python面试常见问题
目录
- 1-10
- 11-20
- 21-30
- 31-40
- 41-50
1-10
1、一行代码实现1–100之和
# 1、一行代码实现1--100之和
sum(range(1,101))
2、如何在一个函数内部修改全局变量
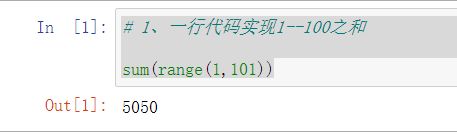
# 2、如何在一个函数内部修改全局变量
# 利用global在函数声明 修改全局变量
a = 6
def cos():
global a
a =4
cos()
print(a)

3、列出5个python标准库
os:提供了不少与操作系统相关联的函数
sys: 通常用于命令行参数
re: 正则匹配
math: 数学运算
datetime:处理日期时间
4、字典如何删除键和合并两个字典
# 4、字典如何删除键和合并两个字典
# del和update方法
dic = {
'n':'da','g':'asd','f':'ae'}
dic2 = {
'b':'sdf','k':'aef','l':'thn'}
del dic['n']
dic.update(dic2)
dic

5、谈下python的GIL
GIL 是python的全局解释器锁,同一进程中假如有多个线程运行,一个线程在运行python程序的时候会霸占python解释器(加了一把锁即GIL),使该进程内的其他线程无法运行,等该线程运行完后其他线程才能运行。如果线程运行过程中遇到耗时操作,则解释器锁解开,使其他线程运行。所以在多线程中,线程的运行仍是有先后顺序的,并不是同时进行。
多进程中因为每个进程都能被系统分配资源,相当于每个进程有了一个python解释器,所以多进程可以实现多个进程的同时运行,缺点是进程系统资源开销大
6、python实现列表去重的方法
# 6、python实现列表去重的方法
# 先通过集合去重,在转列表
list = [12,43,7,89,234,667,56,67,67,34,43]
a = set(list)
a # {
7, 12, 34, 43, 56, 67, 89, 234, 667}
list = [i for i in a]
list

7、fun(args,**kwargs)中的args,**kwargs什么意思?
# 7、fun(*args,**kwargs)中的*args,**kwargs什么意思?
# *args和**kwargs主要用于函数定义。你可以将不定数量的参数传递给一个函数。
# 这里的不定的意思是:预先并不知道,函数使用者会传递多少个参数给你所以在这个场景下使用这两个关键字。
# *args是用来发送一个非键值对的可变数量的参数列表给一个函数.
def d(args_a,*args_b):
print(args_a)
for i in args_b:
print(i)
d('a','b','y','y','k')

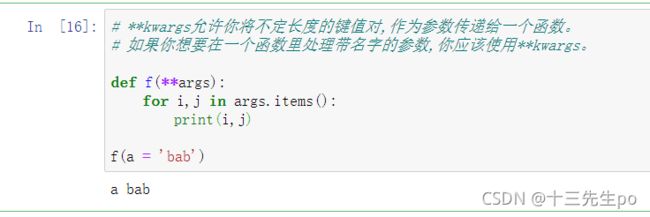
# **kwargs允许你将不定长度的键值对,作为参数传递给一个函数。
# 如果你想要在一个函数里处理带名字的参数,你应该使用**kwargs。
def f(**args):
for i,j in args.items():
print(i,j)
f(a = 'bab')
8、python2和python3的range(100)的区别
# 8、python2和python3的range(100)的区别
# python2返回列表,python3返回迭代器,节约内存
# 当后面没有元素可以next的时候,弹出错误
list = [1,2,45,5,64]
it = iter(list)
next(it) # 1
next(it) # 2
next(it) # 45
next(it) # 5
next(it) # 64
# next(it) # StopIteration Traceback (most recent call last)
# list、dict、str等是可迭代的但不是迭代器,因为next()函数无法调用它们。可以通过iter()函数将它们转换成迭代器。

