基于深度学习的动物识别方法研究与实现
基于深度学习的动物识别方法研究与实现
目 录
摘 要 I
ABSTRACT II
第一章 绪论 1
1.1 研究的目的和意义 1
1.2国内外研究现状 1
1.2.1 目标检测国内外研究现状 1
1.2.2 移动端识别国内外研究现状 2
1.3本文的主要研究内容 2
第二章 动物数据集的构建 4
2.1 数据集介绍 4
2.1.1 计算机视觉相关数据集 4
2.1.2 本文动物数据集的构建 7
2.2 数据预处理 8
2.2.1 数据清洗 8
2.2.2 数据标注 8
2.2.3 数据增广技术 10
2.3 数据格式转换 10
2.3.1 xml转csv格式 10
2.3.2 csv转tfrecord格式 12
第三章 基于深度学习的动物识别 15
3.1 搭建深度学习环境 15
3.1.1 Anaconda、Pycharm、python介绍与安装步骤 15
3.1.2 Nvidia驱动+Tensorflow1.12+cuda9.1+cudnn安装步骤 16
3.1.3 安装第三方库的几种方法 18
3.2 卷积神经网络相关知识 19
3.2.1 神经元结构 19
3.2.2 卷积神经网络 20
3.2.3 典型的CNN网络 21
3.3 目标检测算法 24
3.3.1目标检测介绍 24
3.3.2 IOU、NMS等技术介绍 24
3.3.3 RCNN系列 27
3.3.4 YOLO/SSD系列 30
3.3.5 评价指标 31
3.4 Tensorflow Lite移动端框架介绍 37
3.4.2 ckpt转tflite格式 38
3.5 网络性能实验 40
3.5.1 实验内容 40
3.5.2 实验结果与分析 40
第四章 在安卓端部署模型 44
4.1 应用开发 44
4.1.1 开发环境 44
4.1.2 软件参数 45
第五章 总结与展望 46
参考文献 48
致谢 49
摘 要
在Scopus学术数据库中,人工智能、大数据、区块链是2018年搜索频率最高的词汇之一。而人工智能中的计算机视觉随着卷积神经网络(CNN)和Nvidia GPU(Graphics Processing Unit)加速显卡的出现得到的很大的发展。GPU显卡在训练阶段加速模型的收敛速度,在推理阶段,越高级的GPU配置在推理阶段的速度也是越快的。随着移动互联网和嵌入式设备的普及,每个人拥有一部手机已经很常见。而现在手机的高速发展,像是HUAWEI nova3、畅享9 plus已经安装了GPU显卡,模型的推理速度大大提高,说明在移动端实现实时的目标检测已经成为可能。本文利用CNN,Tensorflow框架,ssd_mobilenet_v2网络结构训练目标检测模型,对神经网络的超参数优化,并使用Tensorflow Lite移动端框架将模型部署到移动端,可以实时识别斑马、长颈鹿等10类动物。本文的主要成果和创新点如下:
(1)修改ssd_mobilenet_v2_coco配置文件,将损失函数hard_example_
miner (正负样本比例为1:3)替换为focal loss[2],focal loss主要解决one-stage目标检测中正负样本比例严重失衡问题,该损失函数降低负样本在训练模型时的权重。
(2)训练模型生成的ckpt通过转换代码转成tflite格式,用来部署在安卓手机端,tflite模型的特点对于pb模型来说没明显的精度损失,低延迟,将32位浮点数转换成8位进行量化操作,模型大小缩小4倍,具有嵌入式设备的可移植性,支持GPU加速。
(3)本文在Android移动终端上搭载SSD_mobilenet_v2网络训练的模型,并对模型输出的结果使用Android的canvas框出目标边界以及在下边界输出预测的类别和所得概率。
关键词:人工智能 计算机视觉 focal loss 动物目标检测 深度学习
ABSTRACT
In Scopus academic database, artificial intelligence, big data,block chain 2018 search is one of the highest frequency vocabulary, and artificial intelligence.Computer vision as the convolutional neural networks (CNN) and Nvidia GPU (Graphics Processing Unit) acceleration of Graphics in the beginning of the development of GPU Graphics in the training stage to accelerate the convergence rate of the model, the inference stage, the more advanced stage of GPU configuration in the reasoning speed is faster.With the popularity of smart phones and embedded device,it has become common for everyone to own a mobile phone. However, with the rapid development of mobile phones like HUAWEI nova3 and changxiang 9 plus, GPU graphics card has been installed. The reasoning speed of the model has been greatly improved, indicating that it is possible to realize real-time target detection on the mobile terminal.In this paper, the convolutional neural network and Tensorflow deep learning framework were used to train the target detection model, improve the target detection algorithm, optimize the hyper-parameter of the neural network, and deploy the model to the mobile terminal using the Tensorflow Lite mobile terminal framework, which can identify the zebra, giraffe and other 10 kinds of animals in real time.The main achievements and innovations of this paper are as follows:
(1) modify the ssd_mobilenet_v2_coco configuration file, and replace the loss function hard_example_miner (positive and negative sample ratio 1:3) with focal loss. Focal loss mainly solves the severe imbalance between positive and negative samples in one-stage target detection, and this loss function reduces the weight of negative samples in the training model.
(2) the training model generation CKPT through change the code into. Lite format, used for deployment in the android mobile terminal, the characteristics of lite model for pb model not obvious precision loss, low latency, the 32-bit floating-point operations into eight quantitatively, narrow model size 4 times, has the portability of embedded devices, support GPU acceleration.
(3)In this paper, the SSD_mobilenet_v2 network training model is installed on the Android mobile terminal, and the target boundary and the predicted category and probability of the predicted output are drawn using the Android canvas box.
Key words: artificial intelligence;Computer vision;focal loss;Animal object detection;Deep learning
第一章 绪论
1.1 研究的目的和意义
随着大数据和人工智能的发展,机器学习目前已成为人工智能技术发展的前驱力量,而以战胜世界围棋第一人柯洁的阿尔法狗的诞生而著名的深度学习正在以蓬勃之势快速发展。深度学习在语音识别,自然语言处理,计算机视觉等诸多领域取得了重大突破。人所接收的外界信息有70%来自人的视觉感官系统,计算机视觉又分为跟踪、分割、目标检测、图片分类以及识别技术,目标检测更是其他计算机视觉任务的基础,只有保证了目标检测结果的类别以及定位准确性才能为跟踪以及识别技术做保障。本文选取动物种类的识别作为应用场景。随着智能手机的发展,手机的CPU逐步拥有PC端CPU的处理速度,有的手机推出了GPU图形处理器专门处理计算机视觉任务,这让移动端的浮点数快速计算速度大大加强。
随着移动互联网的发展,中国将会在2019-2020年推出5G商用,抓住智能手机和移动物联网设备的普及这个契机,本文研发一款基于tensorflow Lite框架的动物实时识别的APP,一是为幼儿的教育增加趣味性,二是对于深度学习的兴趣驱使我完成这项有趣的实验。
1.2国内外研究现状
1.2.1 目标检测国内外研究现状
目标检测的发展可以分为两个阶段,第一阶段是基于传统图像处理和机器学习算法的目标检测方法,第二阶段是基于深度学习的目标检测与识别方法。1999年,由David Lowe提出尺度不变特征变换(Scale-invariant feature transform),可在图像中检测出关键点,具有尺度不变性,是一种局部特征描述子,使用SIFI特征描述子对于有遮挡的物体识别率也较高。2005年,Navneet Dalal 和 Bill Triggs利用方向梯度直方图(Histogram oriented Gradient,HOG)在计算机视觉和图像处理中进行物体检测的特征的描述,通过统计和计算图像局部区域的梯度方向来构成特征。基于深度学习的目标检测是基于卷积神经网络的特征提取方法,该方法有三个特点,局部连接,参数共享,平移不变形。该方法可以分为两类,一类是two-stage检测算法,该方法将检测问题分为两个阶段,首先选取疑似区域(Region proposals),然后对疑似区域进行识别,比较典型的算法是RCNN,Fast-RCNN,Faster-RCNN[1];另一类是one-stage,直接对图像进行回归产生物体的类别和坐标位置,比较典型的算法是YOLO和SSD[3]。
1.2.2 移动端识别国内外研究现状
