flask + pyecharts 疫情数据分析 搭建交互式动态可视化疫情趋势分析、舆情监测平台(附代码实现)
该项目是浙江大学地理空间数据库课程作业8:空间分析中,使用 flask + pyecharts 搭建的简单新冠肺炎疫情数据可视化交互分析平台的一部分,完整的实现包含疫情数据获取、态势感知、预测分析、舆情监测等任务;
包含完整代码、数据集和实现的github地址:
https://github.com/yunwei37/COVID-19-NLP-vis
项目分析报告已部署到网页端,可点击http://flask.yunwei123.tech/进行查看,数据已更新到6.17
本项目采用flask作为后端,使用pyecharts进行数据可视化,通过ajax实现动态交互可视化效果;
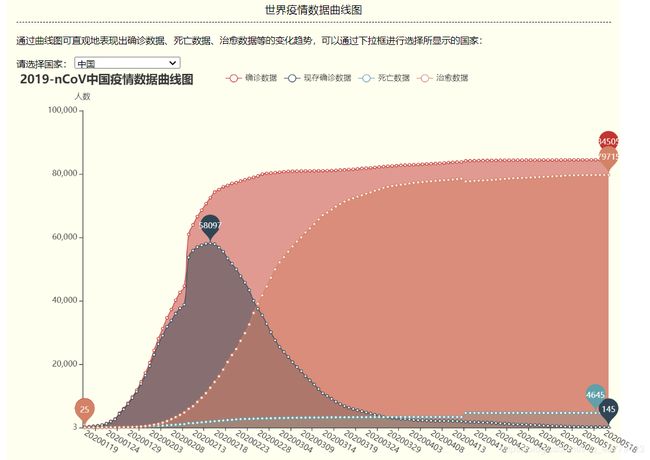
疫情数据曲线图、日历图
疫情数据曲线图:可选择国家
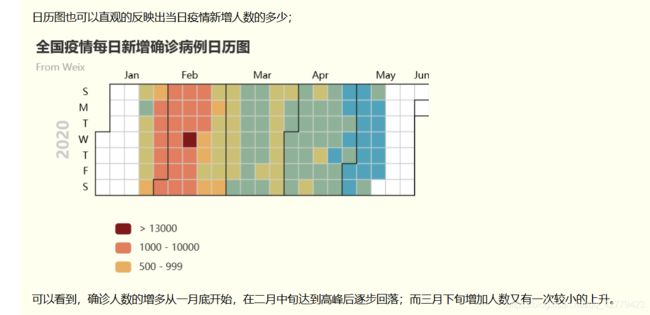
 疫情新增确诊病例日历图:
疫情新增确诊病例日历图:
pyecharts 代码实现:
import time, json
import pandas as pd
import pyecharts.options as opts
from pyecharts.charts import Line
from pyecharts.commons.utils import JsCode
country_name = '中国'
def render_lines(country_name):
#-------------------------------------------------------------------------------------
# 第一步:读取数据
#-------------------------------------------------------------------------------------
n = "dataSets\\countrydata.csv"
data = pd.read_csv(n)
data = data[data['countryName'] == country_name]
date_list = list(data['dateId'])
date_list = list(map(lambda x:str(x),date_list))
confirm_list = list(data['confirmedCount'])
current_list = list(data['currentConfirmedCount'])
dead_list = list(data['deadCount'])
heal_list = list(data['curedCount'])
print(len(date_list))
#print(date_list) # 日期
#print(confirm_list) # 确诊数据
#print(current_list) # 疑似数据
#print(dead_list) # 死亡数据
#print(heal_list) # 治愈数据
#-------------------------------------------------------------------------------------
# 第二步:绘制折线面积图
#-------------------------------------------------------------------------------------
line = (
Line()
.add_xaxis(date_list)
# 平均线 最大值 最小值
.add_yaxis('确诊数据', confirm_list, is_smooth=True,
markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="max"),
opts.MarkPointItem(type_="min")]))
.add_yaxis('现存确诊数据', current_list, is_smooth=True,
markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="max"),
opts.MarkPointItem(type_="min")]))
.add_yaxis('死亡数据', dead_list, is_smooth=True,
markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="max"),
opts.MarkPointItem(type_="min")]))
.add_yaxis('治愈数据', heal_list, is_smooth=True,
markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="max"),
opts.MarkPointItem(type_="min")]))
# 隐藏数字 设置面积
.set_series_opts(
areastyle_opts=opts.AreaStyleOpts(opacity=0.5),
label_opts=opts.LabelOpts(is_show=False))
# 设置x轴标签旋转角度
.set_global_opts(xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30)),
yaxis_opts=opts.AxisOpts(name='人数', min_=3),
title_opts=opts.TitleOpts(title='2019-nCoV'+country_name+'疫情数据曲线图'))
)
return line
import datetime
from pyecharts import options as opts
from pyecharts.charts import Calendar
def calendar_base() -> Calendar:
begin = datetime.date(2020, 1, 19) #设置起始日期
end = datetime.date(2020, 6, 17) #设置终止日期
n = "dataSets\\countrydata.csv"
data = pd.read_csv(n)
data = data[data['countryName'] == country_name]
date_list = list(data['dateId'])
date_list = list(map(lambda x:str(x),date_list))
