一、Storm简介
1. 引例
在介绍Storm之前,我们先看一个日志统计的例子:假如我们想要根据用户的访问日志统计使用斗鱼客户端的用大数据培训户的地域分布情况,一般情况下我们会分这几步:
• 取出访问日志中客户端的IP
• 把IP转换成对应地域
• 按照地域进行统计
Hadoop貌似就可以轻松搞定:
• map做ip提取,转换成地域
• reduce以地域为key聚合,计数统计
• 从HDFS取出结果
如果有时效性要求呢?
• 小时级:还行,每小时跑一个MapReduce Job
• 10分钟:还凑合能跑
• 5分钟 :够呛了,等槽位可能要几分钟呢
• 1分钟 :算了吧,启动Job就要几十秒呢
• 秒级 :… 要满足秒级别的数据统计需求,需要
• 进程常驻运行;
• 数据在内存中
Storm正好适合这种需求。
2. 特性
Storm是一个分布式实时流式计算平台。主要特性如下:
• 简单的编程模型:类似于MapReduce降低了并行批处理复杂性,Storm降低了实时处理的复杂性,只需实现几个接口即可(Spout实现ISpout接口,Bolt实现IBolt接口)。
• 支持多种语言:你可以在Storm之上使用各种编程语言。默认支持Clojure、Java、Ruby和Python。要增加对其他语言的支持,只需实现一个简单的Storm通信协议即可。
• 容错性:nimbus、supervisor都是无状态的, 可以用kill -9来杀死Nimbus和Supervisor进程, 然后再重启它们,任务照常进行; 当worker失败后, supervisor会尝试在本机重启它。
• 分布式:计算是在多个线程、进程和服务器之间并行进行的。
• 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失。
• 可靠的消息处理:Storm保证每个消息至少能得到一次完整处理。任务失败时,它会负责从消息源重试消息(ack机制)。
• 快速、实时:Storm保证每个消息能能得到快速的处理。
3. 与常用其他大数据计算平台对比
• Storm vs. MapReduce Storm的一个拓扑常驻内存运行,MR作业运行完了进行就被kill了;storm是流式处理,MR是批处理;Storm数据在内存中不写磁盘,而MR会与磁盘进行交互;Storm的DAG(有向无环图)模型可以组合多个阶段,而MR只可以有MAP和REDUCE两个阶段。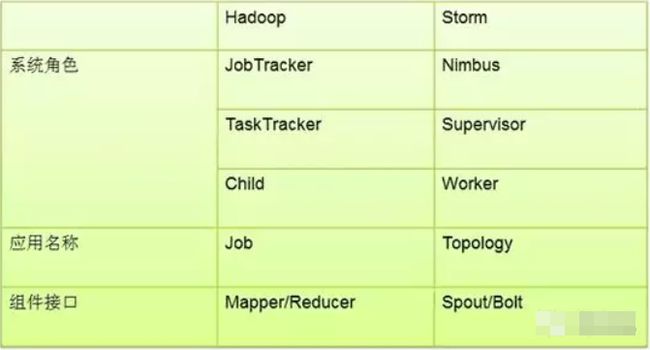
Storm vs. Spark Streaming Storm处理的是每次传入的一条数据,Spark Streaming实际处理的是微批量数据。
二、Storm的架构和运行时原理
1. 集群架构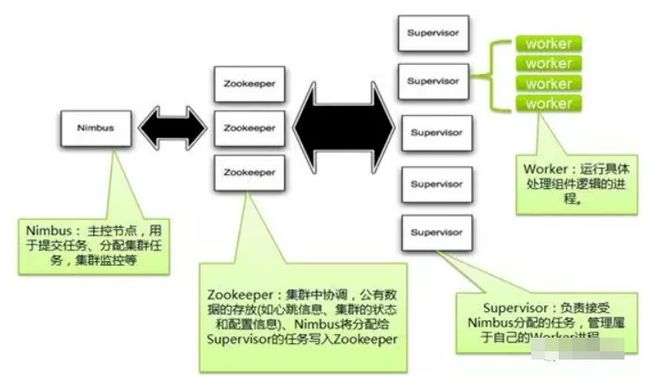
如上图所示,一个典型的storm集群包含一个主控节点Nimbus,负责资源分配和任务调度;还有若干个子节点Supervisor,负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程;Nimbus和Supervisor之间的所有协调工作都是通过Zookeeper集群完成。
2. Storm的容错(Fault Tolerance)机制
Nimbus和Supervisor进程被设计成快速失败(fail fast)的(当遇到异常的情况,进程就会挂掉)并且是无状态的(状态都保存在Zookeeper或者在磁盘上)。
- Nimbus与Supervisor本身也是无状态的,状态信息是由zookeeper存储(实现了高可用,当nimbus挂掉,可以找另外一个节点启动nimbus进程,状态信息从zookeeper获得)。
- 在Nimbus进程失败后,可以快速重启恢复正常工作,不需要很长的时间来进行初始化和状态恢复。
- 当Nimbus从zookeeper得知有supervisor节点挂掉,可以将该节点的任务重新分配给其他子节点。
- Nimbus在“某种程度”上属于单点故障的。在实际中,即使Nimbus进程挂掉,也不会有灾难性的事情发生 。
当Nimbus挂掉会怎样?
