基于Python的并发编程
文章目录
-
- 并发编程概述
-
- Python速度慢的原因
- 全局解释器锁(Global Interpreter Lock,GIL)
- CPU密集型计算&IO密集型计算
- 多进程&多线程&多协程的使用
-
- 多进程
-
- 1.多进程的优势
- 多线程
-
- 1.普通多线程
- 2.生产者消费者模式的多线程
- 3.线程安全的多线程
- 4.使用线程池的多线程
- 5.Flask中使用线程池加速IO
- 多协程
-
- 1.asyncio实现异步IO
- 2.信号量控制异步IO的并发数
并发编程概述
-
为什么要引用并发编程?
- 为了提升程序运行速度
-
并发编程的实现提速的方法有哪些?
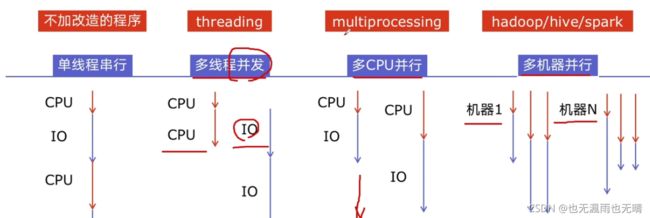
-
Python对并发编程的支持模块有哪些?
模块名 作用 threading实现多线程,利用计算机CPU和IO可以同时执行的原理,让CPU在计算机IO操作过程中访问另一任务。 multprocessing实现多进程,利用多核CPU的能力,真正的并行执行任务。 asyncio实现异步IO,在单线程利用CPU和IO同时执行的原理,实现函数粒度的异步执行。 Lock实现对资源的加锁,防止资源竞争和访问冲突问题。 Queue实现不同线程、进程之间的数据通讯,实现生产者-消费者模式。 线程池/进程池(Pool)实现简化线程、进程的任务提交、等待结束、获取结果等方式。 subprocess实现启动外部程序的进程(如.exe程序),并进行输入输出交互。
Python速度慢的原因
-
相比C/C++/Java来说,Python确实慢,在一些特殊场景下,Python比C++慢100~200倍,因此很多公司的基础架构代码仍用C/C++开发,比如推荐引擎、搜索引擎、存储引擎等对底层性能要求高的模块。
-
那Python慢的主要原因有哪些?
-
动态类型语言,边解释边执行
变量的定义没有类型限制,需要随时检查数据类型,性能下降
缺少源码翻译为机器码的步骤,机器码执行很快,但Python边翻译边执行,很慢
-
GIL的存在:

-
全局解释器锁(Global Interpreter Lock,GIL)
- 是计算机程序设计语言解释器用于同步线程的一种机制,它保证任何时刻仅有一个线程在执行,即便在多核处理器上,使用GIL的解释器也只允许同一时间执行一个线程,别的语言并发编程,可以将多个线程分配在不同的核上处理。
- 为何存在?
- 为了解决多线程之间数据完整性和状态同步的问题。
- Python中对象的管理,是使用引用技术器实现的,引用数为0则释放对象,当两个线程同时调用一个对象时,在释放对象问题上,会产生冲突,造成错误,因此加锁,保证引用计数在每个线程中都同步。
- 如何规避GIL带来的限制?
