高性能网关设计实践
前言
之前的高性能短链设计一文颇受大家好评,共被转载 「47」 次,受宠若惊,在此感谢大家的认可!在文末简单提了一下 OpenResty,一些读者比较感兴趣,刚好我们接入层网关也是用的 OpenResty,所以希望通过对网关设计的介绍来简单总结一下 OpenResty 的相关知识点,争取让大家对 OpenResty 这种高性能 Web 平台有一个比较全面的了解。本文会从以下几个方面来讲解。
网关的作用
接入层网关架构设计与实现
技术选型
OpenResty 原理剖析
网关的作用
网关作为所有请求的流量入口,主要承担着安全,限流,熔断降级,监控,日志,风控,鉴权等功能,网关主要有两种类型
一种是接入层网关(access gateway),主要负责路由,WAF(防止SQL Injection, XSS, 路径遍历, 窃取敏感数据,CC攻击等),限流,日志,缓存等,这一层的网关主要承载着将请求路由到各个应用层网关的功能
另一种是应用层网关,比如现在流行的微服务,各个服务可能是用不同的语言写的,如 PHP,Java 等,那么接入层就要将请求路由到相应的应用层集群,再由相应的应用层网关进行鉴权等处理,处理完之后再调用相应的微服务进行处理,应用层网关也起着路由,超时,重试,熔断等功能。
目前市面上比较流行的系统架构如下
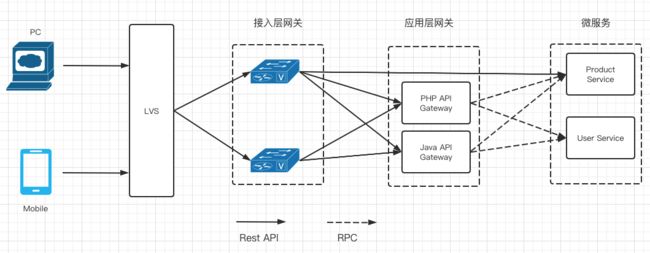
可以看到接入层网关承载着公司的所有流量,对性能有很高的要求,它的设计决定着整个系统的上限。所以我们今天主要谈谈接入层网关的设计。
接入层网关架构设计与实现
首先我们要明白接入层网关的核心功能是:「根据路由规则将请求分发到对应的后端集群」,所以要实现如下几个功能模型 。
1、 路由:根据请求的 host, url 等规则转发到指定的上游(相应的后端集群) 2、 路由策略插件化:这是网关的「灵魂所在」,路由中会有身份认证,限流限速,安全防护(如 IP 黑名单,refer异常,UA异常,需第一时间拒绝)等规则,这些规则以插件的形式互相组合起来以便只对某一类的请求生效,每个插件都即插即用,互不影响,这些插件应该是「动态可配置」的,动态生效的(无须重启服务),为啥要可动态可配置呢,因为每个请求对应的路由逻辑,限流规则,最终请求的后端集群等规则是不一样的

如图示,两个请求对应的路由规则是不一样的,它们对应的路由规则(限流,rewrite)等通过各个规则插件组合在一起,可以看到,光两个请求 url 的路由规则就有挺多的,如果一个系统大到一定程度,url 会有不少,就会有不少规则,这样每个请求的规则就必须「可配置化」,「动态化」,最好能在管理端集中控制,统一下发。
3、后端集群的动态变更
路由规则的应用是为了确定某一类请求经过这些规则后最终到达哪一个集群,而我们知道请求肯定是要打到某一台集群的 ip 上的,而机器的扩缩容其实是比较常见的,所以必须支持动态变更,总不能我每次上下线机器的时候都要重启系统让它生效吧。
4、监控统计,请求量、错误率统计等等
这个比较好理解,在接入层作所有流量的请求,错误统计,便于打点,告警,分析。
要实现这些需求就必须对我们采用的技术:OpenResty 有比较详细的了解,所以下文会简单介绍一下 OpenResty 的知识点。
技术选型
有人可能第一眼想到用 Nginx,没错,由于 Nginx 采用了 epoll 模型(非阻塞 IO 模型),确实能满足大多数场景的需求(经过优化 100 w + 的并发数不是问题),但是 Nginx 更适合作为静态的 Web 服务器,因为对于 Nginx 来说,如果发生任何变化,都需要修改磁盘上的配置,然后重新加载才能生效,它并没有提供 API 来控制运行时的行为,而如上文所述,动态化是接入层网关非常重要的一个功能。所以经过一番调研,我们选择了 OpenResty,啥是 OpenResty 呢,来看下官网的定义:
❝OpenResty® 是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。OpenResty® 的目标是让你的Web服务直接跑在 Nginx 服务内部,充分利用 Nginx 的非阻塞 I/O 模型,不仅仅对 HTTP 客户端请求,甚至于对远程后端诸如 MySQL、PostgreSQL、Memcached 以及 Redis 等都进行一致的高性能响应。
❞
可以简单理解为,OpenResty = Nginx + Lua, 通过 Lua 扩展 Nginx 实现的可伸缩的 Web 平台 。它利用了 Nginx 的高性能,又在其基础上添加了 Lua 的脚本语言来让 Nginx 也具有了动态的特性。通过 OpenResty 中 lua-Nginx-module 模块中提供的 Lua API,我们可以动态地控制路由、上游、SSL 证书、请求、响应等。甚至可以在不重启 OpenResty 的前提下,修改业务的处理逻辑,并不局限于 OpenResty 提供的 Lua API。
关于静态和动态有一个很合适的类比:如果把 Web 服务器当做是一个正在高速公路上飞驰的汽车,Nginx 需要停车才能更换轮胎,更换车漆颜色,而 OpenResty 中可以边跑边换轮胎,更换车漆,甚至更换发动机,直接让普通的汽车变成超跑!