- 已经存在的拓扑可以继续正常运行,但是不能提交新拓扑;
- 正在运行的worker进程仍然可以继续工作。而且当worker挂掉,Supervisor会一直重启worker。
- 失败的任务不会被分配到其他机器(是Nimbus的职责)上了
当一个Supervisor(slave节点)挂掉会怎样?
- 分配到这台机器的所有任务(task)会超时,Nimbus会把这些任务(task)重新分配给其他机器。当一个worker挂掉会怎么样?
- 当一个worker挂掉,Supervisor会重启它。如果启动一直失败那么此时worker也就不能和Nimbus保持心跳了,Nimbus会重新分配worker到其他机器
3. Storm的编程模型
Strom在运行中可分为spout与bolt两个组件,其中,数据源从spout开始,数据以tuple的方式发送到bolt,多个bolt可以串连起来,一个bolt也可以接入多个spot/bolt。运行时Topology如下图: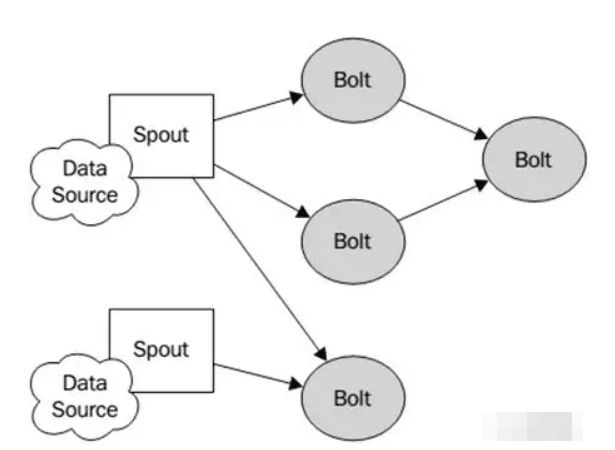
编程模型的一些基本概念:
• 元组
• storm使用tuple(元组)来作为它的数据模型。每个tuple由一堆域(field)组成,每个域有一个值,并且每个值可以是任何类型。
• 一个tuple可以看作一个没有方法的java对象。总体来看,storm支持所有的基本类型、字符串以及字节数组作为tuple的值类型。
• Spout
• i. BaseRichSpout是实现 IRichSpout接口的类,对上述必要的方法有默认的实现;
• ii. 如果业务需要自定义ack()、fail() 等方法,选择实现 IRichSpout接口;
• iii. 如果业务没有自定义需求,选择继承BaseRichSpout类,可以不实现并不一定需要用户实现的方法,简化开发。
• i. open方法是初始化动作。允许你在该spout初始化时做一些动作,传入了上下文,方便取上下文的一些数据。
• ii. close方法在该spout关闭前执行。
• iii. activate和deactivate :一个spout可以被暂时激活和关闭,这两个方法分别在对应的时刻被调用。
• iv. nextTuple 用来发射数据。Spout中最重要的方法。
• v. ack(Object)传入的Object其实是一个id,唯一表示一个tuple。该方法是这个id所对应的tuple被成功处理后执行。
• vi. fail(Object)同ack,只不过是tuple处理失败时执行。
• Spout是在一个topology中产生源数据流的组件。通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源数据。Spout是一个主动的角色,其接口中有个nextTuple()函数,storm框架会不停地调用此函数,用户只要在其中生成源数据即可。
• 实现Spout时,需要实现最顶层抽象ISpout接口里面的几个方法
• 实现Spout时,还需要实现Icomponent接口,来声明发射到下游bolt的字段名称。
• 通常情况下,实现一个Spout,可以直接实现接口IRichSpout,如果不想写多余的代码,可以直接继承BaseRichSpout。
• Bolt
• prepare方法是初始化动作。允许你在该Bolt初始化时做一些动作,传入了上下文,方便取上下文的一些数据。
• excute 用来处理数据。Bolt中最重要的方法。
• cleanup在该Bolt关闭前执行.
