命名实体识别NER & 如何使用BERT实现
目录
1、NER 简介
2. NER方法
2.1 传统机器学习方法:HMM和CRF
2.2 LSTM+CRF:BiLSTM-CRF
2.3 CNN+CRF:IDCNN-CRF
2.4 BERT+(LSTM)+CRF:BERT实现
(1)获取BERT预训练模型
(2)修改 数据预处理代码:DataProcessor
(3)构建模型:create_model
(4) 模型训练
2.5 tensorflow里的CRF原理
3. 实战应用
3.1 语料准备
3.2 数据增强
4. 命名实体识别的难点与现状
5. 未来研究的重点
6. 开源实现
论文:从机器学习到深度学习的代表性研究论文
项目:NLP经典项目实现和论文总结
实体识别和关系抽取是例如构建知识图谱等上层自然语言处理应用的基础。实体识别可以简单理解为一个序列标注问题:给定一个句子,为句子序列中的每一个字做标注。因为同是序列标注问题,除去实体识别之外,相同的技术也可以去解决诸如分词、词性标注(POS)等不同的自然语言处理问题。
说到序列标注直觉是会想到RNN的结构。现在大部分表现最好的实体识别或者词性标注算法基本都是biLSTM的套路。就算是关系抽取这种本来应该很适合CNN来做的文本分类的问题,我们也用了biGRU加字级别与句子级别的双重Attention结构解决掉了。就像Ruder在他的博客 Deep Learning for NLP Best Practices 里面说的,There has been a running joke in the NLP community that an LSTM with attention will yield state-of-the-art performance on any task.
1、NER 简介
NER又称作专名识别,是自然语言处理中的一项基础任务,应用范围非常广泛。命名实体一般指的是文本中具有特定意义或者指代性强的实体,通常包括人名、地名、组织机构名、日期时间、专有名词等。NER系统就是从非结构化的输入文本中抽取出上述实体,并且可以按照业务需求识别出更多类别的实体,比如产品名称、型号、价格等。因此实体这个概念可以很广,只要是业务需要的特殊文本片段都可以称为实体。

学术上NER所涉及的命名实体一般包括3大类(实体类,时间类,数字类)和7小类(人名、地名、组织机构名、时间、日期、货币、百分比)。随着 NLP 任务的不断扩充,在特定领域中会出现特定的类别,比如医药领域中,药名、疾病等类别。
实际应用中,NER模型通常只要识别出人名、地名、组织机构名、日期时间即可,一些系统还会给出专有名词结果(比如缩写、会议名、产品名等)。货币、百分比等数字类实体可通过正则搞定。另外,在一些应用场景下会给出特定领域内的实体,如书名、歌曲名、期刊名等。
NER是NLP中一项基础性关键任务。从自然语言处理的流程来看,NER可以看作词法分析中未登录词识别的一种,是未登录词中数量最多、识别难度最大、对分词效果影响最大问题。同时NER也是关系抽取、事件抽取、知识图谱、机器翻译、问答系统等诸多NLP任务的基础。
NER当前并不算是一个大热的研究课题,因为学术界部分学者认为这是一个已经解决的问题。当然也有学者认为这个问题还没有得到很好地解决,原因主要有:命名实体识别只是在有限的文本类型(主要是新闻语料中)和实体类别(主要是人名、地名、组织机构名)中取得了不错的效果;与其他信息检索领域相比,实体命名评测预料较小,容易产生过拟合;命名实体识别更侧重高召回率,但在信息检索领域,高准确率更重要;通用的识别多种类型的命名实体的系统性能很差。