随着智能手机的兴起和5G网络的商用,越来越多的移动设备和可穿戴设备的CPU处理速度得到提高,由于移动端相比PC端来说具有方便快捷的特点,人们也有想法将电脑端的深度学习模型移植到手机端,2017年,Facebook在开发者大会上退出caffe2框架,具有轻量级和可移植等优点。Tensorflow也在同年推出tensorflow lite,一种移动端的深度学习框架。与国外相比,中国也在开展深度学习的移动端研究,2017年7月,腾讯实验室发布NCNN,可以将深度学习算法移植到手机端,无论是对深度学习感兴趣的学生还是从事与人工智能的从业者都可以非常方便的部署网络。9月25日,百度开源mobile-deep-learning(MDL),它是一款基于CNN实现的移动端框架。综合各个框架的优点的缺点,本文将使用tensorflow lite框架将训练模型移植到安卓手机端进行动物识别。
1.3本文的主要研究内容
本系统是基于tensorflow深度学习框架以及tensorflow lite移动端框架的动物实时识别APP,可以识别鸟,猫,狗,马,羊,牛,大象等十类动物。此APP的开发分为四个步骤,第一步:数据采集,第二步:数据预处理,第三步:调参训练模型,第四步:将模型部署到Android手机端。
首先,数据采集阶段通过火狐浏览器搜索对应的动物图片,待加载到600-700张的时候,使用火狐浏览器的插件图片助手(ImageAssintant)批量图片下载器将网页中加载的图像全部下载到对应的文件夹中,以此类推将动物数据集扩充。
数据预处理阶段是对数据采集阶段采集到的数据进行清洗、标注工作。数据清洗指的是将错误的,与图片名称不符的图片删除。数据标注则是使用标注软件LabelImg将图片中含有对应的目标打上对应的标签,生成xml文件,然后将xml文件转成csv文件,再将csv文件结合jpg文件转成tfrecord二进制格式。使用预训练模型进行微调,训练模型阶段在github上下载tensorflow 的models源码以及coco预训练模型,使用ssd_mobilenet_v2_coco网络对预训练模型进行迁移学习,修改初始学习率,是否使用dropout防止过拟合,求各个bbox的kmeans来修改bbox的宽高比等超参数。最后将模型部署到Android手机端,将ckpt文件通过toco转成方便在手机端移植的tflite格式,使用Android studio编译app。本文的具体内容安排如下:
第一章,绪论。介绍基于深度学习的动物识别技术的研究目的与意义,通过目标检测以及移动端识别技术两个方面介绍国内外研究现状,最后概述了本文所研究的内容和达到的目标。
第二章,动物数据集的构建。描述所要识别的动物种类、数据集分布,使用数据增广技术扩充数据集,将数据集转换成训练数据需要的格式。
第三章,本章首先介绍卷积神经网络的基本构成和几个基础的CNN模型,接下来介绍目前流行的两类目标检测算法,着重介绍本文使用的ssd网络。然后对本文所用的移动端框架Tensorflow Lite将ckpt模型转换成手机端使用的tflite模型,最后做实验得出详细的目标检测指标,FP,TP,FN,Percison,Recall,F1-score。
第四章,将已经训练好的模型移植到手机端,在移动端加载模型,调节一系列参数,像是iou的阈值,score的阈值等等,输出APP到手机端,使用手机对物体进行实时检测。
第五章,总结与展望。总结了本文的研究成果以及对于未来的深度学习技术的向往。
第二章 动物数据集的构建
2.1 数据集介绍
数据,网络,算力并称为深度学习的三大基础要务。数据是排在第一位的,模型所达到的上线不可能超过数据的上线。在深度学习任务中,只有拥有大量的数据才可以出色的完成研究任务。
2.1.1 计算机视觉相关数据集
MNIST手写字体数据集,由LeLun建立,是深度学习的经典入门demo,由6万张训练图片和1万张测试图片构成,每张图片的尺寸为28px*28px黑白色图片,如图2-1所示,这里的颜色为0-1的浮点数,越靠近1,则颜色越靠近黑色,这些图片是采集自不同人的手写字体。MNIST图片样例与标签以二进制的方式保存在压缩文件中,如图2-2,图2-3所示。
 图 2-1 MNIST 数据集图片示例
图 2-1 MNIST 数据集图片示例
 图 2-2 MNIST 数据集 训练集图像二进制格式
图 2-2 MNIST 数据集 训练集图像二进制格式
 图 2-3 MNIST 数据集 训练集标签二进制格式
图 2-3 MNIST 数据集 训练集标签二进制格式
著名的ImageNet数据集是由李飞飞教授建立,她现在是斯坦福大学的计算机科学系教授同时也是谷歌云人工智能和机器学习的首席科学家,ImageNet数据集由1400w+张图片,分为27个大类和2w+个小类,如图2-4所示,只能用于非商业研究和教学用途。与ImageNet数据集相关的是著名的ILSVRC竞赛,许多著名的机器学习算法脱颖而出,像是Alexnet,ZFNet,GoogLeNet,Resnet等等,不管在图像识别还是目标检测上都有很大的提高,在ILSVRC上一战成名成了很多CV从业者的梦想,ImageNet数据集的的标签与数量,如表2-1所示。
 图 2-4 ImageNet数据集图片
图 2-4 ImageNet数据集图片
 表 2-1 ImageNet数据集标签与数量分布情况
表 2-1 ImageNet数据集标签与数量分布情况
PASCAL VOC数据集由Mark Everingham (University of Leeds)、Luc van Gool等人创建,由1.7w+张图片组成,分为20个类别。PASCAL VOC竞赛与ILSVRC竞赛的影响力差不多。PACSAL VOC数据集图像数据如图2-5所示,PACSAL VOC数据集标签数据如图2-6所示。从2005年到2012年一共举办了8届,包含了物体分类(object classication),目标检测(object detection)以及图像识别(Image recognition)、图像分割(Image Segmentation)等任务,后来逐渐被ILSVRCs所替代。
 图 2-5 PACSAL VOC数据集图像数据
图 2-5 PACSAL VOC数据集图像数据
 图 2-6 PACSAL VOC数据集标签数据
图 2-6 PACSAL VOC数据集标签数据
其他数据集是包含一些小众的图像数据,并不是说不重要,是用的比较少,没有将之作为评判算法好坏的标准数据集。
 表 2-2 其他图像数据集
表 2-2 其他图像数据集
2.1.2 本文动物数据集的构建
本文中未使用公开数据集中的动物图片数据,使用网页图片提取器根据动物名称关键字抓取网页中的动物图像。使用的数据集由10种动物组成,分别是elephant(大象),tortoise(乌龟), dog(狗), cat(猫),cow(牛),bird(鸟),giraffe(长颈鹿),zebra(斑马),tiger(老虎),panda(熊猫)。
 图 2-7 鸟
图 2-7 鸟
 图 2-8 大象
图 2-8 大象
为了解决数据不均衡问题,尽量保持每个类别的数量相似,动物数据集的类别和类别数量如图2-11所示。
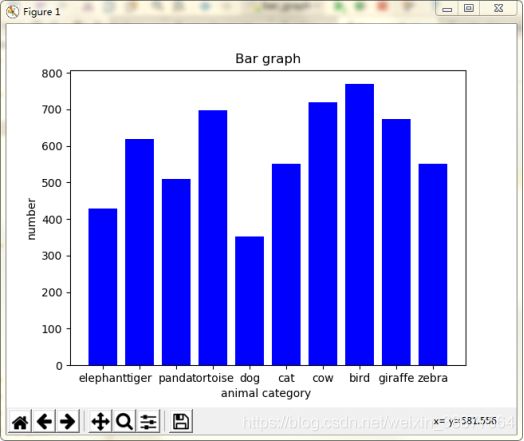 图 2-9 动物数据集数量分布标题
图 2-9 动物数据集数量分布标题
2.2 数据预处理
2.2.1 数据清洗
顾名思义,如果清洗数据分析中的结构化数据,是指发现并纠正结构化数据中错误,检查数据之间的关系是否一致,将数据中的无效值和缺失值等错误数据删掉。而在图像处理中,是指删除数据集中与目标不匹配的数据,如与目标不匹配的图片,卡通图片,目标占图像比较小的图片,动态图等等,如图2-10,图2-11所示。保证训练数据的准确性,因为训练出的模型不可能达到训练数据的上线。
 图 2-10 卡通图片
图 2-10 卡通图片
 图 2-11 斑马错误图片
图 2-11 斑马错误图片
2.2.2 数据标注
机器学习分为有监督学习,无监督学习和强化学习。其中计算机视觉中的目标检测技术属于监督学习,即从给定标注好的训练数据中搭建网络学习出模型的权重(即模型的参数),当一个新的图片进行预测时,可以根据训练出模型的参数得到新输入图片的目标位置以及目标类别。有监督学习的训练集需要人工手动标注,即真值。有监督学习最常见的就是分类和回归,本文所使用的目标检测方法使用的数据标注工具为LabelImg,界面如图2-12所示,使用快捷键拉框标出前景目标的位置和类别。以此类推,每张图片都要标注出目标所在的位置和类别信息。
 图 2-12 数据标注软件--LableImg
图 2-12 数据标注软件--LableImg
每张图片标注完后会生成对应的xml文件,xml文件中包含每张图片的名称、路径、所含目标位置和类别信息,如图2-13所示。
 图 2-13 xml文件所含信息
图 2-13 xml文件所含信息
标注好的xml文件会保存在LabelImg的change save dir目录,可以对这个目录进行修改保存图片到目录中,但默认是与jpg图片同目录,这样方便后期在生成训练数据所需要的tfrecord时简单快捷。
2.2.3 数据增广技术
数据增广主要是用来防止过拟合,网络结构越深,需要学习的参数数量也会增加,模型就会越复杂。过拟合是当训练数据过少时,如果模型中包含过多的参数将会拟合训练数据的所有特点,在识别验证集的时候泛化能力减弱,说白了就是只认得训练数据中的图片而不认识新图片。因此在这种情况下,为了防止过拟合现象的产生,丰富图像数据集,更好的提取图像特征,需要对训练数据进行数据增广。数据增广常用的方法包括:
·Color Jittering:色彩抖动,对图像亮度,饱和度,对比度进行调整
·PCA Jittering:主成分分析,计算RGB三通道的均值和标注差,然后计算协方差矩阵得到对应的特征值和特征向量。
·Random Scale:随机尺度变化
·Random Crop:采用随机图像裁剪缩放
·Horizontal/Vertical Filp:水平或者垂直翻转
·Shift:平移变换
·Rotation/Reflection:旋转和仿射变换
·Noise:高斯噪声,模糊噪声处理
·Lable Shuffle:类别不平衡数据增广
本文在训练ssd_mobilenet_v2网络时采用的方法是随机水平翻转翻转和随机裁剪,只改变了图片的水平信息,如果将图片上下翻转的话会改变数据分布,模型会识别出一些非正常的图片。
2.3 数据格式转换
2.3.1 xml转csv格式
此步是读取2.2.2小节的xml文件内的 ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax'],将其批量写入到csv文件中,写到csv文件的格式如图#所示,图2-14为xml文件转成csv文件的代码:
import os #导入一系列第三方包
import glob
import pandas as pd
import xml.etree.ElementTree as ET
def xml_to_csv(path):
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
print(xml_file)
tree = ET.parse(xml_file) #解析每个xml文件
root = tree.getroot()
for member in root.findall('object'): #读取每张图片的object
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[0].text,
int(member[4][0].text),
int(member[4][1].text),
int(member[4][2].text),
int(member[4][3].text)
)
cls = member[0].text
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
#每个框的文件名,宽度,高度,类别,xmin,ymin,xmax,ymax
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df
def main():
image_path = os.getcwd()
xml_df = xml_to_csv(image_path) #
xml_df.to_csv('animal_test.csv', index=None) #将xml文件信息转换成csv文件
print('Successfully converted xml to csv.')