除了以上的动态性,还有两个特性让 OpenResty 独出一格。
「1.详尽的文档和测试用例」
作为开源项目,文档和测试毫无疑问是其是否靠谱的关键,它的文档非常详细,作者把每个注意的点都写在文档上了,多数时候只要看文档即可,每一个测试案例都包含完整的 Nginx 配置和 lua 代码。以及测试的输入数据和预期的输出数据。
「2.同步非阻塞」
OpenResty 在诞生之初就支持了协程,并且基于此实现了同步非阻塞的编程模型。
「画外音:协程(coroutine)我们可以将它看成一个用户态的线程,只不过这个线程是我们自己调度的,而且不同协程的切换不需要陷入内核态,效率比较高。(一般我们说的线程是要指内核态线程,由内核调度,需要从用户空间陷入内核空间,相比协程,对性能会有不小的影响)」
啥是同步非阻塞呢。假设有以下两个两行代码:
local res, err = query-mysql(sql)
local value, err = query-redis(key)
「同步」:必须执行完查询 mysql,才能执行下面的 redis 查询,如果不等 mysql 执行完成就能执行 redis 则是异步。
「阻塞」:假设执行 sql 语句需要 1s,如果在这 1s 内,CPU 只能干等着不能做其它任何事,那就是阻塞,如果在 sql 执行期间可以做其他事(注意由于是同步的,所以不能执行以下的 redis 查询),则是非阻塞。
同步关注的是语句的先后执行顺序,如果上一个语句必须执行完才能执行下一个语句就是同步,如果不是,就是异步,阻塞关注的是线程是 CPU 是否需要在 IO 期间干等着,如果在 IO(或其他耗时操作期间)期间可以做其他事,那就是非阻塞,不能动,则是阻塞。
那么 OpenResty 的工作原理是怎样的呢,又是如何实现同步非阻塞的呢。
OpenResty 原理剖析
工作原理剖析
由于 OpenResty 基于 Nginx 实现的,我们先来看看 Nginx 的工作原理
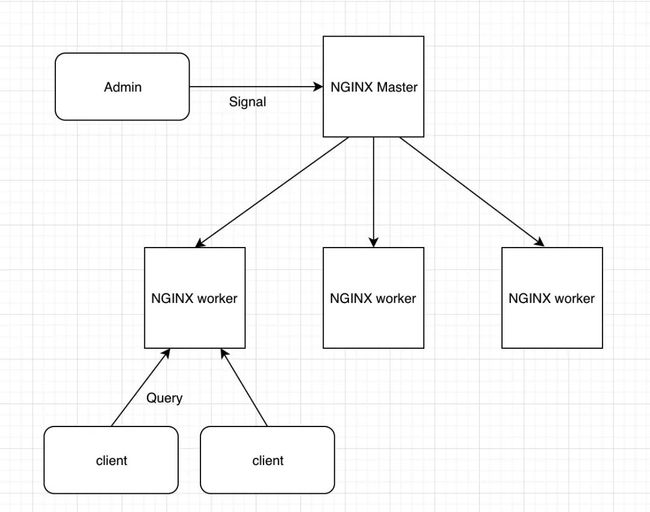
Nginx 启动后,会有一个 master 进程和多个 worker 进程 , master 进程接受管理员的信号量(如 Nginx -s reload, -s stop)来管理 worker 进程,master 本身并不接收 client 的请求,主要由 worker 进程来接收请求,不同于 apache 的每个请求会占用一个线程,且是同步IO,Nginx 是异步非阻塞的,每个 worker 可以同时处理的请求数只受限于内存大小,这里就要简单地了解一下 nginx 采用的 epoll 模型:
epoll 采用多路复用模型,即同一时间虽然可能会有多个请求进来, 但只会用一个线程去监视,然后哪个请求数据准备好了,就调用相应的线程去处理,就像图中所示,如同拨开关一样,同一时间只有一个线程在处理, Nginx 底层就是用的 epoll ,基于事件驱动模型,每个请求进来注册事件并注册 callback 回调函数,等数据准入好了,就调用回调函数进行处理,它是异步非阻塞的,所以性能很高。