2. NER方法
NER一直是NLP领域中的研究热点,从早期基于词典和规则的方法,到传统机器学习的方法,到近年来基于深度学习的方法,NER研究进展的大概趋势大致如下图所示。

图1:NER发展趋势
2.1 传统机器学习方法:HMM和CRF
在基于机器学习的方法中,NER被当作序列标注问题。利用大规模语料来学习出标注模型,从而对句子的各个位置进行标注。NER 任务中的常用模型包括生成式模型HMM、判别式模型CRF等。
条件随机场(ConditionalRandom Field,CRF)是NER目前的主流模型。它的目标函数不仅考虑输入的状态特征函数,而且还包含了标签转移特征函数。在训练时可以使用SGD学习模型参数。在已知模型时,给输入序列求预测输出序列即求使目标函数最大化的最优序列,是一个动态规划问题,可以使用Viterbi算法解码来得到最优标签序列。CRF的优点在于其为一个位置进行标注的过程中可以利用丰富的内部及上下文特征信息。
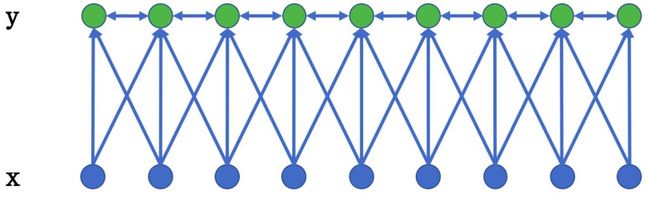
图2:一种线性链条件随机场

- crf++学习模块:crf++提供的一个基于CRF条件随机域学习策略的学习方法。
- 训练语料:关于中文命名实体识别的训练语料,网上有一些公开的语料库(eg:人民日报语料库),将其处理为crf++能识别的格式,加入自己的标签即可。
- 特征选取函数:告诉crf机器学习过程中需要考虑训练语料中的哪些特征(如上下文,词性特征等)
- model:crf++将学习结果以一定格式保存到model文件中。
- 测试语料:可以选择语料库中的一部分作为测试语料。
- crf++测试模块:用于测试crf学习的效果,使用学习部分生成model去预测测试语料中的标签。
如何提升系统的准确率和召回率
-
训练语料的质量和数量
-
特征的选取
-
调整crf++的参数
-
在召回的基础上,进行二次crf学习,可以提高准确率
2.2 LSTM+CRF:BiLSTM-CRF
参考:通俗理解BiLSTM-CRF命名实体识别模型中的CRF层
近年来,随着硬件计算能力的发展以及词的分布式表示(word embedding)的提出,神经网络可以有效处理许多NLP任务。这类方法对于序列标注任务(如CWS、POS、NER)的处理方式是类似的:将token从离散one-hot表示映射到低维空间中成为稠密的embedding,随后将句子的embedding序列输入到RNN中,用神经网络自动提取特征,Softmax来预测每个token的标签。
这种方法使得模型的训练成为一个端到端的过程,而非传统的pipeline,不依赖于特征工程,是一种数据驱动的方法,但网络种类繁多、对参数设置依赖大,模型可解释性差。此外,这种方法的一个缺点是对每个token打标签的过程是独立的进行,不能直接利用上文已经预测的标签(只能靠隐含状态传递上文信息),进而导致预测出的标签序列可能是无效的,例如标签I-PER后面是不可能紧跟着B-PER的,但Softmax不会利用到这个信息。
学术界提出了DL-CRF模型做序列标注。在神经网络的输出层接入CRF层(重点是利用标签转移概率)来做句子级别的标签预测,使得标注过程不再是对各个token独立分类。
应用于NER中的biLSTM-CRF模型主要构成:
-
Embedding层:主要有词向量、字向量以及一些额外特征
-
双向LSTM层:特征抽取器
-
最后的CRF层:做句子级别的标签预测。

实验结果表明biLSTM-CRF已经达到或者超过了基于丰富特征的CRF模型,成为目前基于深度学习的NER方法中的最主流模型。在特征方面,该模型继承了深度学习方法的优势,无需特征工程,使用词向量以及字符向量就可以达到很好的效果,如果有高质量的词典特征,能够进一步获得提高。
