Python爬取豆瓣top榜电影
希望阅读本文的时候,你已经装好python环境。该程序用于爬取豆瓣电影数据,并将数据保存到mysql。
1.你需要在你的python中下载需要的模块,bs4,xlwt,以及pymysql

2.程序主要的步骤是分析网页,提取网页中的数据,存储。具体的mysql表结构如下:
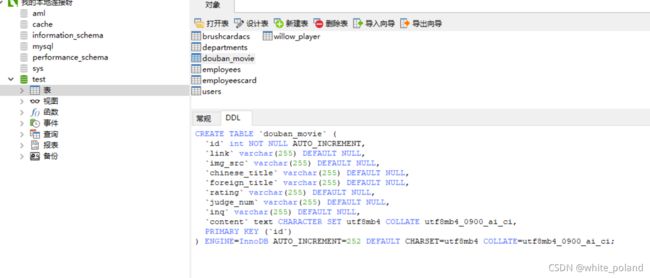
3.python过程代码
获取网页内容
#得到一个指定url的网页内容
def askUrl(url):
#代理,模拟浏览器发送请求,防止被检测为爬虫
head = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"
}
request = urllib.request.Request(url , headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"code"):
print(e.reason)
return html
分析网页并得到数据
#爬取网页
def getData(baseUrl):
dataList = []
for i in range(0,10):
url = baseUrl + str(i * 25)
html = askUrl(url)
#解析数据
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all("div" , class_ = "item"): #找div class属性为item的
data = [] # 保存信息
item = str(item)
#正则查找指定字符串
#链接
link = re.findall(findLink,item)[0]
data.append(link)
#图片
imgSrc = re.findall(findImgSrc,item)[0]
data.append(imgSrc)
#标题
titles = re.findall(findTitle,item)
if(len(titles) == 2):
cTitle = titles[0]
data.append(cTitle)
eTitle = titles[1].replace("/","")
data.append(eTitle)
else:
data.append(titles[0])
data.append("")
#评分
rating = re.findall(findRating,item)[0]
data.append(rating)
#评价人数
judge = re.findall(findJudge,item)[0]
data.append(judge)
#标识
inq = re.findall(findInq,item)
if(len(inq) !=0):
inq = inq[0].replace("。","")
data.append(inq)
else:
data.append("")
#内容
bd = re.findall(findBd,item)[0]
bd = re.sub('数据存储
#存储数据到Mysql
def saveDataToMysql(dataList):
# 打开数据库连接(运行程序记得修改这个配置)
db = pymysql.connect(host='localhost',
user='root',
password='123456',
database='test')
# 使用cursor()方法获取操作游标
cursor = db.cursor()
#批量插入
cursor.executemany('insert into douban_movie(link,img_src,chinese_title,foreign_title,rating,judge_num,inq,content) values(%s,%s,%s,%s,%s,%s,%s,%s)', dataList)
try:
# 提交到数据库执行
db.commit()
except:
# 如果发生错误则回滚
db.rollback()
# 关闭数据库连接
db.close()
4.执行后的mysql结果:
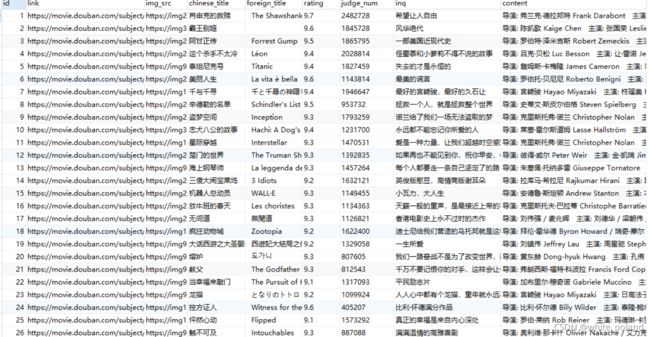
如果需要完整源码的可以上github自取,地址:
python豆瓣电影top数据爬取,并保存至mysql
每天进步一点点,开心也多一点点