main() 图 2-14 csv文件格式
图 2-14 csv文件格式
2.3.2 csv转tfrecord格式
在训练文件的时候会将文件分为训练集,测试集和验证集,往往每一个数据集合会分在一个文件夹内以方便操作,如果是数据量比较少的情况下按照分文件夹的格式内存是可以承受的,但是深度学习以需要学习的数据量大著称,如果每个文件夹中保存着成千上万张图片或文本文件,存储方式是散列存储,不仅占用磁盘空间,生成tfrecord文件不仅处理了这个问题,而且还将数据转换成“protocol Buffer”二进制格式,尤其是遇到数据量大的情况,可以转换成多个tfrecord文件分批次读取数据来提高效率。训练集和测试集的样本分布如表2-3所示。
表 2-3 训练集测试集图片数量与tfrecord文件
|
|
样本数量 |
tfrecord文件大小 |
| 训练集 |
5654张 |
179.63M |
| 测试集 |
478张 |
15.77M |
由图片和csv文件生成tfrecord代码如下所示:
from __future__ import division
from __future__ import print_function
from __future__ import absolute_import
import os #导入一系列第三方包
import io
import pandas as pd
import tensorflow as tf
from PIL import Image
from object_detection.utils import dataset_util
from collections import namedtuple, OrderedDict
flags = tf.app.flags
flags.DEFINE_string('csv_input', '', 'Path to the CSV input')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
FLAGS = flags.FLAGS
def class_text_to_int(row_label): #定义函数,每个类别转换成不同的数字
if row_label == 'elephant':
return 1
elif row_label == 'tiger':
return 2
elif row_label == 'panda':
return 3
elif row_label == 'tortoise':
return 4
elif row_label == 'dog':
return 5
elif row_label == 'cat':
return 6
elif row_label == 'cow':
return 7
elif row_label == 'bird':
return 8
elif row_label == 'giraffe':
return 9
elif row_label == 'zebra':
return 10
else:
print(row_label)
None
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
def create_tf_example(group, path):
with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = group.filename.encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class']))
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def main(_):
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
path = os.getcwd()
examples = pd.read_csv(FLAGS.csv_input)
grouped = split(examples, 'filename')
for group in grouped:
tf_example = create_tf_example(group, path)
writer.write(tf_example.SerializeToString())
writer.close()
output_path = os.path.join(os.getcwd(), FLAGS.output_path)
print('Successfully created the TFRecords: {}'.format(output_path))
if __name__ == '__main__':
tf.app.run()本章介绍了MNIST,ImageNet,PASCAL VOC等数据集的来源以及各个数据集的标注方法等,然后介绍了本文动物数据集的采集方法,数据清洗,数据标注以及将jpg和xml文件转换成tfrecord文件用于数据训练,最后统计了一下每类数据的数量。
第三章 基于深度学习的动物识别
3.1 搭建深度学习环境
本文使用tensorflow框架,Tensorflow是高阶的机器学习库,用户可以方便的设计神经网络结构,而不用自己亲自写C语言和CUDA代码,不需要用户求反向传播的梯度,核心代码是由C++编写,Tensorflow也有内置的TF.Learn和TF.slim等上层组件可以帮助网络更快的构建,同时Tensorflow不只局限于神经网络,而且数据流图支持算法表达,可以轻松实现深度学习以外的机器学习知识,Tensorflow除了支持常见的卷积神经网络,循环神经网络外。还支持深度强化学习乃至其他密集型科学计算。使用它的用户可以将训练好的模型部署到多种硬件设备,操作系统平台上,不仅支持Inter和AMD的CPU,而且支持Linux和Mac。Tensorflow刚开始的时候只支持单机,没有官方和其他深度学习框架做对比。各个深度学习框架在AlexNet上的性能对比如表 3-1所示。
 表 3-1 各深度学习框架在AlexNet的性能对比
表 3-1 各深度学习框架在AlexNet的性能对比
Google在2016年开园Tensorflow Serving,这个组件可以将Tensorflow训练好的模型导出,部署成服务。Tensorflow可以使用它实现机器学习的全部流程,从训练数据,调试参数,到打包模型,最后部署服务,是一个从研究到生产的整条流水线。
3.1.1 Anaconda、Pycharm、python介绍与安装步骤
Anaconda的优点非常明显,它可以节省时间来高效开发,分析不同环境下的不同。Anaconda通过虚拟环境的管理,第三方工具包工具包,不同python版本,不仅可以简化工作流程,提高开发效率,而且方便读者对虚拟环境进行安装,更新,卸载以及在联网的前提下非常方便的安装第三方包,同时可以对虚拟环境进行统一的管理。Pycharm是Python的集成开发软件,分为专业版和社区版,社区版完全可以用来编程,工具齐全,帮助开发者提高工作效率。Python是一门面向对象的动态类型语言,刚开始被使用时的作用是编写自动化脚本,后来越来越多用来独立的大小项目的开发。Python是“优雅,明确,简单”的代表,需要注意的是写代码时要逻辑清晰,思维缜密,这样才可以发挥python语言的强大功能。
前两种软件的安装方法较为简单,直接在官网找到下载链接下载即可。Python可以在Anaconda建立虚拟环境的时候安装。
3.1.2 Nvidia驱动+Tensorflow1.12+cuda9.1+cudnn安装步骤
一、显卡驱动的安装
1、下载与服务器中Nvidia显卡所对应版本的驱动,到官网
http://www.geforce.cn/drivers
2、屏蔽开元驱动nouveau
方法一:在运行nvidia驱动安装程序时,会提示是否需要屏蔽,选yes即可(需要重启)
方法二:编辑blacklist.conf,sudo gedit /etc/modprobe.d/blacklist.conf,添加如下内容(不需要重启)
blacklist vga16fb
blacklist nouveau
blacklist rivafb
blacklist nvidiafb
blacklist rivatv
3、重启电脑
4、cd到驱动文件所在的目录,关闭图像界面
$ sudo service lightdm stop
5、在当前目录下安装显卡驱动,步骤如图3-1所示
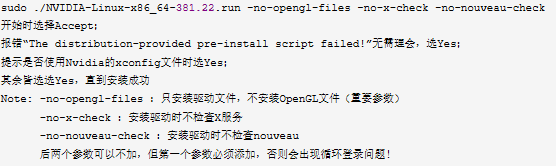 图 3-1 安装显卡驱动
图 3-1 安装显卡驱动
6、终端运行”nvidia-smi”,若出现显卡相应信息,则安装成功
二、安装cuda8.0
1、确定自己电脑的系统信息,以Ubuntu16为例,到官网下载https://developer.nvidia.com/cuda-downloads下载安装与tensorflow对应的版本。
2、下载后再当前目录运行安装
$ sudo ./cuda_8.0.61_375.26_linux.run.26_linux-run
安装过程中一直选择yes直到提示是否安装Nvidia驱动时选择No,因为刚才已经安装过Nvidia驱动。
3、安装成功,此时需要更改环境变量,将以下文件写入~/.bashrc文件的尾部
export PATH=/usr/local/cuda-8.0/bin${path:+:${path}}
export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64${LD_LIBRARY_PATH:+${LD_LIBRARY_PATH}}
执行$ source ~/.bashrc 使设置生效
4、设置环境变量
$ sudo gedit /etc/profile
在profile文件的末尾加入
export PATH=’/usr/local/cuda/bin:$PATH’
以上操作的作用是环境变量生效
$ source /etc/profile
5、设置动态链接库