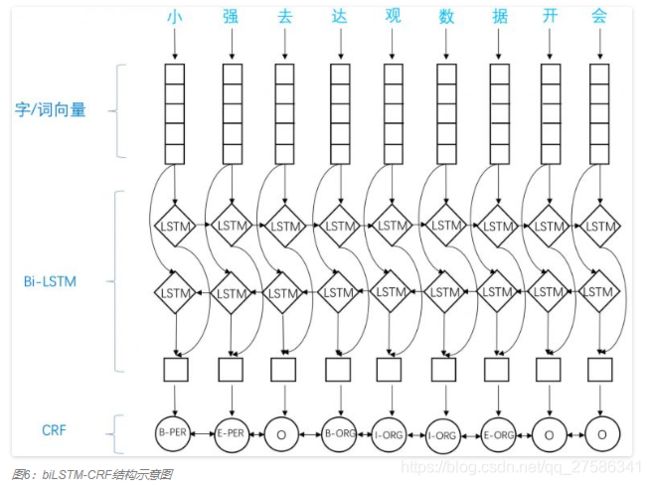
我们来好好分析一下这个模型,看数据的流转和各层的作用。
1.embedding layer 将中文转化为字向量,获得输入embedding
2.将embedding输入到BiLSTM层,进行特征提取(编码),得到序列的特征表征,logits。
3.logits需要解码,得到标注序列。将其输入到解码CRF层,获得每个字的序列。
总结一下,该模型的重点其实有两个:
1. 引入双向LSTM层作为特征提取工具,LSTM拥有较强的长序列特征提取能力,是个不错的选择。双向LSTM,在提取某个时刻特征时,能够利用该时刻之后的序列的信息,无疑能够提高模型的特征提取能力。
2. 引入CRF作为解码工具。中文输入经过双向LSTM层的编码之后,需要能够利用编码到的丰富的信息,将其转化成NER标注序列。通过观察序列,预测隐藏状态序列,CRF无疑是首选。LSTM的输出=观测序列Y=一句话,CRF输出=隐状态序列X=标记序列,CRF使用维特比算法解码得到隐藏状态序列S(s1,s2,...st+1)。
解码问题:给出观测序列O和模型μ,怎样选择一个隐藏状态序列S(s1,s2,...st+1),能最好的解释观测序列O;
2.3 CNN+CRF:IDCNN-CRF
模型参考:https://github.com/crownpku/Information-Extraction-Chinese/tree/master/NER_IDCNN_CRF
解读参考:https://www.toutiao.com/i6751585874980372995/
CNN虽然在长序列的特征提取上有弱势,然而CNN模型有并行能力,有运算速度快的优势。膨胀卷积的引入,使得CNN在NER任务中,能够兼顾运算速度和长序列的特征提取。
基于2017年7月一篇paper Fast and Accurate Entity Recognition with Iterated Dilated Convolutions, 介绍一个使用 Iterated Dilated CNN加CRF的模型来做中文实体识别的方法。代码主要是基于开源项目zjy-ucas/ChineseNER开发,在原来biLSTM模型的基础上增加了IDCNN模型的选项,而IDCNN的模型参考了koth/kcws的实现。感谢!两位大牛都基于tensorflow写代码,虽然风格迥异,代码却都非常漂亮!
Paper: Fast and Accurate Entity Recognition with Iterated Dilated Convolutions
对于序列标注来讲,普通CNN有一个不足,就是卷积之后,末层神经元可能只是得到了原始输入数据中一小块的信息。而对NER来讲,整个输入句子中每个字都有可能对当前位置的标注产生影响,即所谓的长距离依赖问题。为了覆盖到全部的输入信息就需要加入更多的卷积层,导致层数越来越深,参数越来越多。而为了防止过拟合又要加入更多的Dropout之类的正则化,带来更多的超参数,整个模型变得庞大且难以训练。因为CNN这样的劣势,对于大部分序列标注问题人们还是选择biLSTM之类的网络结构,尽可能利用网络的记忆力记住全句的信息来对当前字做标注。
但这又带来另外一个问题,biLSTM本质是一个序列模型,在对GPU并行计算的利用上不如CNN那么强大。如何能够像CNN那样给GPU提供一个火力全开的战场,而又像LSTM这样用简单的结构记住尽可能多的输入信息呢?
