手把手写深度学习(7):用GANs生成手写数字
前言:2014年GANs在NPIS大会上被提出,但是因为种种原因沉寂了两年,直到DCGANs横空出世,将GAN和CNN完美结合,才真正打开了GANs井喷时代,一下子成为最强风口。好几年过去了,热度有增无减。这一讲从DCGAN的原理出发,一步步深入,用DCGAN生成手写数字。
目录
GANs基本原理
算法流程
DCGANs的改进
模型结构
反卷积
模型参数
训练过程
开始训练!
训练代码
loss不收敛?正常现象
结果生成
参考:
GANs基本原理
GAN在做这样一件事,试图训练一个G,让G产生能够欺骗足够优秀的D的假样本。G的输入可以是一个随机分布(可以实验各种分布的噪音对GAN的影响,已有相关论文),而G在对抗中完善的是将输入分布空间映射到真实数据分布空间的映射能力。用一句话总结就是,让G在对抗中学习到如何从随机分布产生一个真实样本分布。
算法流程

DCGANs的改进
DCGANs最主要是改进了CNN结构,具体如下:
1、所有的pooling层使用步幅卷积(判别网络)和微步幅度卷积(生成网络)进行替换。
2、在生成网络和判别网络上使用批处理规范化。有利于模型更快收敛。
3、对于更深的架构移除全连接隐藏层。有利于模型稳定,但是降低收敛速度。
4、在生成网络的所有层上使用ReLU激活函数,除了输出层使用Tanh激活函数。
5、在判别网络的所有层上使用LeakyReLU激活函数。
模型结构
改进后的结构如下:
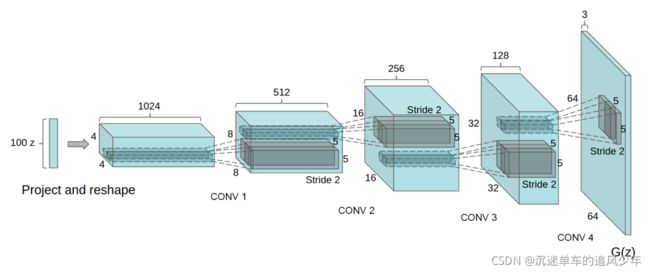
反卷积
图中的stride表示反卷积,在pytorch里面可以用stride参数轻松表示。反卷积其实字面意思是小数或分数卷积,即stride为小数或分数的卷积。如果是普通卷积,则Stride>=1,卷积的输出结果是更小尺寸的图片。而反卷积是为了得到更大尺寸的输出,可是步长为小数,没法移动啊。于是就补0,如果反卷积的stride=3,那么就代表步长为1/3。为了实现这种移动,我们还是移动步长1,但是在原特征图中的元素每两个元素间填充2个0,那么此时移动1步,所覆盖的元素中,非零元素只占1/3(只看一个维度方向),减小了卷积核对非零元素的影响范围,实现了降低步伐,细致地对每个非零元素提取特征,产生更多冗余的效果。普通卷积中,步长越大,则信息抽取越粗,冗余更少,但是会有信息损失。所以反卷积的分数步长,目的在于慢慢地对每个非零元素提取信息,产生更多冗余,来使图片的尺寸增大。
模型参数
我们用pytorch按照上面的描述创建了如下的模型:
Generator(
(gen_model): Sequential(
(0): ConvTranspose2d(100, 512, kernel_size=(4, 4), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): ConvTranspose2d(512, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): ConvTranspose2d(256, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(7): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(10): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
(12): ConvTranspose2d(64, 1, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(13): Tanh()
)
)Discriminator(
(conv_layers): Sequential(
(0): Conv2d(1, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): LeakyReLU(negative_slope=0.2, inplace=True)
(2): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): LeakyReLU(negative_slope=0.2, inplace=True)
(5): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(6): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): LeakyReLU(negative_slope=0.2, inplace=True)
(8): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(9): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(10): LeakyReLU(negative_slope=0.2, inplace=True)
(11): Conv2d(512, 512, kernel_size=(4, 4), stride=(1, 1), bias=False)
)
(linear_layers): Sequential(
(0): Linear(in_features=512, out_features=1, bias=True)
(1): LeakyReLU(negative_slope=0.2, inplace=True)
(2): Sigmoid()
)
)代码如下:
import torch.nn as nn
import torch.nn.functional as F
class Generator(nn.Module):
# init takes in the latent vector size
def __init__(self, nz, image_size=64, n_channels=1):
super(Generator, self).__init__()
self.nz = nz
self.first_out_channels = 512
self.image_size = image_size
