的网页中的. 这些信息大多数时候是给浏览器看, 或者是给搜索引擎的爬虫看.例如,莫烦爬虫测试1的网页代码就很好地展现了网页的节本结构,具体网页的HTML代码如下:
用python登录网页
对网页结构和 HTML 有了一些基本认识以后, 我们就能用 Python 来爬取这个网页的一些基本信息. 首先要做的, 是使用 Python 来登录这个网页, 并打印出这个网页 HTML 的 source code. 注意, 因为网页中存在中文, 为了正常显示中文, read() 完以后, 我们要对读出来的文字进行转换, decode() 成可以正常显示中文的形式.
from urllib.request import urlopen
# if has Chinese, apply decode()
html = urlopen(
"https://morvanzhou.github.io/static/scraping/basic-structure.html"
).read().decode('utf-8')
print(html)
print 出来就是下面这样啦. 这就证明了我们能够成功读取这个网页的所有信息了. 但我们还没有对网页的信息进行汇总和利用. 我们发现, 想要提取一些形式的信息, 合理的利用 tag 的名字十分重要.
<!DOCTYPE html>
<html lang="cn">
<head>
<meta charset="UTF-8">
<title>Scraping tutorial 1 | 莫烦Python</title>
<link rel="icon" href="https://morvanzhou.github.io/static/img/description/tab_icon.png">
</head>
<body>
<h1>爬虫测试1</h1>
<p>
这是一个在 <a href="https://morvanzhou.github.io/">莫烦Python</a>
<a href="https://morvanzhou.github.io/tutorials/scraping">爬虫教程</a> 中的简单测试.
</p>
</body>
</html>
2.BeatufulSoup 解析网页
Beautiful Soup 4.2.0 中文官网
0.BeatufulSoup的介绍
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式。 我们了解了网页 (html) 的基本构架, 知道了爬网页就是在这个构架中找到需要的信息. 那么找到需要的信息时, BeautifulSoup 就是一个找信息好帮手. 它能帮你又快有准地找到信息. 大大简化了使用难度。
1.安装
# Python 2+
pip install beautifulsoup4
#---------------------------------------------------
# Python 3+
pip3 install beautifulsoup4
```python
在这里插入代码片
2.1 简单使用
`爬取基本网页,BeautifulSoup 使用起来非常简单, 我们先按常规读取网页。
from bs4 import BeautifulSoup
from urllib.request import urlopen
# if has Chinese, apply decode()
html = urlopen("https://morvanzhou.github.io/static/scraping/basic-structure.html").read().decode('utf-8')
print(html
回顾一下, 每张网页中, 都有两大块, 一个是 , 一个是 , 我们等会用 BeautifulSoup 来找到 body 中的段落
和所有链接 .
<!DOCTYPE html>
<html lang="cn">
<head>
<meta charset="UTF-8">
<title>Scraping tutorial 1 | 莫烦Python</title>
<link rel="icon" href="https://morvanzhou.github.io/static/img/description/tab_icon.png">
</head>
<body>
<h1>爬虫测试1</h1>
<p>
这是一个在 <a href="https://morvanzhou.github.io/">莫烦Python</a>
<a href="https://morvanzhou.github.io/tutorials/scraping">爬虫教程</a> 中的简单测试.
</p>
</body>
</html>
读取其实很简单,直接soup.h1或soup.p,a链接就用soup.find_all(a).
soup = BeautifulSoup(html, features='lxml')
print(soup.h1)
"""
爬虫测试1
"""
print('\n', soup.p)
"""
"""
"""
爬虫教程
"""
all_href = soup.find_all('a')
all_href = [l['href'] for l in all_href]
print('\n', all_href)
# ['https://morvanzhou.github.io/', 'https://morvanzhou.github.io/tutorials/scraping']
懂得这些还是远远不够的, 真实情况往往比这些复杂. BeautifulSoup 还有很多其他的选择”增强器”. 还得了解些 CSS 的概念, 用 BeautifulSoup 加上 CSS 来选择内容.
2.2 BeautifulSoup 解析网页: CSS
2.2.1 什么是 CSS
其实CSS就是对页面进行渲染的,让页面更加好看,特别有“骨感”!下面就拿莫烦python网站举例子。

上面是没有加CSS的网页,如果有CSS,网页就变得丰富多彩起来. 文字有了颜色, 字体, 位置也多样了, 图片也有规则了,如下图所示。

所以, CSS 主要用途就是装饰你 “骨感” HTML 页面。
2.2.1 CSS 的 Class
网络爬虫必须掌握的一条CSS规则就是Class,CSS 在装饰每一个网页部件的时候, 都会给它一个名字. 而且一个类型的部件, 名字都可以一样.比如我们这个练习网页. 里面的字体/背景颜色, 字体大小, 都是由 CSS 来掌控的.

而 CSS 的代码, 可能就会放在这个网页的中. 我们先使用 Python 读取这个页面.
from bs4 import BeautifulSoup
from urllib.request import urlopen
# if has Chinese, apply decode()
html = urlopen("https://morvanzhou.github.io/static/scraping/list.html").read().decode('utf-8')
print(html)
在 中, 你会发现有这样一些东西被放在