$ sudo gedit /etc/ld.so.conf.d/cuda.conf
末行添加 /usr/local/cuda/lib64
执行链接库文件使其生效
sudo ldconfig
6、测试cuda的例子
$ cd /usr/local/cuda/samples/1_Utilities/deviceQuery
$ make
$ sudo ./deviceQuery
三、安装Cudnn
1、cuda和cudnn以及tensorflow的版本是对应的,需要确定已经安装的cuda版本,然后到cudnn官网下载相应的文件。
2、下载后进行解压
3、进入include文件夹下
$ sudo cp cudnn.h /usr/local/cuda/include
4、进入lib64文件夹,然后执行命令
$ sudo cp lib* /usr/local/cuda/lib64
5、在终端执行
$ cd /usr/local/cuda/lib64/
$ sudo rm -rf libcudnn.so libcudnn.so.6 #删除原有的动态链接文件
$ sudo ln -s libcudnn.so.6.0.21 libcudnn.so.6 #生成软链接,注意6.0.21中为lib64中原有的软链接名
$ sudo ln -s libcudnn.so.6 libcudnn.so #生成软链接
3.1.3 安装第三方库的几种方法
1、使用pip第三方工具,需要安装pip
pip install tensorflow-gpu
pip install opencv-python
有时下载速度比较慢会导致安装失败,所以使用清华镜像源
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorflow-gpu,速度可达10M/s
2、使用conda管理工具
conda install tensorflow-gpu
3、使用whl文件进行安装
此方法多用于离线安装第三方包,可以提前找有网络的地方下载whl文件,whl文件可以到https://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml 网站下载,下载之后进入whl文件所在路径,可以直接使用pip install *.whl文件进行安装。
3.2 卷积神经网络相关知识
3.2.1 神经元结构
卷积神经网络的结构与高中时学的神经元传导类似,图3-2为神经元的传导过程。
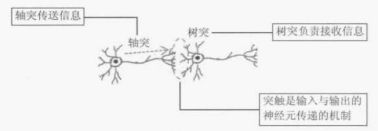 图 3-2 神经元的传导过程
图 3-2 神经元的传导过程
轴突传送信息:神经元的一个细长的轴突,以电流方式将信息传递给另一个神经元,轴突最长可达一米,最短只有毫米的十几分之一。
树突接收信息:树突主要的功能是接收其他神经元传来的电化学信息,再传递给本身的细胞。
突触是输入和输出的神经元传递的机制:输入与输出神经元之间的结构为突触,神经元与神经元之间通过释放化学递质来传递信息,当电压达到临界值时,就会通知轴突传动电脉冲到接收神经元。图3-3为用数学公式来仿真神经元的传导过程。
 图 3-3 用数学公式来仿真神经元的传导过程
图 3-3 用数学公式来仿真神经元的传导过程
 图 3-4 以数学运算模拟突触机制
图 3-4 以数学运算模拟突触机制
3.2.2 卷积神经网络
神经网络的一个分支是卷积神经网络,但是卷积神经网络依然是层级网络,只是隐藏层之间的形式和功能做出了变化,并在传统神经网络上做了相应改进。卷积神经网络同样是一种前馈神经网络,它只是局部的感知图像的特征而并非全连接,对大规模检测识别性能的性能都表现良好,尤其是对图形图像处理效率极高。
卷积网络有两个比较大的特点,一是卷积网络有至少一个卷积层,用来提取特征;二是卷积网络的卷积层通过权值共享的方式进行工作,大大减少权值w的数量。
卷积神经网络包括卷积层,池化层,激励层(激活函数)以及全连接层。
卷积层(Convolutional layer):取输入图像的高维特征,生成特征图,卷积层的两个特点是局部感知,权值共享。
池化层(Pooling layer):取区域的平均值或最大值,对前一层生成的特征图进行压缩,一方面减少图像复杂度,使特征图变小,简化网络计算复杂度。
激励层(activation):激活函数实际上是一个非线性函数,如果不加入非线性函数的话,输出与输入的关系一直是线性关系,加入激活函数之后可以增强网络的表达能力,几乎可以逼近任何函数。比较常见的激活函数有sigmoid、tanh、relu等。各激活函数对比如表3-2所示。
表 3-2各种激活函数对比
|
|
数学解析式 |
函数形状 |
特点 |
缺点 |
| Sigmoid |
|
|
能够把输入的连续实值变换为0到1之间 |
反向传播过程中容易出现梯度消失和爆炸,而且权重会往一个方向更新,收敛慢 |
| tanh |
|
|
解决权重往一个方向更新收敛慢的问题 |
反向传播过程中容易出现梯度消失和爆炸 |
| relu |
|
|
计算速度快 收敛速度快于sigmoid和relu |
参数初始化过程可能导致神经元不被激活,学习率太高参数更新大 |



全连接层(Fully Connected layer):将所有的特征连接在一起,将输出值送给类似于softmax分类器。Softmax分类器将每一个类别的概率值从大到小输出,取概率最大的索引即为目标的类别信息。
3.2.3 典型的CNN网络
一、Lenet
LeNet是基于CNN的深度学习框架,最早由Yann LeNet和Yoshua Bengio提出,手写识别字体就是用LeNet的网络结构,其网络结构如图3-5所示。
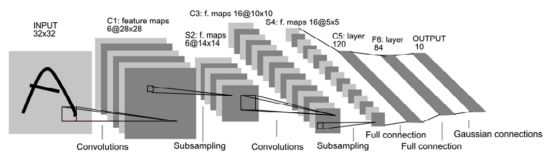 图 3-5 LeNet网络结构示意图
图 3-5 LeNet网络结构示意图
C*:卷积层(convolution layer)
特点:(1)拓扑结构:输入层相邻节点卷积后仍然相邻
(2)稀疏连接:每个像素仅与输入层的相邻节点连接
(3)权值共享:特征图共享相同尺寸的卷积核,但是卷积核里的参数初始化不同
S*:采样层(pooling layer)
F*:全连接层(Fulley connected layer)
二、Alexnet
Alexnet是2012年ImageNet大赛的冠军获得者hiton和他的学生设计的网络结构,首次应用ReLu激活函数和Dropout防止过拟合,Alexnet网络验证了ReLu激活函数在神经网络隐藏层较多的情况下超过sigmoid激活函数的性能,成功解决了之前在LeNet中未解决的梯度弥散问题,而且使用dropout随机扔掉神经元,可以防止过拟合现象,Alexnet中主要是在最后的全连接层使用dropout扔掉50%的神经元,AlexNet使用最大池化,但是其他的CNN网络的是平均池化,平均池化会增加图像的模糊化效果,最大池化可以避免此问题,最后使用水平翻转和随机裁剪的数据增广技术和GPU计算加速。Alexnet的网络结构如图3-6所示。
 图 3-6 Alexnet网络结构
图 3-6 Alexnet网络结构
三、Googlenet
2014年Christian Szegedy提出的全新网络结构,在此之前Alexnet和GoogleNet是通过增加网络层数来实现好的效果,但单纯的增加神经网络的层数会带来很多副作用,比如过拟合,梯度爆炸等。Inception能利用计算资源,使用相同算力服务器的情况下可以提取到更多的特征来提高精度。GoogleNet的网络结构共有22层,由于网路结构太大,整理出一个网络结构表格,如表3-3所示。网络最后的全连接层除了最后一个全连接其他的由全局平均池化代替,降低了参数量,其参数量是VGG16的1/27,AlexNet的1/12。使用1*1卷积,为了减少参数,降维,Inception通过3*3和5*5后加入1*1来减小计算,增强了神经网络的表达能力。
 表 3-3 GoogleNet(Inception v1)网络结构
表 3-3 GoogleNet(Inception v1)网络结构
四、Resnet
Resnet网络是何凯明于2015年提出的网络结构,作者通过增加网络结构的深度来提高模型的准确率。其论文的核心是解决由于隐藏层深度过深导致的模型性能退化的问题。何凯明作者通过一系列的实验证明了网络深度对于识别任务来说影响很大,如果单纯加深网络的深度,在coco数据集上取得了相对28%的提升。对于之前提高的AlexNet,GoogleNet等,如果这些网络单纯的增加网络的深度会导致梯度爆炸或梯度消失。对于该问题的解决方法是使用正则化项和Batch_Normalization,随着网络层数的增加在训练集上的准确率收敛甚至下降,这不是过拟合问题,而是退化问题,因为过拟合在训练集中的准确率是上升的,这便提出了深度残差网络,如果深层后面的层是恒等映射的话,网络结构便退化为一个简单的结构,所有直接将网络设计为H(x)=F(x)+x,如图3-7所示,可以转换为学习一个残差函数F(x)=H(x)-x,只要F(x)=0,就构成了一个恒等映射H(x)= x,这样拟合残差就会更容易。神经网络层数不同时resnet的的网络结构如表3-4所示。
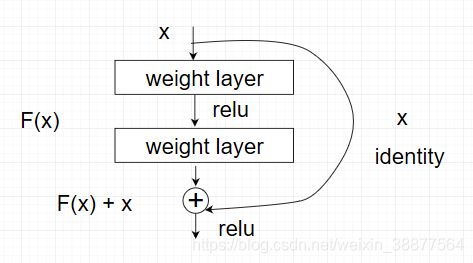 图 3-7 resnet中的残差块
图 3-7 resnet中的残差块
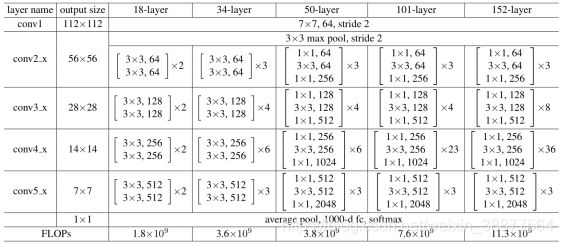 表 3-4 层数不同的resnet网络结构
表 3-4 层数不同的resnet网络结构
3.3 目标检测算法
3.3.1目标检测介绍
在计算机视觉中,关于图像识别有四大任务如图3-8,即图像分类,定位,检测与分割,图像分类是给定一张图片判断其中存在什么类别的物体,目标定位是定位出这个目标的位置,目标检测是定位出这个目标的位置并且知道目标属于什么类别,目标分割分为实例分割和语义分割,用于解决每一个像素属于哪个目标或场景的问题。在此基础之上延伸出目标跟踪,行人重识别等更加高级的任务。
2012年,Alex等人提出了Alexnet网络,图像分类的准确性有了大幅度提高,目标检测的大部分框架都迁移自图像分类,故有学者将深度学习应用到目标检测领域。根据检测思路的不同目标检测框架可以分为两类。详细会在3.3.3节和3.3.4节介绍。