list、dict、str等是可迭代的但不是迭代器,因为next()函数无法调用它们。可以通过iter()函数将它们转换成迭代器。
9、一句话解释什么样的语言能够用装饰器?
函数可以作为参数传递的语言,可以使用装饰器
10、python内建数据类型有哪些
整型–int
布尔型–bool
字符串–str
列表–list
元组–tuple
字典–dict
11-20
11、简述面向对象中__new__和__init__区别
# 11、简述面向对象中__new__和__init__区别
# __init__是初始化方法,创建对象后,就立刻被默认调用了,可接收参数
class Man(object):
def __init__(self,eyes,legs):
self.eyes = eyes
self.legs = legs
def run(self):
print('人会跑')
m = Man(2,2)
print('人的眼睛数量:%d'%m.eyes)
print('人的腿数量:%d'%m.legs)
1、__new__至少要有一个参数cls,代表当前类,此参数在实例化时由Python解释器自动识别
2、__new__必须要有返回值,返回实例化出来的实例,这点在自己实现__new__时要特别注意,可以return父类(通过super(当前类名, cls))__new__出来的实例,或者直接是object的__new__出来的实例
3、__init__有一个参数self,就是这个__new__返回的实例,__init__在__new__的基础上可以完成一些其它初始化的动作,__init__不需要返回值
4、如果__new__创建的是当前类的实例,会自动调用__init__函数,通过return语句里面调用的__new__函数的第一个参数是cls来保证是当前类实例,如果是其他类的类名,;那么实际创建返回的就是其他类的实例,其实就不会调用当前类的__init__函数,也不会调用其他类的__init__函数。
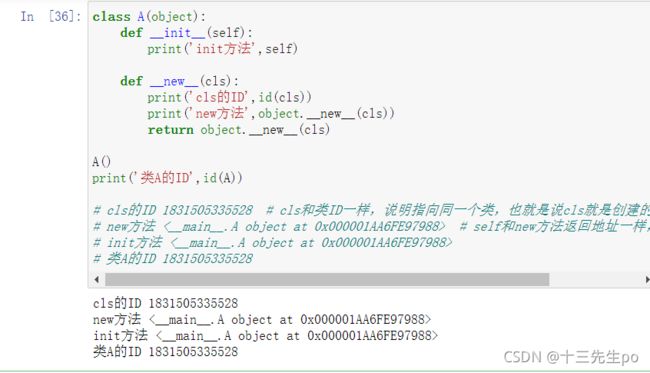
class A(object):
def __init__(self):
print('init方法',self)
def __new__(cls):
print('cls的ID',id(cls))
print('new方法',object.__new__(cls))
return object.__new__(cls)
A()
print('类A的ID',id(A))
# cls的ID 1831505335528 # cls和类ID一样,说明指向同一个类,也就是说cls就是创建的实例类
# new方法 <__main__.A object at 0x000001AA6FE97988> # self和new方法返回地址一样,说明返回值是对象
# init方法 <__main__.A object at 0x000001AA6FE97988>
# 类A的ID 1831505335528
12、简述with方法打开处理文件帮我我们做了什么?
# 12、简述with方法打开处理文件帮我我们做了什么?
f = open('./1.txt','wb')
try:
f.write('hello world')
except:
pass
finally:
f.close()
# 打开文件在进行读写的时候可能会出现一些异常状况,如果按照常规的f.open
# 写法,我们需要try,except,finally,做异常判断,并且文件最终不管遇到什么情况,都要执行finally f.close()关闭文件,with方法帮我们实现了finally中f.close
# (当然还有其他自定义功能,有兴趣可以研究with方法源码)

13、列表[1,2,3,4,5],请使用map()函数输出[1,4,9,16,25],并使用列表推导式提取出大于10的数,最终输出[16,25]
# 13、列表[1,2,3,4,5],请使用map()函数输出[1,4,9,16,25],并使用列表推导式提取出大于10的数,最终输出[16,25]
# map()函数第一个参数是fun,第二个参数是一般是list,第三个参数可以写list,也可以不写,根据需求
li = [1,2,3,4,5]
def f(x):
return x**2
re = map(f,li)
re # <map at 0x1aa6fe9e648>
r = [i for i in re if i > 10]
r

