大数据生态(十)集成部署遭遇问题(提前、zk、hdfs)汇总
目录
1 .bash_profile和/etc/profile
问题说明
问题解答
现象说明
原因说明
解决
操作
2 赋权问题
2.1 e3base应用目录权限
原因
解决方案
2.2 SSH互联失败
原因
解决方案
3 Zookeeper 启动问题
3.1 Log目录错误
原因
解决方案
3.2 zookeeper启动成功,关联集群失败
现象
原因
解决方案
成果
hadoop运行失败
4 Hadoop启动问题
4.1 配置文件问题
说明
原因
解决方案
4.2 datanode启动报错
说明
原因
解决
4.3 datanode存活时间短暂后挂掉
现象说明
原因
解决方案
指定顺序
4.4 datanode问题补充
4.4.1 namenode报错信息:
4.4.2尝试解决
1.bash_profile和/etc/profile
问题说明
1、平常看B站之类的教学视频配置环境都是在/etc/profile里面设置环境变量然后可以采用which hadoop查看应用安装目录和版本信息(hadoop version),为什么按照部署文档部署的配置环境变量在.bash_profile呢?而不是在/etc/profile呢?
2、切换用户组用户:由root用户切换e3base后,环境配置失效。
问题解答
现象说明
将.bash_profile配置的是root用户而不是用户组用户,导致不成功。
原因说明
root用户拥有十分巨大的权限。在root用户的.bash_profile配置环境变量,实质上是等价于在/etc/profile里面配置变量的。
而一个用户对应有自己的.bash_profile配置文件。
实际生产中不会用root用户进行使用,而是用用户组用户进行操作——为了安全生产。
这就导致,用户组用户(比如说e3base)的.bash_profile在切换后是空的,需要重新配置。
PS:甚至对于个别root用户权限的文档后续还需要赋权。
解决
切换用户组用户,重新部署.bash_profile文件。以后均使用实际使用用户配置环境。
操作
.bash_profile路径:/home/用户名/.bash_profile
cd
vi .bash_profile
PATH=$PATH:$HOME/bin
export E3_INFO_HOME=/e3base/e3-info
export IN_HOME=/e3base
export ZOO_HOME=$IN_HOME/zookeeper
export HADOOP_HOME=$IN_HOME/hadoop
export PATH=$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$ZOO_HOME/bin:$PATH
2赋权问题
2.1 e3base应用目录权限
原因
之前用root用户创建/e3base目录导致用户组用户无权访问/e3base下的应用;
chown -R e3base:e3base_lxg /e3base/
解决方案
/e3base目录由root创建,用户组用户没有操作权限。

chmod -R 777 /e3base

2.2 SSH互联失败
原因
密钥文件authorized_keys依旧是权限不够
解决方案
赋权前,默认Touch authorized_keys

赋权后:
chmod 600 authorized_keys

3Zookeeper启动问题
3.1Log目录错误
原因
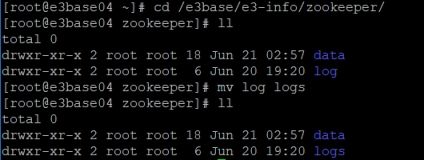
Mkdir创建logs目录的时候少打了s,导致目录错误。
解决方案
修改root/e3base/e3-info/zookeeper/log 为logs
3.2 zookeeper启动成功,关联集群失败
现象
解析集群主机IP失败,未关联
原因
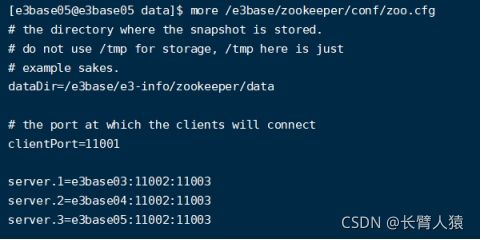
hosts文件未将集群所有主机录进去解析,仅仅是将本机虚拟机录进去解析。
Hosts解析

解决方案
在每个集群主机中补全配置主机名称和IP解析。
成果

Hadoop内存问题
注意到前面文档:
vim /e3base/hadoop/etc/hadoop/hadoop-env.sh
注:配置文件中HADOOP_HEAPSIZE、HADOOP_NAMENODE_OPTS、HADOOP_DATANODE_OPTS参数中的JVM堆内存大小,如在测试环境,请注意修改这些参数中的-Xms -Xms -Xmn值符合当前主机环境,如堆内存值配置过大超过系统可用内存,会导致服务启动失败。

一般将上面出现的参数名字的参数全修改小,(200/300),默认参数未生产环境的参数,我们带不动。

hadoop运行失败
/e3base/hadoop/sbin/start-dfs.sh
提示:
![]()
翻看e3-info日志文件:
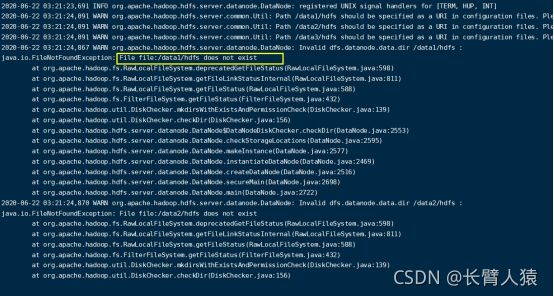
使用root创建/var/run/hadoop-hdfs/目录
并通过chown给e3base用户和组赋权;sudo chmod -R 755 /var/run/hadoop-hdfs/
OR : chown -R e3base:e3base_lxg /var/run/hadoop-hdfs/