 图 3-8 计算机视觉四大任务
图 3-8 计算机视觉四大任务
本文主要做的任务是目标检测,它是一系列广泛的视觉应用的前提,如实例分割,人体骨架,人脸识别以及高级视觉推理。目前基于CNN的目标检测依靠bbox回归和非极大值抑制(NMS)来定位物体,目标检测结合目标分类和目标定位,目前最主要的目标检测器是基于两层框架,被描述为多任务学习问题。其检测流程如下
- 从背景中分离出前景区域并为目标贴上对应的标签;
- 回归一组系数通过NMS或者其他计算预测结果和gt之间的度量方法;
- 通过NMS过程取出冗余的边界框;
3.3.2 IOU、NMS等技术介绍
Intersection over Union(IOU)是一种度量标准,用来度量预测的bbox(bounding box)与gt(ground truth)之间的关系,详细的公式如图3-9所示,目标检测的评价指标与图像分类的评价指标不大一样。
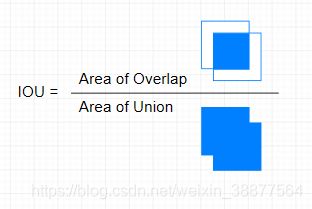 图 3-9 IOU计算公式
图 3-9 IOU计算公式
IOU相当于两个区域的交集除以两个区域的并集,一般来说,IOU>0.5就可以认为是一个不错的结果。图3-10列出三种不同真值与预测值的交并比。
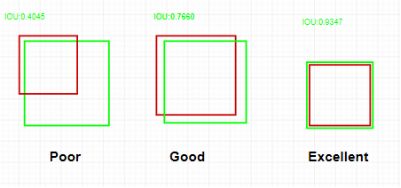 图 3-10 预测与真值之间的IOU关系
图 3-10 预测与真值之间的IOU关系
Non-Maximum Suppression(NMS),非极大值抑制,其作用是取出具有相同帧值的预测框,并选出分数最高的框,将非极大值的元素进行抑制。例如在人脸检测中,不管是传统的滑窗法还是基于faster-rcnn的RPN层提供的Region Proposal每个框会获得一个分数,但是对与一个相同的物体可能会有多个框将其框出。如图3-11所示
 图 3-11 非极大值抑制效果图
图 3-11 非极大值抑制效果图
NMS的过程即是去除冗余的检测框进而保存最好的一个。在目标检测中产生Region Proposal后使用分类网络给出每个框的分类置信度,然后使用bbox回归修正框的位置,最后使用NMS抑制冗余的框进而保留分类置信度最大的bbox。详细的目标检测中应用NMS的如图3-12,实现NMS的算法如图3-13所示。
 图 3-12 目标检测中应用NMS的过程
图 3-12 目标检测中应用NMS的过程
 图 3-13 NMS算法
图 3-13 NMS算法
3.3.3 RCNN系列
目标检测在传统方法中使用滑动窗口法进行定位,但是需要的计算量太大而且会有很多负样本的信息需要计算,随着深度学习技术的发展,有一种新的基于区域检测的方法被提出,此方法即为R-CNN方法,它只针对一部分的区域进行检测,这种方法的第一步在原图上产生2000个左右的候选区域,产生候选区域所使用最多的方法是选择性搜索(selective search),以下简称SS。SS的大致流程如下所示:
(1)生成初始预测框的区域集合;
(2)计算区域集合中所有与预测框相邻区域的相似度,其中的相似度综合考虑了预测框中的颜色,尺寸和纹理等信息;
(3)将相似度高的两两预测框进行相似度对比,并移除其中一个,以此类推;
(4)重新计算合并的区域和其他所有区域的相似度并执行合并过程直到结束[9];
产生候选区域集合后对候选集合内的大小进行归一化处理,并将其作为CNN网络的输入。第二步是利用CNN网络提取特征图。最后通过线性SVM分类器进行分类和回归。然而对于RCNN网络对Region Proposal的特征提取速度慢的缺点,提出了SPP-net,其中的SPP层采用空间金字塔结构,改变网络的输入图片的大小,可以输入任意尺寸的图片。
在此之后提出了Fast-rcnn,通过ROI-Pooling层对SPP层空间金字塔的思想进行简化。ROI-Pooling层的处理流程如图3-14所示。
 图 3-14 ROI Pooling计算过程
图 3-14 ROI Pooling计算过程
(1)原始图像尺寸:800*800 ,原始图像Region Proposal尺寸: 665*665
(2)VGG 16 卷积得到Feature map size: 800/32 = 25,Feature map RP : 665/32 = 20.78 经过量化向下取整为20*20
(3)经过ROI pooling后固定特征图的尺寸: 7*7 ,将20*20映射成49个同等大小的区域,每个区域为20/7 = 2.86,向下取整第二次量化每个小区域为2*2。
(4)对这2*2 进行最大池化取出最大像素值,最后输出49个像素,组成7*7的特征图,经过两次向下取整的量化,原本20*20的疑似区域硬被降到14*14,像素丢失了1/3,
再将其映射回原图中会造成更大的定位误差。在feature map中有1像素的误差缩放到原图上会有32个像素的误差,何况在ROI-pooling中有两次量化,导致等比例缩放时空间量化粗糙影响准确定位。Faster-rcnn在Fast-rcnn的基础上将SS替换为区域推荐网络(Region Proposal Network,RPN),进一步提高了检测速度。R-CNN系列框架最新提出的是Mask-rcnn,它针对Faster-rcnn中的ROI-pooling问题的缺点,提出ROI-Align算法,使用双线性插值代替直接对其进行量化操作。ROI-Align算法流程如3-15所示
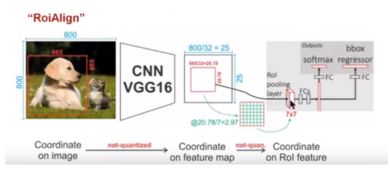 图 3-15 ROI Align计算过程
图 3-15 ROI Align计算过程
(1)前面卷积过程原理与ROI pooling类似,得到Feature map,其中的RP为20.78,直接取浮点数,不会被量化。经过ROIAlingn后Feature Map的尺寸被固定为7*7,20.78/7 = 2.97,pooling后的feature map被分成7*7=49个区域,每个区域的面积为2.97*2.97
(2)采样的点数为4,如图3-16所示,在上图中只选择中心点位置的像素,但是在ROI Pooling对于每个2.97*2.97的小区域,需要平分四份,每一份取其中心点位置,而中心点位置的像素,采用双线性插值法进行计算,这样,就会得到四个点的像素值。
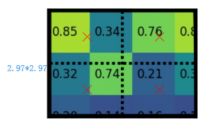 图3-16 双线性插值计算N个点的像素值
图3-16 双线性插值计算N个点的像素值
(3)上图中,四个红色‘×’的像素值是通过双线性插值算法计算得到的
(4)取四个像素值中最大值作为这个小区域(即:2.97*2.97大小的区域)的像素值,以此类推,同样是49个小区域得到49个像素值,组成7*7大小的feature map。最后总结了一个RCNN系列的不同版本的网络结构如图3-17所示。
 图 3-17 RCNN系列框架网络结构图
图 3-17 RCNN系列框架网络结构图
3.3.4 YOLO/SSD系列
YOLO(You Only Look Once)将目标检测看成回归问题,不同于RCNN系列的检测框架,YOLO使用整张图片的特征,将输入图像划分为S*S个网格,每个网格只负责检测中心落在该网格的目标,每个网格分别计算bbox的位置和置信度。之所以叫one stage,它可以一步检测所有区域中的类别概率、边界框左上角和右下角的坐标以及置信度的预测。YOLO的检测速度可以满足实时性的要求,但是精度相对于Two stages网络来说下降了许多。
SSD(Single Shot Detector)在YOLO回归思想的基础之上,提出了Prior box选框机制。YOLO在卷积层后接全连接层,只有高层特征被利用,所以对小目标的检测结果较差。为提升小目标的检测准确率ssd网络设计了特征金字塔(Pyramidal Feature Hierarchy),可以对不同大小的特征图进行融合,提升了模型对于不同尺寸大小的目标的泛化能力。本文使用ssd结合mobilenetv2对自己构建的动物数据集进行训练识别的过程[4]。YOLO和SSD网络结构之间的差异如图3-18所示。
 图 3-18 YOLO与SSD的网络结构
图 3-18 YOLO与SSD的网络结构
SSD在训练过程中使用了几种不同的技巧,一是使用数据增强,数据增强方法对模型的影响比较大,本文使用随机裁剪和水平随机翻转的方法,其论文中提到COCO数据集大约有6.7% mAP效果的提升。二是取conv4_3的特征图,在基础网络部分的特征图分辨率较高,原图中的对于小目标的检测效果更好,可以用来检测小目标,这也是ssd相对于yolo来说小目标识别效果更好的原因。三是使用三种比例的默认框,挑选合适形状的默认框可以提高召回率,在YOLO中,每个单元格预测多个框,但是真实目标的宽高比是不固定的,它需要在训练过程中找到目标的形状,而SSD借鉴了Faster-rcnn中的anchor思想,首先设定好特定比例的框,在SSD中采用3中比例的先验框,分别是1:1,1:2,1:3。使用此方法在比只是用正方形的默认框的效果好2.9%,四是使用atrous卷积,与YOLO最后采用的全连接层不同的是,SSD直接采用卷积的形式提取融合不同层的特征图来提取检测结果,此卷积方法还没有做过多的了解。图3-19显示了SSD在训练过程中使用不同的训练技巧得到的结果。
训练过程中,首先要确定真值与哪个先验框匹配,与之匹配的先验框所对应的边界框负责预测它。SSD中的先验框与真值的匹配规则有两点,一是对于图片中的真值,需要找到一个与其IOU最大的先验框,如果先验框没有与真值匹配,那么此先验框为负样本,在一张图像中的负样本数量要远大于正样本数量,所以采用hard_example_miner对正负样本进行均衡,使其比例均衡在正样本:负样本在1:3左右,本文中使用focal loss对正负样本不均衡问题进行处理,着重训练那些困难样本,对于容易识别的目标降低其权重。
 图 3-19 SSD网络训练技巧
图 3-19 SSD网络训练技巧
3.3.5 评价指标
模型训练完成后如何从多个模型中选择模型取决于它的评价指标的高低,这需要构建相同的验证集,对验证集进行标注工作,计算模型预测的结果与gt之间的IOU大小,如果IOU大于某个阈值则判断为正样本。这便提到了几个不同的评价指标。