14、python中生成随机整数、随机小数、0–1之间小数方法
# 14、python中生成随机整数、随机小数、0--1之间小数方法
# 随机整数:random.randint(a,b),生成区间内的整数
# 随机小数:习惯用numpy库,利用np.random.randn(5)生成5个随机小数
# 0-1随机小数:random.random(),括号中不传参
import random
import numpy as np
r1 = random.randint(1,130)
r2 = np.random.randn(5)
r3 = random.random()
print('整数',r1)
print('随机小数',r2)
print('0-1之间小数',r3)

15、避免转义给字符串加哪个字母表示原始字符串?
r , 表示需要原始字符串,不转义特殊字符
16、
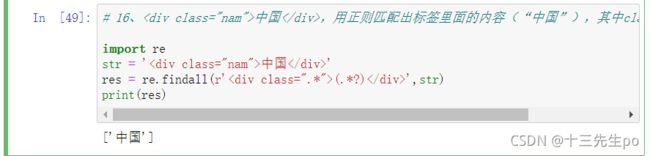
# 16、<div class="nam">中国</div>,用正则匹配出标签里面的内容(“中国”),其中class的类名是不确定的
import re
str = '中国'
res = re.findall(r'(.*?)',str)
print(res)
17、python中断言方法举例
# 17、python中断言方法举例
# assert()方法,断言成功,则程序继续执行,断言失败,则程序报错
a = 4
assert(a>1),'断言失败'
print('断言成功,继续执行')
# 断言成功,继续执行
b = 6
assert(b>10),'断言失败'
print('失败了')
# AssertionError: 断言失败

18、数据表student有id,name,score,city字段,其中name中的名字可有重复,需要消除重复行,请写sql语句
# 18、数据表student有id,name,score,city字段,其中name中的名字可有重复,需要消除重复行,请写sql语句
# select distinct name from student
19、10个Linux常用命令
# 19、10个Linux常用命令
# ls pwd cd touch rm mkdir tree cp mv cat more grep echo
20、python2和python3区别?列举5个
- 1、Python3 使用 print 必须要以小括号包裹打印内容,比如 print(‘hi’)
Python2 既可以使用带小括号的方式,也可以使用一个空格来分隔打印内容,比 如 print ‘hi’ - 2、python2 range(1,10)返回列表,python3中返回迭代器,节约内存
- 3、python2中使用ascii编码,python中使用utf-8编码
- 4、python2中unicode表示字符串序列,str表示字节序列
python3中str表示字符串序列,byte表示字节序列 - 5、python2中为正常显示中文,引入coding声明,python3中不需要
- 6、python2中是raw_input()函数,python3中是input()函数
21-30
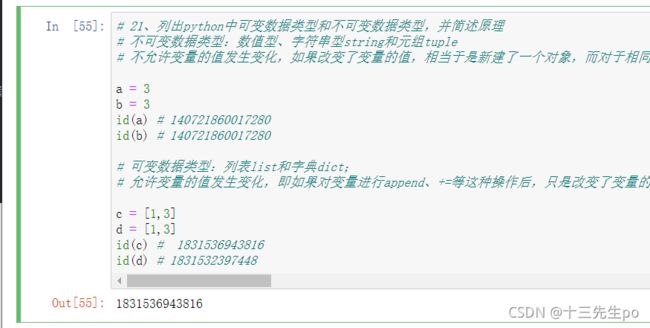
21、列出python中可变数据类型和不可变数据类型,并简述原理
# 21、列出python中可变数据类型和不可变数据类型,并简述原理
# 不可变数据类型:数值型、字符串型string和元组tuple
# 不允许变量的值发生变化,如果改变了变量的值,相当于是新建了一个对象,而对于相同的值的对象,在内存中则只有一个对象(一个地址),如下图用id()方法可以打印对象的id
a = 3
b = 3
id(a) # 140721860017280
id(b) # 140721860017280
# 可变数据类型:列表list和字典dict;
# 允许变量的值发生变化,即如果对变量进行append、+=等这种操作后,只是改变了变量的值,而不会新建一个对象,变量引用的对象的地址也不会变化,不过对于相同的值的不同对象,在内存中则会存在不同的对象,即每个对象都有自己的地址,相当于内存中对于同值的对象保存了多份,这里不存在引用计数,是实实在在的对象。
c = [1,3]
d = [1,3]
id(c) # 1831536943816
id(d) # 1831532397448
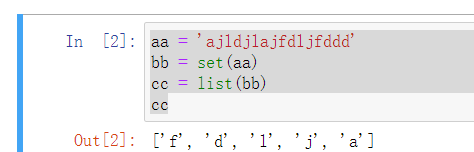
22、s = “ajldjlajfdljfddd”,去重并从小到大排序输出"adfjl"
# 22、s = "ajldjlajfdljfddd",去重并从小到大排序输出"adfjl"
# set去重,去重转成list,利用sort方法排序,reverse=False是从小到大排
# list是不 变数据类型,s.sort时候没有返回值,所以注释的代码写法不正确
aa = 'ajldjlajfdljfddd'
bb = set(aa)
bb
cc = list(bb)
cc
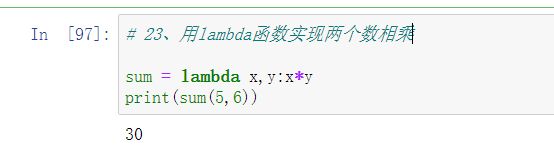
23、用lambda函数实现两个数相乘
# 23、用lambda函数实现两个数相乘
sum = lambda x,y:x*y
print(sum(5,6))
24、字典根据键从小到大排序
# 24、字典根据键从小到大排序
dic={
"name":"zs","age":18,"city":"深圳","tel":"1362626627"}
# lis = sorted(dic) # ['age', 'city', 'name', 'tel']
lis = sorted(dic.items(),key=lambda i:i[0],reverse=False)
lis
# 字典化
dict(lis)