打个简单的比方,我们都有订票的经验,当我们委托酒店订票时,接待员会先把我们的电话号码和相关信息等记下来(注册事件),挂断电话后接待员在操作期间我们就可以去做其他事了(非阻塞),当接待员把手续搞好后会主动打电话给我们通知我们票订好了(回调)。
worker 进程是从 master fork 出来的,这意味着 worker 进程之间是互相独立的,这样不同 worker 进程之间处理并发请求几乎没有同步锁的限制,好处就是一个 worker 进程挂了,不会影响其他进程,我们一般把 worker 数量设置成和 CPU 的个数,这样可以减少不必要的 CPU 切换,提升性能,每个 worker 都是单线程执行的。那么 LuaJIT 在 OpenResty 架构中的位置是怎样的呢。

首先启动的 master 进程带有 LuaJIT 的机虚拟,而 worker 进程是从 master 进程 fork 出来的,在 worker 内进程的工作主要由 Lua 协程来完成,也就是说在同一个 worker 内的所有协程,都会共享这个 LuaJIT 虚拟机,每个 worker 进程里 lua 的执行也是在这个虚拟机中完成的。
同一个时间点,worker 进程只能处理一个用户请求,也就是说只有一个 lua 协程在运行,那为啥 OpenResty 能支持百万并发请求呢,这就需要了解 Lua 协程与 Nginx 事件机制是如何配合的了。
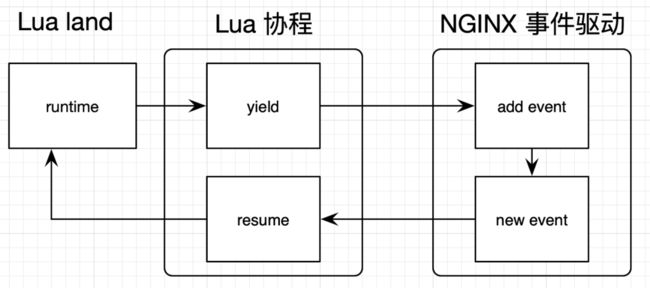
如图示,当用 Lua 调用查询 MySQL 或 网络 IO 时,虚拟机会调用 Lua 协程的 yield 把自己挂起,在 Nginx 中注册回调,此时 worker 就可以处理另外的请求了(非阻塞),等到 IO 事件处理完了, Nginx 就会调用 resume 来唤醒 lua 协程。
事实上,由 OpenResty 提供的所有 API,都是非阻塞的,下文提到的与 MySQL,Redis 等交互,都是非阻塞的,所以性能很高。
OpenResty 请求生命周期
Nginx 的每个请求有 11 个阶段,OpenResty 也有11 个 *_by_lua 的指令,如下图示:
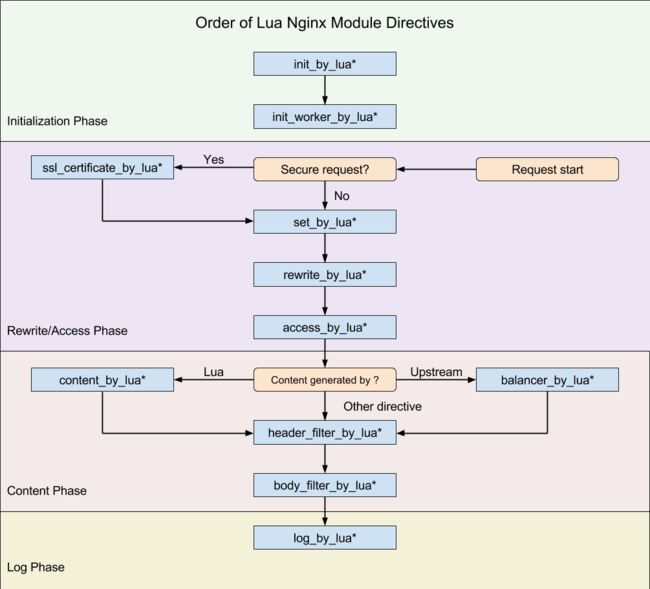
各个阶段 *_by_lua 的解释如下
set_by_lua:设置变量;
rewrite_by_lua:转发、重定向等;
access_by_lua:准入、权限等;
content_by_lua:生成返回内容;
header_filter_by_lua:应答头过滤处理;
body_filter_by_lua:应答体过滤处理;
log_by_lua:日志记录。
这样分阶段有啥好处呢,假设你原来的 API 请求都是明文的
# 明文协议版本
location /request {
content_by_lua '...'; # 处理请求
}
现在需要对其加上加密和解密的机制,只需要在 access 阶段解密, 在 body filter 阶段加密即可,原来 content 的逻辑无需做任务改动,有效实现了代码的解藕。
# 加密协议版本
location /request {
access_by_lua '...'; # 请求体解密