self.n_channels = n_channels
self.kernel_size = 4
self.gen_model = nn.Sequential(
# nz will be the input to the first convolution
nn.ConvTranspose2d(
self.nz, self.first_out_channels, kernel_size=self.kernel_size,
stride=1, padding=0, bias=False),
nn.BatchNorm2d(self.first_out_channels),
nn.ReLU(True),
nn.ConvTranspose2d(
self.first_out_channels, self.first_out_channels//2,
kernel_size=self.kernel_size,
stride=2, padding=1, bias=False),
nn.BatchNorm2d(self.first_out_channels//2),
nn.ReLU(True),
nn.ConvTranspose2d(
self.first_out_channels//2, self.first_out_channels//4,
kernel_size=self.kernel_size,
stride=2, padding=1, bias=False),
nn.BatchNorm2d(self.first_out_channels//4),
nn.ReLU(True),
nn.ConvTranspose2d(
self.first_out_channels//4, self.first_out_channels//8,
kernel_size=self.kernel_size,
stride=2, padding=1, bias=False),
nn.BatchNorm2d(self.first_out_channels//8),
nn.ReLU(True),
nn.ConvTranspose2d(
self.first_out_channels//8, self.n_channels, kernel_size=self.kernel_size,
stride=2, padding=1, bias=False),
nn.Tanh()
)
def forward(self, x):
out = self.gen_model(x)
# print(out.shape)
return out
class Discriminator(nn.Module):
def __init__(self, n_channels=1):
super(Discriminator, self).__init__()
self.n_channels = n_channels
self.first_out_channels = 64*1
self.kernel_size = 4
self.leaky_relu_neg_slope = 0.2
self.conv_layers = nn.Sequential(
nn.Conv2d(
self.n_channels, self.first_out_channels,
kernel_size=self.kernel_size,
stride=2, padding=1, bias=False),
nn.LeakyReLU(self.leaky_relu_neg_slope, inplace=True),
nn.Conv2d(
self.first_out_channels, self.first_out_channels*2,
kernel_size=self.kernel_size,
stride=2, padding=1, bias=False),
nn.BatchNorm2d(self.first_out_channels*2),
nn.LeakyReLU(self.leaky_relu_neg_slope, inplace=True),
nn.Conv2d(
self.first_out_channels*2, self.first_out_channels*4,
kernel_size=self.kernel_size,
stride=2, padding=1, bias=False),
nn.BatchNorm2d(self.first_out_channels*4),
nn.LeakyReLU(self.leaky_relu_neg_slope, inplace=True),
nn.Conv2d(
self.first_out_channels*4, self.first_out_channels*8,
kernel_size=self.kernel_size,
stride=2, padding=1, bias=False),
nn.BatchNorm2d(self.first_out_channels*8),
nn.LeakyReLU(self.leaky_relu_neg_slope, inplace=True),
nn.Conv2d(
self.first_out_channels*8, 512,
kernel_size=self.kernel_size,
stride=1, padding=0, bias=False),
)
self.linear_layers = nn.Sequential(
nn.Linear(512, 1),
nn.LeakyReLU(self.leaky_relu_neg_slope, inplace=True),
nn.Sigmoid()
)
def forward(self, x):
x = self.conv_layers(x)
bs, _, _, _ = x.shape
x = F.adaptive_avg_pool2d(x, 1).reshape(bs, -1)
x = self.linear_layers(x)
return x训练过程
一般来说先训练判别器,再训练生成器。判别器可以在一个epoch过程中训练多次,但是生成器一般只训练一次。
画了个草图,后面有时间补一张脑图吧


开始训练!