25、利用collections库的Counter方法统计字符串每个单词出现的次数"kjalfj;ldsjafl;hdsllfdhg;lahfbl;hl;ahlf;h"
# 25、利用collections库的Counter方法统计字符串每个单词出现的次数"kjalfj;ldsjafl;hdsllfdhg;lahfbl;hl;ahlf;h"
from collections import Counter
a = "kjalfj;ldsjafl;hdsllfdhg;lahfbl;hl;ahlf;h"
res = Counter(a)
print(res)

26、字符串a = “not 404 found 张三 99 深圳”,每个词中间是空格,用正则过滤掉英文和数字,最终输出"张三 深圳"
# 26、字符串a = "not 404 found 张三 99 深圳",每个词中间是空格,用正则过滤掉英文和数字,最终输出"张三 深圳"
import re
a = "not 404 found 张三 99 深圳"
li = a.split(' ')
print(li) # ['not', '404', 'found', '张三', '99', '深圳']
res = re.findall('\d+|[a-zA-Z]+',a)
print(res) # ['not', '404', 'found', '99']
for i in res:
if i in li:
li.remove(i)
print(li) # ['张三', '深圳']
new = ' '.join(li)
print(new) # 张三 深圳
print('============================')
# 贴上匹配小数的代码,虽然能匹配,但是健壮性有待进一步确认
res2 = re.findall('\d+\.?\d*|[a-zA-Z]+',a)
print(res2) # ['not', '404', 'found', '99']
for i in res2:
if i in li:
li.remove(i)
new2 = ' '.join(li)
print(new2) # 张三 深圳