• 在拓扑中所有的计算逻辑都是在Bolt中实现的。一个Bolt可以处理任意数量的输入流,产生任意数量新的输出流。Bolt可以做函数处理,过滤,流的合并,聚合,存储到数据库等操作。在Bolt中最主要的函数是execute函数,它使用一个新的元组当作输入。Bolt使用OutputCollector对象来吐出新的元组。
• 实现Bolt时,需要实现IBolt接口,它声明了Bolt的核心方法,负责Topology所有的计算逻辑:
• 实现Bolt时,还需要实现Icomponent接口,来声明发射到下游bolt的字段名称
• 通常情况下,实现一个Bolt ,可以直接实现接口IRichBolt/IBasicBolt,也可以直接继承BaseRichBolt/BaseBasicBolt。IBasicBolt/BaseBasicBolt在emit数据的时候,会自动和输入的tuple相关联,而在execute方法结束的时候那个输入tuple会被自动ack。使用IRichBolt/BaseRichBolt需要在emit数据的时候,显示指定该数据的源tuple要加上第二个参数anchor tuple,以保持tracker链路,即collector.emit(oldTuple,newTuple);并且需要在execute执行成功后调用OutputCollector.ack(tuple), 当失败处理时,执行OutputCollector.fail(tuple)。
• Stream Groupings(流分组)
• 定义了一个流在Bolt任务间该如何被切分。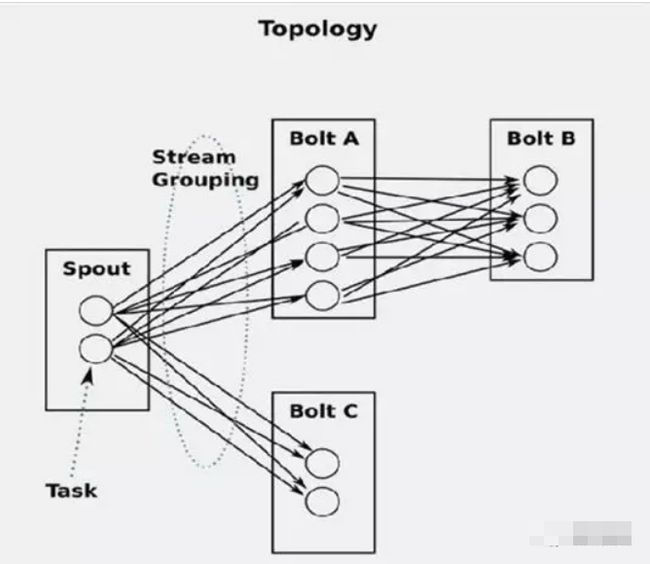
- 随机分组(Shuffle grouping):随机分发tuple到Bolt的任务,保证每个任务获得相等数量的tuple。
- 字段分组(Fields grouping):根据指定字段分割数据流,并分组。例如,根据“user-id”字段,相同“user-id”的元组总是分发到同一个任务,不同“user-id”的元组可能分发到不同的任务。
- 全部分组(All grouping):tuple被复制到bolt的所有任务。这种类型需要谨慎使用。
- 全局分组(Global grouping):全部流都分配到bolt的同一个任务。明确地说,是分配给ID最小的那个task。