Fisher Yu and Vladlen Koltun 2015 提出了dilated CNN模型,意思是“膨胀的”CNN。其想法并不复杂:正常CNN的filter,都是作用在输入矩阵一片连续的区域上,不断sliding做卷积。dilated CNN为这个filter增加了一个dilation width,作用在输入矩阵的时候,会skip所有dilation width中间的输入数据;而filter本身的大小保持不变,这样filter获取到了更广阔的输入矩阵上的数据,看上去就像是“膨胀”了一般。
具体使用时,dilated width会随着层数的增加而指数增加。这样随着层数的增加,参数数量是线性增加的,而receptive field却是指数增加的,可以很快覆盖到全部的输入数据。
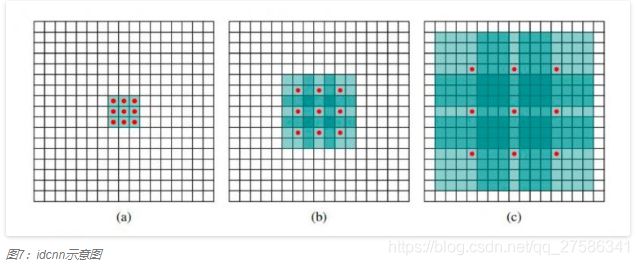
图7中可见感受域是以指数速率扩大的。原始感受域是位于中心点的1x1区域:
(a)图中经由原始感受域按步长为1向外扩散,得到8个1x1的区域构成新的感受域,大小为3x3;
(b)图中经过步长为2的扩散,上一步3x3的感受域扩展为为7x7;
(c)图中经步长为4的扩散,原7x7的感受域扩大为15x15的感受域。每一层的参数数量是相互独立的。感受域呈指数扩大,但参数数量呈线性增加。
对应在文本上,输入是一个一维的向量,每个元素是一个character embedding:
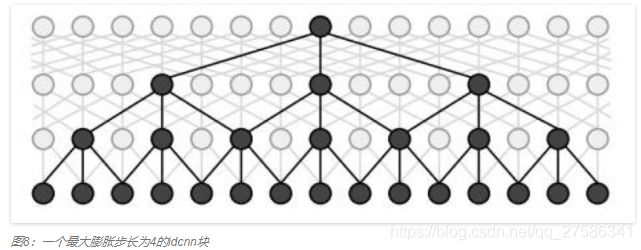
IDCNN对输入句子的每一个字生成一个logits,这里就和biLSTM模型输出logits完全一样,加入CRF层,用Viterbi算法解码出标注结果。
在biLSTM或者IDCNN这样的网络模型末端接上CRF层是序列标注的一个很常见的方法。biLSTM或者IDCNN计算出的是每个词的各标签概率,而CRF层引入序列的转移概率,最终计算出loss反馈回网络。
2.4 BERT+(LSTM)+CRF:BERT实现
模型参考:https://github.com/macanv/BERT-BiLSTM-CRF-NER
BERT中蕴含了大量的通用知识,利用预训练好的BERT模型,再用少量的标注数据进行FINETUNE是一种快速的获得效果不错的NER的方法。
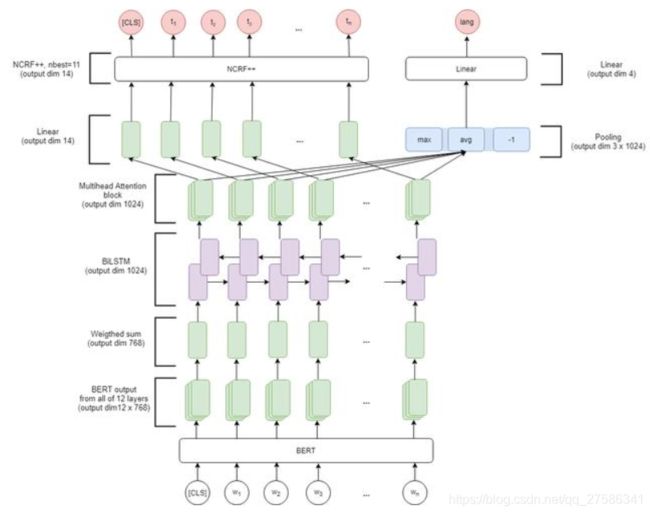
(1)获取BERT预训练模型
BERT源码可以从google-research的github中获取:https://github.com/google-research/bert
在其GitHub中,也公布了获取BERT Chinese的预训练模型,正是我们需要的,链接如下:
https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip
(2)修改 数据预处理代码:DataProcessor
参照DataProcessor,结合NER任务的特点,我们需要定义一个NerProcessor来处理NER标记语料,主要的工作就是将语料组织成Estimator能够接受的格式。主要就是实现_read_data,_create_example和get_labels三个函数,具体需要组织成什么样的形式,可以看看源代码。
我们可以实现如下形式的_create_example函数,它读取语料和标记,并且通过InputExample函数,构造成Estimator能够接受的格式。
def _create_example(self, lines, set_type):
examples = []
for (i, line) in enumerate(lines):
guid = "%s-%s" % (set_type, i)
text = tokenization.convert_to_unicode(line[1])
label = tokenization.convert_to_unicode(line[0])
