从0开始的python学习:编译原理实验2:词法分析器1--状态转换图方法
继续先把实验报告上的先搬上来。目前还停留在简单粗暴地解决问题的层次,对代码效率没有任何的考虑。
实验二:词法分析器1–状态转换图方法
实验目的: 通过编写一个只包含部分保留字和单词符号(见语言子集L)的C语言的扫描器(词法分析器),掌握编译器的方法之一—状态转换图法。
实验要求:
1、该词法分析器的任务如下:
1)滤掉源程序中的无用成分,如空格;
2)输出分类记号供语法分析器使用,并产生两个表格(符号表):常数表和变量表(即标识符表),分别记录曾扫描到的变量和常量,表的数据结构和包含内容自行定义;
3)识别非法输入,并将其标记为“出错记号”。
2、该词法分析器的功能:
以在下面段落3中定义的PASCAL语言子集的源程序作为词法分析程序的输入,即源程序,源程序段存放在文件中。词法分析器打开该文件后,自文件头开始扫描源程序字符,发现符合“单词”定义的源程序字符串时,将它翻译成固定长度的单词内部表示,并查填适当的信息表(符号表),一旦发现不符合“单词”定义的源程序字符串时,给出错误提示。经过词法分析后,源程序字符串(源程序的外部表示)被翻译成具有等长信息的单词串(源程序的内部表示),并产生两个表格:常数表和变量表(即标识符表),它们分别包含了源程序中的所有常数和所有标识符。即该词法分析器可将下面C语言子集L所定义的“单词”区分开来,识别输入的源程序代码中每个“单词”是关键字,还是常量,还是变量,对于变量还要记录变量的个数,识别不同的变量,如程序段:real xx,y;xx=1;if(xx=1)y=5;要能识别出有2个变量,分别是xx,y,第1次扫描到xx,识别出是(6,0) 第2次、第3次扫描到xx,识别出仍是(6,0);第1次扫描到y,识别出是(6,1) ,第2次扫描到y,识别出仍是(6,1);对于常数采用同样的识别方法。
3、C语言子集L----保留字不区分大小写
L={ IF,THEN,ELSE,INT,CHAR,FOR,=,>=,==-,+, /,%,++,", ; }∪{常数}∪{变量,即标识符},变量只由字母构成,字母个数小于10。
4、实验报告要求:
(1)词法分析器构造原理,单词符号(记号)的分类编码表,状态转换图设计绘制写在实验报告中;
(2)进行词法分析器的测试:测试例程(一小段程序)、测试结果与测试结果分析。
5、例子:
本例中单词符号(记号)的种类:
1、保留字(关键字);
2、分隔符;
3、运算符;
4、常数;
5、标识符
(单词符号的分类可以自己规定,请在实验报告中给出分类编码表)
测试用例
第一段:
for (i=1;i<=100;i++)
{
printf("%d ", i ); }
over
运行词法分析程序后,显示结果如下:
for (for,16)
( ((,err)
i (i,51)
= (=,31)
1 (1,41)
; (;,22)
i (i ,51)
<= (<=,err)
100 (100,42)
; (;,22)
i (i ,51)
++ (++,37)
) (),err)
{ ({,err)
Printf (Printf,52)
( ((,err)
" (" ,21)
% (%,36)
d (d,53)
" (" ,21)
, (,err)
i (i,51)
) ( ),err)
; ( ;,22)
} ( },err)
over
常数表中的内容为:1,100
变量表(标识符表)中的内容为:i,printf,d
更多测试用例
第二段:
{
int n,i,kk;
printf(“n=?"); scanf("%d",&n);
for (i=2; i<=kk; i++)
if(n%i==0) break;
if(i<n) printf("%d no\n",n);
else printf("%d yes\n",n);
return 0;
}
over
第三段:
char c;
int letters=0,space=0,digit=0,other=0;
printf("\n");
while((c=getchar())!='\n')
{
if (( c>='a' && c<='z' )||( c>='A' && c<='Z') ) letters++;
else if (c==' ') space++;
else if (c>='0' && c<='9') digit++;
else other++;
}
printf(letters,space,digit,other);
over
实验代码:
# -*- coding: UTF-8 -*-
# list.append(obj) 增添对象
# extend 列表
# aList = [123, 'xyz', 'zara', 'abc', 123];
# bList = [2009, 'manni'];
# aList.extend(bList)
# 设置列表
list0 = ['IF', 11, 'THEN', 12, 'ELSE', 13, 'INT', 14, 'CHAR', 15, 'FOR', 16]
list2 = ['=', 21, '>=', 22, "==", 23, '+', 24, '/', 25, '%', 26, '++', 27, '"', 28, ';', 29] # 运算符
list4 = [] # 数字 动态添加
list5 = [] # 变量名 动态添加,检查是否存在
# 分割语句
list_temp = []
# str = 'for (i=1;i<=100;i++)' \
# '{ printf("%d ", i );' \
# '}' \
# 测试代码片,可以写个读文件
str = '{ int n,i,kk;' \
' printf("n=?"); scanf("%d",&n); ' \
' for (i=2; i<=kk; i++) ' \
' if(n%i==0) break; ' \
' if(i \
' else printf("%d yes\n",n); ' \
' return 0; ' \
'}'
list_temp = str.split()
print list_temp
# 开始从第一个单词循环
i = 0
sum_1 = 0
j = 0
k = 0
# 开始遍历
for idx in range(len(list_temp)):
str_new = list_temp[idx]