confirm_list = list(data['confirmedIncr'])
data =[
[str(begin + datetime.timedelta(days=i)), confirm_list[i]] #设置日期间隔,步数范围
for i in range((end - begin).days - 3)
]
print(len(data))
c = (
Calendar()
.add('', data, calendar_opts=opts.CalendarOpts(range_=['2020-1','2020-6'])) #添加到日历图,指定显示2019年数据
.set_global_opts( #设置底部显示条,解释数据
title_opts=opts.TitleOpts(title='全国疫情每日新增确诊病例日历图',subtitle='From Weix'),
visualmap_opts=opts.VisualMapOpts(
pieces=[
{
'min': 13000, 'color': '#7f1818'}, #不指定 max
{
'min': 1000, 'max': 10000},
{
'min': 500, 'max': 999},
{
'min': 100, 'max': 499},
{
'min': 10, 'max': 99},
{
'min': 0, 'max': 9} ],
orient='vertical', #设置垂直显示
pos_top='230px',
pos_left='100px',
is_piecewise=True #是否连续
)
)
)
return c
if __name__ == "__main__":
calendar_base().render('全国疫情每日新增确诊病例日历图.html')
前端html:
疫情数据分析词云图:

pyecharts 代码实现:
# coding=utf-8
import jieba
import re
import time
from collections import Counter
import pandas as pd
import datetime
#------------------------------------中文分词------------------------------------
#截取该日期前后的10%文章
#percent = 0-90
def generatewordData(percent):
cut_words = ""
all_words = ""
data = pd.read_csv('dataSets\\中国社会组织_疫情防控-5_21.csv')
percent = percent / 10
num = data.shape[0]/10
data = data.iloc[int(num*percent):int(num*percent+num),]
print(data.shape[0])
print(list(data['时间'])[0])
print(list(data['时间'])[-1])
for line in data['正文内容']:
line = str(line)
seg_list = jieba.cut(line,cut_all=False)
cut_words = (" ".join(seg_list))
all_words += cut_words
# 输出结果
all_words = all_words.split()
# 词频统计
c = Counter()
for x in all_words:
if len(x)>1 and x != '\r\n':
c[x] += 1
words = []
for (k,v) in c.most_common(50):
# print(k, v)
words.append((k,v))
words = words[1:]
return words,list(data['时间'])[0],list(data['时间'])[-1]
# 渲染图
from pyecharts import options as opts
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
#import wordData
# percent 0-90
def render_wordcloud(percent = 0) -> WordCloud:
from scripts.wordData import date_data
words = date_data[int(percent)][0]
c = (
WordCloud()
.add("", words, word_size_range=[20, 100], shape=SymbolType.ROUND_RECT)
.set_global_opts(title_opts=opts.TitleOpts(title='全国新型冠状病毒疫情新闻词云图'+' '+date_data[int(percent)][1]+' - '+date_data[int(percent)][2]))
)
return c
# 生成图
if __name__ == "__main__":
date_words = []
for i in range(0,91):
print(i)
words,date_start,date_end = generatewordData(i)
date_words.append([words,date_start,date_end])
with open("wordData.py",'w',encoding='utf-8') as f:
f.write("date_data="+str(date_words))
f.close()
微博情感分析曲线图
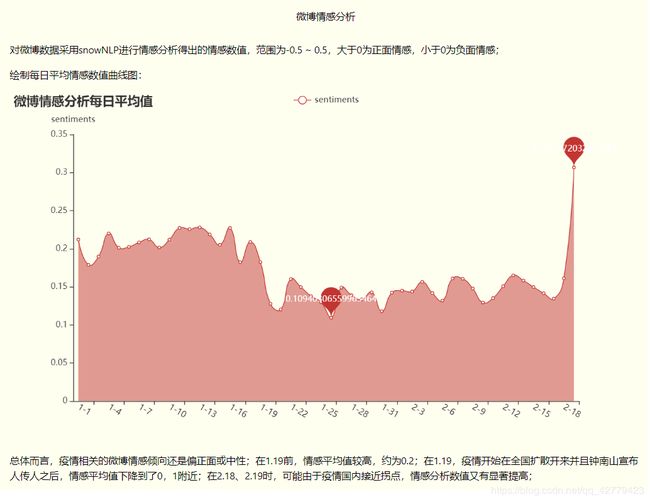
`pyecharts 代码实现:
# dateId: 0-50
def weiboWordcloud(dateId):
from scripts.weiboWordData import date_data
words = date_data[int(dateId)][1]
date = date_data[int(dateId)][0]
c = (
WordCloud()
.add("", words, word_size_range=[20, 100], shape=SymbolType.ROUND_RECT)
.set_global_opts(title_opts=opts.TitleOpts(title='全国新型冠状病毒疫情微博每日主题词词云图 '+str(date)))
)
return c