(1)TP:True Positive Ground Truth为正样本,detection为正样本的数量
(2)FP:False Positive Ground Truth为负样本,detection为正样本的数量
(3)FN:False Positive Ground Truth为正样本,detection为负样本的数量
(4)Percision:TP/(TP+FP)
(5)Recall:TP/(TP+FN)
(6)F1-score: 2*TP/(2*TP+FP+FN)
编写python代码实现每个类别的TP,FP,FN,percison,recall,F1-score评价指标,详细代码如下所示。
from __future__ import absolute_import #导入一系列第三方包
from __future__ import division
from __future__ import print_function
from __future__ import unicode_literals
import os,cv2,glob
import numpy as np
import tensorflow as tf
import xml.etree.ElementTree as ET
from PIL import Image
classDict={1:'elephant',2:'tiger',3:'panda',4:'tortoise',5:'dog',6:'cat',7:'cow',8:'bird',9:'giraffe',10:'zebra'}
class Predictor(object): #定义predictor类
def __init__(self, ckpt_path):
self._ckpt_path = ckpt_path
self.graph = tf.Graph()
self._load_ckpt()
def _load_ckpt(self): #解析ckpt文件
with self.graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(self._ckpt_path, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
def predict(self, session, image): #定义预测函数
boxes = self.graph.get_tensor_by_name('detection_boxes:0') #从预测结果中得到box的位置
scores = self.graph.get_tensor_by_name('detection_scores:0') #从预测结果中得到每个类别的score值
classes = self.graph.get_tensor_by_name('detection_classes:0')#从预测结果中得到每个类别
num = self.graph.get_tensor_by_name('num_detections:0')#从预测结果中得到图片中的框的数量
image_tensor = self.graph.get_tensor_by_name('image_tensor:0') #输入图像
(boxes, scores, classes,num) = \
session.run(
[boxes, scores, classes,num],
feed_dict={image_tensor: np.expand_dims(image, 0)})
boxes = np.squeeze(boxes, 0) #np.squeeze是从数组形状中删除单维度条目
scores = np.squeeze(scores, 0)
classes = np.squeeze(classes, 0).astype(np.int64)
num = np.squeeze(num,0).astype(np.int64)
return (boxes, scores, classes,num)
def supervise(self,path): #deal pictures 传入参数path为去掉后缀的basename
jpg_filename = path + '.jpg'
img = Image.open(jpg_filename).convert('RGB')#打开图片
image = np.asarray(img)#将图片转成array矩阵
(img_width, img_height) = img.size
with tf.Session(graph=self.graph) as sess:
(boxes, scores, classes, num) = self.predict(sess,image)
det_lists = []
for k in range(num): #循环每张图片的框
if (scores[k] > 0.5): #如果框的置信度>0.5的话
cls = classes[k] #取第K个clsss的数字
clsname = classDict[cls] #根据class的数据找到classDict中的值
box = boxes[k] #取框的大小
det_y0 = box[0] * img_height #将box中的坐标映射到原图中,以下的功能相似
det_x0 = box[1] * img_width
det_y1 = box[2] * img_height
det_y2 = box[3] * img_width
det_list = [clsname,int(det_y0),int(det_x0),int(det_y1),int(det_y2)]#将预测的框写成此种格式
det_lists.append(det_list) #将每张图片的所有框的两种信息加到det_list中
return det_lists,boxes,scores,num,classes
def read_info_from_xml(self,path): #从xml中读取gt并写入
'''
# read information from xml
:param path:
:return: [['staff', 314, 930, 822, 1143], ['coat', 437, 1014, 603, 1113], ['boots', 721, 1009, 812, 1081]]
'''
xml_filename = path + '.xml'
tree = ET.parse(xml_filename)
root = tree.getroot()
gt_lists = [] #将所有的class和坐标写入gt_list
for member in root.findall('object'):
gt_list = []
gt_name = member[0].text
xmin = int(member[4][0].text)
ymin = int(member[4][1].text)
xmax = int(member[4][2].text)
ymax = int(member[4][3].text)
gt_list = [gt_name,ymin, xmin, ymax, xmax]
gt_lists.append(gt_list)
return gt_lists
def compute_iou(rec1, rec2): #计算IOU的函数
"""
computing IoU
:param rec1: (y0, x0, y1, x1), which reflects
(top, left, bottom, right)
:param rec2: (y0, x0, y1, x1)
:return: scala value of Io1U
"""
# computing area of each rectangles
S_rec1 = (rec1[3] - rec1[1]) * (rec1[4] - rec1[2])
S_rec2 = (rec2[3] - rec2[1]) * (rec2[4] - rec2[2])
# computing the sum_area
sum_area = S_rec1 + S_rec2
# find the each edge of intersect rectangle
left_line = max(rec1[2], rec2[2])
right_line = min(rec1[4], rec2[4])
top_line = max(rec1[1], rec2[1])
bottom_line = min(rec1[3], rec2[3])
# judge if there is an intersect
if left_line >= right_line or top_line >= bottom_line:
return 0
else:
intersect = (right_line - left_line) * (bottom_line - top_line)
return intersect / (sum_area - intersect)
def count_class_num(path): #计算每个类别的GT值
rdict = {}
lines = os.listdir(path)
for line in lines:
if line.endswith('.xml'):
for xml_file in glob.glob(path + '/%s'%line):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
name = member[0].text
if name in rdict.keys():
rdict[name] += 1
else:
rdict[name] = 1
return rdict
if __name__ == '__main__':
TP_total,FP_total,FN_total,ldict = 0,0,0,{}