- 根据CPU密集型和IO密集型选择多进程和多线程。
CPU密集型计算&IO密集型计算
| 类型 | 说明 | 常见场景 |
|---|---|---|
| CPU密集型计算(CPU-bound) | CPU密集型计算,也叫计算密集型,是指I/O在很短的时间就可以完成,CPU需要大量的计算和处理,特点是CPU占用率相当高。 | 压缩、解压缩、正则表达式搜索 |
| IO密集型计算(I/O-bound) | IO密集型计算是指系统运作大部分的状况是CPU在等I/O(硬盘/内存)的读写操作,CPU占用率较低。 | 文件处理程序、网络请求、读写数据库 |
多进程&多线程&多协程的使用
| 名称 | 优点 | 缺点 | 场景 |
|---|---|---|---|
多进程(multprocessing) |
可以利用多核CPU并行运算 | 占用资源最多,可启动的数目比线程少 | CPU密集型计算 |
多线程(threading) |
相比进程:更轻量级,占用资源少 | 相比进程:多线程只能并发执行,不能利用多CPU(GIL);相比协程:启动数目有限制,占用内存资源,有线程切换开销 | IO密集型计算,同时运行的任务数目不太多 |
多协程【Coroutine】(asyncio) |
内存开销最少,启动数目最多 | 支持的库有限制(aiohttp支持,requests不支持),代码实现复杂 | IO密集型计算,同时运行的任务数目很多,但需库支持的场景 |
- 多进程&多线程实现概览

强烈建议下文阅读顺序与写文顺序一致(非排版顺序):多线程、多进程、多协程。
多进程
1.多进程的优势
-
计算一百个较大数字是否为素数(CPU-bound)
import math import time from concurrent.futures import ThreadPoolExecutor from concurrent.futures import ProcessPoolExecutor PRIMES = [112272535095293] * 100 def timer(f): def inner(): start_time = time.time() f() print(time.time() - start_time) return inner def is_prime(n): if n < 2: return False if n == 2: return True if n % 2 == 0: return False sqrt_n = int(math.floor(math.sqrt(n))) for i in range(3, sqrt_n + 1, 2): if n % i == 0: return False return True @timer def single_thread(): for n in PRIMES: is_prime(n) @timer def multi_thread(): with ThreadPoolExecutor() as pool: pool.map(is_prime, PRIMES) @timer def multi_process(): with ProcessPoolExecutor() as pool: pool.map(is_prime, PRIMES) if __name__ == '__main__': single_thread() multi_thread() multi_process() # 54.2112915 单线程 # 55.0219151 多线程 # 10.2812801 多进程可以看出CPU密集型计算时多线程反而速度更低,多进程速度最快。
-
如上代码运行后,生成多个Python解释器进程(任务管理器):
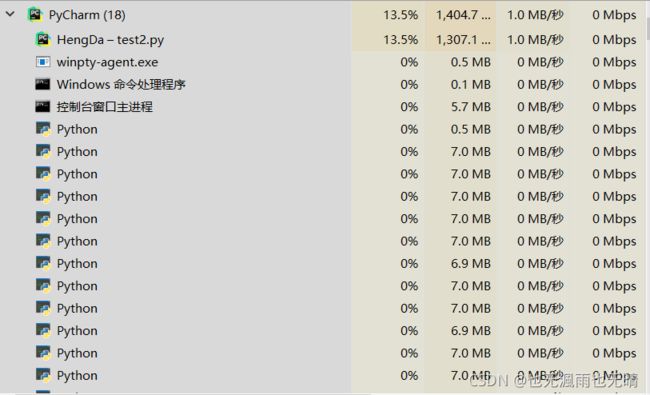
-
多线程对CPU-bound无用

多线程
1.普通多线程
-
单线程和多线程的速度比较
import time import threading # 任务函数 def run_task(task): print(f'线程:{ threading.current_thread().name}', '正在执行任务:', task) # 阻塞两秒,用于模拟网络请求等IO操作 time.sleep(2) # 单线程运行五个任务 def single_thread(): start_time = time.time() for task in range(1, 6): run_task(task) print('cost:' , time.time() - start_time) # 多线程运行五个任务 def multi_thread(): start_time = time.time() threads = [] # 此处开辟了五个线程,过多的线程会有切换开销,需要合理创建线程数。 for task in range(1, 6): threads.append( threading.Thread(target=run_task, args=(task,)) ) # 启动线程 for thread in threads: thread.start() # 线程等待 for thread in threads: thread.join() print('cost' , time.time() - start_time) if __name__ == '__main__': single_thread() multi_thread() -
结果如下:
线程:MainThread 正在执行任务: 1 # 均为主线程运行 线程:MainThread 正在执行任务: 2 线程:MainThread 正在执行任务: 3 线程:MainThread 正在执行任务: 4 线程:MainThread 正在执行任务: 5 <single_thread> cost: 10.036925792694092 线程:Thread-1 正在执行任务: 1 # 开创的线程1-5 线程:Thread-2 正在执行任务: 2 线程:Thread-3 正在执行任务: 3 线程:Thread-4 正在执行任务: 4 线程:Thread-5 正在执行任务: 5 <multi_thread> cost 2.003706693649292 # 速度还是有明显提高的,当然本例只是简单的演示,具体还需依据场景而定。
2.生产者消费者模式的多线程
import time