4 Hadoop启动问题
4.1 配置文件问题
说明
原本的部署文档是按照五台虚拟机进行部署的,即两台管理节点(namenode)主机,三台datanode数据节点主机。分别对应为:
管理节点:e3base01、e3base02;
数据节点:e3base03、e3base04、e3base05;
原因
而我们部署用三台,两台复用管理和数据节点,一台单独数据节点。那么默认配置文档就出现了问题了——主机数量对不上。
解决方案
hadoop核心配置文件:
vi hdfs-site.xml
4.1.1 修改主机对应的管理节点主机名
说明:nn对应的是管理节点主机名称。
我们这儿复用,改为对应的管理节点主机(数量不多)名称:e3base03、e3base0。

4.1.2统一用户组的用户名称
原因:免去一个个配用户的操作。同时每台主机的用户组不互通【组里面的用户也不互通】

PATH=$PATH:$HOME/.local/bin:$HOME/bin
export E3_INFO_HOME=/e3base/e3-info
export IN_HOME=/e3base
export ZOO_HOME=$IN_HOME/zookeeper
export HADOOP_HOME=$IN_HOME/hadoop
export PATH=$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$ZOO_HOME/bin:$PATH
4.2datanode启动报错
说明
原因
4.2.1/var/run/hadoop-hdfs文件
可能存在的三个原因
l /var/run/hadoop-hdfs文件未创建
l /var/run/hadoop-hdfs文件未赋权
l /var/run/hadoop-hdfs文件hadoop自动删除
4.2.2data1/2/3目录权限未赋予
1、查看日志文件寻找错误定位;
2、注意配置文件默认的数据路径是这个,要创建并赋权或者去该配配置文件也可以
解决
针对4.2.1
\1. 切换root权限,初始化目录: mkdir /var/run/hadoop-hdfs
\2. 编辑 vi /usr/lib/tmpfiles.d/e3base.conf 写入:d /var/run/hadoop-hdfs 0755 e3base e3base - -
\3. 或者执行 : echo ‘d /var/run/hadoop-hdfs 0755 e3base e3base - -’ >/usr/lib/tmpfiles.d/e3base.conf
PS: 手动赋权:
Datanoded的/var/run/hadoop-hdfs关闭被删除
mkdir /var/run/hadoop-hdfs
[root@e3base03 e3base]# chown -R e3base:e3base_lxg /var/run/hadoop-hdfs
针对4.2.2
mkdir -p data3/hdfs
chown -R e3base:e3base_lxg /data1
4.3datanode存活时间短暂后挂掉
现象说明
datanode能起来,但是往往存活时间不长,自动被杀死。
原因
4.3.1 namenode在集群主机中ID未保持一致;
4.3.2 hadoop元数据收到损坏。
4.3.3 未按正确步骤启动,可能导致4.3.2
解决方案
1、清空Jn 和Nn文件,因为datanode和namenode的id配不上;
2、清空data1/2/3 hdfs目录下的数据文件;
3、然后重新初始化;
4、切记按照指定顺序初始化和启动服务进程。
指定顺序
l 初始化zkfc
l 启动journal node
l 初始化主namenode
l 启动namenode
l 启动zkfc
l 启动datanode
4.4 datanode问题补充
4.4.1namenode报错信息:
Block pool ID needed, but service not yet registered with NN, trace… …
4.4.2尝试解决
重新拷贝正确主机目录给错误主机
主节点们之间,元素据未同步(其中一个跑不起的损坏),拷贝能跑的nn数据到不能跑的nn节点. scp -r nn [email protected] /e3base/e3-info/hadoop/
ERROR namenode.FSImage: Error replaying edit log at offset 0. Expected transaction ID was 3
org.apache.hadoop.hdfs.server.namenode.RedundantEditLogInputStream$PrematureEOFException: got premature end-of-file at txid 0; expected file to go up to 3
修复命令
hadoop namenode -recover
从报错来看,,是获取edit log日志出错。说白点,就是namenode元数据破坏了,需要修复。
解决:
(1)、在出错的机器执行如下命令,一路按c或者y
修改对其ID

namenode clusterID 和datanode clusterID 不一致导致的差异:
两种解决方案:
1、将data1/2/3/hdfs/下面的文件全删除,重新初始化namenode;
2、修改至ID一致:
将hdfs/current/VERSION 文件中的 clusterID的值覆盖
/current/VERSION 文件中的 clusterID的=后面
也就是让name data两个的clusterID保持一致
3、启动顺序:journal node -> namenode->zkfc->最后datanode;
总体:
l 初始化zkfc
l 启动journal node
l 初始化主namenode
l 启动namenode
l 启动zkfc
l 启动datanode
补充
1 日志文件报错:无法写入namenode日志
报错详情
Error replaying edit log namenode
原因
元数据损坏
解决方案
删除e3base03下的current里面的所有数据再拷贝过去
![]()
scp * e3base03:/e3base/e3-info/hadoop/nn/current/
2 问题1解决后datanode挂掉
现象
问题一解决后datanode起不来。
原因
nomenodeid改变。
解决方案
将/data1/2/2下面的Version文件里面的namenodeID替换统一
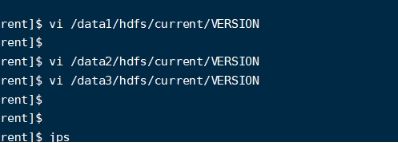
datanode找data/1/2/3
Namenode 找nn
ClusterID ->保持一致。
原因2临时缓存目录设置问题

解决方案