examples.append(InputExample(guid=guid, text=text, label=label))
return examples(3)构建模型:create_model
首先,在create_model()中,我们利用BERT的BertModel类构造BERT结构,然后获取其最后一层的输出:
# 使用数据加载BertModel,获取对应的字embedding
model = modeling.BertModel(
config=bert_config,
is_training=is_training,
input_ids=input_ids,
input_mask=input_mask,
token_type_ids=segment_ids,
use_one_hot_embeddings=use_one_hot_embeddin
)
# 获取对应的BertModel的输出
embedding = model.get_sequence_output()然后增加(BiLSTM)CRF层,进行解码:
max_seq_length = embedding.shape[1].value
# 算序列真实长度
used = tf.sign(tf.abs(input_ids))
lengths = tf.reduce_sum(used, reduction_indices=1)
# 添加CRF output layer
blstm_crf =
BLSTM_CRF(embedded_chars=embedding,
hidden_unit=lstm_size,
cell_type=cell,
num_layers=num_layers,
dropout_rate=dropout_rate,
initializers=initializers,
num_labels=num_labels,
seq_length=max_seq_length,
labels=labels,
lengths=lengths,
is_training=is_training)
rst = blstm_crf.add_blstm_crf_layer(crf_only=True)(4) 模型训练
做了上述的准备工作之后,模型的训练只需参照run_pretraining.py的main函数即可。主要的工作有:
1. processors初始化
processor = processors[task_name]()2. 加载训练数据
train_examples = processor.get_train_examples(FLAGS.data_dir)3. 利用model_fn_builder构造模型,加载模型参数等。这是Tensorflow中新的架构方法,通过定义model_fn函数,定义模型。然后用Estimator API进行模型的训练,预测,评估等。
model_fn = model_fn_builder()4. estimator配置
estimator = tf.contrib.tpu.TPUEstimator( model_fn=model_fn,...)5.调用Estimator进行训练过程的控制及正式开始训练等。
5.1 将数据转化为tf_record 数据5.2 读取record 数据,组成batch5.3 训练模型
2.5 tensorflow里的CRF原理
在tensorflow中,实现了crf_log_likelihood函数。在命名实体识别项目中,自然语言是已知的序列,自然语言经过特征提取过后的logits,是发射矩阵,对应着t_k函数;随机初始化的self.trans矩阵是状态转移矩阵,对应着参数s_l,随着训练的过程不断的优化。
代码讲解参考:https://mp.weixin.qq.com/s/79M6ehrQTiUc0l_sO9fUqA
3. 实战应用
3.1 语料准备
Embedding:我们选择中文维基百科语料来训练字向量和词向量。
基础语料:选择人民日报1998年标注语料作为基础训练语料。