import threading
import queue
# 任务函数
def run_task(queue_obj):
# 判断任务队列是否为空,获取下一条任务数据
while not queue_obj.empty():
task = queue_obj.get()
print(f'线程:{
threading.current_thread().name}', '正在执行任务:', task)
# 阻塞两秒,用于模拟网络请求等IO操作
time.sleep(2)
def single_thread(queue_obj):
start_time = time.time()
run_task(queue_obj)
print(' cost:' , time.time() - start_time)
# 多线程,开辟五个线程,用于消费生产数据,即queue_obj中的任务数据
def multi_thread(queue_obj):
start_time = time.time()
threads = []
for task in range(1, 6):
threads.append(
threading.Thread(target=run_task, args=(queue_obj,))
)
for thread in threads:
thread.start()
for thread in threads:
thread.join()
print(' cost' , time.time() - start_time)
if __name__ == '__main__':
# 分别开启两个生产者,填充任务数据
queue_obj = queue.Queue()
queue_obj2 = queue.Queue()
for task in range(1, 6):
queue_obj.put(task)
single_thread(queue_obj)
for task in range(1, 6):
queue_obj2.put(task)
multi_thread(queue_obj2)
# 结果同上
3.线程安全的多线程
线程安全:
某个函数、函数库在多线程环境中被调用时,能够正确处理多个线程之间的共享变量,是程序功能正确完成。
-
如例暴露线程安全问题:
import threading # lock = threading.Lock() # 使用锁解决冲突 # 账户类,属性余额 class Account: def __init__(self, balance): self.balance = balance # 取钱,当索取数量>=余额,正确;否则返回`余额不足` def draw(account, amount): # 上锁解决冲突 # with lock: if account.balance >= amount: time.sleep(0.1) # 模拟线程阻塞 print(threading.current_thread().name, 'success') account.balance -= amount print(threading.current_thread().name, '余额:', account.balance) else: print(threading.current_thread().name, '余额不足') if __name__ == '__main__': account = Account(1000) ta = threading.Thread(name='ta', target=draw, args=(account,800)) tb = threading.Thread(name='tb', target=draw, args=(account,800)) ta.start() tb.start()-
结果如下:
tb 取钱成功 tb 余额 200 ta 取钱成功 ta 余额 -600 # 问题暴露,由于当线程切换时,账户属性还未变化时,会产生数据不同步的问题。解决方法:
使用
Lock上锁,当线程切换时,必须先拿到锁,才能切换,保证数据的同步性。
-
4.使用线程池的多线程
-
线程的生命周期

-
线程池的原理:
- 新建线程需要系统分配资源、终止线程系统需要回收资源,如果可以将新建的线程保存起来并重复利用,则可以减去新建、终止线程的开销——线程池。
-
线程池的优点:
- 提升性能:减少系统新建、终止的开销,重用了线程资源。
- 适合处理突发的大量请求或需要大量线程完成任务,但实际任务处理较短。
- 防御功能:能有效的避免系统由于线程创建过多,而导致系统负荷过大的问题。
-
使用方法1:
import time import threading import concurrent.futures def run_task(tasks): time.sleep(2) return f'{ tasks}执行完成' # 任务列表 tasks = [('任务' + str(i)) for i in range(1, 6)] start_time = time.time() with concurrent.futures.ThreadPoolExecutor() as pool: # 创建池 result = pool.map(run_task, tasks) # 传递函数和任务列表,返回值`result`是包含 每一个任务对象返回值 的 生成器 results = list(zip(tasks, result)) for i, j in results: print(i, j) print(time.time() - start_time) # 结果如下: 任务1 任务1执行完成 任务2 任务2执行完成 任务3 任务3执行完成 任务4 任务4执行完成 任务5 任务5执行完成 2.0206351280212402 -
使用方法2:
import time import threading import concurrent.futures def run_task(tasks): time.sleep(2) return f'{ tasks}执行完成' # 任务列表 tasks = [('任务' + str(i)) for i in range(1, 6)] start_time = time.time() with concurrent.futures.ThreadPoolExecutor() as pool: results = { } for task in tasks: # 传递函数和单个任务 # 返回`futures`对象:# 该对象有`result`方法,返回当前任务的返回值 futures = pool.submit(run_task, task) results[task] = futures for i, j in results.items(): print(i, j.result()) # 注意调用位置 print(time.time() - start_time) # 结果同上
5.Flask中使用线程池加速IO
import json
import time
import flask
import cpncurrent
app = flask.Flask(__name__)
# 模拟磁盘IO
def read_file():
time.sleep(0.1)
return "file result"
# 模拟数据库IO
def connect_db():
time.sleep(0.2)
return "db result"
# 模拟调用apiIO
def create_api():
time.sleep(0.3)
return "api result"
@app.route('/')
def index():
file_io = read_file()
db_io = connect_db()
api_io = create_api()
return json.dumps({
"file_io": file_io,
"db_io": db_io,
"api_io": api_io,
})
if __name__ == '__main__':
app.run()
# 使用 time curl 返回结果:
0.623s
-
使用线程池改造:
import json import time from concurrent.futures import ThreadPoolExecutor import flask app = flask.Flask(__name__) pool = ThreadPoolExecutor() # 初始化线程池对象 def connect_db(): time.sleep(0.5) return "db result" def read_file(): time.sleep(0.3) return "file result" def create_api(): time.sleep(0.2) return "api result" @app.route('/') def index(): # 提交任务 file_io = pool.submit(read_file) db_io = pool.submit(connect_db) api_io = pool.submit(create_api) return json.dumps({ "file_io": file_io.result(), # 获取结果对象 "db_io": db_io.result(), "api_io": api_io.result(), }) if __name__ == '__main__': # 多进程池定义于此 app.run() # 使用 time curl 返回结果: 0.318s # IO时间减半多进程池类似与多线程池,不过由于不共享环境,需要定义在mian入口函数内。
多协程
- 基本原理

使用异步IO时,需要保证依赖库支持异步IO特性。爬虫为例,则需要使用
aiohttp,requests暂不支持异步IO。
1.asyncio实现异步IO
import time
import asyncio
import aiohttp
urls = [
f"https://www.cnblogs.com/sitehome/p/{
page}"
for page in range(1, 50 + 1)
]
# 定义协程:
# async关键字表示事件循环之后调用的步骤
# await关键字表示,到达该IO时,不阻塞,而是进行下一次循环,继续去调用async代码
async def async_spider(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
result = await resp.text()
print(f'{
url},{
len(result)}')
# 构造事件循环对象
loop = asyncio.get_event_loop()
# 创建任务列表
tasks = [
loop.create_task(async_spider(url))
for url in urls
]
start_time = time.time()
# 循环等待至tasks中的任务完成
loop.run_until_complete(asyncio.wait(tasks))
print(time.time() - start_time)
# 3.1056487560272217
2.信号量控制异步IO的并发数
- 信号量

import time
import asyncio
import aiohttp
urls = [
f"https://www.cnblogs.com/sitehome/p/{
page}"
for page in range(1, 50 + 1)
]
# 定义信号量
semaphore = asyncio.Semaphore(10)
async def async_spider(url):
async with semaphore: # 信号量控制
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
result = await resp.text()
await asyncio.sleep(3)
# 每阻塞三秒实现十个并发
print(f'{
url},{
len(result)}')
loop = asyncio.get_event_loop()
tasks = [
loop.create_task(async_spider(url))
for url in urls
]
start_time = time.time()
loop.run_until_complete(asyncio.wait(tasks))
print(time.time() - start_time)
# 3.1056487560272217