model_path = r'D:/graduation_project/animal/animal.pb'
label_file = r'D:/graduation_project/animal/animal.pbtxt'
predictor = Predictor(model_path)
root = r'D:\graduation_project\animal\animal_pic\Total'
lines = os.listdir(root)
for class_name in classDict.values(): #循环每个类别
ldict[class_name + '_TP'] = ldict[class_name + '_FP'] = ldict[class_name + '_FN'] = 0 #首先将每个类别的TP,FP,FN设置为0方便后面的增加数量操作
for line in lines:
print('===============================')
TP, TP_lists = 0, []
if line.endswith('.jpg'):
path_basename = os.path.join(root,line.split('.')[0])
det_lists, boxes, scores, num, classes = predictor.supervise(path_basename) #预测函数,返回5个值
gt_lists = predictor.read_info_from_xml(path_basename) #读取GT
print('det_lists:',det_lists) #预测出的dection列表
print('gt_lists',gt_lists) #gt #读取的GT列表
for i in range(len(det_lists)): #循环det_lists和gt_lists
for j in range(len(gt_lists)):
if det_lists[i][0] == gt_lists[j][0]:#如果预测的类别与真值相同的话且IOU在0.5以上则预测的框为TP
det_class = det_lists[i][0]
cal_iou = compute_iou(det_lists[i], gt_lists[j])
what = 0
if cal_iou > 0.5:
what += 1
if str(det_class)+'_TP' not in ldict.keys():
ldict[str(det_class) + '_TP'] = 1
else:
ldict[str(det_class)+'_TP'] += 1
TP += 1
TP_total += 1
TP_lists.append(det_lists[i])
TP_lists.append(gt_lists[j])
break
for i in TP_lists:
if i in det_lists: #如果det_lists中的与gt_lists中的框可以匹配上的话则删除掉,在gt_lists保存下来的框为FN,在det_lists中保存下来的框为FP的。
det_lists.remove(i)
for j in TP_lists:
if j in gt_lists:
gt_lists.remove(j)
print('after det_lists',det_lists)
print('after gt_lists',gt_lists)
FP = len(det_lists)
FN = len(gt_lists)
if len(det_lists)>0:
for i in det_lists:
if str(i[0])+'_FP' not in ldict.keys():
ldict[str(i[0]) + '_FP'] = 1
else:
ldict[str(i[0])+'_FP'] += 1
if len(gt_lists)>0:
for j in gt_lists:
if str(j[0])+'_FN' not in ldict.keys():
ldict[str(j[0])+'_FN'] = 1
else:
ldict[str(j[0])+'_FN'] += 1
FP_total += FP
FN_total += FN
print('TP',TP,'FP',FP,'FN',FN)
print('***********************************')
print('TP_total:',TP_total,'FP_total:',FP_total,'FN_total:',FN_total)
percision = round((TP_total / (TP_total + FP_total)),2)
recall = round((TP_total / (TP_total + FN_total)),2)
F1_score = round((2 * TP_total / (2 * TP_total + FP_total + FN_total)),2)
print('ldict:',ldict)
per_class = {}
for class_name in classDict.values():
if ldict[class_name+'_TP'] > 0:
per_class[class_name+'_Percision'] = ldict[class_name+'_TP']/(ldict[class_name+'_TP']+ldict[class_name+'_FP'])
per_class[class_name+'_Recall'] = ldict[class_name+'_TP']/(ldict[class_name+'_TP'] + ldict[class_name+'_FN'])
per_class[class_name + '_F1_score'] = 2* ldict[class_name+'_TP'] / (2* ldict[class_name+'_TP'] + ldict[class_name+'_FP'] + ldict[str(class_name)+'_FN'])
print('per_class',per_class)
print('precision',percision)
print('recall',recall)
print('F1_score',F1_score)
count_num = count_class_num(root)
print('count_num',count_num) 由于测试集在训练时参与参数的调优过程,所以在测试集中的数据准确率有失偏衡,对于验证集的详细测试结果位于3.5.2小节。
3.4 Tensorflow Lite移动端框架介绍
TensorFlow Lite(以下简称tflite)是TensorFlow针对移动设备和嵌入式设备的轻量级解决方案。它支持具有低延迟和小二进制大小的设备上的机器学习推理。tflite还支持Android神经网络API的硬件加速。tflite使用许多技术来实现低延迟,例如为移动APP优化内核、预融合激活和允许更小更快(定点数学)模型的量化内核。
tflite基于flatbuffer定义了一种新的模型文件格式。flatbuffer是一个高效的开源跨平台序列化库。它与协议缓冲区类似,但主要的区别是flatbuffer在访问数据之前不需要对二级表示进行解析/解包步骤(通常与每个对象的内存分配耦合)。此外,flatbuffer的代码占用比协议缓冲区小一个数量级。如图3-20和图3-21所示,无论是在大小还是在编/解码的时间方面都有比较高的优势。
 图 3-20 各个数据类型在大小的对比
图 3-20 各个数据类型在大小的对比
 图 3-21 各个数据类型在编/解码时间方面的对比
图 3-21 各个数据类型在编/解码时间方面的对比
机器学习正在改变计算的方式,移动设备和嵌入式设备上的使用的新兴趋势。在摄像头和语音交互模型的驱动下,消费者的期望也趋向于与移动设备进行自然的、类人的交互。有几个因素提高了人们对这个领域的兴趣:
(1)科技的创新为智能手机和智能电脑的硬件加速,而Android神经网络API等框架使得在移动端实现变为可能
(2)计算机视觉与自然语言处理(NLP)的飞速发展,使得模型可以脱离网络独立使用CPU运行,即设备不需要连接到网络。
tflite提供了以下几个方面的便利:
(1)一系列的核心运算符,它包括离散的序列和浮点的序列,有很多的运算符已经在移动平台中创建和定义,学生和科学研究者可以编辑一下自定义操作符并可以在tflite模型中使用它们。
(2)tflite格式是一种flatbuffers格式
(3)在移动设备上执行的tflite模型执行速度会更快
(4)用于将Tensorflow训练的模型转换为tflite格式在手机端部署
(5)tflite模型的特点对于pb模型来说没明显的精度损失,而且低延迟,将32位浮点数转换成8位进行量化操作,模型大小缩小4倍,具有嵌入式设备的可移植性,支持GPU加速。
3.4.2 ckpt转tflite格式
Tflite是2017年Google I/O大会上的重要宣布之一,应用开发者可以利用tflite在移动设备上部署人工智能模型。将ckpt转成tflite格式需要进行三个步骤,分别是
(1)在电脑端使用tensorflow框架,ssd_mobilenet_v2网络结构训练模型
(2)使用代码将tensorflow模型转换成tflite格式
(3)将tflite模型迁移到Android端
在tensorflow中训练模型生成的模型文件会生成3种文件,分别是
·model.ckpt.meta:保存Tensorflow网络计算图
·model.ckpt:保存每一个变量的取值,变量是模型中需要优化的部分
·checkpoint:目录中的检查点文件
首先将ckpt的计算图和权重固化成pb模型,将计算图中的变量取值以常量的方式保存,而且保存的pb模型可以被C++等其他语言调用。
 图3-22 训练模型生成的ckpt文件
图3-22 训练模型生成的ckpt文件
通过调用