附加语料:98语料作为官方语料,其权威性与标注正确率是有保障的。但由于其完全取自人民日报,而且时间久远,所以对实体类型覆盖度比较低。比如新的公司名,外国人名,外国地名。为了提升对新类型实体的识别能力,我们收集了一批标注的新闻语料。主要包括财经、娱乐、体育,而这些正是98语料中比较缺少的。由于标注质量问题,额外语料不能加太多,约98语料的1/4。
3.2 数据增强
对于深度学习方法,一般需要大量标注语料,否则极易出现过拟合,无法达到预期的泛化能力。我们在实验中发现,通过数据增强可以明显提升模型性能。具体地,我们对原语料进行分句,然后随机地对各个句子进行bigram、trigram拼接,最后与原始句子一起作为训练语料。
另外,我们利用收集到的命名实体词典,采用随机替换的方式,用其替换语料中同类型的实体,得到增强语料。
4. 命名实体识别的难点与现状
参考:https://blog.csdn.net/u012879957/article/details/81281428
中文的命名实体识别与英文的相比,挑战更大,目前未解决的难题更多。英语中的命名实体具有比较明显的形式标志,即实体中的每个词的第一个字母要大写,所以实体边界识别相对容易,任务的重点是确定实体的类别。和英语相比,汉语命名实体识别任务更加复杂,而且相对于实体类别标注子任务,实体边界的识别更加困难。
汉语命名实体识别的难点主要存在于:(1)汉语文本没有类似英文文本中空格之类的显式标示词的边界标示符,命名实体识别的第一步就是确定词的边界,即分词;(2)汉语分词和命名实体识别互相影响;(3)除了英语中定义的实体,外国人名译名和地名译名是存在于汉语中的两类特殊实体类型;(4)现代汉语文本,尤其是网络汉语文本,常出现中英文交替使用,这时汉语命名实体识别的任务还包括识别其中的英文命名实体;(5)不同的命名实体具有不同的内部特征,不可能用一个统一的模型来刻画所有的实体内部特征。
最后,现代汉语日新月异的发展给命名实体识别也带来了新的困难。
其一,标注语料老旧,覆盖不全。譬如说,近年来起名字的习惯用字与以往相比有很大的变化,以及各种复姓识别、国外译名、网络红人、虚拟人物和昵称的涌现。
其二,命名实体歧义严重,消歧困难。譬如下列句子:
余则成潜伏在敌后 VS 余则成潜伏在线
我和你一起唱《我和你》吧。
看完吓死你:惊悚视频,胆小勿入。
5. 未来研究的重点
最后进行一下总结,将神经网络与CRF模型相结合的CNN/RNN-CRF成为了目前NER的主流模型。对于CNN与RNN,并没有谁占据绝对优势,各有各的优点。由于RNN有天然的序列结构,所以RNN-CRF使用更为广泛。基于神经网络结构的NER方法,继承了深度学习方法的优点,无需大量人工特征。只需词向量和字向量就能达到主流水平,加入高质量的词典特征能够进一步提升效果。对于少量标注训练集问题,迁移学习、半监督学习应该是未来研究的重点。
半监督式学习是最近兴起的一项技术,主要技术成为“bootstrapping",它也包括了一些监督式学习的方法,例如,都需要从一系列种子来开始学习的过程,比如一个主要是别疾病名称的系统运行之前就需要用户提供几个疾病实体的名称,然后系统就开始搜索包含这些名称的文本,并根据上下文的线索和一些其他的规则来找出相同文本中的其他疾病实例的名称。之后系统再用新找到的实体作为新的种子,重读的在文本中进行搜索的过程并寻找新的实例。通过多次的重复,可以从大量的文本中找出大量的疾病名称实体。近期进行的半监督的命名实体识别实验的结果显示,其性能和基线监督方法的性能相比具有很大竞争力。
命名实体识别近年来在多媒体索引、半监督和无监督的学习、复杂语言环境和机器翻译等方面取得大量新的研究成果。随着半监督的学习和无监督的学习方法不断被引入到这个领域, 采用未标注语料集等方法将逐步解决语料库不足的问题。在复杂语言现象(如借喻等)研究以及命名实体识别系统与机器翻译的互提高方面, 也有广阔的发展空间。命名实体识别将在更加开放的领域中, 综合各方面的发展成果, 为自然语言处理的深层次发展奠定更坚实的基础。
6. 开源实现
1, https://github.com/Hironsan/anago