- 无分组(None grouping):你不需要关心流是如何分组。目前,无分组等效于随机分组。
- 直接分组(Direct grouping):这是一个特别的分组类型。元组生产者决定tuple由哪个元组处理者任务接收。
4. Storm消息处理的可靠性机制
可靠性机制(Ack机制)指的是Storm可以保证从Spout发出的每个消息都能被完全处理。一条消息被“完整处理”,指一个从Spout发出的元组所触发的消息树中所有的消息都被Storm处理了。如果在指定的超时时间里,这个Spout元组触发的消息树中有任何一个消息没有处理完,就认为这个Spout元组处理失败了。这个超时时间是通过每个拓扑的Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS配置项来进行配置的,默认是30秒。
Storm 是这样实现可靠性机制的:
• Storm 的拓扑有一些特殊的称为“acker”的任务,这些任务负责跟踪每个 Spout 发出的 tuple 的 DAG。当一个 acker 发现一个 DAG 结束了,它就会给创建 spout tuple 的 Spout 任务发送一条消息,让这个任务来应答这个消息。你可以使用Config.TOPOLOGY_ACKERS 来配置拓扑的 acker 数量。Storm 默认会将 acker 的数量设置为1,不过如果你有大量消息的处理需求,你可能需要增加这个数量。
• acker任务跟踪一个元组树,只占用固定大小的空间(大约20字节)。若采用 Ack机制,每个处理的tuple, 必须被ack或者fail。因为storm追踪每个tuple要占用内存。所以如果不ack/fail每一个tuple, 那么最终你会看到OutOfMemory错误。
• 编程实现(必要条件):acker数设置大于0;Spout发送元组时,指定messageId;bolt处理完元组时,一定要调用ack/fail方法。
5. Storm的并发机制
在一个 Storm 集群中,Storm 主要通过以下三个部件来运行拓扑:工作进程(worker processes)、执行器(executors)、任务(tasks)。三者的关系如下: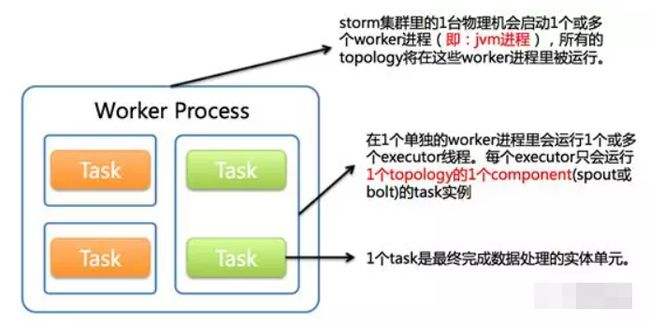