content_by_lua '...'; # 处理请求,不需要关心通信协议
body_filter_by_lua '...'; # 应答体加密
}
再比如我们不是要要上文提到网关的核心功能之一不是要监控日志吗,就可以统一在 log_by_lua 上报日志,不影响其他阶段的逻辑。
worker 间共享数据利器: shared dict
worker 既然是互相独立的进程,就需要考虑其共享数据的问题, OpenResty 提供了一种高效的数据结构: shared dict ,可以实现在 worker 间共享数据,shared dict 对外提供了 20 多个 Lua API,都是原子操作的,避免了高并发下的竞争问题。
路由策略插件化实现
有了以上 OpenResty 点的铺垫,来看看上文提的网关核心功能 「路由策略插件化」,「后端集群的动态变更」如何实现
首先针对某个请求的路由策略大概是这样的
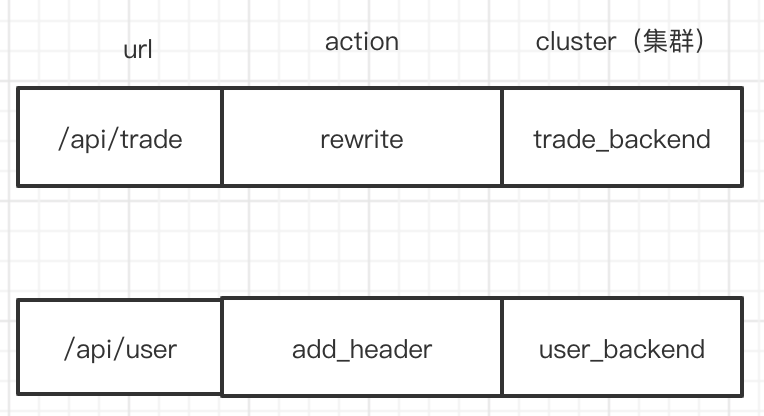
整个插件化的步骤大致如下
1、每条策略由 url ,action, cluster 等组成,代表请求 url 在打到后端集群过程中最终经历了哪些路由规则,这些规则统一在我们的路由管理平台配置,存在 db 里。
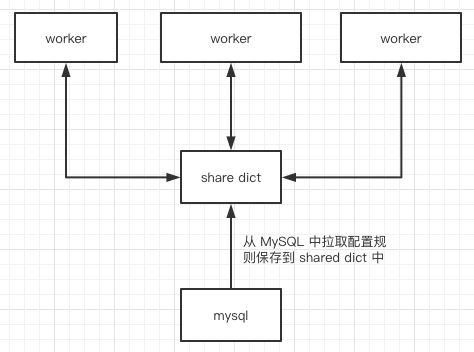
2、OpenResty 启动时,在请求的 init 阶段 worker 进程会去拉取这些规则,将这些规则编译成一个个可执行的 lua 函数,这一个个函数就对应了一条条的规则。

需要注意的是为了避免重复去 MySQL 中拉取数据,某个 worker 从 MySQL 拉取完规则(此步需要加锁,避免所有 worker 都去拉取)或者后端集群等配置信息后要将其保存在 shared dict 中,这样之后所有的 worker 请求只要从 shared dict 中获取这些规则,然后将其映射成对应模块的函数即可,如果配置规则有变动呢,配置后台通过接口通知 OpenResty 重新加载一下即可
经过路由规则确定好每个请求对应要打的后端集群后,就需要根据 upstream 来确定最终打到哪个集群的哪台机器上,我们看看如何动态管理集群。
后端集群的动态配置
在 Nginx 中配置 upstream 的格式如下
upstream backend {
server backend1.example.com weight=5;
server backend2.example.com;
server 192.0.0.1 backup;
}
以上这个示例是按照权重(weight)来划分的,6 个请求进来,5个请求打到 backend1.example.com, 1 个请求打到 backend2.example.com,如果这两台机器都不可用,就打到 192.0.0.1,这种静态配置的方式 upstream 的方式确实可行,但我们知道机器的扩缩容有时候比较频繁,如果每次机器上下线都要手动去改,并且改完之后还要重新去 reload 无疑是不可行的,出错的概率很大,而且每次配置都要 reload 对性能的损耗也是挺大的,为了解决这个问题,OpenResty 提供了一个 dyups 的模块来解决此问题, 它提供了一个 dyups api,可以动态增,删,创建 upsteam,所以在 init 阶段我们会先去拉取集群信息,构建 upstream,之后如果集群信息有变动,会通过如下形式调用 dyups api 来更新 upstream