models/research/object_detection/export_tflite_ssd_graph.py
运行export_pb.sh
运行后会生成ckpt文件固化的pb文件(图3-23)。
然后使用tflite转换工具,tflite_connvert可以直接将pb文件转换成tflite格式,命令如图3-24所示。如果想查看tflite的网络结构的输入和输出需要运行图3-25所示的命令。
图 3-24 pb转tflite格式的sh文件
为了可以看到模型的输入输出以及各个节点的情况,故将tflite模型的网络结构输出到pdf中以方便查看。
图3-25 生成tflite网络结构pdf的sh文件
输出的pdf文件如下所示,其中包含模型的输入格式(图3-26)和输出格式(图3-27)
图 3-26 tflite 模型的输入格式
图3-27 tflite模型的输出格式,分别为boxes(目标的位置信息),classes(目标的类别信息),scores(目标的分数信息),num(图片中含目标的数量)
3.5 网络性能实验
3.5.1 实验内容
本文的测试数据为478张,平均涵盖10种动物,训练时分别针对其Map,不同IOU所对应的准确度,学习率,分类损失,定位损失,优化损失以及整体损失的tensorboard监控,tensorboard所显示的详细信息在3.5.2中详细说明。在测试集中使用
3.5.2 实验结果与分析
目标检测任务中模型的分类和定位都需要进行评估,每个图像含有不同的类别和位置信息,因此图像分类中的评价指标不能当做目标检测中的评价指标。图3-28展示了训练过程中mAP(Mean Average Percision)的变化量,根据曲线可以看到平均mAP在48%,大目标的mAP在53%,中等目标的mAP在0.05附近,而小目标的mAP一直是零,是因为训练图像中几乎都是大目标的,所以对于大目标的泛化能力比较强。
图 3-28 训练集mAP
训练集IOU在0.5以上和IOU在0.75以上的mAP如图3-29和3-30所示
图 3-29 IOU在0.5以上mAP 图 3-30 IOU在0.75以上的mAP
SSD的损失函数包含分类损失(Classification Loss)和回归损失(Location Loss,分类损失一般使用交叉熵损失,本文改进交叉熵损失使用Focal loss,主要解决ssd目标检测中正负样本严重不均衡的问题,该损失降低了大量简单的负样本所占的权重,着重处理那些困难样本,focal loss的公式如图3-31所示,回归损失采用smooth L1,公式如图3-32所示,总损失(Total Loss)是分类损失和回归损失的加权和,α表示两者的权重,N表示匹配到默认框的数量,总损失函数如图3-33所示
图 3-31 focal loss分类损失
图 3-32 smooth L1回归损失
图 3-33 总损失
训练时分类损失、回归损失以及总损失的变化曲线如图3-34所示
图 3-34 不同loss的变化曲线
因为测试集的准确率相对于模型没有见过的图片是偏高的,所以每个类别分别找了20个左右的验证集,验证集的测试结果如表3-5所示,
 表 3-5 验证集的测试结果
表 3-5 验证集的测试结果
分析表中的数据可知长颈鹿、斑马的准确率、召回率和F1-score是最高的,对猫狗的准确率是偏低的,因为猫狗本来就比较像。红色的数字代表准确率、召回率等评价指标的最高值,蓝色的数字代表评价指标的最低值。
第四章 在安卓端部署模型
4.1 应用开发
本文主要使用的Google公司推出的tensorflow lite框架进行移动端APP开发,是Google专门为移动端设备和物联网设备推出的框架,不需要三方依赖,跨平台,兼容性好。开发者能够轻松的将模型转换成移动端专用的tflite格式,可以用在目标检测中。
4.1.1 开发环境
 图 4-1 Android Studio项目框架图
图 4-1 Android Studio项目框架图
本文开发的APP基于Android Studio 3.2
类别输出的信息在animal_data.txt中,整个项目的框架图如图4-1所示
4.1.2 软件参数
测试本文提出的动物识别APP时,运行程序消耗40%左右的CPU,内存在130M-200M之间波动。图4-2为在运行测试APP时的手机占用情况。
 图 4-2 App性能测试
图 4-2 App性能测试
本文训练了轻量型神经网络模型,降低了模型的大小,测试手机环境为vivo nex,测试机为CPU,所有处理时间比较慢,tflite模型的大小6.73M,APP的大小为167.45M,对于每张输入图像的识别时间大概在110ms一张图片。APP界面如图4-3所示。
 图 4-3 APP界面示意图
图 4-3 APP界面示意图
 图 4-3 APP界面示意图
图 4-3 APP界面示意图
图 4-3 APP界面示意图
第五章 总结与展望
随着人工智能与5G移动通信的发展,为未来几年之内的移动互联设备实现高效率的处理图像提供可能。本文从采集数据到Android开发APP可分为10个阶段。
(1)选择需要识别的动物种类,本文选取大象,老虎,斑马等10类动物
(2)使用网页插件(批量下载工具)采集所需种类的图像,每类下载600-700张
(3)进行数据清洗,将图片数据中的漫画,玩偶,动态图,目标占比比较小的图片删掉
(4)使用数据标注工具(LabelImg)对测试训练数据打标签,作用是告诉模型正样本所在的位置,以便后续的算法进行训练
(5)将标注好的数据转换成tensorflow专用的tfrecord数据格式,不仅处理了图像占用磁盘空间的问题,而且还将数据转换成“protocol Buffer”二进制格式,尤其是遇到数据量大的情况,可以转换成多个tfrecord文件分批次读取数据来提高效率。
(6)调整超参数,类似学习率,batch_size,loss等可以人工自行设计的参数
(7)跑模型,配置GPU服务器,本文所使用的服务器显卡是1080,操作系统为Ubantu16.04
(8)使用tensorboard监控模型的训练过程,查看训练过程中评价指标与超参数的变化
(9)对200张验证集进行测试,测试出每一个类别的准确率,看看哪个类别的准确率高,哪个类别的准确率低,因为tensorboard中查看的曲线是整体的曲线,并没有将每一类别的准确率输出。
(10)将训练生成的ckpt文件转成tflite格式,使用Android Sutdio编译工程生成APP
由于本文的APP在移动端是实时识别,无法计算出评价指标,故在本地使用pb模型对验证数据集进行测试,最终的正确率为86%,召回率为0.91,F1-score为0.88。
未来在本文研究的基础上可以进行以下优化:
(1)数据集方面,可以通过扩充数据集中动物类别来增加动物识别的多样性,让动物识别APP不光能识别出生活中常见的动物,还可以识别出濒临绝种的动物,表5-1展示了中国脊椎动物的濒危状况[10],为普通动物爱好者和动物科学研究学家提供一个便捷式的工具,为幼儿教育提供提高动物识别能力的简易APP[8]。
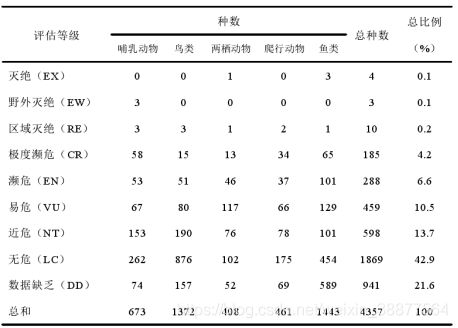 表 5-1 中国脊椎动物濒危状况
表 5-1 中国脊椎动物濒危状况
(2)预处理方面,可以使用一种边缘增强的算法增加边缘的梯度,增加环境信息的融合,还可以使用数据融合算法增加图像数据。
(3)算法模型方面,最近mobilenetv3论文已发出,已经有开源实现,可以尝试mobilenetv3网络,图5-1为mobilenetv3与mobilenetv2的tflite格式的差别。
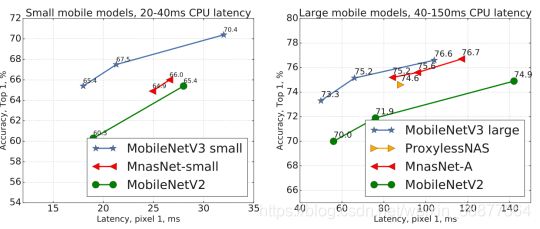 图 5-1 mobielentv3-small and Large 准确率
图 5-1 mobielentv3-small and Large 准确率
参考文献
[1] Shaoqing Ren, Kaiming He, Ross Girshick.Faster R-CNN: TowardsReal-Time
Object Detection with Region Proposal Network[J].CVPR.2016,6(1):1-14
[2] Tsung-Yi Lin, Priya Goyal, Ross Girshick. Focal Loss for Dense Object Detection[J].IEEE
transactions on pattern analysis and machine intelligence.2018,6(1):1-10
[3] 汪宋,费树岷.SSD(Single Shot MultiBox Detector)目标检测算法的研究与改进[J].工业控制计算机.2019,32(4):103-105
[4] Mark,Sandler ,Andrew . MobileNetV2: Inverted Residuals and Linear Bottlenecks[J].CVPR.
2018,4(1):1-14
- Raghuraman,Krishnamoorthi.Quantizing deep convolutional networks for efficient inferenc-
e[J].A whitepaper .2018,6(21):3-36
- Borui Jiang,Ruixuan Luo, Jiayuan Mao.Acquisition of-Localiza-tion Confidence for Accur-
ate Object Detection[J].CVPR.2018,7(30):1-16
- Sara Sabour ,Nicholas Frosst,Geoffrey E.Hinton.Dynamic Routing Between Capsules[J].
CVPR.2017,10(26):1-2
[8] 袁东芝. 基于卷积神经网络的动物识别算法研究[D].华南理工大学,2018
[9] 寇大磊,权冀川,张仲伟.基于深度学习的目标检测框架进展研究[J].计算机工程与应
用.2019,3(8):1-12
[10] 蒋志刚,江建平,王跃招等.中国脊椎动物红色名录[J].生物多样性.2016,24(5):500-
551