可以换成中文预料就可以训练,bidirectional LSTM + CRF
2,https://github.com/ljingsheng/Named-Entity-Recognition
语料来自人民日报预料,keras,LSTM
3,https://github.com/zjy-ucas/ChineseNER
bidirectional LSTM + CRF tensorflow(其中的conlleval代码可以用来评测命名实体识别结果,参考https://blog.argcv.com/articles/2104.c)
4, https://github.com/crownpku/Information-Extraction-Chinese/tree/master/NER_IDCNN_CRF
Chinese Named Entity Recognition using IDCNN/biLSTM+CRF TensorFlow
5, (优先阅读)https://github.com/Determined22/zh-NER-TF
BiLSTM-CRF TensorFlow 文章参考:http://www.cnblogs.com/Determined22/p/7238342.html
6, https://github.com/fangwater/Medical-named-entity-recognition-for-ccks2017
医疗领域命名实体 A LSTM+CRF model for the seq2seq task for Medical named entity recognition in ccks2017
7,达观数据如何打造一个中文NER系统(传统CRF)
CRF打造的命名实体系统
8,BILSTM-CRF在命名实体识别NER上的应用
https://github.com/guillaumegenthial/sequence_tagging
https://guillaumegenthial.github.io/sequence-tagging-with-tensorflow.html
https://mp.weixin.qq.com/s?src=11×tamp=1507706758&ver=445&signature=W71hFyMaaTnzLv5utt24BJQ9bSFndQzCDqFeg6Dg2ACdD0y3nlFDHNazDzzQees8VN21cbcUlXYBSN9AFJ7tNWX4ZJ2O-pj71Rhcc4ReX09HdLrk40whV09ojT9Jbsi*&new=1
9,CRF有用的Github
9.1,一个使用条件随机场的中文命名实体识别模型(用sklearn_crfsuite,用人民日报语料)
https://github.com/lpty/nlp_base/tree/master/ner
https://blog.csdn.net/sinat_33741547/article/details/79131223
9.2,CRF++ 实现中文分词 ( 有把分词转换为CRF格式的代码以及调用举例的特征模板)
http://www.stay-stupid.com/?p=224
https://github.com/ictlyh/CRFSegment
中文分词工具测评
http://rsarxiv.github.io/2016/11/29/%E4%B8%AD%E6%96%87%E5%88%86%E8%AF%8D%E5%B7%A5%E5%85%B7%E6%B5%8B%E8%AF%84/
http://sighan.cs.uchicago.edu/bakeoff2005/
重要:命名实体现有可用训练数据以及人民日报语料库
https://github.com/hltcoe/golden-horse/tree/master/data
有CRF PPT介绍 CRF++模型格式说明
http://www.hankcs.com/nlp/the-crf-model-format-description.html