训练代码
from models import Generator, Discriminator
from config import(
IMAGE_SIZE, NZ, DEVICE, SAMPLE_SIZE,
EPOCHS, K, BATCH_SIZE, DATASET,
NUM_WORKERS, PRINT_EVERY, BETA1, BETA2,
N_CHANNELS, LEARNING_RATE, GEN_MODEL_SAVE_INTERVAL
)
from utils import (
label_fake, label_real, create_noise,
save_generator_image, make_output_dir,
weights_init, print_params, save_loss_plots,
initialize_tensorboard, add_tensorboard_scalar,
save_gen_model
)
from datasets import return_data
from torchvision.utils import make_grid
from PIL import Image
import torch.optim as optim
import torch.nn as nn
import imageio
import torch
import glob as glob
import time
# function to train the discriminator network
def train_discriminator(
optimizer, data_real, data_fake, label_fake, label_real
):
# get the batch size
b_size = data_real.size(0)
# get the real label vector
real_label = label_real(b_size).to(DEVICE)
# get the fake label vector
fake_label = label_fake(b_size).to(DEVICE)
optimizer.zero_grad()
# get the outputs by doing real data forward pass
output_real = discriminator(data_real).view(-1)
loss_real = criterion(output_real, real_label)
# get the outputs by doing fake data forward pass
output_fake = discriminator(data_fake).view(-1)
loss_fake = criterion(output_fake, fake_label)
# real loss backprop
loss_real.backward()
# fake data loss backprop
loss_fake.backward()
# update discriminator parameters
optimizer.step()
loss = loss_real + loss_fake
return loss
# function to train the generator network
def train_generator(optimizer, data_fake, label_real):
# get the batch size
b_size = data_fake.size(0)
# get the real label vector
real_label = label_real(b_size).to(DEVICE)
optimizer.zero_grad()
# output by doing a forward pass of the fake data through discriminator
output = discriminator(data_fake).view(-1)
loss = criterion(output, real_label)
# backprop
loss.backward()
# update generator parameters
optimizer.step()
return loss
if __name__ == '__main__':
# Initialize SummaryWriter.
writer = initialize_tensorboard(DATASET)
# initialize the generator
generator = Generator(
NZ, IMAGE_SIZE, N_CHANNELS
).to(DEVICE)
# initialize the discriminator
discriminator = Discriminator(N_CHANNELS).to(DEVICE)
# initialize generator weights
generator.apply(weights_init)
# initialize discriminator weights
discriminator.apply(weights_init)
print('##### GENERATOR #####')
print(generator)
print_params(generator, 'Generator')
print('######################')
print('\n##### DISCRIMINATOR #####')
print(discriminator)
print_params(discriminator, 'Discriminator')
print('######################')
# optimizers
optim_g = optim.Adam(
generator.parameters(), lr=LEARNING_RATE, betas=(BETA1, BETA2)
)
optim_d = optim.Adam(
discriminator.parameters(), lr=LEARNING_RATE, betas=(BETA1, BETA2)
)
# loss function
criterion = nn.BCELoss()
losses_g = [] # to store generator loss after each epoch
losses_d = [] # to store discriminator loss after each epoch
batch_losses_g = [] # to store generator loss after each batch
batch_losses_d = [] # to store discriminator loss after each batch
images = [] # to store images generatd by the generator
generator.train()
discriminator.train()
# create the noise vector
noise = create_noise(SAMPLE_SIZE, NZ).to(DEVICE)
# train data loader
train_loader = return_data(
BATCH_SIZE, data=DATASET,
num_worders=NUM_WORKERS, image_size=IMAGE_SIZE
)
# create directory to save generated images, trained generator model...
# ... and the loss graph
make_output_dir(DATASET)
global_batch_iter = 0
for epoch in range(EPOCHS):
print(f"Epoch {epoch+1} of {EPOCHS}")
epoch_start = time.time()
loss_g = 0.0
loss_d = 0.0
for bi, data in enumerate(train_loader):
print(f"Batches: [{bi+1}/{len(train_loader)}]", end='\r')
image, _ = data
image = image.to(DEVICE)
b_size = len(image)
# run the discriminator for k number of steps
for step in range(K):
data_fake = generator(create_noise(b_size, NZ).to(DEVICE)).detach()
data_real = image
# train the discriminator network
bi_loss_d = train_discriminator(
optim_d, data_real, data_fake, label_fake, label_real
)
# add current discriminator batch loss to `loss_d`
loss_d += bi_loss_d
# append current discriminator batch loss to `batch_losses_d`
batch_losses_d.append(bi_loss_d.detach().cpu())
data_fake = generator(create_noise(b_size, NZ).to(DEVICE))
# train the generator network
bi_loss_g = train_generator(optim_g, data_fake, label_real)
# add current generator batch loss to `loss_g`
loss_g += bi_loss_g
# append current generator batch loss to `batch_losses_g`
batch_losses_g.append(bi_loss_g.detach().cpu())
# Add each batch Generator and Discriminator loss to TensorBoard
add_tensorboard_scalar(
'Batch_Loss', writer,
{'gen_batch_loss': bi_loss_g, 'disc_batch_loss': bi_loss_d},
global_batch_iter
)
if (bi+1) % PRINT_EVERY == 0:
print(f"[Epoch/Epochs] [{epoch+1}/{EPOCHS}], [Batch/Batches] [{bi+1}/{len(train_loader)}], Gen_loss: {bi_loss_g}, Disc_loss: {bi_loss_d}")