• 1个worker进程执行的是1个topology的子集(注:不会出现1个worker为多个topology服务)。1个worker进程会启动1个或多个executor线程来执行1个topology的component(spout或bolt)。因此,1个运行中的topology就是由集群中多台物理机上的多个worker进程组成的。
• executor是1个被worker进程启动的单独线程。每个executor只会运行1个topology的1个component(spout或bolt)的task(注:task可以是1个或多个,storm默认是1个component只生成1个task,executor线程里会在每次循环里顺序调用所有task实例)。
• task是最终运行spout或bolt中代码的单元(注:1个task即为spout或bolt的1个实例,executor线程在执行期间会调用该task的nextTuple或execute方法)。topology启动后,1个component(spout或bolt)的task数目是固定不变的,但该component使用的executor线程数可以动态调整(例如:1个executor线程可以执行该component的1个或多个task实例)。这意味着,对于1个component存在这样的条件:#threads<=#tasks(即:线程数小于等于task数目)。默认情况下task的数目等于executor线程数目,即1个executor线程只运行1个task。
三、构建基于Storm的实时数据分析平台实战经验
构建基于Storm的实时数据分析平台,第一步当然应该是搭建storm集群。这个网上的教程还有轮子实在是太多,我就不贴出来了。请大家Google或者Baidu之,然后一步步搭建集群就完了。
1. Storm使用的一些实战经验
• 在架构上,推荐 “消息中间件 + storm + 外部存储” 3架马车式架构
• Storm从消息中间件中取出数据,计算出结果,存储到外部存储上
• 通常消息中间件推荐使用RocketMQ,Kafka
• 外部存储推荐使用HBase,Redis
• 该架构,非常方便Storm程序进行重启(如因为增加业务升级程序)