27、filter方法求出列表所有奇数并构造新列表,a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 27、filter方法求出列表所有奇数并构造新列表,a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# filter() 函数用于过滤序列,过滤掉不符合条件的元素,
# 返回由符合条件元素组成的新列表。
# 该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,
# 然后返回 True 或 False,最后将返回 True 的元素放到新列表
# 方法1
def double(a):
return a%2 == 1
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
list1 = filter(double,a)
list1 # 返回地址 <filter at 0x1aa76b41648>
new_list = [i for i in list1]
new_list

28、列表推导式求列表所有奇数并构造新列表,a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 28、列表推导式求列表所有奇数并构造新列表,a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
res = [i for i in a if i%2 ==1]
res

29、正则re.complie作用
re.compile是将正则表达式编译成一个对象,加快速度,并重复使用
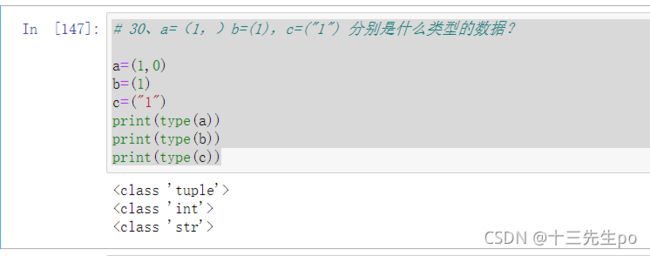
30、a=(1,)b=(1),c=(“1”) 分别是什么类型的数据?
# 30、a=(1,)b=(1),c=("1") 分别是什么类型的数据?
a=(1,0)
b=(1)
c=("1")
print(type(a))
print(type(b))
print(type(c))
31-40
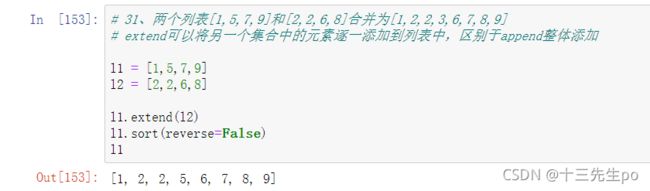
31、两个列表[1,5,7,9]和[2,2,6,8]合并为[1,2,2,3,6,7,8,9]
# 31、两个列表[1,5,7,9]和[2,2,6,8]合并为[1,2,2,3,6,7,8,9]
# extend可以将另一个集合中的元素逐一添加到列表中,区别于append整体添加
l1 = [1,5,7,9]
l2 = [2,2,6,8]
l1.extend(l2)
l1.sort(reverse=False)
l1
32、用python删除文件和用linux命令删除文件方法
python:os.remove(文件名)
linux: rm 文件名
33、log日志中,我们需要用时间戳记录error,warning等的发生时间,请用datetime模块打印当前时间戳 “2018-04-01 11:38:54”
# 33、log日志中,我们需要用时间戳记录error,warning等的发生时间,请用datetime模块打印当前时间戳 “2018-04-01 11:38:54”
# 顺便把星期的代码也贴上了
import datetime
# now_time = datetime.datetime.now().strftime('%y-%m-%d %H:%M:%S')
# day = datetime.datetime.now().isoweekday()
# type(day) # int
# now_time
total = str(datetime.datetime.now().strftime('%y-%m-%d %H:%M:%S'))+'星期:'+str(datetime.datetime.now().isoweekday())
# 已放错误调试文件中

34、数据库优化查询方法
外键、索引、联合查询、选择特定字段等等
35、请列出你会的任意一种统计图(条形图、折线图等)绘制的开源库,第三方也行
pyecharts、matplotlib
# 36、写一段自定义异常代码
# 自定义异常用raise抛出异常
def c():
try:
for i in range(6):
if i > 4:
raise Exception('数字大于4了')
except Exception as ret:
print(ret)
c()

37、正则表达式匹配中,(.)和(.?)匹配区别?
# 37、正则表达式匹配中,(.*)和(.*?)匹配区别?
# (.*)是贪婪匹配,会把满足正则的尽可能多的往后匹配
# (.*?)是非贪婪匹配,会把满足正则的尽可能少匹配
import re
s = '哈哈嘿嘿'
r1 = re.findall('(.*)',s)
print('贪婪匹配:',r1)
r2 = re.findall('(.*?)',s)
print('非贪婪匹配:',r2)