global_batch_iter += 1
# Save the generator model after the specified interval.
if (epoch+1) % GEN_MODEL_SAVE_INTERVAL == 0:
save_gen_model(
epoch+1, generator, optim_g, criterion,
f"outputs_{DATASET}/generator_{epoch+1}.pth"
)
# create the final fake image for the epoch
generated_img = generator(noise).cpu().detach()
# make the images as grid
generated_img = make_grid(generated_img)
# save the generated torch tensor models to disk
save_generator_image(generated_img, f"outputs_{DATASET}/gen_img{epoch+1}.png")
epoch_loss_g = loss_g / bi # total generator loss for the epoch
epoch_loss_d = loss_d / bi # total discriminator loss for the epoch
# Append current generator epoch loss to list.
losses_g.append(epoch_loss_g.detach().cpu())
# Append current discriminator epoch loss to list.
losses_d.append(epoch_loss_d.detach().cpu())
add_tensorboard_scalar(
'Epoch_Loss', writer,
{'disc_epoch_loss': epoch_loss_d, 'gen_epoch_loss': epoch_loss_g},
epoch
)
epoch_end = time.time()
print(f"Generator loss: {epoch_loss_g:.8f}, Discriminator loss: {epoch_loss_d:.8f}\n")
print(f"Took {(epoch_end-epoch_start):.3f} seconds for epoch {epoch+1}")
print('-'*50, end='\n')
print('DONE TRAINING')
# Save the generator model final time.
if (epoch+1) % GEN_MODEL_SAVE_INTERVAL == 0:
save_gen_model(
EPOCHS, generator, optim_g, criterion,
f"outputs_{DATASET}/generator_final.pth"
)
# save the generated images as GIF file
all_saved_image_paths = glob.glob(f"outputs_{DATASET}/gen_*.png")
imgs = [Image.open(image_path) for image_path in all_saved_image_paths]
imageio.mimsave(f"outputs_{DATASET}/generator_images.gif", imgs)
# save epoch loss plot
save_loss_plots(losses_g, losses_d, f"outputs_{DATASET}/epoch_loss.png")
# save batch loss plot
save_loss_plots(
batch_losses_g, batch_losses_d, f"outputs_{DATASET}/batch_loss.png"
)
loss不收敛?正常现象
我们化简后的训练目标是:
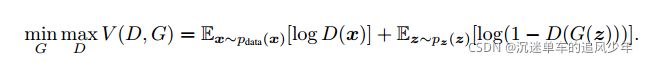
在训练D时,要使目标函数(二元交叉熵)极大化,即真数据尽可能输出接近1,假数据尽可能输出接近0。而训练G时,要使目标函数极小化。G要让目标函数后半部分尽可能小,即让D对假数据输出接近1(误判),实现欺骗。
所以G和D之间是一个零和博弈的过程,这个loss不像大多数深度学习任务那样,会由大变小,最终收敛。像下图这样来回震荡是正常现象。

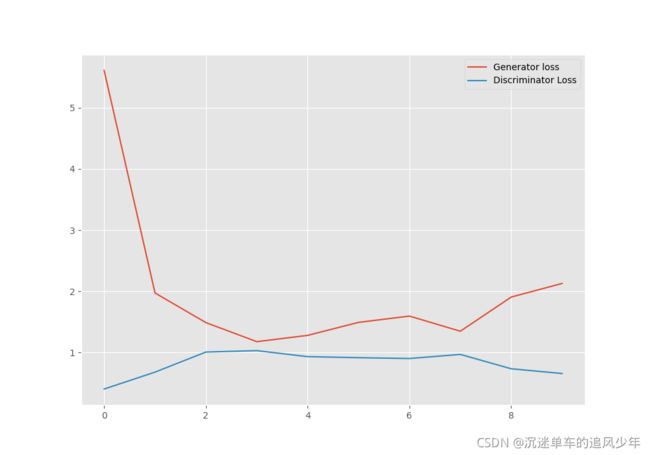
结果生成

参考:
- 生成对抗网络学习笔记3----论文unsupervised representation learning with deep convolutional generative adversarial_I am what i am-CSDN博客https://arxiv.org/pdf/1511.06434.pdf生成对抗网络学习笔记3----论文unsupervised representation learning with deep convolutional generative adversarial_I am what i am-CSDN博客
- Gan(生成式对抗网络)_百度百科
- GAN学习指南:从原理入门到制作生成Demo - 知乎
- 进入GAN的世界(一)DCGAN - 知乎