i = 0
while i < len(str_new):
if 'a' <= str_new[i] <= 'z' or 'A' <= str_new[i] <= 'Z':
if i != len(str_new)-1:
end = i + 1
while end < len(str_new):
if 'a' <= str_new[end] <= 'z' or 'A' <= str_new[end] <= 'Z':
end = end + 1
else:
end = end - 1
break
if i != end:
tmp = str_new[i:end+1]
if tmp.upper() in list0:
print tmp, "(", tmp, ",", list0[list0.index(tmp.upper()) + 1], ")"
else:
if tmp not in list5:
list5.append(tmp)
list5.append(50 + k)
k = k + 1
print tmp, "(", tmp, ",", list5[list5.index(tmp) + 1], ")"
else:
print tmp, "(", tmp, ",", list5[list5.index(tmp) + 1], ")"
i = end + 1
continue
else:
tmp = str_new[i]
if tmp not in list5:
list5.append(tmp)
list5.append(50 + k)
k = k + 1
print tmp, "(", tmp, ",", list5[list5.index(tmp) + 1], ")"
else:
print tmp, "(", tmp, ",", list5[list5.index(tmp) + 1], ")"
i = end + 1
continue
else:
tmp = str_new[i]
if tmp not in list5:
list5.append(tmp)
list5.append(50 + k)
k = k + 1
print tmp, "(", tmp, ",", list5[list5.index(tmp) + 1], ")"
else:
print tmp, "(", tmp, ",", list5[list5.index(tmp) + 1], ")"
i = i + 1
continue
else:
if '0' <= str_new[i] <= '9':
sum_1 = 0
while i < len(str_new):
if '0' <= str_new[i] <= '9':
sum_1 = sum_1 * 10 + int(str_new[i])
i = i + 1;
else:
num_end = i
if sum_1 not in list4:
list4.append(sum_1)
list4.append(40 + j)
j = j + 1
print sum_1, "(", sum_1, ",", list4[list4.index(sum_1) + 1], ")"
break
i = num_end-1
else:
# = 与 ==
if str_new[i] == '=':
if str_new[i + 1] == '=':
print "==", "(", "==", ",", 23, ")"
i = i + 1
else:
print "=", "(", "=", ",", 21, ")"
else:
# < 与 <=
if str_new[i] == '>':
if str_new[i + 1] == '=':
print ">=", "(", ">=", ",", 22, ")"
i = i + 1
else:
print ">", "(", ">", ",", "err", ")"
else:
# + 与 ++
if str_new[i] == '+':
if str_new[i + 1] == '+':
print "++", "(", "++", ",", 27, ")"
i = i + 1
else:
print "+", "(", "+", ",", 24, ")"
else:
if str_new[i] == '/':
print '/', "(", '/', ",", "25", ")"
else:
if str_new[i] == '%':
print '%', "(", '%', ",", "26", ")"
else:
if str_new[i] == '"':
print '"', "(", '"', ",", "28", ")"
else:
if str_new[i] == ';':
print ';', "(", ";", ",", "29", ")"
else:
# 错误判断,一般就是符号错误,最多2个,看下一位'='判断
if str_new[i] not in list2:
if i != len(str_new) - 1:
if str_new[i + 1] == '=':
print str_new[i: i + 2], "(", str_new[i: i + 2], ",", "err", ")"
i = i + 1
else:
print str_new[i], "(", str_new[i], ",", "err", ")"
else:
print str_new[i], "(", str_new[i], ",", "err", ")"
i = i + 1
x = 0
print("常数有:")
print list4
while x < len(list4):
if 2 * x < len(list4): # 防止越界
print(list4[2 * x])
x = x + 1
x = 0
print("变量有:")
print list5
while x < len(list5):
if 2 * x < len(list5):
print(list5[2 * x])
x = x + 1

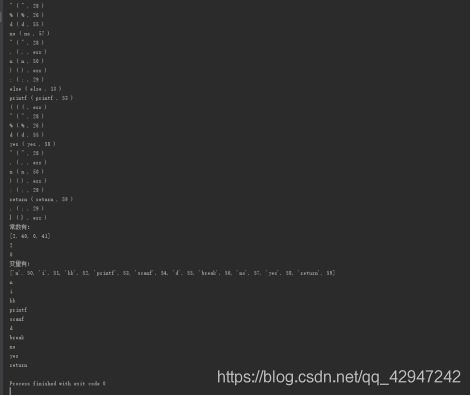

还是照搬了实验报告,删了些注释掉的代码,有空再看看能不能改进。
问题及讨论:
数据可以用词典来保存,可以更方便。