38、简述Django的orm
ORM,全拼Object-Relation Mapping,意为对象-关系映射
实现了数据模型与数据库的解耦,通过简单的配置就可以轻松更换数据库,而不需要修改代码只需要面向对象编程,orm操作本质上会根据对接的数据库引擎,翻译成对应的sql语句,所有使用Django开发的项目无需关心程序底层使用的是MySQL、Oracle、sqlite…,如果数据库迁移,只需要更换Django的数据库引擎即可

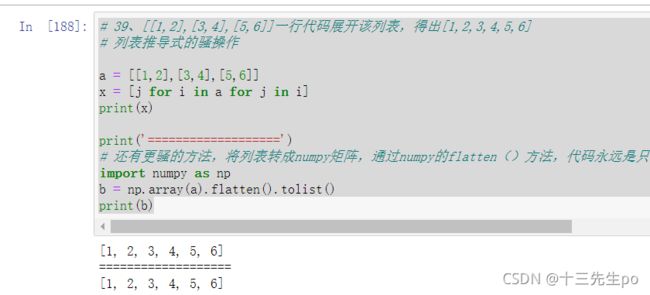
39、[[1,2],[3,4],[5,6]]一行代码展开该列表,得出[1,2,3,4,5,6]
# 39、[[1,2],[3,4],[5,6]]一行代码展开该列表,得出[1,2,3,4,5,6]
# 列表推导式的骚操作
a = [[1,2],[3,4],[5,6]]
x = [j for i in a for j in i]
print(x)
print('===================')
# 还有更骚的方法,将列表转成numpy矩阵,通过numpy的flatten()方法,代码永远是只有更骚,没有最骚
import numpy as np
b = np.array(a).flatten().tolist()
print(b)
40、x=“abc”,y=“def”,z=[“d”,“e”,“f”],分别求出x.join(y)和x.join(z)返回的结果
# 40、x="abc",y="def",z=["d","e","f"],分别求出x.join(y)和x.join(z)返回的结果
# join()括号里面的是可迭代对象,x插入可迭代对象中间,形成字符串,结果一致,有没有突然感觉字符串的常见操作都不会玩了
# 顺便建议大家学下os.path.join()方法,拼接路径经常用到,也用到了join,和字符串操作中的join有什么区别,该问题大家可以查阅相关文档,后期会有答案
x="abc"
y="def"
z=["d","e","f"]
m = x.join(y)
print(m)
print('=================')
b = x.join(z)
print(b)

41-50
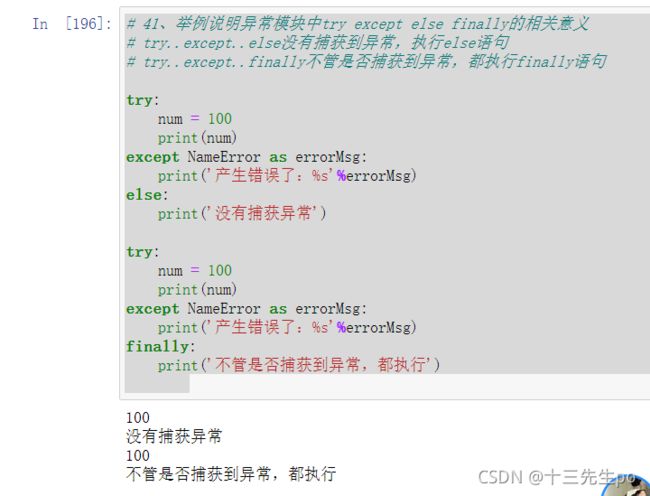
41、举例说明异常模块中try except else finally的相关意义
# 41、举例说明异常模块中try except else finally的相关意义
# try..except..else没有捕获到异常,执行else语句
# try..except..finally不管是否捕获到异常,都执行finally语句
try:
num = 100
print(num)
except NameError as errorMsg:
print('产生错误了:%s'%errorMsg)
else:
print('没有捕获异常')
try:
num = 100
print(num)
except NameError as errorMsg:
print('产生错误了:%s'%errorMsg)
finally:
print('不管是否捕获到异常,都执行')
42、python中交换两个数值
# 42、python中交换两个数值
d,h = 3,5
print(d,h)
h,d = d,h
print(d,h)