-- 动态配置 upstream 接口站点
server {
listen 127.0.0.1:81;
location / {
dyups_interface;
}
}
-- 增加 upstream:user_backend
curl -d "server 10.53.10.191;" 127.0.0.1:81/upstream/user_backend
-- 删除 upstream:user_backend
curl -i -X DELETE 127.0.0.1:81/upstream/user_backend
使用 dyups 就解决了动态配置 upstream 的问题
网关最终架构设计图
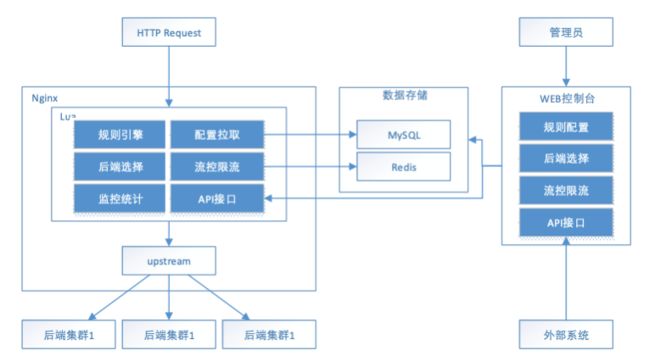
通过这样的设计,最终实现了网关的配置化,动态化。
总结
网关作为承载公司所有流量的入口,对性能有着极高的要求,所以技术选型上还是要慎重,之所以选择 OpenResty,一是因为它高性能,二是目前也有小米,阿里,腾讯等大公司在用,是久经过市场考验的,本文通过对网关的总结简要介绍了 OpenResty 的相关知识点,相信大家对其主要功能点应该有所了解了,不过 OpenResty 的知识点远不止以上这些,大家如有兴趣,可以参考文末的学习教程深入学习,相信大家会有不少启发的。
题外话
「码海」历史精品文章已经做成电子书了,如有需要欢迎添加我的个人微信,除了发你电子书外,也可以加入我的读者群,一起探讨问题,共同进步!里面有不少技术总监等大咖,相信不管是职场进阶也好,个人困惑也好,都能对你有所帮助哦

巨人的肩膀
谈谈微服务中的 API 网关 https://www.cnblogs.com/savorboard/p/api-gateway.html
Openresty动态更新(无reload)TCP Upstream的原理和实现 https://developer.aliyun.com/article/745757
http://www.ttlsa.com/Nginx/Nginx-modules-ngx_http_dyups_module/
极客时间 OpenResty 从入门到实战

1. 人人都能看懂的 6 种限流实现方案!
2. 一个空格引发的“惨案“
3. 大型网站架构演化发展历程
4. Java语言“坑爹”排行榜TOP 10
5. 我是一个Java类(附带精彩吐槽)
6. 看完这篇Redis缓存三大问题,保你能和面试官互扯
7. 程序员必知的 89 个操作系统核心概念
8. 深入理解 MySQL:快速学会分析SQL执行效率
9. API 接口设计规范
10. Spring Boot 面试,一个问题就干趴下了!


扫码二维码关注我
·end·
—如果本文有帮助,请分享到朋友圈吧—
我们一起愉快的玩耍!

你点的每个赞,我都认真当成了喜欢