• 职责清晰化,减少和外部系统的交互,Storm将计算结果存储到外部存储后,用户的查询就无需访问Storm中服务进程,查询外部存储即可。在实际计算中,常常发现需要做数据订正,因此在设计整个项目时,需要考虑重跑功能 。在最终生成的结果中,数据最好带时间戳 。
• 结合Storm UI查看topology各个组件的负载,合理配置各组件的并发度。
• Spout和Bolt的构造函数只会在submit Topology时调一次,然后序列化起来,直接发给工作节点,工作节点里实例化时不会被调用里,所以复杂的成员变量记得都定义成transient,在open(),prepare()里初始化及连接数据库等资源。
• 按照性能来说, 使用ack机制普通接口 < 关掉ack机制的普通接口, 因此,需要根据业务对数据处理的速率需求决定是否采用ack机制。
• 当使用fieldGrouping方式时,有可能造成有的task任务重,有的task任务轻,因此让整个数据流变慢, 尽量让task之间压力均匀。
• KafkaSpout的并发度最好设置成Kafka的分区数。消费Kafka时, 一个分区只能一个线程消费,因此有可能简单的增加并发无法解决问题, 可以尝试增加Kafka的分区数。
• 如果topology性能有问题, 可以尝试关掉ack机制,查看性能如何,如果性能有大幅提升,则预示着瓶颈不在spout, 有可能是Acker的并发少了,或者业务处理逻辑慢了。
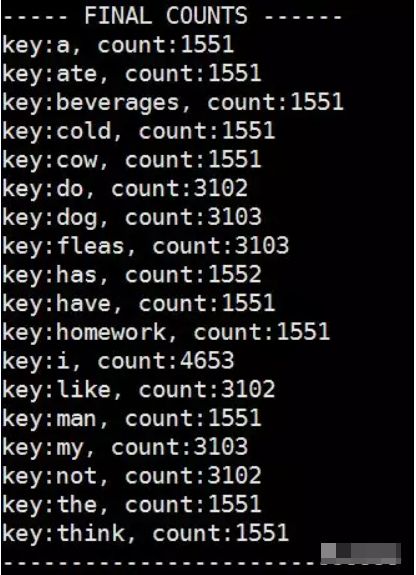
2. Storm编程实践-WordCount
• Spout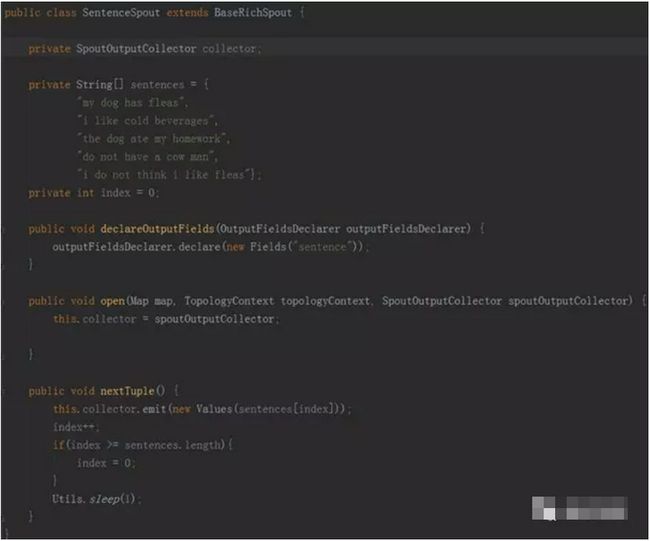
• SpiltSentenceBolt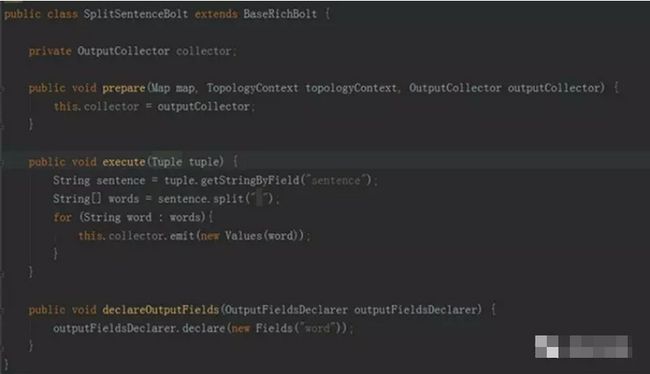
• WordCountBolt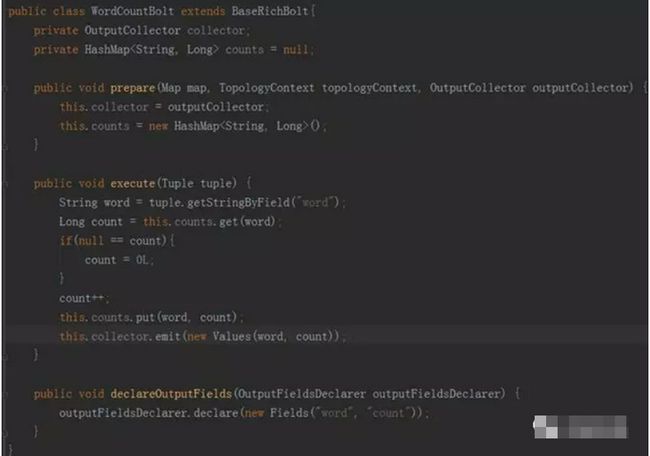
• ReportBolt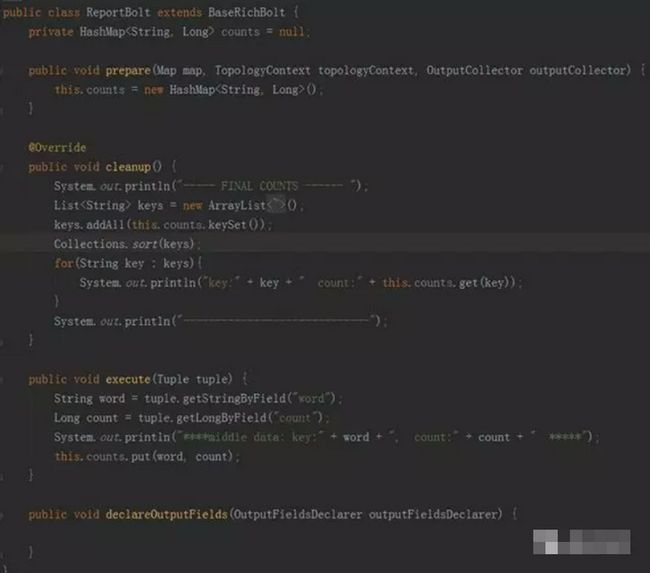
• Topology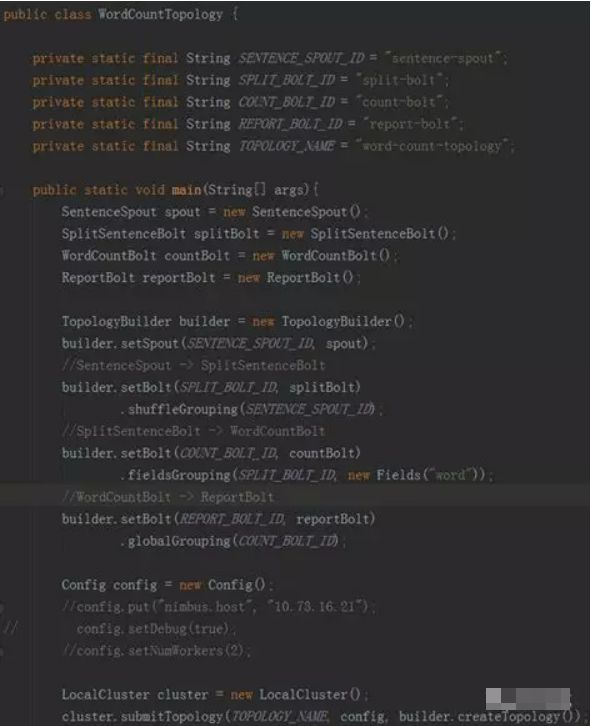
• Result