43、举例说明zip()函数用法
# 43、举例说明zip()函数用法
# zip()函数在运算时,会以一个或多个序列(可迭代对象)做为参数,返回一个元组的列表。同时将这些序列中并排的元素配对。
# zip()参数可以接受任何类型的序列,同时也可以有两个以上的参数;当传入参数的长度不同时,zip能自动以最短序列长度为准进行截取,获得元组。
# 列表
a = [1,2]
b = [3,4]
r1 = [ i for i in zip(a,b)]
print(r1)
# 元组
a = (34,7)
b = (87,98)
r2 = [ i for i in zip(a,b)]
print(r2)
# 字符串
a = 'sd'
b = 'nrt'
r3 = [ i for i in zip(a,b)]
print(r3)

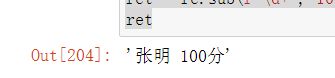
44、a=“张明 98分”,用re.sub,将98替换为100
# 44、a="张明 98分",用re.sub,将98替换为100
import re
a="张明 98分"
ret = re.sub(r'\d+','100',a)
ret
45、写5条常用sql语句
show databases;
show tables;
desc 表名;
select * from 表名;
delete from 表名 where id=5;
update students set gender=0,hometown=“北京” where id=5
46、a="hello"和b="你好"编码成bytes类型
# 46、a="hello"和b="你好"编码成bytes类型
a="hello".encode()
b="你好".encode()
print(type(a),type(b))

47、[1,2,3]+[4,5,6]的结果是多少?
# 47、[1,2,3]+[4,5,6]的结果是多少?
# 两个列表相加,等价于extend
a = [1,2,3]
b = [4,5,6]
c = a + b
c
48、提高python运行效率的方法
1、使用生成器,因为可以节约大量内存
2、循环代码优化,避免过多重复代码的执行
3、核心模块用Cython PyPy等,提高效率
4、多进程、多线程、协程
5、多个if elif条件判断,可以把最有可能先发生的条件放到前面写,这样可以减少程序判断的次数,提高效率
49、简述mysql和redis区别
redis: 内存型非关系数据库,数据保存在内存中,速度快
mysql:关系型数据库,数据保存在磁盘中,检索的话,会有一定的Io操作,访问速度相对慢
50、遇到bug如何处理
1、细节上的错误,通过print()打印,能执行到print()说明一般上面的代码没有问题,分段检测程序是否有问题,如果是js的话可以alert或console.log
2、如果涉及一些第三方框架,会去查官方文档或者一些技术博客。
3、对于bug的管理与归类总结,一般测试将测试出的bug用teambin等bug管理工具进行记录,然后我们会一条一条进行修改,修改的过程也是理解业务逻辑和提高自己编程逻辑缜密性的方法,我也都会收藏做一些笔记记录。
4、导包问题、城市定位多音字造成的显示错误问题
51、正则匹配,匹配日期2018-03-20
# 51、正则匹配,匹配日期2018-03-20
# url='https://sycm.taobao.com/bda/tradinganaly/overview/get_summary.json?dateRange=2018-03-20%7C2018-03-20&dateType=recent1&device=1&token=ff25b109b&_=1521595613462'
# 仍有同学问正则,其实匹配并不难,提取一段特征语句,用(.*?)匹配即可
url='https://sycm.taobao.com/bda/tradinganaly/overview/get_summary.json?dateRange=2018-03-20%7C2018-03-20&dateType=recent1&device=1&token=ff25b109b&_=1521595613462'
r1 = re.findall(r'dateRange=(.*?)%7C(.*?)&',url)
r1
